


神經網絡擬合誤差分析是一個復雜且深入的話題,涉及到多個方面,需要從數據質量、模型結構、訓練過程和正則化方法等多個角度進行綜合考慮。
- 引言
神經網絡是一種強大的機器學習模型,廣泛應用于各種領域,如圖像識別、自然語言處理和時間序列預測等。然而,神經網絡的擬合誤差是一個關鍵問題,影響模型的性能和泛化能力。本文將從多個角度分析神經網絡擬合誤差的原因、影響因素和解決方案。 - 神經網絡基本原理
在分析神經網絡擬合誤差之前,我們需要了解神經網絡的基本原理。神經網絡由多個層次的神經元組成,每個神經元通過權重和偏置與前一層的神經元相連。通過前向傳播和反向傳播算法,神經網絡可以學習輸入數據與輸出數據之間的映射關系。 - 神經網絡擬合誤差的來源
神經網絡擬合誤差主要來源于以下幾個方面:
a. 數據質量問題:數據的噪聲、異常值和不平衡分布會影響神經網絡的擬合效果。
b. 模型結構問題:神經網絡的層數、神經元數量和激活函數等結構參數會影響模型的擬合能力。
c. 訓練過程問題:學習率、批次大小、迭代次數等訓練參數會影響模型的收斂速度和擬合效果。
d. 正則化方法:為了防止過擬合,神經網絡通常采用L1、L2正則化或Dropout等方法,但過度正則化可能導致欠擬合。
- 神經網絡擬合誤差的評估方法
評估神經網絡擬合誤差的方法有很多,主要包括:
a. 均方誤差(MSE):計算預測值與真實值之間的平方差的平均值。
b. 均方根誤差(RMSE):MSE的平方根,用于衡量預測值與真實值之間的偏差。
c. 絕對平均誤差(MAE):計算預測值與真實值之間的絕對差的平均值。
d. R-squared:衡量模型解釋的方差與總方差的比例,用于評估模型的解釋能力。
- 神經網絡擬合誤差的影響因素分析
神經網絡擬合誤差的影響因素包括:
a. 數據預處理:數據標準化、歸一化和特征選擇等預處理方法會影響模型的擬合效果。
b. 模型初始化:權重和偏置的初始值會影響模型的收斂速度和擬合效果。
c. 優化算法:梯度下降、Adam、RMSprop等優化算法的選擇會影響模型的訓練效果。
d. 超參數調整:通過網格搜索、隨機搜索或貝葉斯優化等方法調整超參數,可以找到最優的模型結構和訓練參數。
- 神經網絡擬合誤差的解決方案
針對神經網絡擬合誤差,可以采取以下解決方案:
a. 數據增強:通過數據增強方法,如旋轉、縮放、翻轉等,增加數據的多樣性,提高模型的泛化能力。
b. 模型集成:通過模型集成方法,如Bagging、Boosting和Stacking,提高模型的預測準確性。
c. 早停法(Early Stopping):在訓練過程中,當驗證集的誤差不再降低時,提前終止訓練,避免過擬合。
d. 正則化技術:合理使用L1、L2正則化或Dropout等正則化技術,平衡模型的擬合能力和泛化能力。
- 案例分析
通過具體的案例分析,展示神經網絡擬合誤差的分析方法和解決方案。例如,使用MNIST數據集進行手寫數字識別任務,分析不同模型結構、訓練參數和正則化方法對擬合誤差的影響。 - 結論
神經網絡擬合誤差分析是一個多方面的問題,需要從數據質量、模型結構、訓練過程和正則化方法等多個角度進行綜合考慮。通過合理的數據預處理、模型初始化、優化算法選擇和超參數調整,可以有效降低擬合誤差,提高模型的預測性能和泛化能力。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103734 -
模型
+關注
關注
1文章
3522瀏覽量
50452 -
機器學習
+關注
關注
66文章
8505瀏覽量
134677 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14169
發布評論請先 登錄
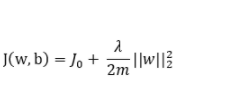





 工商網監
工商網監

評論