") matlab bp神經(jīng)網(wǎng)絡(luò)分析結(jié)果怎么看
matlab bp神經(jīng)網(wǎng)絡(luò)分析結(jié)果怎么看
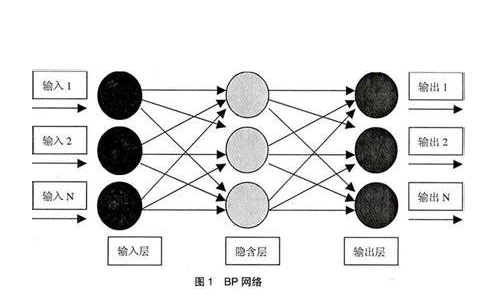
BP神經(jīng)網(wǎng)絡(luò)(Backpropagation Neural Network)是一種多層前饋神經(jīng)網(wǎng)絡(luò),其核心思想是通過(guò)反向傳播算法來(lái)調(diào)整網(wǎng)絡(luò)權(quán)重,使得網(wǎng)絡(luò)的輸出盡可能接近目標(biāo)值。在MATLAB中,可以使用內(nèi)置的神經(jīng)網(wǎng)絡(luò)工具箱來(lái)實(shí)現(xiàn)BP神經(jīng)網(wǎng)絡(luò)的構(gòu)建、訓(xùn)練和分析。
- 網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)
在進(jìn)行BP神經(jīng)網(wǎng)絡(luò)分析之前,首先需要設(shè)計(jì)合適的網(wǎng)絡(luò)結(jié)構(gòu)。網(wǎng)絡(luò)結(jié)構(gòu)主要包括輸入層、隱藏層和輸出層。輸入層的神經(jīng)元數(shù)量取決于問(wèn)題的特征維度,輸出層的神經(jīng)元數(shù)量取決于問(wèn)題的輸出維度。隱藏層的數(shù)量和神經(jīng)元數(shù)量則需要根據(jù)具體問(wèn)題進(jìn)行調(diào)整。
1.1 輸入層設(shè)計(jì)
輸入層的神經(jīng)元數(shù)量應(yīng)該與問(wèn)題的特征維度相等。例如,如果問(wèn)題的特征向量包含10個(gè)特征,則輸入層應(yīng)該有10個(gè)神經(jīng)元。輸入層的激活函數(shù)通常選擇線性函數(shù),即f(x) = x。
1.2 隱藏層設(shè)計(jì)
隱藏層的數(shù)量和神經(jīng)元數(shù)量對(duì)網(wǎng)絡(luò)的性能有很大影響。一般來(lái)說(shuō),隱藏層的數(shù)量可以根據(jù)問(wèn)題的復(fù)雜程度進(jìn)行選擇,通常為1-3層。每層隱藏層的神經(jīng)元數(shù)量可以根據(jù)問(wèn)題的規(guī)模和特征維度進(jìn)行調(diào)整。常用的方法有:
- 經(jīng)驗(yàn)法:根據(jù)問(wèn)題規(guī)模和經(jīng)驗(yàn)選擇合適的神經(jīng)元數(shù)量。
- 試錯(cuò)法:通過(guò)多次實(shí)驗(yàn),逐漸調(diào)整神經(jīng)元數(shù)量,找到最優(yōu)解。
- 信息論法:根據(jù)信息熵和互信息等指標(biāo)來(lái)確定神經(jīng)元數(shù)量。
1.3 輸出層設(shè)計(jì)
輸出層的神經(jīng)元數(shù)量取決于問(wèn)題的輸出維度。例如,如果問(wèn)題是二分類(lèi)問(wèn)題,則輸出層應(yīng)該有2個(gè)神經(jīng)元;如果是多分類(lèi)問(wèn)題,則輸出層應(yīng)該有類(lèi)別數(shù)個(gè)神經(jīng)元。輸出層的激活函數(shù)通常選擇softmax函數(shù),用于將輸出值轉(zhuǎn)換為概率分布。
- 訓(xùn)練過(guò)程
在設(shè)計(jì)好網(wǎng)絡(luò)結(jié)構(gòu)后,接下來(lái)需要進(jìn)行訓(xùn)練。訓(xùn)練過(guò)程主要包括數(shù)據(jù)預(yù)處理、網(wǎng)絡(luò)初始化、訓(xùn)練算法選擇和訓(xùn)練參數(shù)設(shè)置等步驟。
2.1 數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理是訓(xùn)練前的重要步驟,包括歸一化、去中心化、特征選擇等操作。歸一化可以將數(shù)據(jù)縮放到[0,1]或[-1,1]的范圍內(nèi),有助于提高訓(xùn)練速度和收斂性。去中心化是將數(shù)據(jù)的均值調(diào)整為0,有助于提高網(wǎng)絡(luò)的泛化能力。特征選擇則是從原始數(shù)據(jù)中選擇對(duì)問(wèn)題有貢獻(xiàn)的特征,減少噪聲和冗余。
2.2 網(wǎng)絡(luò)初始化
網(wǎng)絡(luò)初始化是為網(wǎng)絡(luò)的權(quán)重和偏置賦予初始值的過(guò)程。權(quán)重和偏置的初始值對(duì)網(wǎng)絡(luò)的訓(xùn)練和性能有很大影響。常用的初始化方法有:
- 隨機(jī)初始化:為權(quán)重和偏置賦予小的隨機(jī)值。
- 正態(tài)分布初始化:為權(quán)重和偏置賦予正態(tài)分布的值。
- 均勻分布初始化:為權(quán)重和偏置賦予均勻分布的值。
2.3 訓(xùn)練算法選擇
BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練算法主要有梯度下降法、共軛梯度法、Levenberg-Marquardt算法等。梯度下降法是最常用的訓(xùn)練算法,其核心思想是通過(guò)計(jì)算損失函數(shù)的梯度來(lái)更新網(wǎng)絡(luò)權(quán)重。共軛梯度法和Levenberg-Marquardt算法則是在梯度下降法的基礎(chǔ)上進(jìn)行改進(jìn),以提高訓(xùn)練速度和收斂性。
2.4 訓(xùn)練參數(shù)設(shè)置
訓(xùn)練參數(shù)主要包括學(xué)習(xí)率、迭代次數(shù)、目標(biāo)誤差等。學(xué)習(xí)率決定了權(quán)重更新的幅度,過(guò)小的學(xué)習(xí)率會(huì)導(dǎo)致訓(xùn)練速度慢,過(guò)大的學(xué)習(xí)率則可能導(dǎo)致訓(xùn)練不收斂。迭代次數(shù)決定了訓(xùn)練的輪數(shù),過(guò)多的迭代次數(shù)會(huì)增加訓(xùn)練時(shí)間,過(guò)少的迭代次數(shù)則可能導(dǎo)致訓(xùn)練不充分。目標(biāo)誤差則是訓(xùn)練過(guò)程中的停止條件,當(dāng)損失函數(shù)的值小于目標(biāo)誤差時(shí),訓(xùn)練停止。
- 結(jié)果評(píng)估
在訓(xùn)練完成后,需要對(duì)網(wǎng)絡(luò)的性能進(jìn)行評(píng)估。常用的評(píng)估指標(biāo)有準(zhǔn)確率、召回率、F1分?jǐn)?shù)、ROC曲線等。
3.1 準(zhǔn)確率
準(zhǔn)確率是最常用的評(píng)估指標(biāo),表示分類(lèi)正確的樣本數(shù)占總樣本數(shù)的比例。計(jì)算公式為:
準(zhǔn)確率 = 正確分類(lèi)的樣本數(shù) / 總樣本數(shù)
3.2 召回率
召回率表示分類(lèi)為正類(lèi)的樣本中,實(shí)際為正類(lèi)的比例。計(jì)算公式為:
召回率 = 正確分類(lèi)為正類(lèi)的樣本數(shù) / 實(shí)際為正類(lèi)的樣本數(shù)
3.3 F1分?jǐn)?shù)
F1分?jǐn)?shù)是準(zhǔn)確率和召回率的調(diào)和平均值,用于衡量模型的平衡性。計(jì)算公式為:
F1分?jǐn)?shù) = 2 * (準(zhǔn)確率 * 召回率) / (準(zhǔn)確率 + 召回率)
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7002瀏覽量
88943 -
BP神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
2文章
115瀏覽量
30549 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4327瀏覽量
62573 -
神經(jīng)元
+關(guān)注
關(guān)注
1文章
363瀏覽量
18449
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MATLAB神經(jīng)網(wǎng)絡(luò)工具箱函數(shù)
用matlab編程進(jìn)行BP神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)時(shí)如何確定最合適的,BP模型
關(guān)于BP神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)模型的確定!!
關(guān)于開(kāi)關(guān)磁阻電機(jī)的matlab BP神經(jīng)網(wǎng)絡(luò)數(shù)學(xué)建模方面的資料
labview BP神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)
基于BP神經(jīng)網(wǎng)絡(luò)的手勢(shì)識(shí)別系統(tǒng)
【案例分享】基于BP算法的前饋神經(jīng)網(wǎng)絡(luò)
基于BP神經(jīng)網(wǎng)絡(luò)的PID控制
BP神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)實(shí)例(MATLAB編程)
BP神經(jīng)網(wǎng)絡(luò)概述

BP神經(jīng)網(wǎng)絡(luò)的簡(jiǎn)單MATLAB實(shí)例免費(fèi)下載





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論