 生成式推薦系統與京東聯盟廣告-綜述與應用
生成式推薦系統與京東聯盟廣告-綜述與應用
大型語言模型(LLM)正在深刻地影響自然語言處理(NLP)領域,其強大的處理各種任務的能力也為其他領域的從業者帶來了新的探索路徑。推薦系統(RS)作為解決信息過載的有效手段,已經緊密融入我們的日常生活,如何用LLM有效重塑RS是一個有前景的研究問題[20, 25]。
這篇文章從生成式推薦系統與京東聯盟廣告各自的背景出發,引出二者結合的原因和方式。接著,對現有的流程和方法進行了總結和梳理。最后,介紹了我們在聯盟廣告場景下的應用實踐。
?
一、背景
生成式推薦系統
A generative recommender system directly generates recommendations or recommendation-related content without the need to calculate each candidate’s ranking score one by one[25].
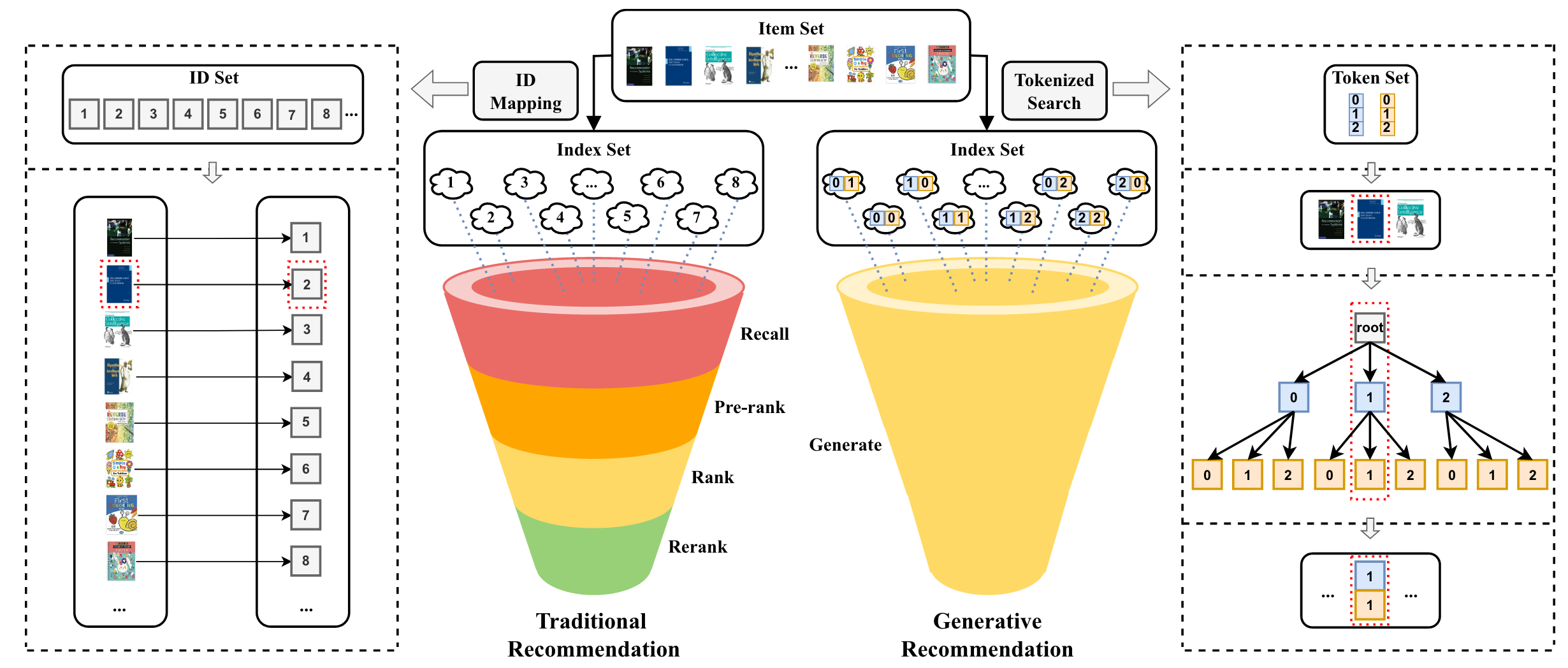
由于現實系統中的物料(item)數量巨大,傳統RS通常采用多級過濾范式,包括召回、粗排、精排、重排等流程,首先使用一些簡單而有效的方法(例如,基于規則/策略的過濾)來減少候選物料的數量,從數千萬甚至數億到數百個,然后對這些物料應用較復雜的推薦算法,以進一步選擇較少數量的物料進行推薦。受限于響應時間的要求,復雜推薦算法并不適用于規模很大的所有物料。
LLM的生成能力有可能重塑RS,相較于傳統RS,生成式推薦系統具備如下的優勢:1)簡化推薦流程。LLM可以直接生成要推薦的物料,而非計算候選集中每個物料的排名分數,實現從多級過濾范式(discriminative-based,判別式)到單級過濾范式(generative-based,生成式)的變遷。LLM在每個解碼步生成一個向量,表示在所有可能詞元(token)上的概率分布。經過幾個解碼步,生成的token就可以構成代表目標物料的完整標識符,該過程隱式枚舉所有候選物料以生成推薦目標物料[25]。2)具備更好的泛化性和穩定性。利用LLM中的世界知識和推理能力,在具有新用戶和物料的冷啟動和新領域場景下具備更好的推薦效果和遷移效果。同時,相比于傳統RS,生成式推薦系統的方法也更加具備穩定性和可復用性。特征處理的策略隨場景和業務的變化將變小、訓練數據量將變少,模型更新頻率將變低。
??
?圖1. 傳統推薦系統與基于LLM的生成式推薦系統的流程比較[25]
?
京東聯盟廣告
京東聯盟是京東的一個聯盟營銷平臺,以投放站外CPS廣告為主。聯盟合作伙伴通過生成的鏈接在其他網站或社交媒體平臺上推廣京東商品,引導用戶點擊這些鏈接并在京東購物,從而獲得銷售提成(傭金)。京東聯盟借此吸引流量,擴大平臺的可見度和與用戶的接觸范圍,實現拉新促活等目標。
聯盟廣告推薦主要針對低活躍度用戶進行多場景推薦,這樣的推薦面臨如下的挑戰:1)數據稀疏性:低活躍度用戶提供的數據較少,導致更加明顯的數據稀疏性問題。數據不足使得基于ID的傳統推薦模型難以充分地對物料和用戶進行表征,進而影響推薦系統的預測準確性。2)冷啟動問題:對于新用戶或低活躍度用戶,冷啟動問題尤為嚴重。由于缺乏足夠的歷史交互數據,推薦系統難以對這些用戶進行有效的個性化推薦。3)場景理解困難:在多場景推薦系統中,理解不同場景下用戶的具體需求尤為關鍵。對于低活躍度用戶,由于交互數據有限,推薦系統更難以識別出用戶在不同場景下的行為差異和需求變化。4)多樣性和新穎性:保持推薦內容的多樣性和新穎性對于吸引低活躍度用戶至關重要。然而,由于對這些用戶的了解有限,推薦系統難以平衡推薦的準確性與多樣性。
京東聯盟廣告+生成式推薦系統
將LLM融入推薦系統的關鍵優勢在于,它們能夠提取高質量的文本表示,并利用其中編碼的世界知識對用戶和物料進行理解和推薦。與傳統的推薦系統不同,基于LLM的模型擅長捕獲上下文信息,更有效地理解用戶信息、物料描述和其他文本數據。通過理解上下文,生成式推薦系統可以提高推薦的準確性和相關性,從而提升用戶滿意度。同時,面對有限的歷史交互數據帶來的冷啟動和數據稀疏問題,LLM還可通過零/少樣本推薦能力為推薦系統帶來新的可能性。這些模型可以推廣到未見過的新物料和新場景,因為它們通過事實信息、領域專業知識和常識推理進行了廣泛的預訓練,具備較好的遷移和擴展能力。
由此可見,京東聯盟廣告是生成式推薦系統一個天然的應用場。
二、生成式推薦系統的四個環節
為了實現如上的范式變遷,有四個基本環節需要考慮[26]:1)物料表示:在實踐中,直接生成物料(文檔或商品描述)幾乎是不可能的。因此,需要用短文本序列,即物料標識符,表示物料。2)模型輸入表示:通過提示詞定義任務,并將用戶相關信息(例如,用戶畫像和用戶歷史行為數據)轉換為文本序列。3)模型訓練:一旦確定了生成模型的輸入(用戶表示)和輸出(物料標識符),就可以基于Next Token Prediction任務實現訓練。4)模型推理:訓練后,生成模型可以接收用戶信息來預測對應的物料標識符,并且物料標識符可以對應于數據集中的真實物料。
雖然整個過程看起來很簡單,但實現有效的生成式推薦并非易事。在上述四個環節中需要考慮和平衡許多細節。下面詳細梳理了現有工作在四個環節上的應用與探索:
物料表示
An identifier in recommender systems is a sequence of tokens that can uniquely identify an entity, such as a user or an item. An identifier can take various forms, such as an embedding, a sequence of numerical tokens, and a sequence of word tokens (including an item title, a description of the item, or even a complete news article), as long as it can uniquely identify the entity[25].
推薦系統中的物料通常包含來自不同模態的各種信息,例如,視頻的縮略圖、音樂的音頻和新聞的標題。因此,物料標識符需要在文本空間中展示每個物料的復雜特征,以便進行生成式推薦。一個好的物料標識符構建方法至少應滿足兩個標準:1)保持合適的長度以減輕文本生成的難度。 2)將先驗信息集成到物料索引結構中,以確保相似項目在可區分的同時共享最多的token,不相似項目共享最少的token。以下是幾種構建物料標識符的方法:
(1)數字ID(Numeric ID)
由于數字在傳統RS中被廣泛地使用,一個直接的策略是在生成式推薦系統中也使用數字ID來表示物料。傳統RS將每個物料ID視為一個獨立且完整的token,不能被進一步分割。如果將這些token加入到模型中,需要1)大量的內存來存儲每個token的向量表示,以及2)充足的數據來訓練這些向量表示。為了解決這些問題,生成式推薦系統將數字ID分割成多個token組成的序列,使得用有限的token來代表無限的物料成為可能。為了有效地以token序列表示一個物料,現有的工作探索了不同的策略。1)順序索引:基于時間順序,利用連續的數字表示物料,例如,“1001, 1002, ...”,這可以捕捉與同一用戶交互的物料的共現(基于SentencePiece分詞器進行分詞時,“1001”和“1002”分別被分詞為“100”“1”和“100”“2”)。2)協同索引:基于共現矩陣或者協同過濾信息構建物料標識符,使得共現次數更多的物料或者具有相似交互數據的物料擁有相似的標識符前綴。盡管在生成式推薦系統中使用數字ID效果顯著,但它通常缺乏語義信息,因此會遭受冷啟動問題,并且未能利用LLM中編碼的世界知識。
(2)文本元數據(Textual Metadata)
為了解決數字ID中缺乏語義信息的問題,一些研究工作利用了物料的文本元數據,例如,電影標題,產品名稱,書名,新聞標題等。在與LLM結合時可借助LLM中編碼的世界知識更好地理解物料特性。但這種方式有兩個問題:1)當物料表示文本非常長時,進行生成的計算成本會很高。此外,長文本很難在數據集中找到精確匹配;仔細檢查每個長文本的存在性或相關性將使我們回到判別性推薦的范式,因為我們需要將其與數據集中的每個物料計算匹配得分。2)雖然自然語言是一種強大且富有表現力的媒介,但在許多情況下它也可能是模糊的。兩個不相關的物料可能具有相同的名稱,例如,“蘋果”既可以是一種水果也可以特指蘋果公司,而兩個密切相關的物料可能具有不同的標題,例如,數據挖掘中著名的“啤酒和尿布”示例[25]。
(3)語義ID(Semantic-based ID,SID)
為了同時獲得具有語義和區分性的物料標識符,現有方法主要通過如下方式對物料向量進行離散化:1)基于RQ-VAE模型[8]。RQ-VAE模型由編碼器,殘差量化和解碼器三部分構成,其輸入是從預訓練的語言模型(例如,LLaMA[9]和BERT[28])提取的物料語義表示,輸出是物料對應的token序列。在這個分支中,TIGER[7]是一個代表性的工作,它通過物料的文本描述生成對應的token序列,并將token序列命名為Semantic ID。LC-Rec[4]設計了多種微調LLM的任務,旨在實現Semantic ID與用戶交互數據或物料文本描述的語義對齊。這兩種方法首先將物料的語義相關性捕獲到標識符中,即具有相似語義的項目將擁有相似的標識符。然后,標識符表示將通過在推薦數據上訓練來優化,以獲取交互相關性。相比之下,LETTER[6]通過整合層次化的語義、協同信號和編碼分配的多樣性來構建高質量的物料標識符。2)基于語義層次化聚類方法。ColaRec[1]首先利用協同模型編碼物料,并利用k-means聚類算法對物料進行層次化聚類,將分類類別作為物料標識符,之后在微調任務中對齊物料語義信息和交互信息。Hi-Gen[5]則在獲取物料標識符的階段同時考慮了交互信息和語義信息,利用metric learning對兩種信息進行融合。
(4)小結
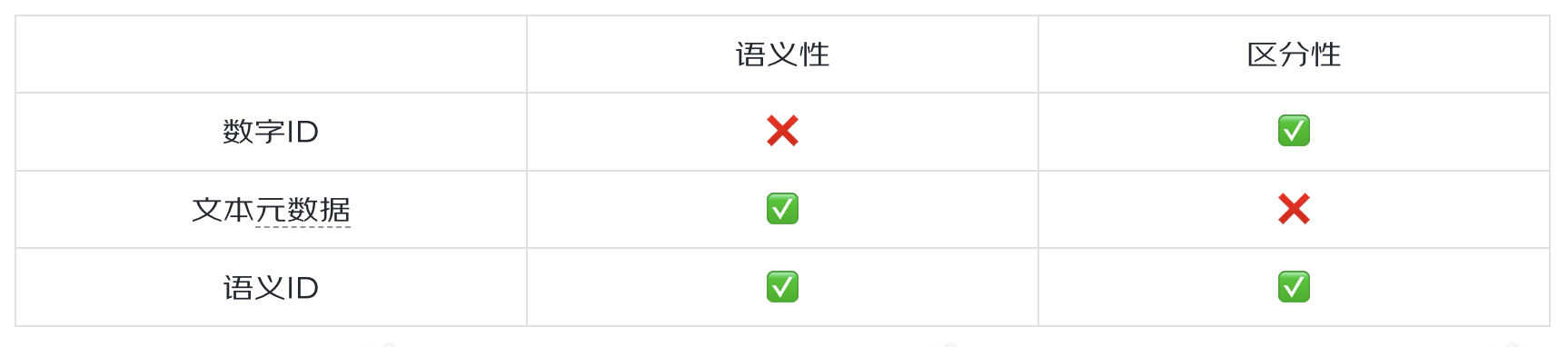
以上三類表示方法的對比如下:
??
表1. 不同離散化物料表示方法的對比
?
模型輸入表示
在生成式推薦系統中,模型輸入由如下的三個部分組成:任務描述、用戶信息、上下文及外部信息。其中,用戶信息主要包括用戶歷史交互數據和用戶畫像。
(1)任務描述
為了利用生成模型的理解能力,任務描述主要用來引導生成模型完成推薦任務,即將推薦任務建模為下一個物料的預測(類比語言模型的Next Token Prediction,此處是Next Item Prediction)。任務描述定義了提示詞模版,將可利用的數據嵌入其中。例如,“這是一個用戶的歷史交互數據:{historical behavior},他的偏好如下:{preference},請提供推薦。”同時將用戶歷史交互數據和偏好作為模型輸入內容[26]。
(2)用戶歷史交互數據
用戶的歷史交互數據在推薦系統中扮演著至關重要的角色,這種互動數據隱性地傳達了用戶對物料的偏好。用戶歷史交互數據的表示與上文介紹的物料表示密切相關,現有方法將其表示為:1)物料數字ID序列。物料數字ID被LLM作為純文本處理,由分詞器分割成幾個token。2)物料文本序列。將物料文本元數據進行拼接送入預訓練語言模型,語言模型可根據世界知識建模物料之間的相關性。3)物料文本向量加物料ID向量序列。LLaRA[2]在物料標題向量后拼接了物料ID向量,以補充來自協同模型的交互信息。
(3)用戶畫像
為了增強用戶建模,集成用戶畫像(例如,關于用戶的基礎信息和偏好信息)是推薦系統中建模用戶特征的一種有效方式。在大多數情況下,用戶的基礎信息(例如,性別)可以直接從在線推薦平臺獲取。這些用戶信息可與描述性文本結合使用,例如,“用戶描述:女性,25-34歲,在銷售/市場營銷領域工作”[26]。然而,由于用戶隱私問題,獲取用戶畫像可能具有挑戰性,導致一些研究直接采用用戶ID或ID向量[3]進行用戶建模。
(4)上下文及外部信息
上下文信息(例如,位置、場景和時間)可能會影響用戶決策,例如,在戶外用品推薦中,用戶可能更傾向于購買帳篷而水龍頭。因此,在LLM中結合諸如時間之類的上下文信息,可以實現有效的用戶理解。此外,外部知識也可以用來增強生成式推薦模型的性能,例如,用戶-物料交互圖中的結構化信息。
?
模型訓練
在推薦數據上訓練生成式推薦模型包括兩個主要步驟:文本數據構建和模型優化[26]。文本數據構建將推薦數據轉換為具有文本輸入和輸出的樣本,其中輸入和輸出的選擇取決于任務定義和物料表示方法。基于數字ID和文本元數據的物料表示方法可以直接構建文本數據,基于語義ID的方法則需要基于向量進行物料標識符的學習和獲取。在模型優化方面,給定<輸入,輸出>數據,生成式模型的訓練目標是最大化給定輸入預測輸出的條件似然。
針對生成式推薦系統,“用戶到物料標識符的訓練”是主要任務,即輸入是用戶構建,輸出是下一個物料的標識符。基于數字ID和文本元數據的方法利用該任務進行模型訓練。對于基于語義ID的方法,由于語義ID和自然語言之間存在差距,一般會利用如下輔助任務來增強物料文本和標識符之間的對齊[4]:1)“物料文本到物料標識符的訓練”或“物料標識符到物料文本的訓練”。對于每個訓練樣本,輸入輸出對包括同一物料的標識符和文本內容,可以互換地作為輸入或輸出。2)“用戶到物料文本的訓練”。通過將用戶信息與下一個物料的文本內容配對來隱式對齊物料標識符和物料文本。對于訓練如LLaMA這樣的大型語言模型,可采用多種策略來提高訓練效率,例如,參數高效微調,模型蒸餾和推薦數據篩選。
?
模型推理
為了實現物料推薦,生成式推薦系統在推理階段需要對生成結果進行定位,即實現生成的物料標識符與數據集中物料的有效關聯。給定用戶輸入表示,生成式推薦系統首先通過束搜索自回歸地生成物料標識符。這里的生成方式分為兩種:自由生成和受限生成[26]。對于自由生成,在每一個解碼步中,模型在整個詞表中搜索,并選擇概率最高的前K個token(K值取決于束搜索中定義的束大小)作為下一步生成的輸入。然而,在整個詞表上的搜索可能會導致生成不在數據集中的標識符,從而使推薦無效。
為了解決這個問題,早期工作使用精確匹配進行物料定位,即進行自由生成并簡單地丟棄無效的標識符。盡管如此,它們仍然由于無效標識符而導致準確率低,特別是對于基于文本元數據的標識符。為了提高準確性,BIGRec[23]提出將生成的標識符通過生成的token序列的表示和物料表示之間的L2距離來定位到有效物料上。如此,每個生成的標識符都確保被定位到有效的物料上。與此同時,受限生成也在推理階段被使用,例如,使用Trie(prefix tree)或者FM-index進行受限生成,保證標識符的有效生成。
在預測下一個物料這樣的典型推薦任務之外,也可充分利用自由生成產生新的物料描述或預測接下來N個物料。
?
現有工作總結
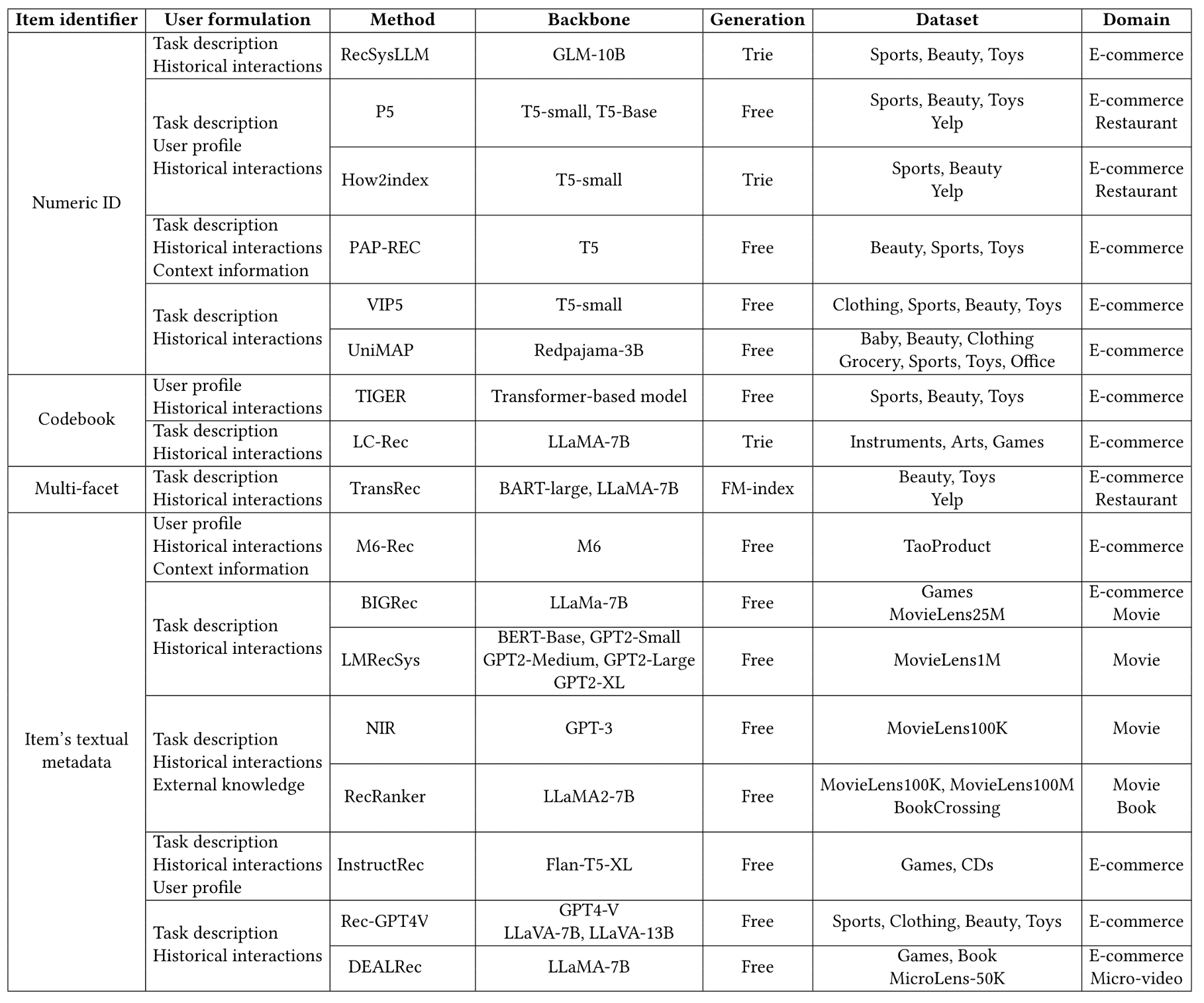
當前生成式推薦系統的代表性工作(RecSysLLM[22],P5[20][24],How2index[18],PAP-REC[17],VIP5[19],UniMAP[27],TIGER[7],LC-Rec[4],TransRec[16],M6-Rec[21],BIGRec[23],LMRecSys[10],NIR[12],RecRanker[13],InstructRec[11],Rec-GPT4V[14],DEALRec[15])可總結為:
??
表2. 生成式推薦系統的代表性工作[26]
?
三、實踐方案
總體設計
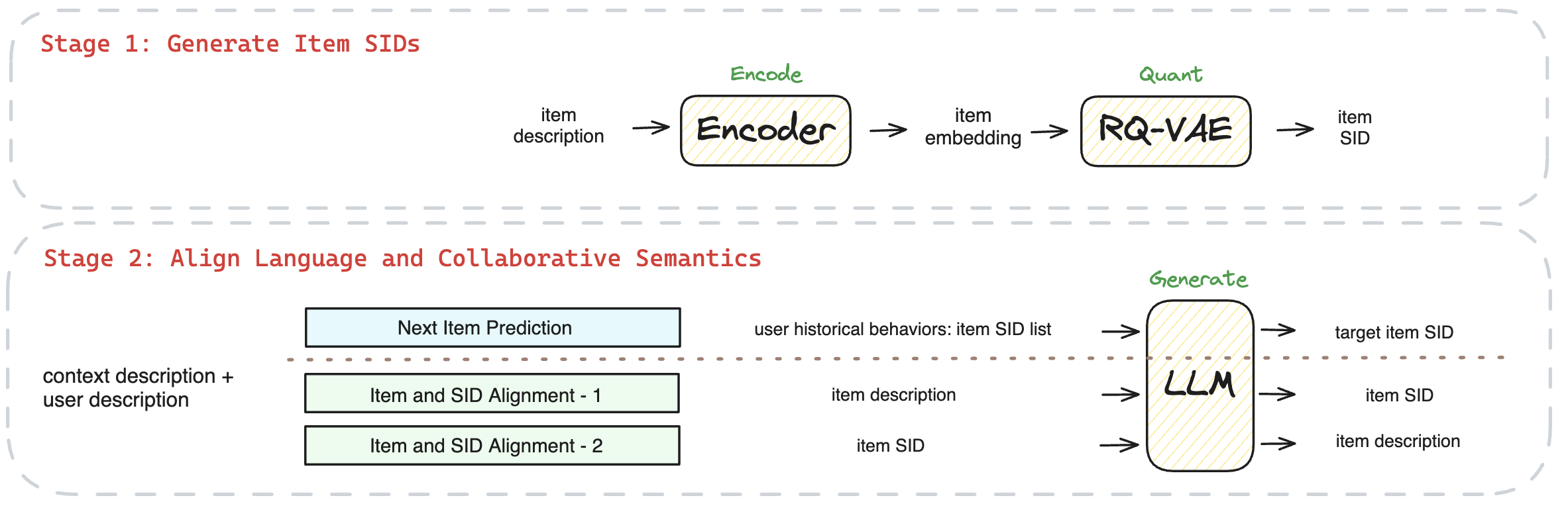
基于對現有工作的調研和總結,我們的方案以“基于語義ID的物料表示”和“對齊協同信息和文本信息的訓練任務”展開:
??
圖2. 總體設計框架圖
?
功能模塊
(1)基于語義ID(SID)的物料表示
物料文本描述:基于商品標題表示物料。
物料向量:通過預訓練的bert-base-chinese和Yi-6B分別提取文本描述對應的向量,向量維度為768(bert-base-chinese)和4096(Yi-6B)。
物料SID:基于RQ-VAE模型對物料向量進行量化。RQ-VAE模型由編碼器,殘差量化和解碼器三部分構成,其輸入是從預訓練的語言模型中提取的向量,輸出是物料對應的SID序列。針對沖突數據,我們采取了兩種方式,一種是不進行處理,即一個SID對應多個商品;另一種是采用TIGER的方案,對有沖突的商品增加隨機的一維,使得一個SID唯一對應一個商品。例如,商品“ThinkPad 聯想ThinkBook 14+ 2024 14.5英寸輕薄本英特爾酷睿ultra AI全能本高性能獨顯商務辦公筆記本電腦”可表示為:或。
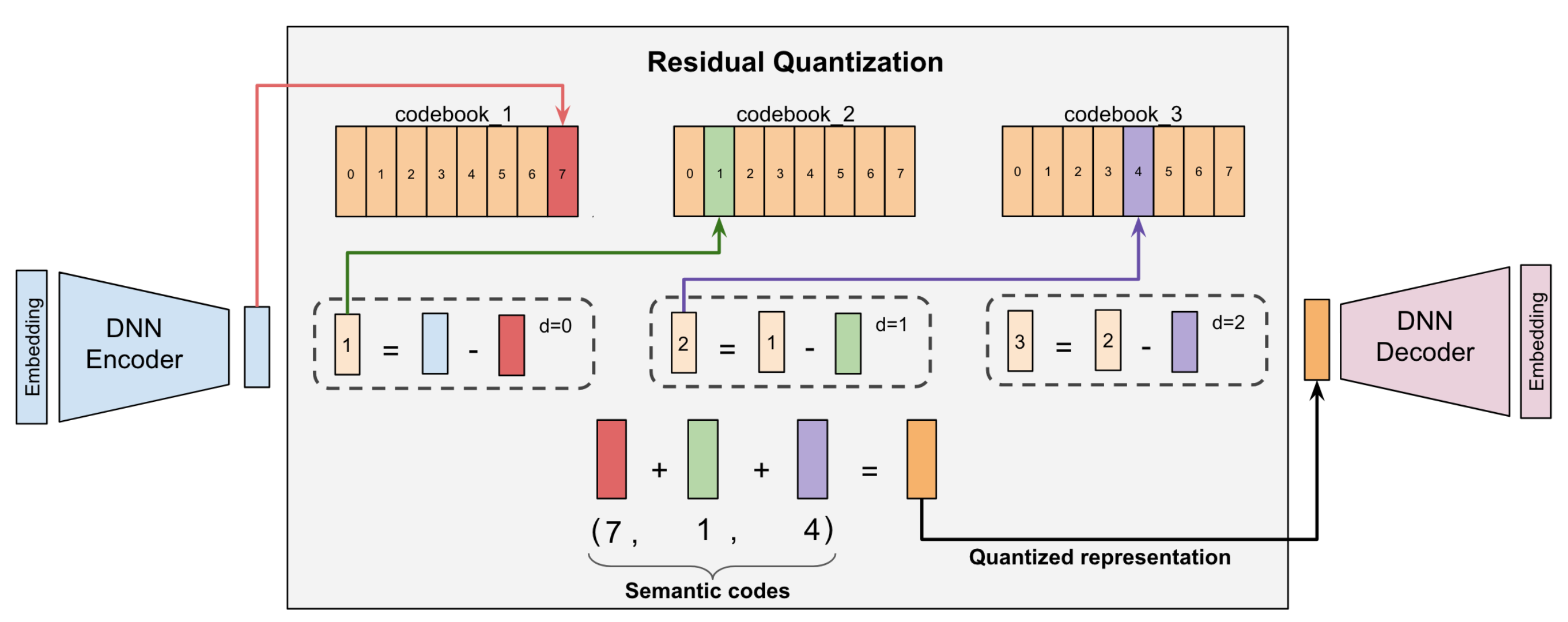
??
圖3. RQ-VAE模型圖[8]
(2)對齊協同信息和文本信息的訓練任務
Next Item Prediction:推薦系統的主任務,即針對給定的用戶描述(用戶畫像+歷史交互數據),預測下一個推薦的物料。
Additional Alignment:由于SID和自然語言之前存在差距,通過額外的對齊訓練,建立物料SID和物料文本描述之間的聯系,包括SID到文本描述和文本描述到SID的兩個雙向任務。
?
四、離線與在線實驗
訓練數據
(1)Next Item Prediction
{
"instruction": "該用戶性別為女,年齡為46-55歲,婚姻狀況為已婚,有無子女狀況為未知。用戶已按時間順序點擊了如下商品:, , , , , , , , , , , , ,你能預測用戶下一個可能點擊的商品嗎?",
"response": ""
}
(2)Item and SID Alignment1 - SID2Title
{
"instruction": "商品的標題是什么?",
"response": "ThinkPad 聯想ThinkBook 14+ 2024 14.5英寸輕薄本英特爾酷睿ultra AI全能本高性能獨顯商務辦公筆記本電腦 Ultra5 125H 32G 1T 3K屏 高刷屏"
}
(3)Item and SID Alignment2 - Title2SID
{
"instruction": "哪個商品的標題是"ss109威震天變形MP威震玩具天金剛飛機威男孩機器人戰機模型合金 震天戰機(戰損涂裝版)"?",
"response": ""
}
基座模型、訓練及推理
(1)base model: Qwen1.5-0.5B/1.8B/4B和Yi-6B
(2)基于SID增加新tokens,并利用交互數據進行訓練
(3)采用基于beam search的受限解碼策略,beam size=20
(4)實驗方式:離線實驗+線上小流量實驗
(5)離線評估指標:HR@1,5,10; NDCG@1,5,10
(6)在線評估指標:UCTR
實驗結果
(1)離線實驗——同一基座模型不同參數規模的對比:
?對比0.5B/1.8B/4B的結果可得,模型參數量越大,處理多種任務的能力越強,評估指標值越高;
?由于0.5B模型能力較弱,不適宜處理多種任務數據,單一任務訓練得到的模型相較混合任務有8倍提升;
?在離線訓練和測試數據有3個月的時間差的情況下,模型的表現仍然可觀。
(2)離線實驗——不同基座模型的對比:
?Yi-6B模型在不使用受限解碼的情況下就有最佳的表現;
?微調后的Yi-6B指令遵循的能力較好,可進行next item prediction和標題文本生成。
(3)離線實驗——與協同模型結果對比:
?在相同的數據規模和數據預處理的情況下,Yi-6B模型的效果更好;
?對稀疏數據進行過濾后訓練的協同模型效果會有顯著提升,傳統模型對數據和特征的處理方式更為敏感。
(4)線上小流量實驗:
?多個置信的站外投放頁面的小流量實驗顯示,基于生成式模型base版本可與傳統多路召回+排序的top1推薦對應的UCTR結果持平,在部分頁面更優,UCTR+5%以上。
?更適合數據稀疏、用戶行為不豐富的場景。
?
五、優化方向
在生成式推薦系統中,構建高質量的數據集是實現精準推薦的關鍵。在物料表示和輸入-輸出數據構建層面,將語義信息、多模態信息與協同信息結合,基于聯盟場景特點,可以顯著提升物料表示的準確性和相關性。
為了支持RQ-VAE的穩定訓練和語義ID的增量式推理,需要開發一種可擴展的SID訓練和推理框架,確保語義ID能夠快速適應物料變化。
此外,優化基座模型是提高生成式推薦系統性能的另一個關鍵領域。通過訓練任務的組合和采用多種訓練方式,例如,多LoRA技術和混合數據策略,可以進一步增強模型的表現。推理加速也是優化的一個重要方面,通過模型蒸餾、剪枝和量化等技術,可以提高系統的響應速度和效率。同時,基座模型的選型與變更,也是持續追求優化效果的一部分。
未來,可考慮引入搜索query內容進行搜推一體化建模。此外,引入如用戶推薦理由生成和用戶偏好生成等任務,可豐富系統的功能并提高用戶的互動體驗。
?
我們的目標是通過持續的技術革新,推動推薦系統的發展,實現更高效、更個性化的用戶服務。歡迎對這一領域感興趣的合作伙伴加入我們,共同探索生成式推薦系統技術的未來。
?
六、參考文獻
1.Wang Y, Ren Z, Sun W, et al. Enhanced generative recommendation via content and collaboration integration[J]. arXiv preprint arXiv:2403.18480, 2024.
2.Liao J, Li S, Yang Z, et al. Llara: Large language-recommendation assistant[J]. Preprint, 2024.
3.Zhang Y, Feng F, Zhang J, et al. Collm: Integrating collaborative embeddings into large language models for recommendation[J]. arXiv preprint arXiv:2310.19488, 2023.
4.Zheng B, Hou Y, Lu H, et al. Adapting large language models by integrating collaborative semantics for recommendation[J]. arXiv preprint arXiv:2311.09049, 2023.
5.Wu Y, Feng Y, Wang J, et al. Hi-Gen: Generative Retrieval For Large-Scale Personalized E-commerce Search[J]. arXiv preprint arXiv:2404.15675, 2024.
6.Wang W, Bao H, Lin X, et al. Learnable Tokenizer for LLM-based Generative Recommendation[J]. arXiv preprint arXiv:2405.07314, 2024.
7.Rajput S, Mehta N, Singh A, et al. Recommender systems with generative retrieval[J]. Advances in Neural Information Processing Systems, 2024, 36.
8.Zeghidour N, Luebs A, Omran A, et al. Soundstream: An end-to-end neural audio codec[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 30: 495-507.
9.Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
10.Zhang Y, Ding H, Shui Z, et al. Language models as recommender systems: Evaluations and limitations[C]//I (Still) Can't Believe It's Not Better! NeurIPS 2021 Workshop. 2021.
11.Zhang J, Xie R, Hou Y, et al. Recommendation as instruction following: A large language model empowered recommendation approach[J]. arXiv preprint arXiv:2305.07001, 2023.
12.Wang L, Lim E P. Zero-shot next-item recommendation using large pretrained language models[J]. arXiv preprint arXiv:2304.03153, 2023.
13.Luo S, He B, Zhao H, et al. RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation[J]. arXiv preprint arXiv:2312.16018, 2023.
14.Liu Y, Wang Y, Sun L, et al. Rec-GPT4V: Multimodal Recommendation with Large Vision-Language Models[J]. arXiv preprint arXiv:2402.08670, 2024.
15.Lin X, Wang W, Li Y, et al. Data-efficient Fine-tuning for LLM-based Recommendation[J]. arXiv preprint arXiv:2401.17197, 2024.
16.Lin X, Wang W, Li Y, et al. A multi-facet paradigm to bridge large language model and recommendation[J]. arXiv preprint arXiv:2310.06491, 2023.
17.Li Z, Ji J, Ge Y, et al. PAP-REC: Personalized Automatic Prompt for Recommendation Language Model[J]. arXiv preprint arXiv:2402.00284, 2024.
18.Hua W, Xu S, Ge Y, et al. How to index item ids for recommendation foundation models[C]//Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 2023: 195-204.
19.Geng S, Tan J, Liu S, et al. VIP5: Towards Multimodal Foundation Models for Recommendation[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. 2023: 9606-9620.
20.Geng S, Liu S, Fu Z, et al. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)[C]//Proceedings of the 16th ACM Conference on Recommender Systems. 2022: 299-315.
21.Cui Z, Ma J, Zhou C, et al. M6-rec: Generative pretrained language models are open-ended recommender systems[J]. arXiv preprint arXiv:2205.08084, 2022.
22.Chu Z, Hao H, Ouyang X, et al. Leveraging large language models for pre-trained recommender systems[J]. arXiv preprint arXiv:2308.10837, 2023.
23.Bao K, Zhang J, Wang W, et al. A bi-step grounding paradigm for large language models in recommendation systems[J]. arXiv preprint arXiv:2308.08434, 2023.
24.Xu S, Hua W, Zhang Y. Openp5: Benchmarking foundation models for recommendation[J]. arXiv preprint arXiv:2306.11134, 2023.
25.Li L, Zhang Y, Liu D, et al. Large language models for generative recommendation: A survey and visionary discussions[J]. arXiv preprint arXiv:2309.01157, 2023.
26.Li Y, Lin X, Wang W, et al. A Survey of Generative Search and Recommendation in the Era of Large Language Models[J]. arXiv preprint arXiv:2404.16924, 2024.
27.Wei T, Jin B, Li R, et al. Towards Universal Multi-Modal Personalization: A Language Model Empowered Generative Paradigm[C]//The Twelfth International Conference on Learning Representations. 2023.
28.Kenton J D M W C, Toutanova L K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of NAACL-HLT. 2019: 4171-4186.
審核編輯 黃宇
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
LLM
+關注
關注
0文章
286瀏覽量
327
發布評論請先 登錄
相關推薦
日本地震對中國廣告聯盟的影響
嵌入式開發環境搭建綜述
廣告賺錢-如何用google adsense 廣告聯盟賺錢方
京東聯手PICO打造“京東VR星球”
老榕樹廣告聯盟對互聯網移動端廣告技術新突破
京東金融APP就短視頻廣告爭議正式致歉
京東再次為低俗廣告道歉 京東金融低俗借貸廣告被吐槽
京粉智能推廣助手-LLM based Agent在聯盟廣告中的應用與落地






 工商網監
工商網監
評論