

NVIDIA Holoscan 是 NVIDIA 的跨領(lǐng)域多模態(tài)實時 AI 傳感器處理平臺,為開發(fā)者構(gòu)建端到端傳感器處理管線奠定了基礎(chǔ)。NVIDIA Holoscan SDK 的功能包括:
具有低延遲傳感器和網(wǎng)絡(luò)連接的組合硬件系統(tǒng)
專為數(shù)據(jù)處理和 AI 優(yōu)化的庫
靈活部署:邊緣或云端
Holoscan SDK 可用于為一系列行業(yè)和用例構(gòu)建流式 AI 管線,包括醫(yī)療設(shè)備、邊緣高性能計算和工業(yè)檢測等。欲了解更多信息,請參閱利用 NVIDIA Holoscan 1.0 開發(fā)生產(chǎn)就緒型 AI 傳感器處理應(yīng)用。
Holoscan SDK 利用軟硬件加速流式 AI 應(yīng)用。它可以與 RDMA 技術(shù)配合使用,通過 GPU 加速功能進一步提高端到端管線性能。端到端傳感器處理管線通常包括:
傳感器數(shù)據(jù)輸入
加速計算和 AI 推理
實時可視化、執(zhí)行和數(shù)據(jù)流出口
該管線中的所有數(shù)據(jù)均存儲在 GPU 內(nèi)存中,Holoscan 原生運算符無需進行主機-設(shè)備內(nèi)存?zhèn)鬏敚涂梢灾苯釉L問這些數(shù)據(jù)。

圖 1. 超聲波分割應(yīng)用的典型管線
本文將介紹如何通過集成 Holoscan SDK 和開源庫 OpenCV,實現(xiàn)無需額外內(nèi)存?zhèn)鬏數(shù)亩说蕉?GPU 加速工作流。
什么是 OpenCV?
OpenCV(開源計算機視覺庫)是一個綜合全面的開源計算機視覺庫。它包含 2500 多種算法,例如圖像和視頻處理、物體和人臉檢測,以及 OpenCV 深度學(xué)習(xí)模塊等。
OpenCV 支持 GPU 加速功能,包含一個 CUDA 模塊。該模塊提供了一組利用 CUDA 計算能力的類和函數(shù),它通過 NVIDIA CUDA 運行時 API 實現(xiàn),能夠提供各種實用功能、底層視覺原語和高級算法。
借助 OpenCV 提供的綜合全面的 GPU 加速算法和運算符,開發(fā)者可以基于 Holoscan SDK 實現(xiàn)更加復(fù)雜的管線(圖 2)。
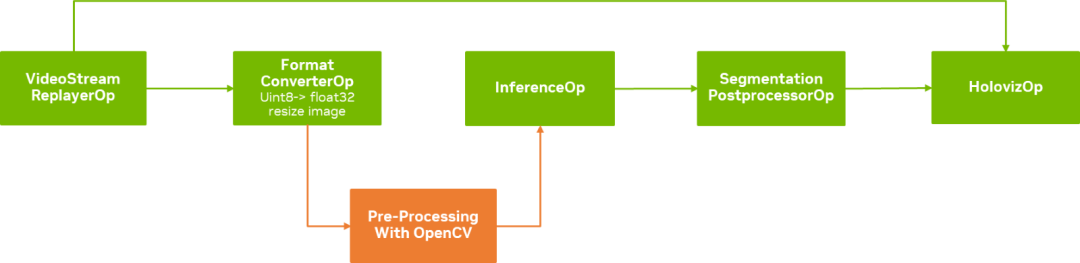
圖 2. 基于 OpenCV 和 Holoscan SDK
的增強型超聲波分割管線
在 Holoscan SDK 管線中
集成 OpenCV 運算符
如要開始在 Holoscan SDK 管線中集成 OpenCV 運算符,您需要滿足以下條件:
OpenCV >= 4.8.0
Holoscan SDK >= v0.6
如要安裝帶有 CUDA 模塊的 OpenCV,請遵循 opencv/opencv_contrib 提供的指南。如要使用 Holoscan SDK 和 OpenCV CUDA 構(gòu)建鏡像,請參閱 nvidia-holoscan/holohub Dockerfile:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/Dockerfile
張量是 Holoscan SDK 中的數(shù)據(jù)類型,它被定義為單一數(shù)據(jù)類型的多維元素數(shù)組。張量類是 DLManagedTensorCtx 結(jié)構(gòu)的包裝器,DLManagedTensorCtx 結(jié)構(gòu)持有 DLManagedTensor 對象。張量類支持 DLPack 和 NumPy 數(shù)組接口(__array_interface__ 和 __cuda_array_interface__),因此可以與其他 Python 庫(如 CuPy、PyTorch、JAX、TensorFlow 和 Numba)一起使用。
但 OpenCV 的數(shù)據(jù)類型是 GpuMat,它既沒有實現(xiàn) __cuda_array_interface_,也沒有實現(xiàn)標準 DLPack。如要實現(xiàn)端到端 GPU 加速管線或應(yīng)用,需要實現(xiàn)兩個函數(shù)來將 GpuMat 轉(zhuǎn)換為 CuPy 數(shù)組,后者可以直接使用 Holoscan Tensor 訪問,反之亦然。
從 GpuMat 到 CuPy
數(shù)組的無縫零拷貝
OpenCV Python 綁定的 GpuMat 對象提供了一個 cudaPtr 方法,該方法可用于訪問 GpuMat 對象的 GPU 內(nèi)存地址。該內(nèi)存指針可用于直接初始化 CuPy 數(shù)組,從而避免主機和設(shè)備之間發(fā)生不必要的數(shù)據(jù)傳輸,實現(xiàn)高效率的數(shù)據(jù)處理。
下面的函數(shù)用于從 GpuMat 創(chuàng)建 CuPy 數(shù)組。HoloHub 內(nèi)窺鏡深度估計應(yīng)用提供了源代碼。
importcv2
import cupy as cp
def?gpumat_to_cupy(gpu_mat:?cv2.cuda.GpuMat)?->?cp.ndarray:
????w,?h?=?gpu_mat.size()
????size_in_bytes?=?gpu_mat.step?*?w
????shapes = (h, w, gpu_mat.channels())
????assert?gpu_mat.channels()?<=3,?"Unsupported?GpuMat?channels"
????dtype?=?None
????if?gpu_mat.type()?in?[cv2.CV_8U,cv2.CV_8UC1,cv2.CV_8UC2,cv2.CV_8UC3]:
????????dtype?=?cp.uint8
????elif?gpu_mat.type()?==?cv2.CV_8S:
????????dtype?=?cp.int8
????elif?gpu_mat.type()?==?cv2.CV_16U:
????????dtype?=?cp.uint16
????elif?gpu_mat.type()?==?cv2.CV_16S:
????????dtype?=?cp.int16
????elif?gpu_mat.type()?==?cv2.CV_32S:
????????dtype?=?cp.int32
????elif?gpu_mat.type()?==?cv2.CV_32F:
????????dtype?=?cp.float32
????elif?gpu_mat.type()?==?cv2.CV_64F:
????????dtype?=?cp.float64?
assert?dtype?is?not?None,?"Unsupported?GpuMat?type"
????
????mem?=?cp.cuda.UnownedMemory(gpu_mat.cudaPtr(),?size_in_bytes,?owner=gpu_mat)
????memptr?=?cp.cuda.MemoryPointer(mem,?offset=0)
????cp_out = cp.ndarray(
shapes,
dtype=dtype,
memptr=memptr,
strides=(gpu_mat.step, gpu_mat.elemSize(), gpu_mat.elemSize1()),
)
????return?cp_out
請注意,我們在此函數(shù)中使用了非自有內(nèi)存 API 創(chuàng)建 CuPy 數(shù)組。在某些情況下,OpenCV 運算符會創(chuàng)建一個需要由 CuPy 處理的新設(shè)備內(nèi)存,其生命周期不限于一個運算符,而是整個管線。在這種情況下,從 GpuMat 啟動的 CuPy 數(shù)組會知道所有者并保留對對象的引用。更多詳情,請參閱 CuPy 互操作性文檔:
https://docs.cupy.dev/en/stable/user_guide/interoperability.html#device-memory-pointers
從 Holoscan Tensor 到
GpuMat 的無縫零拷貝
隨著 OpenCV 4.8 的發(fā)布,OpenCV 的 Python 綁定現(xiàn)在支持直接從 GPU 內(nèi)存指針初始化 GpuMat 對象。這一功能通過與 GPU 駐留數(shù)據(jù)直接交互,來提高數(shù)據(jù)整合和處理效率,避免了主機和設(shè)備內(nèi)存之間的數(shù)據(jù)傳輸。
在基于 Holoscan SDK 的管線應(yīng)用中,可以通過 CuPy 數(shù)組提供的 __cuda_array_interface__ 獲取 GPU 內(nèi)存指針。請參考下面概述的函數(shù),了解如何利用 CuPy 數(shù)組創(chuàng)建 GpuMat 對象。有關(guān)實現(xiàn)詳情,請參見HoloHub 內(nèi)窺鏡深度估計應(yīng)用中提供的源代碼:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/endoscopy_depth_estimation.py#L28
import?cv2
import?cupy?as?cp
def?gpumat_from_cp_array(arr:?cp.ndarray)?->?cv2.cuda.GpuMat:
????assert?len(arr.shape)?in?(2,?3),?"CuPy?array?must?have?2?or?3?dimensions?to?be?a?valid?GpuMat"
????type_map?=?{
????????cp.dtype('uint8'):?cv2.CV_8U,
????????cp.dtype('int8'):?cv2.CV_8S,
????????cp.dtype('uint16'):?cv2.CV_16U,
????????cp.dtype('int16'):?cv2.CV_16S,
????????cp.dtype('int32'):?cv2.CV_32S,
????????cp.dtype('float32'):?cv2.CV_32F,
????????cp.dtype('float64'):?cv2.CV_64F
????}
????depth?=?type_map.get(arr.dtype)
????assert?depth?is?not?None,?"Unsupported?CuPy?array?dtype"
????channels?=?1?if?len(arr.shape)?==?2?else?arr.shape[2]
????mat_type?=?depth?+?((channels?-?1)?<
整合 OpenCV 運算符
有了上述兩個函數(shù),您就可以在基于 Holoscan SDK 的管線中進行任何 OpenCV-CUDA 操作,而無需進行內(nèi)存?zhèn)鬏敗崿F(xiàn)步驟如下:
在調(diào)用 OpenCV 運算符的位置創(chuàng)建自定義運算符。詳情參見 Holoscan SDK 示例文檔:
https://docs.nvidia.com/holoscan/sdk-user-guide/holoscan_create_operator.html#creating-a-custom-operator-python
在運算符的計算函數(shù)中:
a.接收前一個運算符的信息,并從HoloscanTensor創(chuàng)建一個CuPy 數(shù)組
b.調(diào)用gpumat_from_cp_array以創(chuàng)建GpuMat
c.使用自定義OpenCV運算符進行處理
d.調(diào)用gpumat_to_cupy,從GpuMat創(chuàng)建CuPy數(shù)組
請看下面的演示代碼。完整的源代碼請參見 HoloHub 內(nèi)窺鏡深度估計應(yīng)用:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/endoscopy_depth_estimation.py#L161
defcompute(self,op_input,op_output,context):
stream = cv2.cuda_Stream()
message = op_input.receive("in")
cp_frame = cp.asarray(message.get("")) # CuPy array
cv_frame = gpumat_from_cp_array(cp_frame) # GPU OpenCV mat
## Call OpenCV Operator
cv_frame = cv2.cuda.XXX(hsv_merge, cv2.COLOR_HSV2RGB)
cp_frame = gpumat_to_cupy(cv_frame)
cp_frame = cp.ascontiguousarray(cp_frame)
out_message = Entity(context)
out_message.add(hs.as_tensor(cp_frame), "")
op_output.emit(out_message,"out")
總結(jié)
要將 OpenCV CUDA 運算符集成到基于 Holoscan SDK 構(gòu)建的應(yīng)用中,只需要實現(xiàn)兩個函數(shù)即可促成 OpenCV GpuMat 和 CuPy 數(shù)組間的轉(zhuǎn)換。借助這兩個函數(shù),您可以在自定義運算符中直接訪問 Holoscan Tensors。通過調(diào)用這些函數(shù),您可以無縫創(chuàng)建端到端 GPU 加速應(yīng)用,而不再需要通過內(nèi)存?zhèn)鬏攣硖岣咝阅堋?/p>
-
傳感器
+關(guān)注
關(guān)注
2561文章
52198瀏覽量
761645 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5188瀏覽量
105413 -
OpenCV
+關(guān)注
關(guān)注
31文章
642瀏覽量
42230
原文標題:在 NVIDIA Holoscan SDK 中使用 OpenCV 構(gòu)建零拷貝 AI 傳感器處理管線
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何使用SDK在獨立模式下的OpenCV應(yīng)用程序
NVIDIA Jetson的相關(guān)資料分享
NVIDIA DRIVE OS 5.2.6 Linux SDK發(fā)布 為加速計算和AI而設(shè)計
NVIDIA 發(fā)布適用于醫(yī)療設(shè)備和計算傳感系統(tǒng)的 AI 計算平臺

NVIDIA發(fā)布Clara Holoscan MGX醫(yī)療級平臺
使用Clara Holoscan SDK增強AI醫(yī)療設(shè)備流式處理工作流
使用 NVIDIA DeepStream SDK 6.2 順利開發(fā)視覺 AI 應(yīng)用
使用NVIDIA Holoscan for Media構(gòu)建下一代直播媒體應(yīng)用
利用NVIDIA Holoscan 1.0開發(fā)生產(chǎn)就緒型AI傳感器處理應(yīng)用
NVIDIA發(fā)布DeepStream 7.0,助力下一代視覺AI開發(fā)
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持,實現(xiàn)邊緣實時醫(yī)療、工業(yè)和科學(xué) AI 應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論