") 化工廠液體泄漏識(shí)別預(yù)警算法
化工廠液體泄漏識(shí)別預(yù)警算法
化工廠液體泄漏識(shí)別預(yù)警基于圖像識(shí)別算法是計(jì)算機(jī)視覺(jué)的基礎(chǔ)算法,例如VGG,GoogLeNet,ResNet等,化工廠液體泄漏識(shí)別這類(lèi)算法主要是判斷圖片中目標(biāo)的種類(lèi)液體泄漏識(shí)別預(yù)警自動(dòng)識(shí)別監(jiān)控視頻中機(jī)械管道是否存在液體泄漏行為。如檢測(cè)到液體泄漏,立即反饋給后臺(tái)人員及時(shí)處理。
要對(duì)圖片中一個(gè)物體進(jìn)行分類(lèi),首先要解決如何從圖片中發(fā)現(xiàn)這個(gè)物體,最直觀的方法就是用不同尺寸的方框進(jìn)行掃描,這個(gè)方框可以被稱(chēng)為window,和要得到的物體尺寸是兩回事。這就是RNN的方法,但這種方法計(jì)算量大,因此出現(xiàn)了Yolo,其核心思想就體現(xiàn)在如何從一張圖像準(zhǔn)確獲取目標(biāo)的方法上。
至于目標(biāo)檢測(cè)的用處,現(xiàn)在最大的場(chǎng)景就是無(wú)人駕駛,在無(wú)人駕駛中,需要實(shí)時(shí)檢測(cè)出途中的人、車(chē)、物體、信號(hào)燈、交通標(biāo)線等,再通過(guò)融合技術(shù)將各類(lèi)傳感器獲得的數(shù)據(jù)提供給控制中心進(jìn)行決策。而目標(biāo)檢測(cè)相當(dāng)于無(wú)人駕駛系統(tǒng)的眼睛。在目標(biāo)檢測(cè)技術(shù)領(lǐng)域,有包含region proposals提取階段的兩階段(two-stage)檢測(cè)框架如R-CNN/Fast-RCNN/R-FCN等。
卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練與硬件加速器實(shí)現(xiàn)圖像識(shí)別系統(tǒng)的第二部分是 CNN 加速器,CNN 加速器的實(shí)現(xiàn)包含訓(xùn)練與推理兩個(gè)階段。一是卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練,提取相應(yīng)的權(quán)重值和偏置值,即訓(xùn)練階段。二是根據(jù)網(wǎng)絡(luò)模型實(shí)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò),并做硬件加速,提升卷積神經(jīng)網(wǎng)絡(luò)運(yùn)算的速率,即推理階段。CNN 網(wǎng)絡(luò)訓(xùn)練完畢后,采用 PyTorch 神經(jīng)網(wǎng)絡(luò)框架將卷積神經(jīng)網(wǎng)絡(luò)模型及其參數(shù)保存在pt 文件中。而 PyTorch 神經(jīng)網(wǎng)絡(luò)框架提供了 load 方法,可以很方便地讀取文件中保存的參數(shù),但輸出格式為張量,無(wú)法直接使用。故先轉(zhuǎn)換為 Numpy[61]的數(shù)據(jù)格式,再提取其中的參數(shù),以固定的格式保存數(shù)據(jù)。
class Detect(nn.Module): stride = None # strides computed during build onnx_dynamic = False # ONNX export parameter def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer super().__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid
-
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
520瀏覽量
38267 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238264 -
預(yù)警
+關(guān)注
關(guān)注
1文章
46瀏覽量
14466
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
藍(lán)牙人員定位在化工廠實(shí)際應(yīng)用效果

化工廠過(guò)程儀表的維護(hù)與校準(zhǔn)
煤化工廠人員定位系統(tǒng)解決方案
化工廠如何實(shí)現(xiàn)人員定位及軌跡管理?
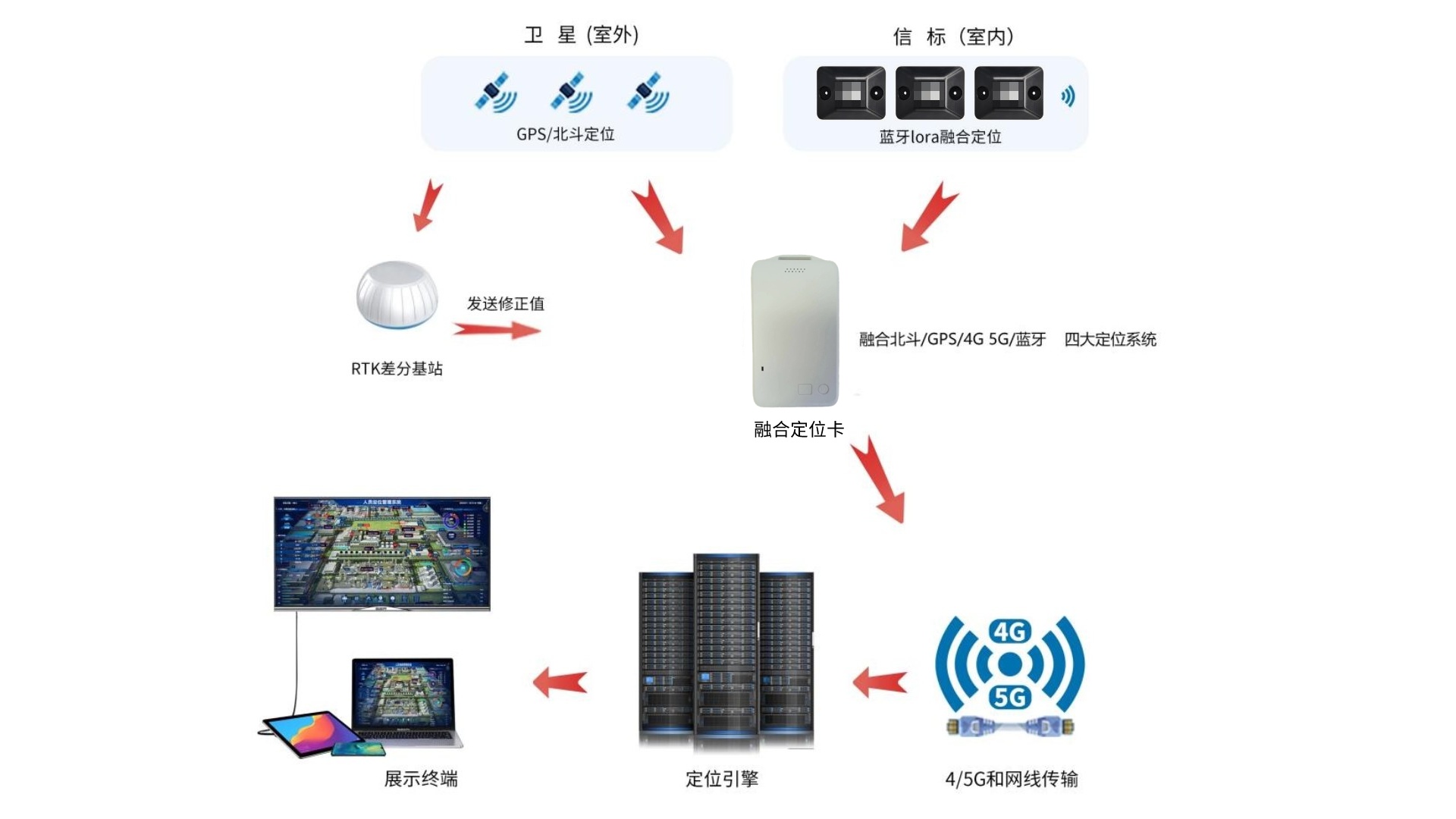
化工廠室內(nèi)外4G/5G+藍(lán)牙+GPS/北斗RTK人員定位系統(tǒng)解決方案
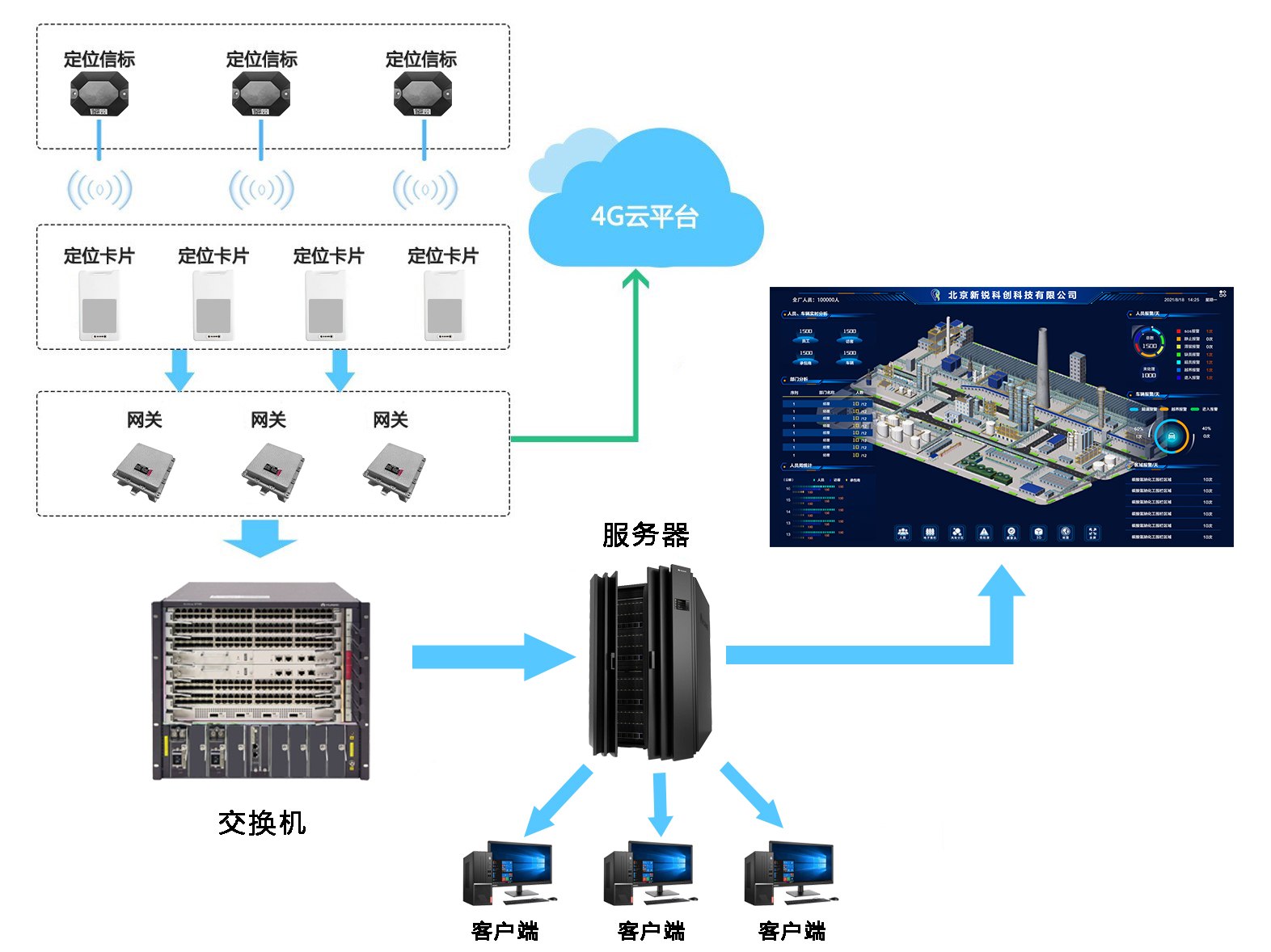
化工廠精確人員定位系統(tǒng)解決方案
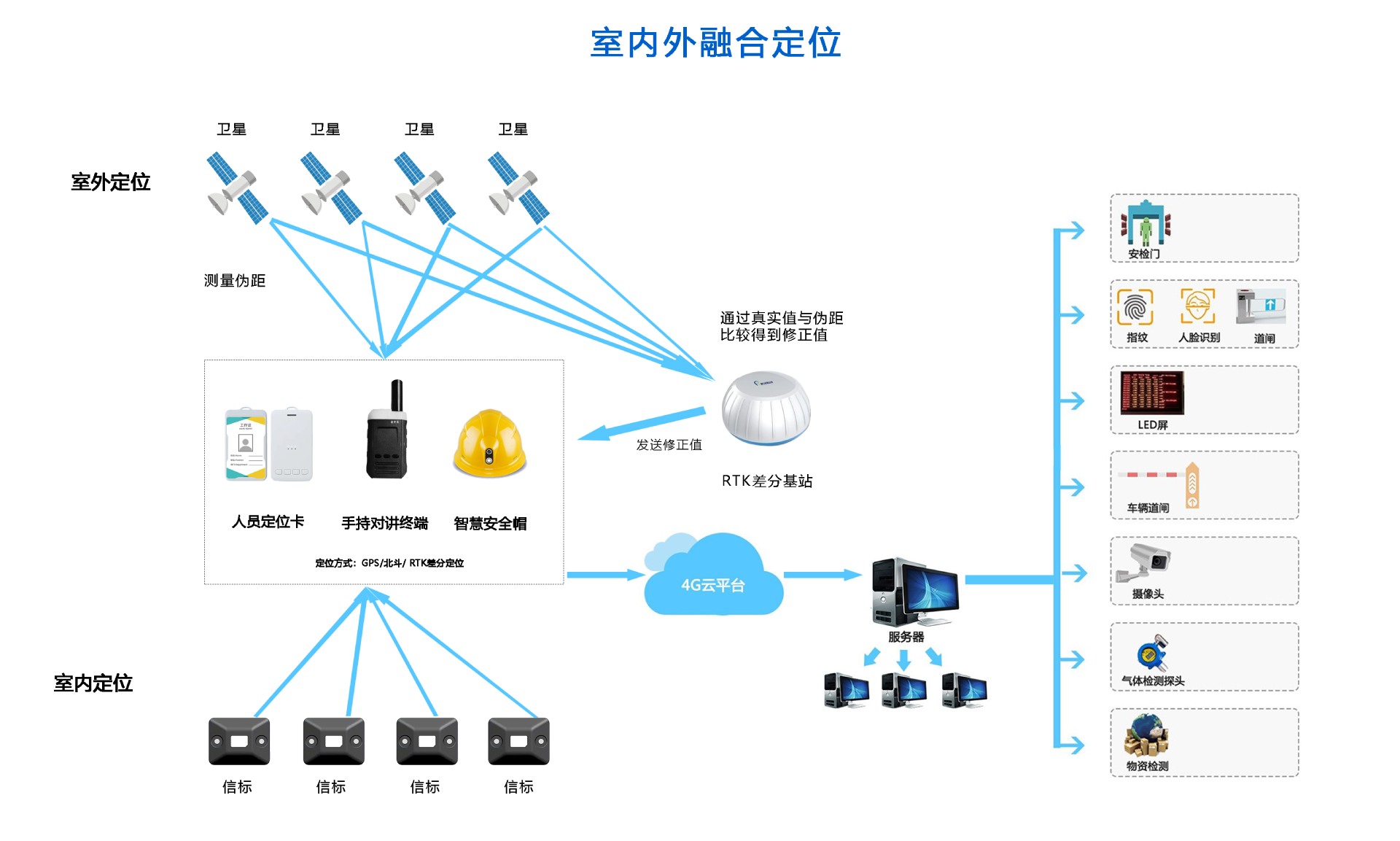
化工廠藍(lán)牙+GPS 北斗RTK人員定位系統(tǒng)解決方案
化工廠人員定位系統(tǒng)應(yīng)遵循哪些原則?答案在這里!
人員定位系統(tǒng)可以解決化工廠哪些管理薄弱點(diǎn)?
化工廠定位的解決方案是什么?可以解決哪些難題
防爆巡檢終端在石化工廠安全保障中的應(yīng)用

化工廠防爆對(duì)講機(jī)應(yīng)用方案

化工廠環(huán)境監(jiān)測(cè)系統(tǒng)是什么
盤(pán)古信息助力PCB企業(yè)構(gòu)建智能化工廠 引領(lǐng)產(chǎn)業(yè)變革的未來(lái)之路





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論