
") 動(dòng)態(tài)線程池思想學(xué)習(xí)及實(shí)踐
動(dòng)態(tài)線程池思想學(xué)習(xí)及實(shí)踐

相關(guān)文檔
美團(tuán)線程池實(shí)踐:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 線程池思想解析:https://www.javadoop.com/post/java-thread-pool?
引言
在后臺(tái)項(xiàng)目開發(fā)過程中,我們常常借助線程池來實(shí)現(xiàn)多線程任務(wù),以此提升系統(tǒng)的吞吐率和響應(yīng)性;而線程池的參數(shù)配置卻是一個(gè)難以合理評(píng)估的值,雖然業(yè)界也針對(duì)cpu密集型,IO密集型等場景給出了一些參數(shù)配置的經(jīng)驗(yàn)與方案,但是實(shí)際業(yè)務(wù)場景中通常會(huì)因?yàn)榱髁康碾S機(jī)性,業(yè)務(wù)的更迭性等情況出現(xiàn)預(yù)計(jì)和實(shí)際運(yùn)行情況偏差較大的情況;而不合理的線程池參數(shù),可能導(dǎo)致服務(wù)器負(fù)載升高,服務(wù)不可用,內(nèi)存溢出等嚴(yán)重問題;一旦遇到參數(shù)不合理的問題,還需要重新上線修改,并且存在反復(fù)修改的情況,而這期間花費(fèi)的時(shí)間可能帶來更大的風(fēng)險(xiǎn),甚至導(dǎo)致嚴(yán)重業(yè)務(wù)事故;那么有沒有一種方式能有效感知上述問題并及時(shí)避免以上問題呢?或許動(dòng)態(tài)線程池可以。
什么是動(dòng)態(tài)線程池
簡單來說,動(dòng)態(tài)線程池就是能在不重新部署應(yīng)用的情況下動(dòng)態(tài)實(shí)時(shí)變更其核心參數(shù),并且能對(duì)其核心參數(shù)及運(yùn)行狀態(tài)進(jìn)行監(jiān)控及告警;以便開發(fā)人員可以及時(shí)感知到實(shí)際業(yè)務(wù)中因?yàn)楦鞣N隨機(jī)情況導(dǎo)致線程池異常的場景,并依據(jù)動(dòng)態(tài)變更能力快速調(diào)整并驗(yàn)證參數(shù)的合理性。
為什么需要?jiǎng)討B(tài)線程池,存在什么痛點(diǎn)
線程池在給我們業(yè)務(wù)帶來性能和吞吐提升的同時(shí),也存在諸多風(fēng)險(xiǎn)和問題,其中主要原因就在于我們難以設(shè)置出合理的線程池參數(shù),一方面線程池的運(yùn)行機(jī)制不是很好理解,配置合理強(qiáng)依賴開發(fā)人員的個(gè)人經(jīng)驗(yàn)和知識(shí);另一方面,線程池執(zhí)行的情況和任務(wù)類型相關(guān)性較大,同時(shí)實(shí)際場景中流量的隨機(jī)性,業(yè)務(wù)的更迭性也導(dǎo)致業(yè)界難以有一套成熟或開箱即用的經(jīng)驗(yàn)策略來幫助開發(fā)人員參考。而線程池參數(shù)難以合理設(shè)置的特性又不得不讓我們關(guān)注以下三個(gè)痛點(diǎn)問題:
1.運(yùn)行情況難感知:在業(yè)務(wù)使用線程池的過程中,線程池的運(yùn)行情況對(duì)于開發(fā)人員來說很難感知,我們難以知道每個(gè)線程池創(chuàng)建了多少個(gè)線程,是否有隊(duì)列積壓,線程池運(yùn)行狀態(tài)怎么樣,線程池是否已經(jīng)耗盡... 直到出現(xiàn)線上問題或收到客訴才后知后覺;(我們能否對(duì)系統(tǒng)中用到的線程池進(jìn)行一個(gè)整體的把控,在線程池任務(wù)積壓,任務(wù)拒絕等問題發(fā)生時(shí),甚至問題發(fā)生前進(jìn)行及時(shí)感知,讓開發(fā)人員能未雨綢繆,盡早發(fā)現(xiàn)和解決問題呢?-線程池監(jiān)控,異常告警)
流量突增導(dǎo)致預(yù)估和實(shí)際情況偏差較大,同時(shí)由于未能及時(shí)感知并解決積壓情況,最終引發(fā)客訴 case1:廣告主大批量刪除物料后異步清理附屬表出現(xiàn)任務(wù)積壓 問題描述:廣告主批量刪除計(jì)劃物料后,對(duì)應(yīng)物料附屬表數(shù)據(jù)未及時(shí)刪除,導(dǎo)致廣告主關(guān)鍵詞等物料數(shù)上限得不到釋放而影響創(chuàng)建新物料,引發(fā)線上客訴。 問題原因:廣告主刪除計(jì)劃物料后,系統(tǒng)會(huì)同步刪除計(jì)劃物料主表信息,然后通過線程池的方式異步刪除計(jì)劃物料附屬表數(shù)據(jù)。臨近大促廣告主物料增刪頻率及單次批量操作的物料數(shù)量都有明顯增加,由于核心線程設(shè)置較小同時(shí)隊(duì)列設(shè)置過長,導(dǎo)致計(jì)劃主表同步刪除后異步刪除附屬表的任務(wù)出現(xiàn)隊(duì)列積壓,對(duì)應(yīng)的關(guān)鍵詞等物料數(shù)上限得不到釋放而影響新物料創(chuàng)建,引發(fā)線上客訴。
?
2.線程拒絕難定位:當(dāng)拒絕發(fā)生后,即使我們迅速感知到了線程池運(yùn)行異常,也經(jīng)常會(huì)因?yàn)榫芙^持續(xù)時(shí)間較短而拿不到問題發(fā)生時(shí)的線程堆棧,因此通常難以快速定位甚至無法定位到是哪里的原因?qū)е碌木芙^,比如是流量的突增將線程池打滿,還是某個(gè)業(yè)務(wù)邏輯耗時(shí)較長將線程池中的線程拖住;(我們有沒有一種方式能在線程池拒絕后去更容易的定位到問題呢?-自動(dòng)觸發(fā)線程池堆棧打印,分析工具)
case2: 線程池拒絕具有隨機(jī)性,當(dāng)拒絕時(shí)長較短時(shí),難以定位問題原因 問題描述:某業(yè)務(wù)接口內(nèi)部計(jì)算邏輯較多,且存在多處外部接口調(diào)用邏輯,上線后不定時(shí)出現(xiàn)線程池拒絕異常,由于持續(xù)時(shí)間不長,問題發(fā)生后無法通過jstack去獲取問題發(fā)生時(shí)現(xiàn)場的線程堆棧, 很難定位是什么原因?qū)е铝司€程池拒絕;由于沒有較好的排查手段,只能通過逐步摟日志的方式排查,而排查過程又可能因?yàn)槿罩据^多或者日志不全出現(xiàn)問題定位時(shí)間長或者是根本無法定位的情況。 問題原因:某外部某接口不穩(wěn)定,在性能較差且流量較大時(shí)就容易把調(diào)用線程池打滿,導(dǎo)致可用率下降
?
3.參數(shù)問題難以快速調(diào)整:在定位到某個(gè)線程池參數(shù)設(shè)置不合理的情況后,我們需要根據(jù)情況隨即進(jìn)行調(diào)整,但是"修改->打包->審批->發(fā)布"的時(shí)間很可能會(huì)擴(kuò)大問題的影響甚至是事故嚴(yán)重程度;同時(shí)因?yàn)榫€程池參數(shù)難以合理設(shè)置的原因,可能導(dǎo)致我們要重復(fù)進(jìn)行上述"修改->打包->審批->發(fā)布"的流程...(有沒有一種方法能快速修改并驗(yàn)證參數(shù)設(shè)置的合理性呢?-參數(shù)動(dòng)態(tài)調(diào)整)
線程池參數(shù)設(shè)置不合理,難以快速調(diào)整參數(shù),業(yè)務(wù)風(fēng)險(xiǎn)上升 case3:應(yīng)用JSF接口修改為異步調(diào)用后出現(xiàn)可用率下降 問題描述:將應(yīng)用中部分JSF接口切換為異步模式后,對(duì)應(yīng)可用率有明顯下降 問題原因:在修改為異步模式的JSF接口中,部分業(yè)務(wù)在拿到future對(duì)象后使用ThenApply做了一些耗時(shí)的操作,另外還有一部分在ThenApply里面又調(diào)用了另外一個(gè)異步方法;而thenApply的執(zhí)行會(huì)使用jsf的callBack線程池,由于線程池線程配置較小,并且部分回調(diào)方法耗時(shí)較長,導(dǎo)致callBack線程池被打滿,子任務(wù)請(qǐng)求線程時(shí)進(jìn)入阻塞隊(duì)列排隊(duì),出現(xiàn)接口超時(shí)可用率下降。
業(yè)界動(dòng)態(tài)線程池動(dòng)態(tài)線程池調(diào)研
當(dāng)前業(yè)界已存在部分動(dòng)態(tài)線程池組件,其主體功能及大體思想類似,但存在以下幾個(gè)問題
1.與外部中間件耦合較多,難以二次開發(fā)加以使用;
2.使用靈活性受限,難以根據(jù)業(yè)務(wù)自身特點(diǎn)進(jìn)行定制化(自動(dòng)觸發(fā)線程池堆棧打印,一鍵清空隊(duì)列,callback線程池等)
綜合考慮上述問題,決定結(jié)合公司中間件及自身業(yè)務(wù)特點(diǎn)實(shí)現(xiàn)一套集線程池監(jiān)控,異常告警,線程棧自動(dòng)獲取,動(dòng)態(tài)刷新為一體的動(dòng)態(tài)線程池組件。
如何實(shí)現(xiàn)動(dòng)態(tài)線程池
整體方案
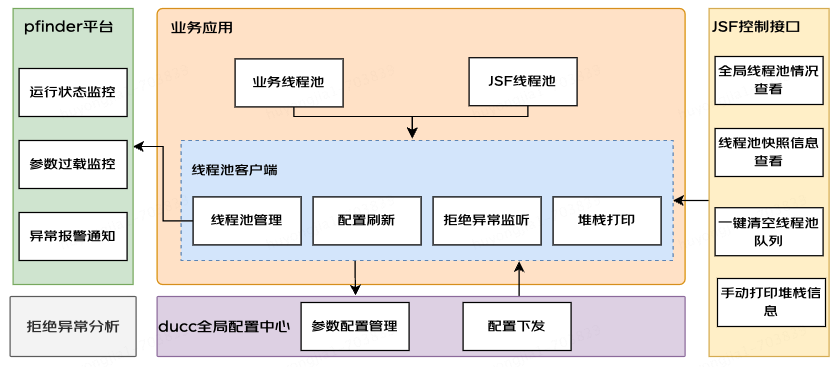
線程池監(jiān)控及告警
要實(shí)現(xiàn)線程池監(jiān)控及告警,我們需要關(guān)注以下幾個(gè)要點(diǎn)
1.如何獲取到待監(jiān)控的線程池信息
在實(shí)際業(yè)務(wù)中我們通常想要知道應(yīng)用中有哪些線程池,每個(gè)線程池各個(gè)參數(shù)在每個(gè)時(shí)刻的運(yùn)行情況是怎么樣的;對(duì)于第一種場景,我們可以構(gòu)建一個(gè)線程池管理器,用于管理應(yīng)用中使用到的業(yè)務(wù)線程池,為此我們可以在應(yīng)用初始化時(shí)將這些線程池按名稱和實(shí)際對(duì)象注冊(cè)到管理器;后續(xù)使用時(shí)就可以根據(jù)名稱從管理中心拉取到對(duì)應(yīng)線程池;
public class ThreadPoolManager {
// 線程池管理器
private static final ConcurrentHashMap REGISTER_MAP_BY_NAME = new ConcurrentHashMap();
private static final ConcurrentHashMap REGISTER_MAP_BY_EXECUTOR = new ConcurrentHashMap();
// 注冊(cè)線程池
public static void registerExecutor(String threadPoolName, Executor executor) {
REGISTER_MAP_BY_NAME.putIfAbsent(threadPoolName, executor);
REGISTER_MAP_BY_EXECUTOR.putIfAbsent(executor, threadPoolName);
}
// 根據(jù)名稱獲取線程池
public static Executor getExecutorByName(String threadPoolName) {
return REGISTER_MAP_BY_NAME.get(threadPoolName);
}
// 根據(jù)線程池獲取名稱
public static String getNameByExecutor(Executor executor) {
return REGISTER_MAP_BY_EXECUTOR.get(executor);
}
// 獲取所有線程池名稱
public static Set getAllExecutorNames() {
return REGISTER_MAP_BY_NAME.keySet();
}
}
對(duì)于第二種場景,線程池的核心實(shí)現(xiàn)類ThreadPoolExecutor提供了多個(gè)參數(shù)查詢方法,我們可以借助這些方法查詢某一時(shí)刻該線程池的運(yùn)行快照
getCorePoolSize() // 核心線程數(shù) getMaximumPoolSize() // 最大線程數(shù) getQueue() // 阻塞隊(duì)列,獲取隊(duì)列大小,容量等 getActiveCount() // 活躍線程數(shù) getTaskCount() // 歷史已完成和正在執(zhí)行的任務(wù)數(shù)量 getCompletedTaskCount() // 已完成任務(wù)數(shù)
2.如何將監(jiān)控的信息保存和展示出來
監(jiān)管了應(yīng)用中的業(yè)務(wù)線程池,也能獲取到某一時(shí)刻各線程池的運(yùn)行情況快照,但要實(shí)現(xiàn)線程池?cái)?shù)據(jù)監(jiān)控還需要我們?cè)诿總€(gè)時(shí)刻去采集線程池運(yùn)行信息,并將其保存下來,同時(shí)還需要將這些數(shù)據(jù)用一個(gè)可視化頁面展示出來供我們觀察才行,否則我們只知道某一時(shí)刻的線程池情況也意義不大。為此,我們需要考慮上面看到的過程,例如使用Micrometer采集性能數(shù)據(jù),使用Prometheus時(shí)序數(shù)據(jù)庫存儲(chǔ)指標(biāo)數(shù)據(jù),使用Grafana展示數(shù)據(jù);而現(xiàn)在,我們只需要根據(jù)pfinder的埋點(diǎn)要求將對(duì)應(yīng)要監(jiān)控的線程池指標(biāo)配置到上報(bào)邏輯即可,剩下的數(shù)據(jù)分時(shí)采集,數(shù)據(jù)存儲(chǔ),數(shù)據(jù)展示可以完全交給pfinder來完成。
// 已經(jīng)設(shè)置埋點(diǎn)的線程池
public static ConcurrentHashSet monitorThreadPool = new ConcurrentHashSet();
// 監(jiān)控埋點(diǎn)注冊(cè)
public static void monitorRegister() {
log.info("===> monitor register start...");
// 1.獲取所有線程池
Set allExecutorNames = ThreadPoolManager.getAllExecutorNames();
// 2.遍歷線程池,注冊(cè)埋點(diǎn)
allExecutorNames.forEach(executorName-> {
if (!monitorThreadPool.contains(executorName)) {
monitorThreadPool.add(executorName);
Executor executor = ThreadPoolManager.getExecutorByName(executorName);
collect(executor, executorName);
}
});
log.info("===> monitor register end...");
}
// pfinder指標(biāo)埋點(diǎn)
public static void collect(Executor executorService, String threadPoolName) {
ThreadPoolExecutor executor = (ThreadPoolExecutor)executorService;
String prefix = "thread.pool."+threadPoolName;
gauge1 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getCorePoolSize())
.tags(MetricTag.of("type_dimension", "core_size")).build();
gauge2 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getMaximumPoolSize())
.tags(MetricTag.of("type_dimension", "max_size"))
.build();
gauge4 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getQueue().size())
.tags(MetricTag.of("type_dimension", "queue_size"))
.build();
}
3.如何監(jiān)聽到異常并告警
線程池運(yùn)行過程中,我們可能更多關(guān)注線程池拒絕前感知線程池隊(duì)列是否有積壓,線程數(shù)是否已達(dá)設(shè)置核心或最大線程數(shù)高點(diǎn)以及線程池拒絕異常;由于使用pfinder作為線程池監(jiān)控組件,其中線程池隊(duì)列是否有積壓,線程數(shù)是否已達(dá)設(shè)置核心,最大線程數(shù)高點(diǎn)等異常監(jiān)聽及告警可以直接依賴pfinder的告警配置來實(shí)現(xiàn); 例如下圖中配置隊(duì)列積壓超過閾值時(shí)的報(bào)警
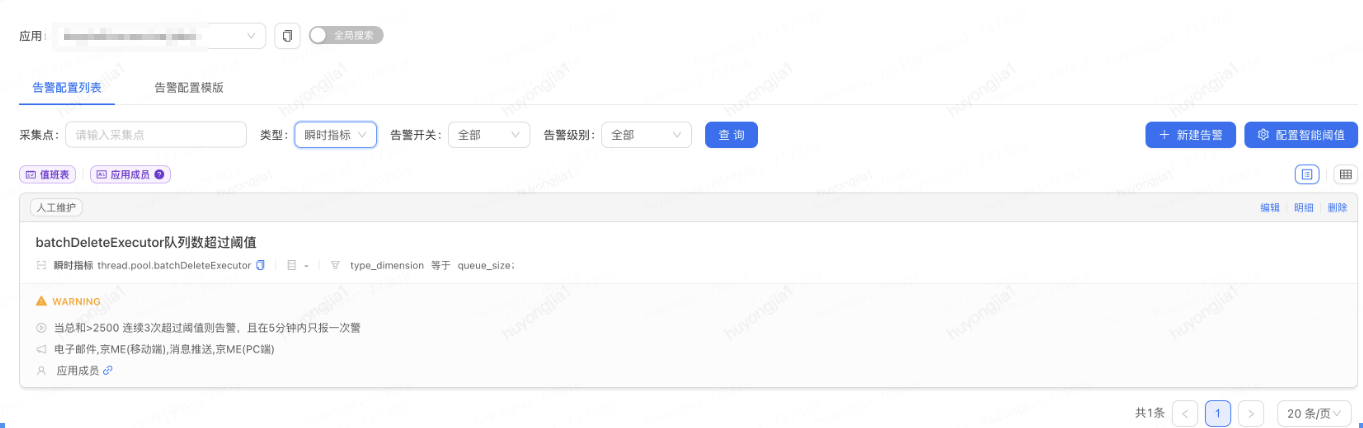
而線程池拒絕異常,我們可以在線程池初始化時(shí)包裝線程池的拒絕策略,在執(zhí)行實(shí)際拒絕策略前拋出告警;
@Slf4j
public class RejectInvocationHandler implements InvocationHandler {
private final Object target;
@Value("${jtool.pool.reject.alarm.key}")
private String key;
public RejectInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
ExecutorService executor = (ExecutorService)args[1];
if (Strings.equals(method.getName(), "rejectedExecution")) {
try {
rejectBefore(executor);
}
catch (Exception exp) {
log.error("==> Exception while do rejectBefore for pool [{}]", executor, exp);
}
}
return method.invoke(target, args);
}
private void rejectBefore(ExecutorService executor) {
// 觸發(fā)報(bào)警
rejectAlarm(executor);
}
/**
* 拒絕報(bào)警
*/
private void rejectAlarm(ExecutorService executor) {
String alarmKey = Objects.nonNull(key) ? key : ThreadPoolConst.UMP_ALARM_KEY;
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor)executor;
String threadPoolName = ThreadPoolManager.getNameByExecutor(threadPoolExecutor);
String errorMsg = String.format("===> 線程池拒絕報(bào)警 key: [%s], cur executor: [%s], core size: [%s], max size: [%s], queue size: [%s], curQueue size: [%s]",
alarmKey, threadPoolName, threadPoolExecutor.getCorePoolSize(), threadPoolExecutor.getMaximumPoolSize(), threadPoolExecutor.getQueue().size()+threadPoolExecutor.getQueue().remainingCapacity(), threadPoolExecutor.getQueue().size());
log.error(errorMsg);
Profiler.businessAlarm(alarmKey, errorMsg);
}
}
自動(dòng)觸發(fā)線程堆棧打印
感知到拒絕線程池拒絕異常后,我們需要及時(shí)去定位線程池拒絕原因,但現(xiàn)在我們可能只知道是哪個(gè)線程池發(fā)生了線程池拒絕異常,卻難以知道是什么原因?qū)е碌模覀兂3OM诰€程池拒絕時(shí)能拿到應(yīng)用的線程堆棧信息,并依據(jù)其分析拒絕原因;但是線程拒絕常常發(fā)生速度很快,我們很難捕捉到拒絕時(shí)刻的全局線程堆棧快照;為此,我們考慮在線程池拒絕發(fā)生時(shí)自動(dòng)觸發(fā)線程池堆棧打印到日志;
public class RejectInvocationHandler implements InvocationHandler {
...
private void rejectBefore(ExecutorService executor) {
// 打印線程堆棧到日志的間隔條件
if (CommonProperty.canPrintStackTrace()) {
// 觸發(fā)報(bào)警
rejectAlarm(executor);
// 觸發(fā)線程堆棧打印
printThreadStack(executor);
}
}
...
}
...
/**
* 打印線程堆棧信息
*/
public static void printThreadStack(Executor executor) {
if (!CommonProperty.logPrintFlag) {
log.info("===> 線程池堆棧打印關(guān)閉:[{}]", CommonProperty.logPrintFlag);
return;
}
logger.info("n=================>>> 線程池拒絕堆棧打印start,觸發(fā)提交拒接處理的線程池:【{}】", executor);
Map allStackTraces = Thread.getAllStackTraces();
log.info("===> allStackTraces size :[{}]", allStackTraces.size());
StringBuilder stringBuilder = new StringBuilder();
allStackTraces.entrySet().stream()
.sorted(Comparator.comparing(entry -> entry.getKey().getName()))
.forEach(threadEntry -> {
Thread thread = threadEntry.getKey();
stringBuilder.append(Strings.format("n線程:[{}] 時(shí)間: [{}]n", thread.getName(), new Date()));
stringBuilder.append(Strings.format("tjava.lang.Thread.State: {}n", thread.getState()));
StackTraceElement[] stack = threadEntry.getValue();
for (StackTraceElement stackTraceElement : stack) {
stringBuilder.append("tt").append(stackTraceElement.toString()).append("n");
}
stringBuilder.append("n");
logger.info(stringBuilder.toString());
stringBuilder.delete(0, stringBuilder.length());
});
logger.info("==============>>> end");
}
...
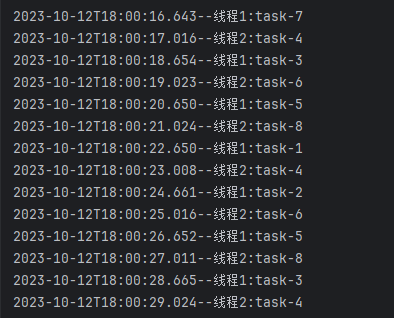
打印后的信息如下所示
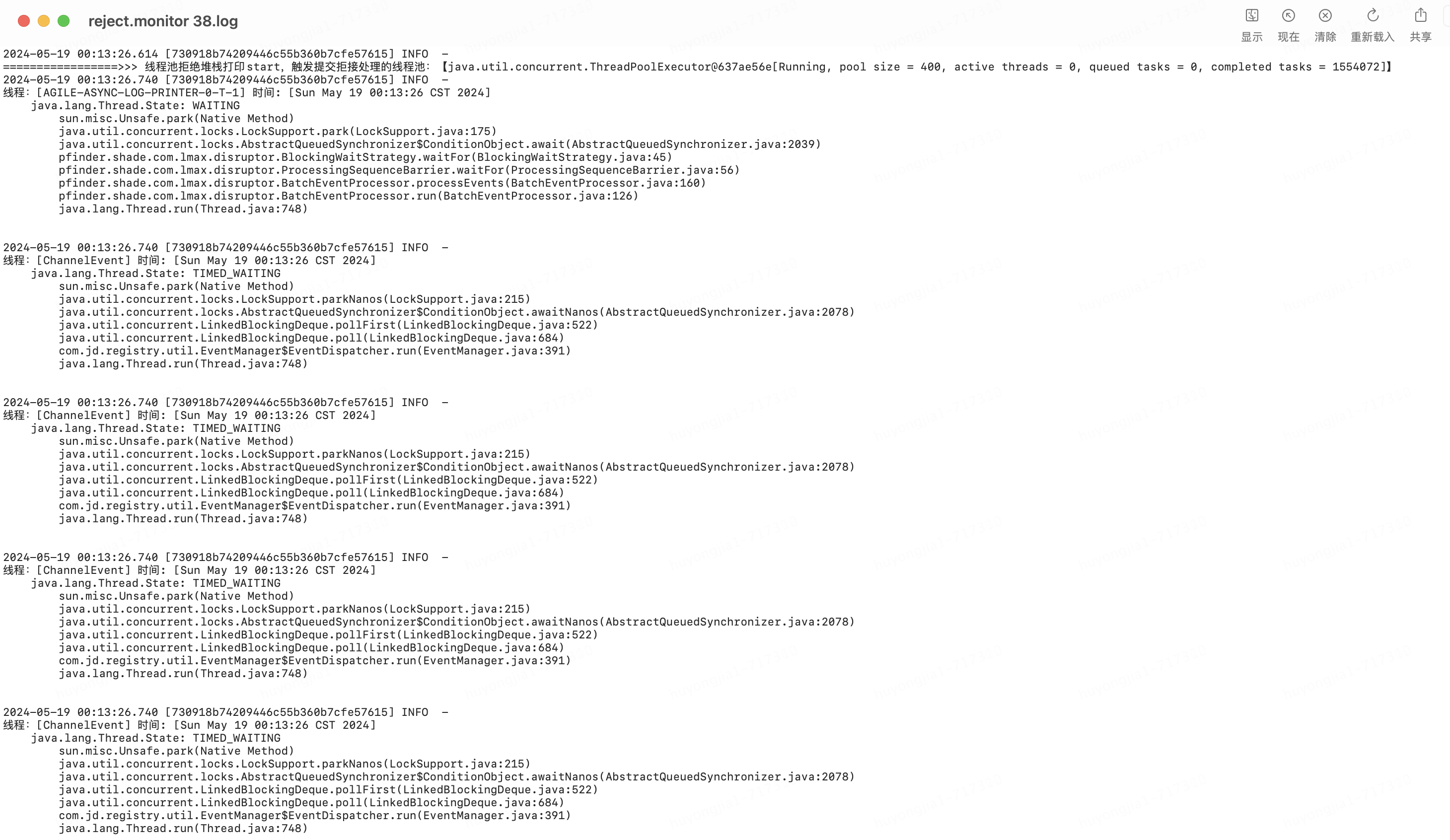
拿到問題發(fā)生時(shí)的堆棧信息后,我們就可以根據(jù)拒絕線程的名稱去分析拒絕原因了,看看是否有什么原因?qū)е戮€程被卡住;為了更方便的分析,可以根據(jù)簡單的根據(jù)日志規(guī)則去分析拒絕線程池問題發(fā)生時(shí)各線程池的運(yùn)行狀態(tài)是什么,大部分都集中到了哪個(gè)方法的哪個(gè)位置
public class ThreadLogAnalyzer {
public static void main(String[] args) {
String logFilePath = "/Users/huyongjia1/Desktop/huyongjia/demo/jsfdemo/MyJtool/src/main/resources/reject.monitor 21.log";
String threadPoolNameLike = "simpleTestExecutor";
int threadCount = 0;
HashMap statusMap = new HashMap();
HashMap methodMap = new HashMap();
try (BufferedReader br = new BufferedReader(new FileReader(logFilePath))) {
String line;
while ((line = br.readLine()) != null) {
if (line.contains("=================>>> 線程池拒絕堆棧打印start,觸發(fā)提交拒接處理的線程池")) {
System.out.println("開始讀整個(gè)線程");
}
if (line.contains(threadPoolNameLike)) {
threadCount++;
String curStatus = br.readLine();
if (curStatus.contains("java.lang.Thread.State")) {
statusMap.put(curStatus, (statusMap.getOrDefault(curStatus, 0) + 1));
String methodTrace = br.readLine();
methodMap.put(methodTrace, (methodMap.getOrDefault(methodTrace, 0) + 1));
}
}
if (line.contains("==============>>> end")) {
System.out.println("結(jié)束讀整個(gè)線程");
}
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(Strings.format("===> 當(dāng)前線程名[{}]共計(jì):{}", threadPoolNameLike, threadCount));
System.out.println("n===> 狀態(tài)分析結(jié)果:");
for (Map.Entry statusEntry : statusMap.entrySet()) {
System.out.println(Strings.format("t {} {}", statusEntry.getKey(), statusEntry.getValue()));
}
System.out.println("n===> 方法分析結(jié)果:");
ArrayList> methodEntryList = Lists.newArrayList(methodMap.entrySet());
methodEntryList.sort(new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
return o2.getValue() - o1.getValue();
}
});
for (Map.Entry methodEntry : methodEntryList) {
System.out.println(Strings.format("{} {} {}%", methodEntry.getKey(), methodEntry.getValue(), (methodEntry.getValue() / (double)threadCount) * 100));
}
}
}
例如當(dāng)前收到simpleTestExecutor線程池拒絕告警,利用堆棧信息分析如下,可以看到該線程池共4個(gè)線程,其中3個(gè)的運(yùn)行狀態(tài)為TIMED_WAITING,并且都停在了sleep邏輯處
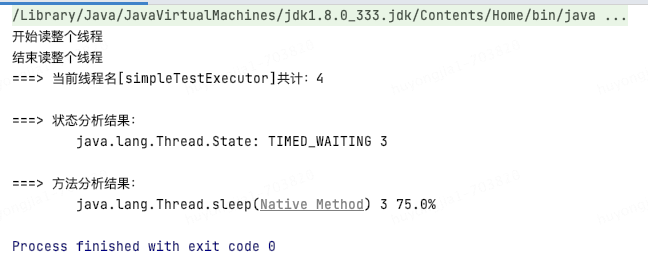
線程池參數(shù)動(dòng)態(tài)刷新
要實(shí)現(xiàn)線程池參數(shù)動(dòng)態(tài)刷新,我們需要關(guān)注以下幾個(gè)要點(diǎn):
1.哪些參數(shù)需要變更
在使用線程池時(shí),我們通常需要配置多個(gè)參數(shù),但是實(shí)際上我們只需要靈活配置好corePoolSize(核心線程數(shù)),maximumPoolSize(最大線程數(shù)),workQueue(隊(duì)列長度)這三個(gè)核心參數(shù)就可以應(yīng)對(duì)大部分場景了;
2.運(yùn)行中的線程池如何變更參數(shù)
從前面我們可以知道線程池的核心實(shí)現(xiàn)類ThreadPoolExecutor提供了改變corePoolSize,maximumPoolSize的兩個(gè)快捷方法:
1. setCorePoolSize(int corePoolSize)
2. setMaximumPoolSize(int maximumPoolSize)
我們只需要通過rpc或者h(yuǎn)ttp的方式將想要變更的參數(shù)傳遞到應(yīng)用再利用上述方法設(shè)置進(jìn)去即可;而隊(duì)列長度的變更卻相對(duì)麻煩點(diǎn),因?yàn)槲覀兂J褂玫淖枞?duì)列LinkedBlockingQueue將隊(duì)列大小設(shè)置為成了一個(gè)final類型的變量,我們無法快捷變更,那該怎么辦呢,其中一個(gè)思想就是自定義一個(gè)LinkedBlockQueue,修改capacity為非final類型,同時(shí)考慮并發(fā)問題對(duì)其中涉及到的方法進(jìn)行修改;(可參考RabbitMq中的VariableLinkedBlockingQueue)
3.應(yīng)用集群場景下如何實(shí)現(xiàn)一鍵參數(shù)變更
實(shí)際情況下,我們的應(yīng)用是已集群的方式部署的,這時(shí)我們可以借助ducc全局配置工具將要變更的參數(shù)傳遞到集群的各個(gè)機(jī)器,各機(jī)器根據(jù)再根據(jù)參數(shù)中的線程池名稱去線程池管理中心拿到對(duì)應(yīng)的線程進(jìn)行參數(shù)變更即可;
/**
* ducc控制線程池刷新方法, 需要?jiǎng)討B(tài)刷新的線程池信息列表,舉例如下:
* value:
* [
* {
* "threadPoolName": "my_pool",
* "corePoolSize": "10",
* "maximumPoolSize": "20",
* "queueCapacity": "100"
* }
* ]
*/
@LafValue("jtool.pool.refresh")
public void refresh(@JsonConverter List threadPoolProperties) {
String jsonString = JSON.toJSONString(threadPoolProperties);
log.info("===> refresh thread pool properties [{}]", jsonString);
threadPoolProperties = JSONObject.parseArray(jsonString, ThreadPoolProperties.class);
refresh(threadPoolProperties);
}
public static boolean refresh(List threadPoolProperties) {
if (Objects.isNull(threadPoolProperties)) {
log.warn("refresh param is empty!");
return false;
}
log.info("Executor refresh param: [{}]", threadPoolProperties);
// 1.根據(jù)參數(shù)獲取對(duì)應(yīng)的線程池
threadPoolProperties.forEach(threadPoolProperty -> {
String threadPoolName = threadPoolProperty.getThreadPoolName();
Executor executor = ThreadPoolManager.getExecutorByName(threadPoolName);
if (Objects.isNull(executor)) {
log.warn("Register not find this executor: {}", threadPoolName);
return;
}
// 2. 線程池刷新
refreshExecutor(executor, threadPoolName, threadPoolProperty);
log.info("Refresh thread pool finish, threadPoolName: [{}]", threadPoolName);
});
return true;
}
實(shí)踐效果
線程池監(jiān)控
達(dá)成目的:對(duì)應(yīng)用中的線程池情況做整體把控,能方便獲取各線程池的運(yùn)行情況
接入pfinder監(jiān)控后的效果如下
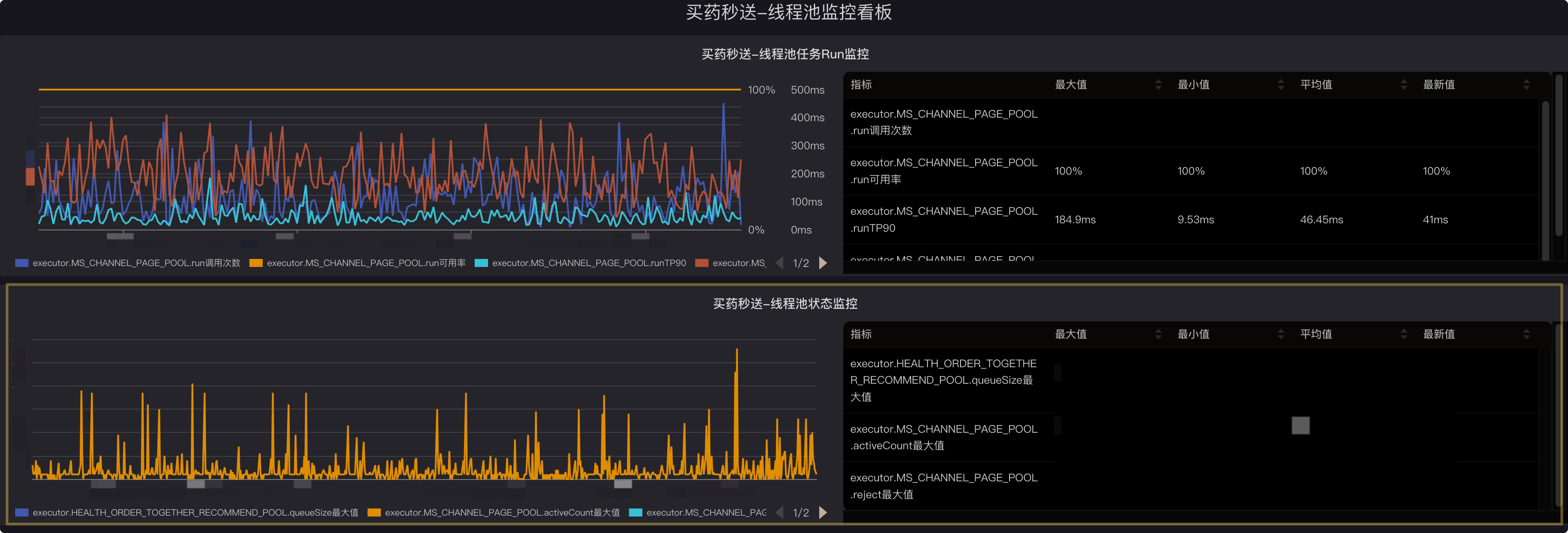
1.pfinder監(jiān)控:注冊(cè)的監(jiān)控線程池會(huì)自動(dòng)上報(bào)線程池的活躍,核心,最大,隊(duì)列大小,隊(duì)列容量,任務(wù)數(shù)等指標(biāo);監(jiān)控地址在pfinder當(dāng)前服務(wù)的業(yè)務(wù)監(jiān)控中,正確接入后可以看到已經(jīng)被監(jiān)控的線程池列表,監(jiān)控埋點(diǎn)名稱: thread.pool.{線程池名稱}
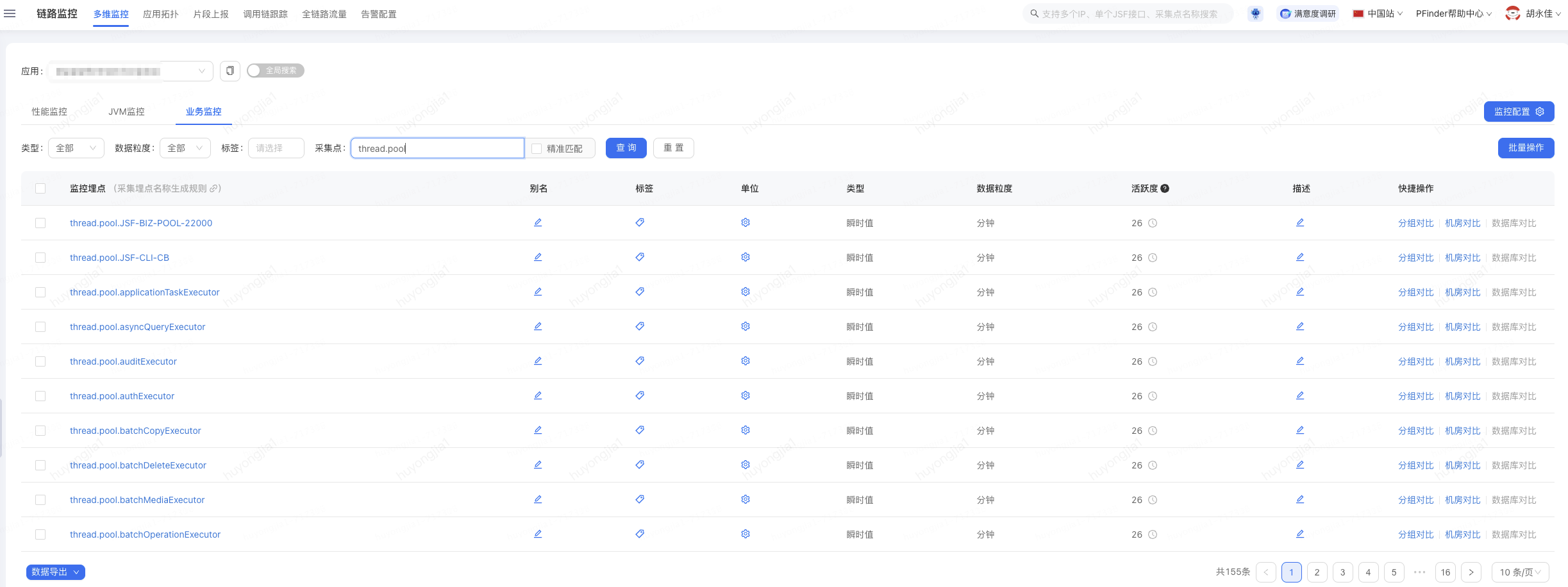
如果要看某一個(gè)線程池的指標(biāo)數(shù)據(jù),可以單獨(dú)進(jìn)入某個(gè)線程池的監(jiān)控,其中通過數(shù)據(jù)選擇要看的指標(biāo)(type_dimension)
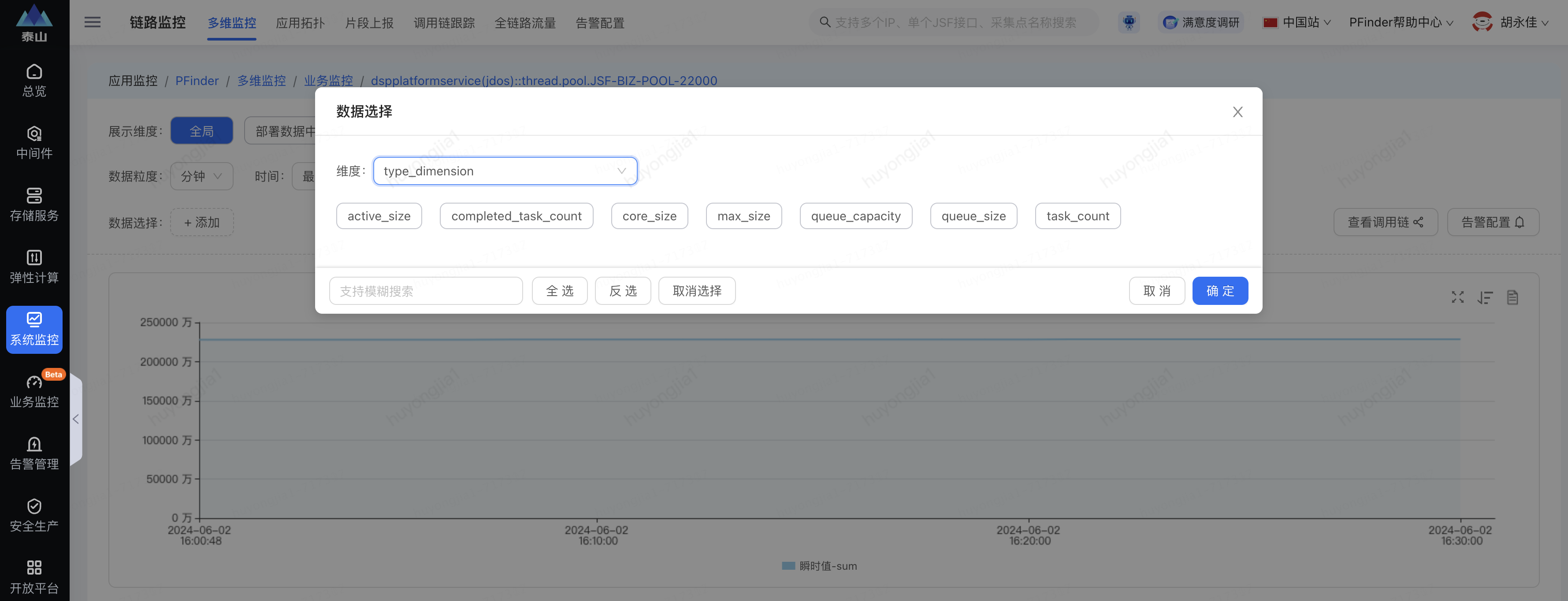
可在展示維度中選擇要具體展示的維度,比如分組,實(shí)例等
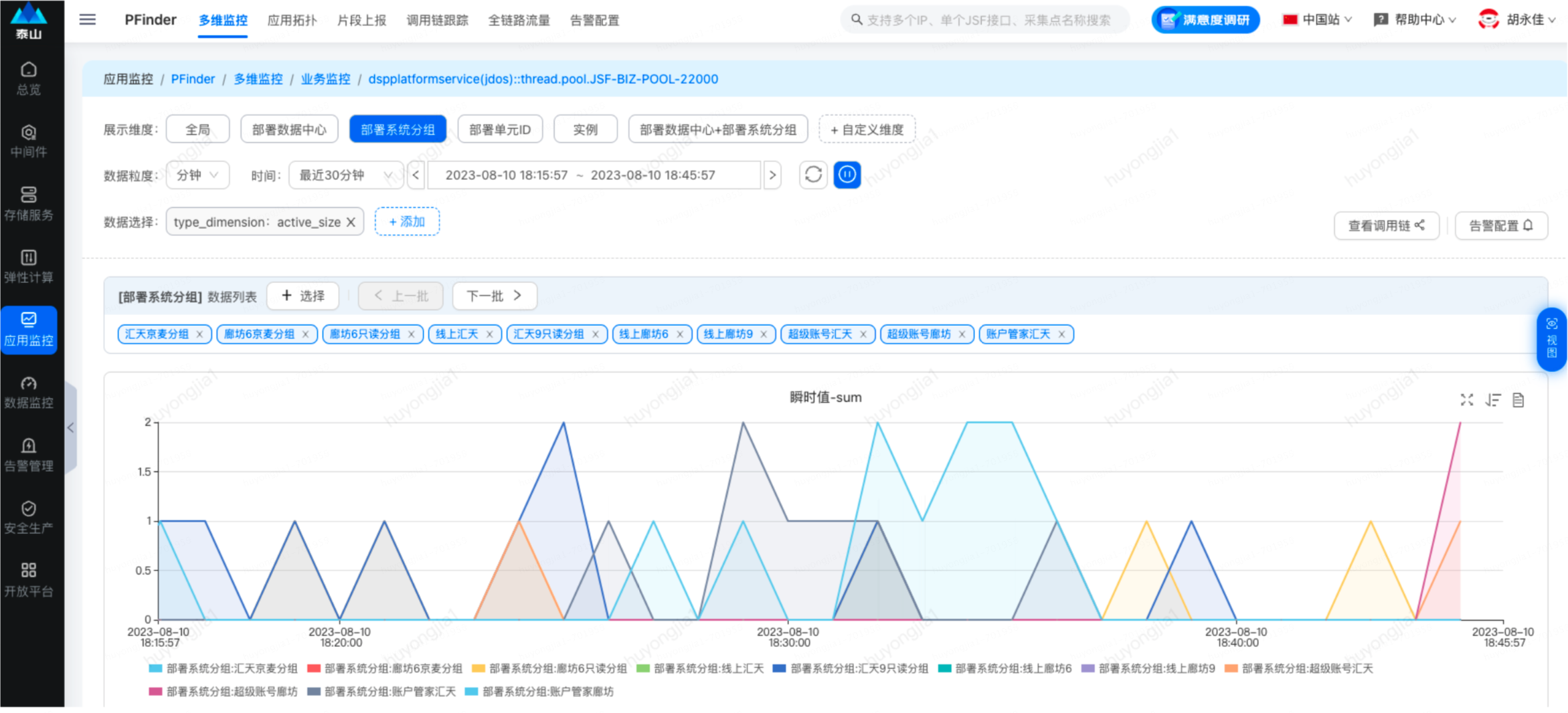
1.當(dāng)前監(jiān)控?cái)?shù)據(jù)為分鐘級(jí)維度,即按分鐘粒度展示線程池參數(shù)的瞬時(shí)值,如果需要更精細(xì)化的數(shù)據(jù),可以選擇pfinder的秒級(jí)監(jiān)控
2.支持監(jiān)控指標(biāo):
| 監(jiān)控指標(biāo) | 指標(biāo)值 |
| 線程池核心參數(shù) | core_size |
| 線程池最大線程參數(shù) | max_size |
| 當(dāng)前活躍線程數(shù) | active_size |
| 阻塞隊(duì)列容量(設(shè)置的大小) | queue_capacity |
| 阻塞隊(duì)列當(dāng)前大小(是否有排隊(duì)) | queue_size |
| 線程池完成任務(wù)數(shù) | completed_task_count |
此外,可以通過JSF接口查看當(dāng)前時(shí)刻應(yīng)用中的線程信息快照,當(dāng)前時(shí)刻被監(jiān)控的線程池有哪些:
感知異常告警
達(dá)成目的:及時(shí)感知線程池異常情況,避免問題放大
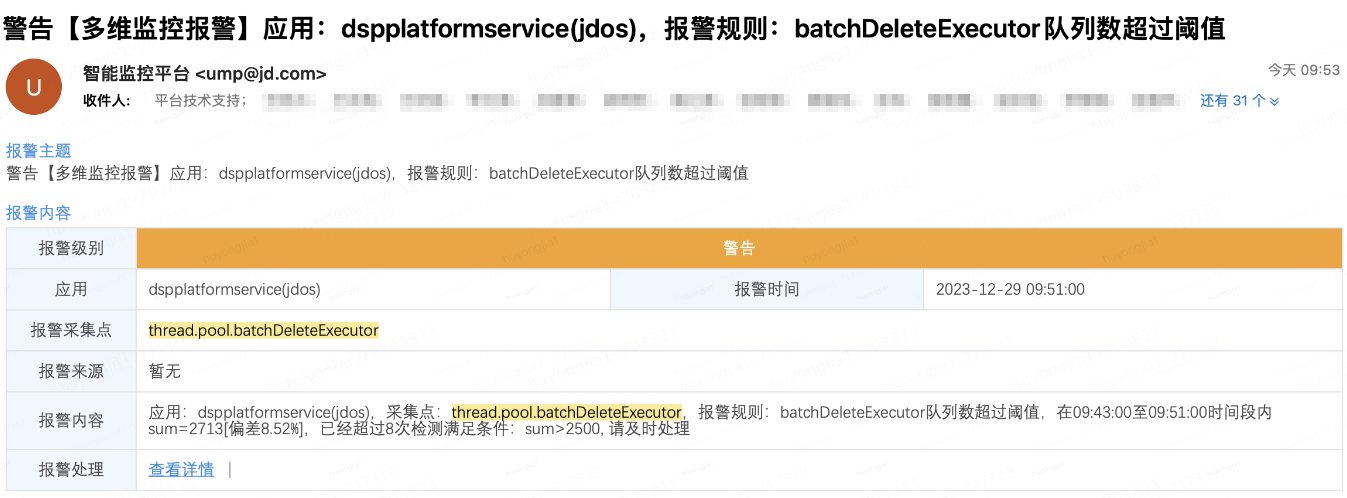
以隊(duì)列積壓和線程池拒絕告警為例
隊(duì)列積壓告警(郵件):
線程池拒絕告警(咚咚):

自動(dòng)觸發(fā)線程堆棧打印
達(dá)成目的:自動(dòng)記錄問題發(fā)生時(shí)的線程堆棧,為線程池拒絕異常排查提供思路,并加快問題定位
實(shí)踐案例1:
大促期間對(duì)核心接口的壓測(cè)途中,突然收到偶發(fā)機(jī)器的JSF線程池拒絕告警

實(shí)際分析發(fā)現(xiàn)拒絕時(shí)間較短,整體持續(xù)時(shí)間不到1分鐘
下圖因?yàn)榫€程不夠瞬間打上去的線程數(shù)持續(xù)時(shí)間
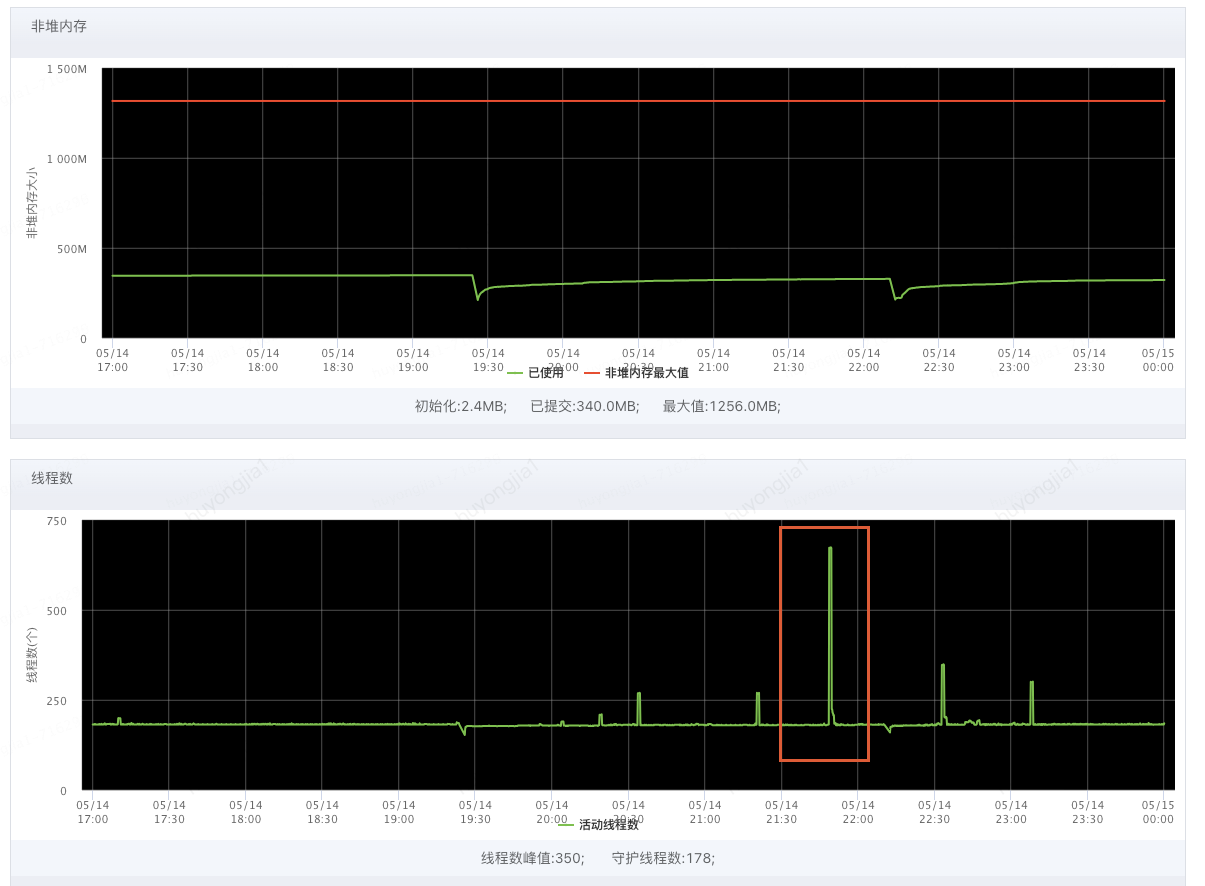
由此來看我們難以通過人工觸發(fā)jstack的方式在短時(shí)間內(nèi)獲取到問題發(fā)生時(shí)的線程堆棧,也因此無法定位到具體拒絕原因;因此我們嘗試借助線程池拒絕時(shí)自動(dòng)打印的線程堆棧分析,自動(dòng)打印機(jī)制會(huì)在線程池發(fā)生拒絕策略的同時(shí)將全局線程堆棧打印到機(jī)器對(duì)應(yīng)的日志目錄
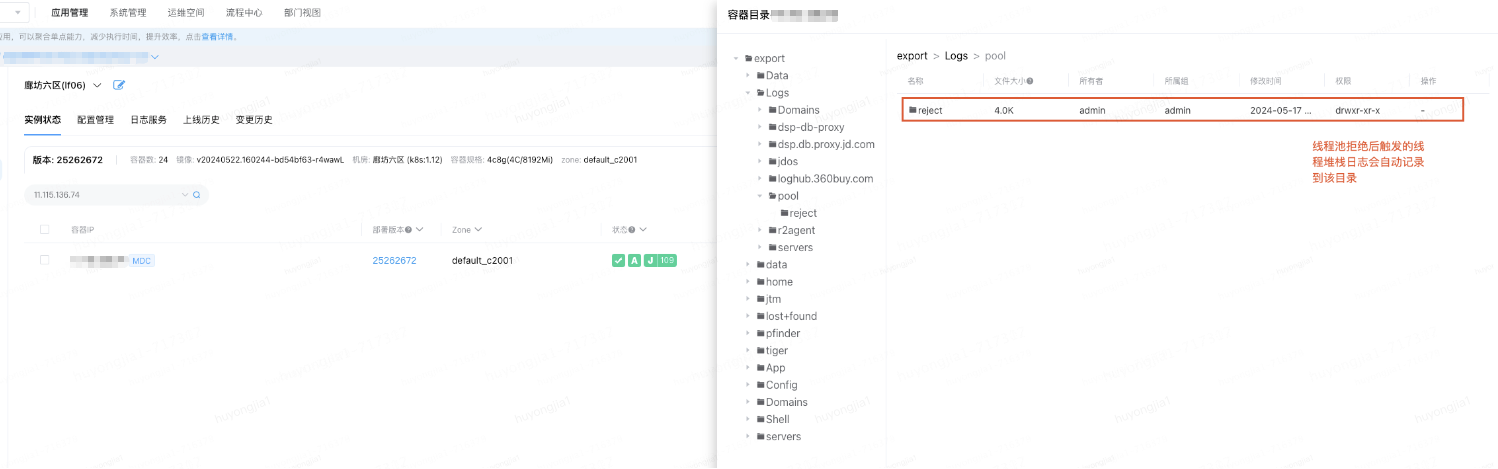
下圖為問題發(fā)生時(shí)自動(dòng)打印的堆棧日志
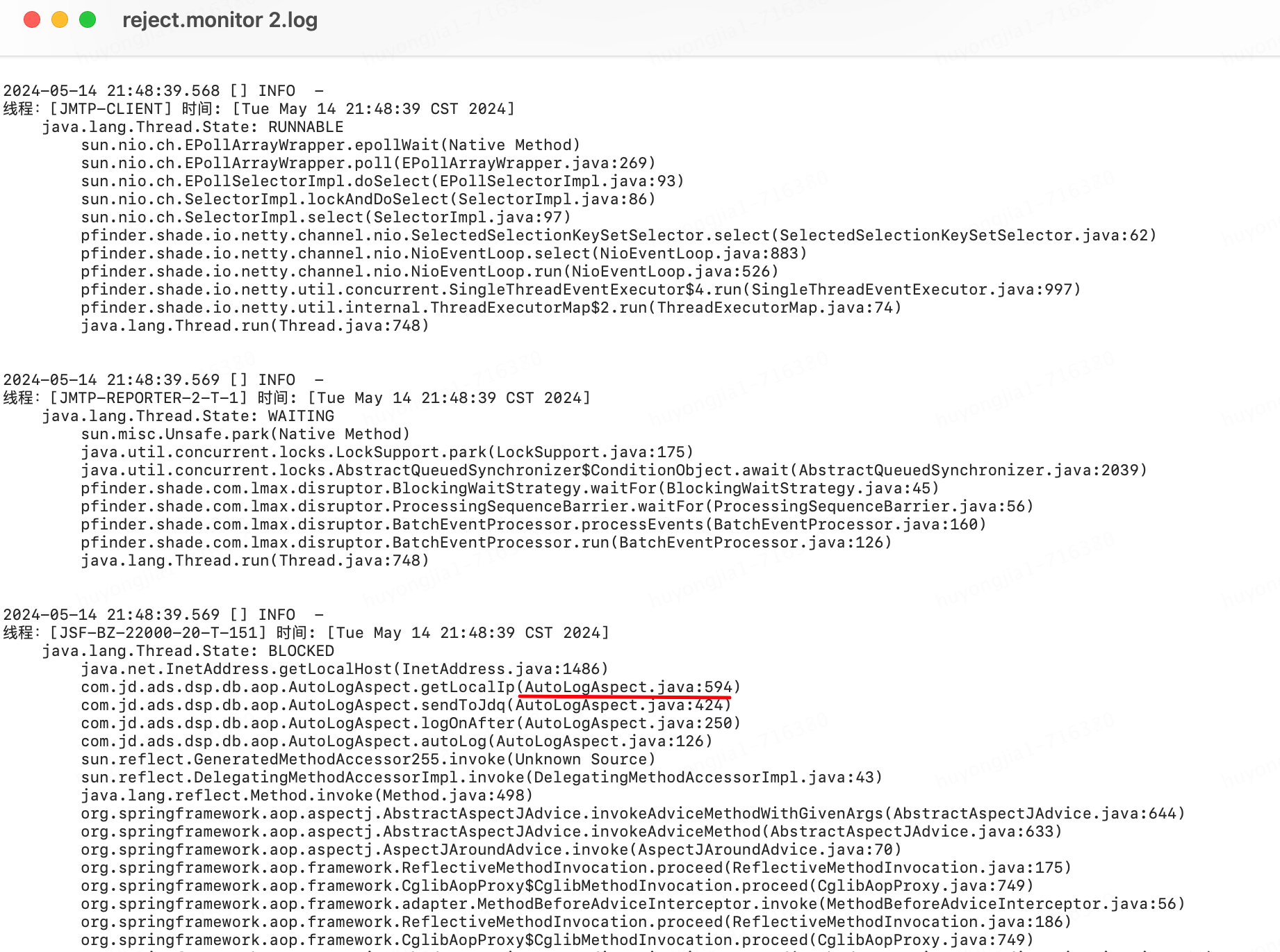




借助分析工具發(fā)現(xiàn)512個(gè)線程,511個(gè)都卡在了同一位置
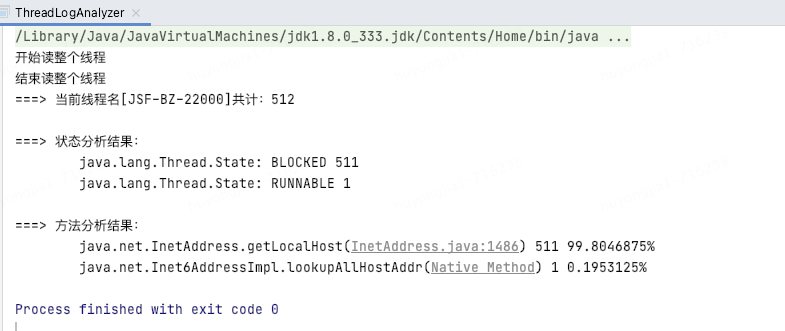
從堆棧和分析結(jié)果可以比較容易的定位到時(shí)哪里出現(xiàn)了問題,最終發(fā)現(xiàn)我們?cè)诿看斡涗涥P(guān)鍵日志時(shí)通過InetAddress.getLocalHost()方法獲取了本機(jī)ip,由于獲取的方法在特定情況下可能出現(xiàn)加鎖的情況,所以可能會(huì)先間歇性的線程阻塞;(網(wǎng)上相似案例:https://qa.1r1g.com/sf/ask/4489560281/)
實(shí)踐案例2:
業(yè)務(wù)中某線程池偶爾會(huì)出現(xiàn)線程池拒絕異常,同樣時(shí)間僅持續(xù)秒級(jí),報(bào)警信息如下

通過自動(dòng)觸發(fā)的線程堆棧進(jìn)行分析,發(fā)現(xiàn)該線程池中大量線程在拒絕時(shí)積壓在某接口的jsf調(diào)用等待上
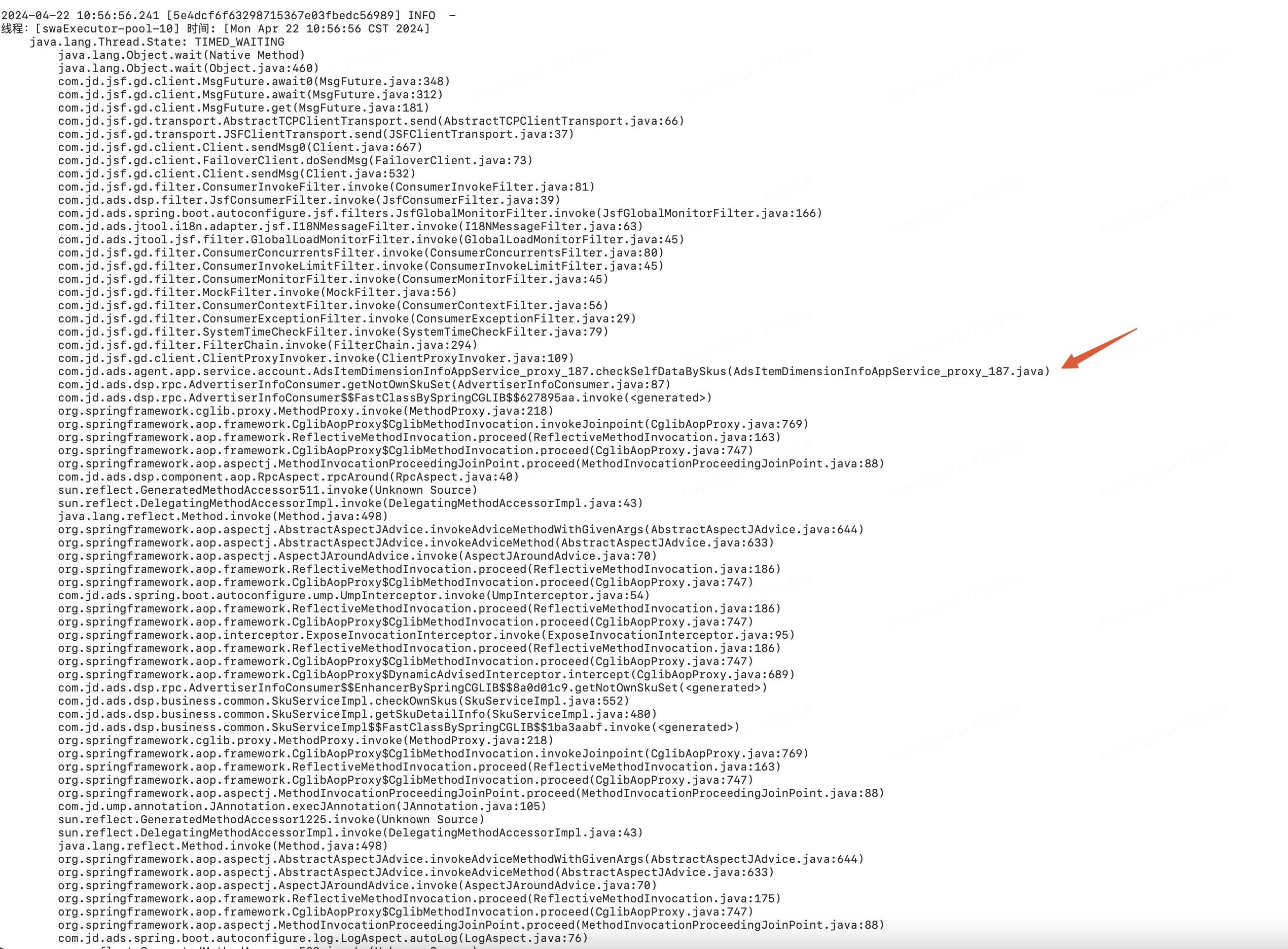
由此再結(jié)合方法監(jiān)控及日志可以比較容易定位到該時(shí)刻接口性能波動(dòng)導(dǎo)致
參數(shù)動(dòng)態(tài)刷新
達(dá)成目的:迅速修改線程池參數(shù),降低問題風(fēng)險(xiǎn)
如果需要對(duì)某線程池的參數(shù)做變更,只需將修改后的參數(shù)設(shè)置到ducc并重新發(fā)布即可
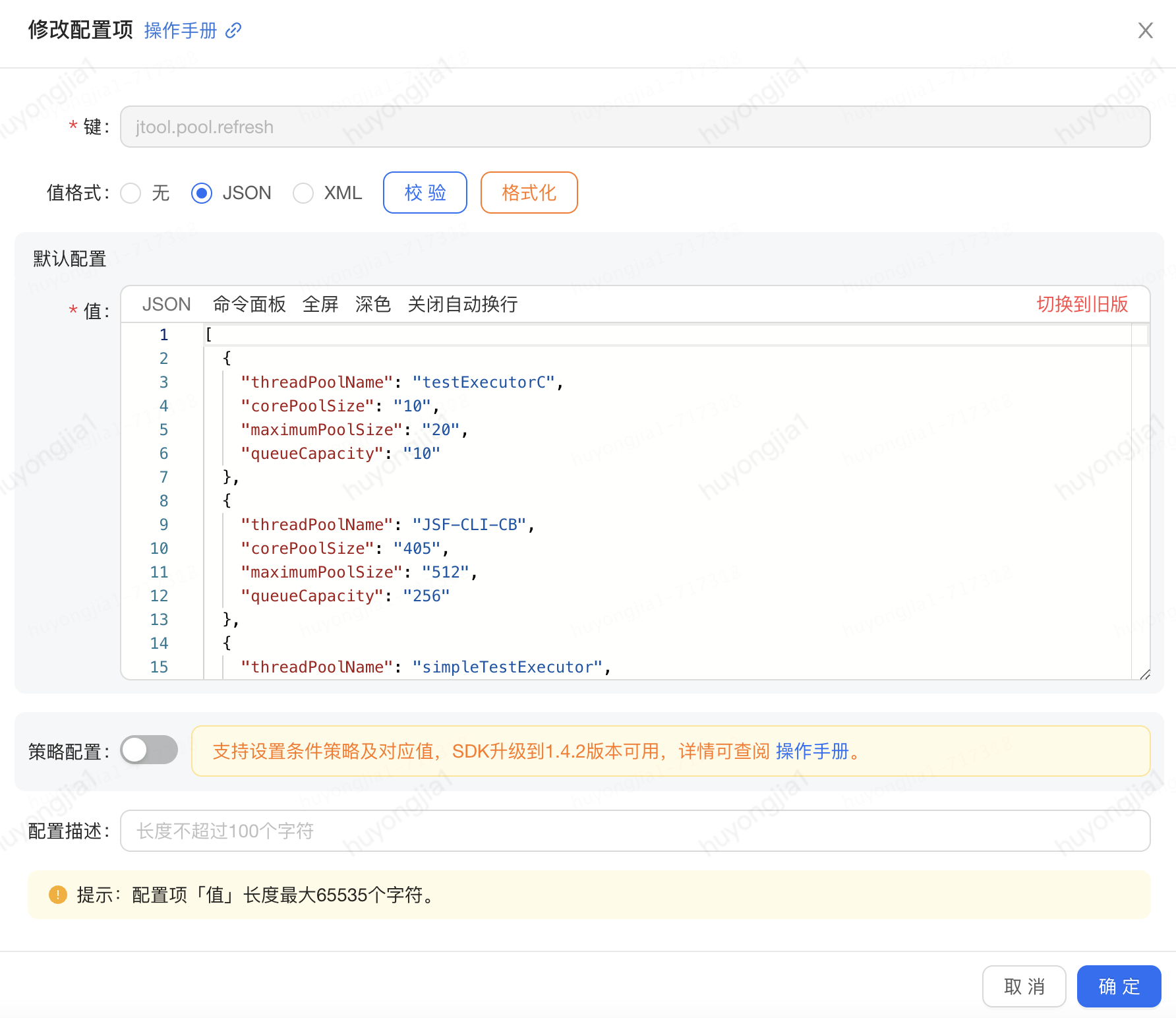
實(shí)踐案例:
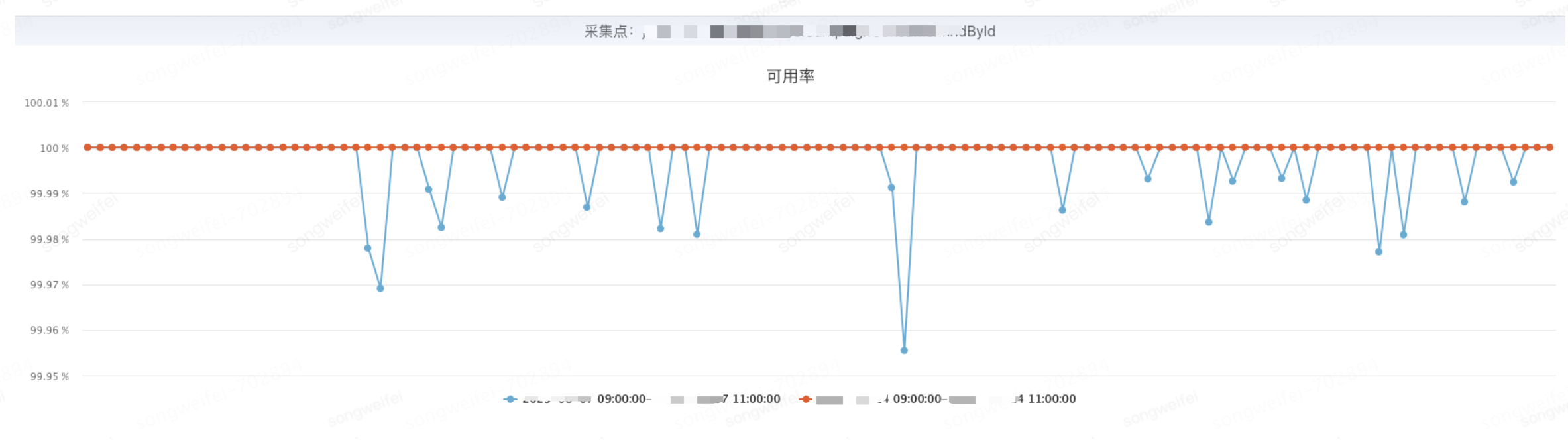
業(yè)務(wù)中部分場景從同步JSF調(diào)用改為異步后,可用率出現(xiàn)下降,通過分析發(fā)現(xiàn)是JSF的JSF-CLI-CB線程池設(shè)置較小,出現(xiàn)等待超時(shí)導(dǎo)致;借助動(dòng)態(tài)線程池的動(dòng)態(tài)配置能力修改對(duì)應(yīng)ducc發(fā)布后問題得到改善
調(diào)整前后對(duì)比
審核編輯 黃宇
-
監(jiān)控
+關(guān)注
關(guān)注
6文章
2312瀏覽量
57075 -
線程池
+關(guān)注
關(guān)注
0文章
57瀏覽量
7109
發(fā)布評(píng)論請(qǐng)先 登錄
C語言線程池的實(shí)現(xiàn)方案
Java中的線程池包括哪些
買藥秒送 JADE動(dòng)態(tài)線程池實(shí)踐及原理淺析
基于線程池技術(shù)集群接入點(diǎn)的應(yīng)用研究
基于Nacos的簡單動(dòng)態(tài)化線程池實(shí)現(xiàn)
多線程之線程池

線程池的線程怎么釋放
Spring 的線程池應(yīng)用
了解連接池、線程池、內(nèi)存池、異步請(qǐng)求池





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論