") 大象機(jī)器人開源協(xié)作機(jī)械臂機(jī)械臂接入GPT4o大模型!
大象機(jī)器人開源協(xié)作機(jī)械臂機(jī)械臂接入GPT4o大模型!
本文已經(jīng)或者同濟(jì)子豪兄作者授權(quán)對(duì)文章進(jìn)行編輯和轉(zhuǎn)載
引言
隨著人工智能和機(jī)器人技術(shù)的快速發(fā)展,機(jī)械臂在工業(yè)、醫(yī)療和服務(wù)業(yè)等領(lǐng)域的應(yīng)用越來越廣泛。通過結(jié)合大模型和多模態(tài)AI,機(jī)械臂能夠?qū)崿F(xiàn)更加復(fù)雜和智能化的任務(wù),提升了人機(jī)協(xié)作的效率和效果。我們個(gè)人平時(shí)接觸不太到機(jī)械臂這類的機(jī)器人產(chǎn)品,但是有一種小型的機(jī)械臂我們?nèi)巳硕伎梢該碛兴黰yCobot,價(jià)格低廉的一種桌面型機(jī)械臂。
案例介紹
本文介紹同濟(jì)子豪兄開源的一個(gè)名為“vlm_arm”項(xiàng)目,這個(gè)項(xiàng)目中將mycobot 機(jī)械臂與大模型和多模態(tài)AI結(jié)合,創(chuàng)造了一個(gè)具身智能體。該項(xiàng)目展示了如何利用先進(jìn)的AI技術(shù)提高機(jī)械臂的自動(dòng)化和智能化水平。本文的目的是通過詳細(xì)介紹該案例的方法和成功,展示機(jī)械臂具身智能體的實(shí)際應(yīng)用。
產(chǎn)品介紹
myCobot 280 Pi
myCobot 280 Pi是一款6自由度的桌面型機(jī)械臂,主要的控制核心是Raspberry Pi 4B,輔助控制核心是ESP32,同時(shí)配備了 Ubuntu Mate 20.04 操作系統(tǒng)和豐富的開發(fā)環(huán)境。這使得 myCobot 280 Pi 在無需外接 PC 的情況下,只需連接顯示器、鍵盤和鼠標(biāo)即可進(jìn)行開發(fā)。

這款機(jī)械臂重量輕,尺寸小,具有多種軟硬件交互功能,兼容多種設(shè)備接口。它支持多平臺(tái)的二次開發(fā),適用于人工智能相關(guān)學(xué)科教育、個(gè)人創(chuàng)意開發(fā)、商業(yè)應(yīng)用探索等多種應(yīng)用場景。
Camera Flange 2.0
在案例中使用到的攝像頭,通過usb數(shù)據(jù)線跟raspberry pi鏈接,可以獲取到圖像來進(jìn)行機(jī)器視覺的處理。

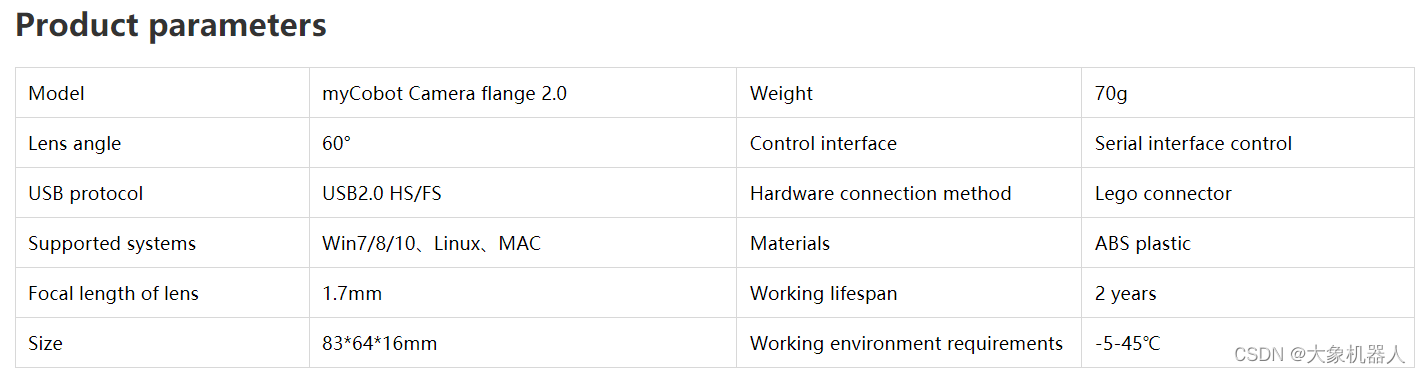
Suction Pump 2.0
吸泵,工作原理通過電磁閥抽空起造成壓強(qiáng)差然后將物體吸起來。通過IO接口鏈接機(jī)械臂,用pymycobot 的API進(jìn)行控制吸泵的開關(guān)。

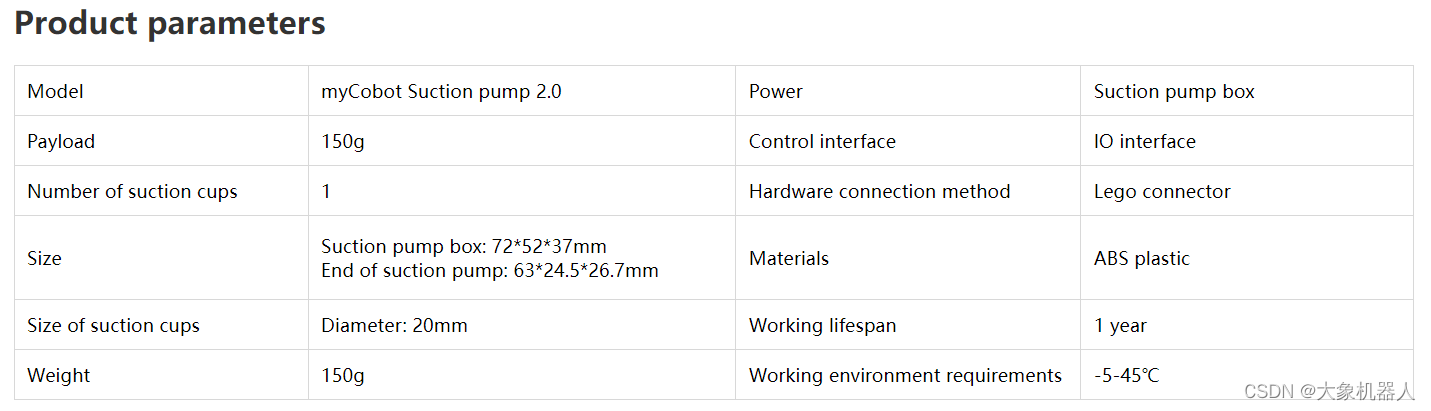
機(jī)械臂的末端都是通過LEGO連接件連接起來的,所以它們之間可以很方便的連接起來不需要額外的結(jié)構(gòu)件。

技術(shù)介紹
整個(gè)的案例將在python環(huán)境中進(jìn)行編譯,下面講介紹使用到的庫。
pymycobot:
elephant robotics編寫的對(duì)myCobot 控制的python庫,可以通過坐標(biāo),角度來控制機(jī)械臂的運(yùn)動(dòng),也可以控制官方適配的末端執(zhí)行器例如夾爪,吸泵的運(yùn)動(dòng)。
Yi-Large:
Yi-large 是由中國人工智能公司 01.AI 開發(fā)的大型語言模型,擁有超過 1000 億參數(shù)。Yi-large 使用了一種叫做“Transformer”的架構(gòu),并對(duì)其進(jìn)行了改進(jìn),使其在處理語言和視覺任務(wù)時(shí)表現(xiàn)得更好。
Claude 3 Opus:
該模型還展示了強(qiáng)大的多語言處理能力和改進(jìn)的視覺分析功能,能夠進(jìn)行圖像的轉(zhuǎn)錄和分析。此外,Claude 3 Opus 被設(shè)計(jì)為更具責(zé)任感和安全性,減少了偏見和隱私問題,確保其輸出更加可信和中立。
AppBuilder-SDK:
AppBuilder-SDK 的功能非常廣泛,包含了諸如語音識(shí)別、自然語言處理、圖像識(shí)別等AI能力組件 (Read the Docs) 。具體來說,它包括了短語音識(shí)別、通用文字識(shí)別、文檔解析、表格抽取、地標(biāo)識(shí)別、問答對(duì)挖掘等多個(gè)組件 (Read the Docs) (GitHub) 。這些功能使開發(fā)者可以構(gòu)建從基礎(chǔ)AI功能到復(fù)雜應(yīng)用的各種項(xiàng)目,提升開發(fā)效率。
該案例中提到了很多的大語言模型,都是可以自行去測試每個(gè)大語言輸出的不同的結(jié)果如何。
項(xiàng)目結(jié)構(gòu)
介紹項(xiàng)目之前必須得介紹一下項(xiàng)目的構(gòu)成,制作了一張流程圖方便理解。
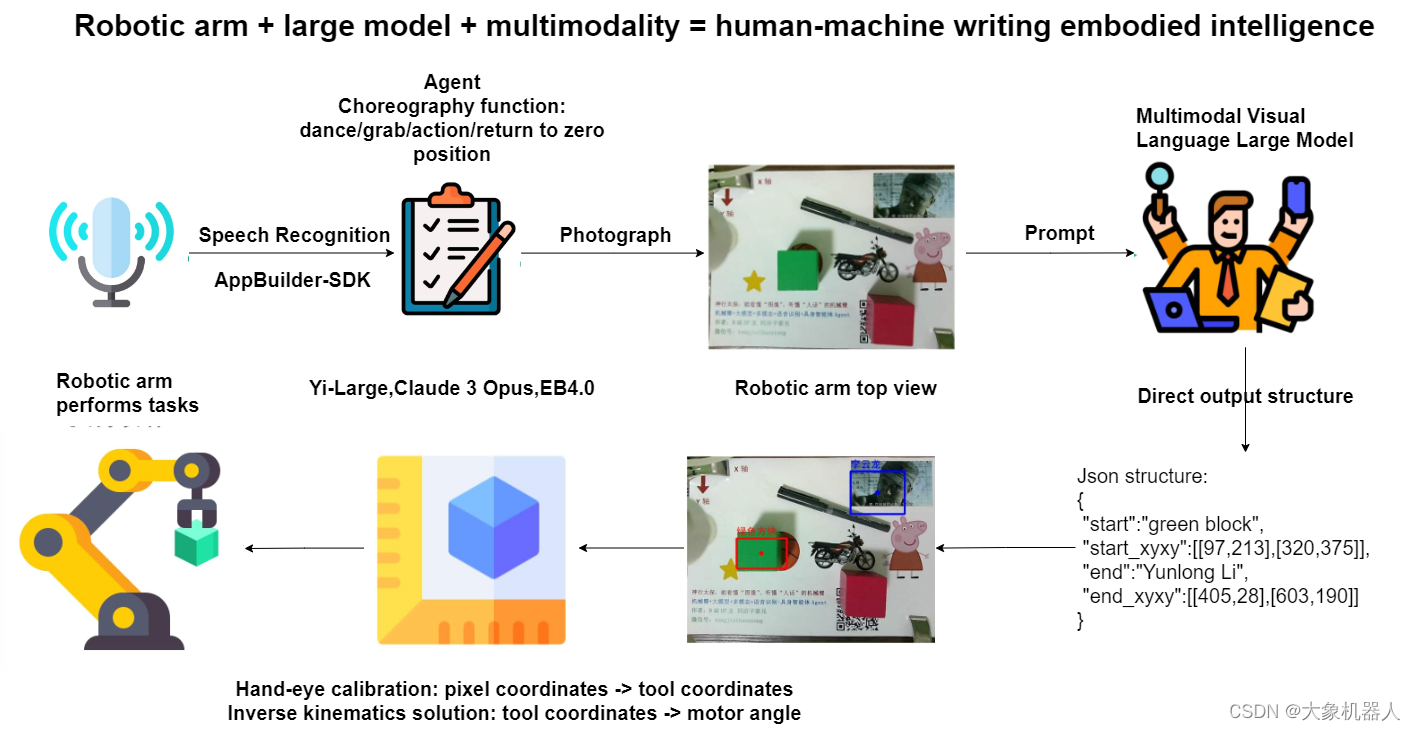
語音識(shí)別-appbuild
首先通過調(diào)用本地的電腦進(jìn)行麥克風(fēng)的錄音制作成音頻文件。
#調(diào)用麥克風(fēng)錄音。 def record(MIC_INDEX=0, DURATION=5): ''' 調(diào)用麥克風(fēng)錄音,需用arecord -l命令獲取麥克風(fēng)ID DURATION,錄音時(shí)長 ''' os.system('sudo arecord -D "plughw:{}" -f dat -c 1 -r 16000 -d {} temp/speech_record.wav'.format(MIC_INDEX, DURATION))
當(dāng)然這種默認(rèn)的錄音在一些特定的環(huán)境中效果是不好的,所以要設(shè)定相關(guān)的參數(shù)保證錄音的質(zhì)量。
CHUNK = 1024 # 采樣寬度 RATE = 16000 # 采樣率 QUIET_DB = 2000 # 分貝閾值,大于則開始錄音,否則結(jié)束 delay_time = 1 # 聲音降至分貝閾值后,經(jīng)過多長時(shí)間,自動(dòng)終止錄音 FORMAT = pyaudio.paInt16 CHANNELS = 1 if sys.platform == 'darwin' else 2 # 采樣通道數(shù)
根據(jù)參數(shù)的設(shè)定,然后開始錄音,之后要對(duì)文件進(jìn)行保存。
output_path = 'temp/speech_record.wav' wf = wave.open(output_path, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames[START_TIME-2:END_TIME])) wf.close() print('保存錄音文件', output_path)
有了錄音文件,電腦當(dāng)然沒那么智能我們需要用到appbuild-sdk來對(duì)音頻文件的語音進(jìn)行識(shí)別,這樣LLM才能夠獲取我們說的話然后做出一些對(duì)應(yīng)的操作。
import appbuilder
os.environ["APPBUILDER_TOKEN"] = APPBUILDER_TOKEN
asr = appbuilder.ASR() # 語音識(shí)別組件
def speech_recognition(audio_path='temp/speech_record.wav'):
# 載入wav音頻文件
with wave.open(audio_path, 'rb') as wav_file:
# 獲取音頻文件的基本信息
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
framerate = wav_file.getframerate()
num_frames = wav_file.getnframes()
# 獲取音頻數(shù)據(jù)
frames = wav_file.readframes(num_frames)
# 向API發(fā)起請(qǐng)求
content_data = {"audio_format": "wav", "raw_audio": frames, "rate": 16000}
message = appbuilder.Message(content_data)
speech_result = asr.run(message).content['result'][0]
return speech_result
Prompt-Agent
緊接著,我們要prompt大語言模型,提前告訴它出現(xiàn)某種情況應(yīng)該如何進(jìn)行應(yīng)對(duì)。這邊對(duì)調(diào)用LLM的API 就不做過多的介紹了,讓我們來看看如何對(duì)LLM做預(yù)訓(xùn)練。
prompt: (截取部分片段,以下是做中文的翻譯) 你是我的機(jī)械臂助手,機(jī)械臂內(nèi)置了一些函數(shù),請(qǐng)你根據(jù)我的指令,以json形式輸出要運(yùn)行的對(duì)應(yīng)函數(shù)和你給我的回復(fù) 【以下是所有內(nèi)置函數(shù)介紹】 機(jī)械臂位置歸零,所有關(guān)節(jié)回到原點(diǎn):back_zero() 放松機(jī)械臂,所有關(guān)節(jié)都可以自由手動(dòng)拖拽活動(dòng):back_zero() 做出搖頭動(dòng)作:head_shake() 做出點(diǎn)頭動(dòng)作:head_nod() 做出跳舞動(dòng)作:head_dance() 打開吸泵:pump_on() 關(guān)閉吸泵:pump_off()【輸出json格式】 你直接輸出json即可,從{開始,不要輸出包含```json的開頭或結(jié)尾 在'function'鍵中,輸出函數(shù)名列表,列表中每個(gè)元素都是字符串,代表要運(yùn)行的函數(shù)名稱和參數(shù)。每個(gè)函數(shù)既可以單獨(dú)運(yùn)行,也可以和其他函數(shù)先后運(yùn)行。列表元素的先后順序,表示執(zhí)行函數(shù)的先后順序 在'response'鍵中,根據(jù)我的指令和你編排的動(dòng)作,以第一人稱輸出你回復(fù)我的話,不要超過20個(gè)字,可以幽默和發(fā)散,用上歌詞、臺(tái)詞、互聯(lián)網(wǎng)熱梗、名場面。比如李云龍的臺(tái)詞、甄嬛傳的臺(tái)詞、練習(xí)時(shí)長兩年半。 【以下是一些具體的例子】 我的指令:回到原點(diǎn)。你輸出:{'function':['back_zero()'], 'response':'回家吧,回到最初的美好'} 我的指令:先回到原點(diǎn),然后跳舞。你輸出:{'function':['back_zero()', 'head_dance()'], 'response':'我的舞姿,練習(xí)時(shí)長兩年半'} 我的指令:先回到原點(diǎn),然后移動(dòng)到180, -90坐標(biāo)。你輸出:{'function':['back_zero()', 'move_to_coords(X=180, Y=-90)'], 'response':'精準(zhǔn)不,老子打的就是精銳'}
智能視覺抓取
在這個(gè)過程中,只需要myCobot移動(dòng)到俯視的一個(gè)位置,對(duì)目標(biāo)進(jìn)行拍攝,然后將拍攝后的照片交給視覺模型進(jìn)行處理,獲取到目標(biāo)的參數(shù)就可以返回給機(jī)械臂做抓取運(yùn)動(dòng)。
調(diào)用相機(jī)進(jìn)行拍攝
def check_camera():
cap = cv2.VideoCapture(0)
while(True):
ret, frame = cap.read()
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
講圖像交給大模型進(jìn)行處理,之后得到的參數(shù)需要進(jìn)一步的處理,繪制可視化的效果,最終將返回得到歸一化坐標(biāo)轉(zhuǎn)化為實(shí)際圖像中的像素坐標(biāo)。
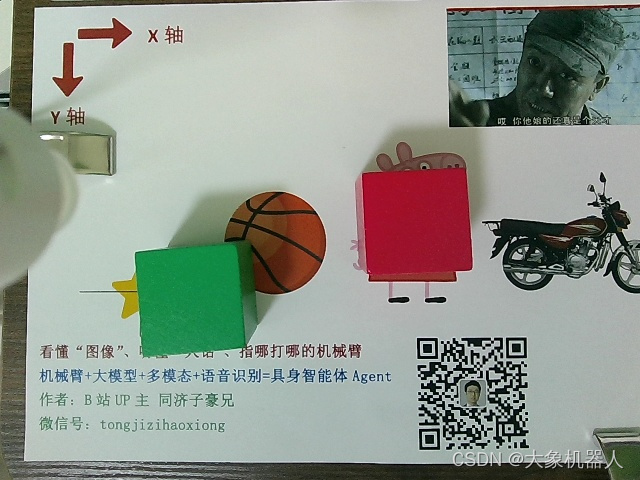
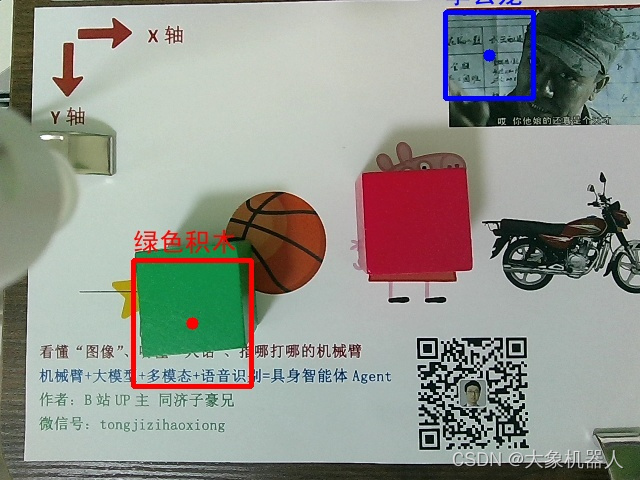
def post_processing_viz(result, img_path, check=False): ''' 視覺大模型輸出結(jié)果后處理和可視化 check:是否需要人工看屏幕確認(rèn)可視化成功,按鍵繼續(xù)或退出 ''' # 后處理 img_bgr = cv2.imread(img_path) img_h = img_bgr.shape[0] img_w = img_bgr.shape[1] # 縮放因子 FACTOR = 999 # 起點(diǎn)物體名稱 START_NAME = result['start'] # 終點(diǎn)物體名稱 END_NAME = result['end'] # 起點(diǎn),左上角像素坐標(biāo) START_X_MIN = int(result['start_xyxy'][0][0] * img_w / FACTOR) START_Y_MIN = int(result['start_xyxy'][0][1] * img_h / FACTOR) # 起點(diǎn),右下角像素坐標(biāo) START_X_MAX = int(result['start_xyxy'][1][0] * img_w / FACTOR) START_Y_MAX = int(result['start_xyxy'][1][1] * img_h / FACTOR) # 起點(diǎn),中心點(diǎn)像素坐標(biāo) START_X_CENTER = int((START_X_MIN + START_X_MAX) / 2) START_Y_CENTER = int((START_Y_MIN + START_Y_MAX) / 2) # 終點(diǎn),左上角像素坐標(biāo) END_X_MIN = int(result['end_xyxy'][0][0] * img_w / FACTOR) END_Y_MIN = int(result['end_xyxy'][0][1] * img_h / FACTOR) # 終點(diǎn),右下角像素坐標(biāo) END_X_MAX = int(result['end_xyxy'][1][0] * img_w / FACTOR) END_Y_MAX = int(result['end_xyxy'][1][1] * img_h / FACTOR) # 終點(diǎn),中心點(diǎn)像素坐標(biāo) END_X_CENTER = int((END_X_MIN + END_X_MAX) / 2) END_Y_CENTER = int((END_Y_MIN + END_Y_MAX) / 2) # 可視化 # 畫起點(diǎn)物體框 img_bgr = cv2.rectangle(img_bgr, (START_X_MIN, START_Y_MIN), (START_X_MAX, START_Y_MAX), [0, 0, 255], thickness=3) # 畫起點(diǎn)中心點(diǎn) img_bgr = cv2.circle(img_bgr, [START_X_CENTER, START_Y_CENTER], 6, [0, 0, 255], thickness=-1) # 畫終點(diǎn)物體框 img_bgr = cv2.rectangle(img_bgr, (END_X_MIN, END_Y_MIN), (END_X_MAX, END_Y_MAX), [255, 0, 0], thickness=3) # 畫終點(diǎn)中心點(diǎn) img_bgr = cv2.circle(img_bgr, [END_X_CENTER, END_Y_CENTER], 6, [255, 0, 0], thickness=-1) # 寫中文物體名稱 img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR 轉(zhuǎn) RGB img_pil = Image.fromarray(img_rgb) # array 轉(zhuǎn) pil draw = ImageDraw.Draw(img_pil) # 寫起點(diǎn)物體中文名稱 draw.text((START_X_MIN, START_Y_MIN-32), START_NAME, font=font, fill=(255, 0, 0, 1)) # 文字坐標(biāo),中文字符串,字體,rgba顏色 # 寫終點(diǎn)物體中文名稱 draw.text((END_X_MIN, END_Y_MIN-32), END_NAME, font=font, fill=(0, 0, 255, 1)) # 文字坐標(biāo),中文字符串,字體,rgba顏色 img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR) # RGB轉(zhuǎn)BGR return START_X_CENTER, START_Y_CENTER, END_X_CENTER, END_Y_CENTER
要用到手眼標(biāo)定將圖像中的像素坐標(biāo),轉(zhuǎn)化為機(jī)械臂的坐標(biāo),以至于機(jī)械臂能夠去執(zhí)行抓取。
def eye2hand(X_im=160, Y_im=120): # 整理兩個(gè)標(biāo)定點(diǎn)的坐標(biāo) cali_1_im = [130, 290] # 左下角,第一個(gè)標(biāo)定點(diǎn)的像素坐標(biāo),要手動(dòng)填! cali_1_mc = [-21.8, -197.4] # 左下角,第一個(gè)標(biāo)定點(diǎn)的機(jī)械臂坐標(biāo),要手動(dòng)填! cali_2_im = [640, 0] # 右上角,第二個(gè)標(biāo)定點(diǎn)的像素坐標(biāo) cali_2_mc = [215, -59.1] # 右上角,第二個(gè)標(biāo)定點(diǎn)的機(jī)械臂坐標(biāo),要手動(dòng)填! X_cali_im = [cali_1_im[0], cali_2_im[0]] # 像素坐標(biāo) X_cali_mc = [cali_1_mc[0], cali_2_mc[0]] # 機(jī)械臂坐標(biāo) Y_cali_im = [cali_2_im[1], cali_1_im[1]] # 像素坐標(biāo),先小后大 Y_cali_mc = [cali_2_mc[1], cali_1_mc[1]] # 機(jī)械臂坐標(biāo),先大后小 # X差值 X_mc = int(np.interp(X_im, X_cali_im, X_cali_mc)) # Y差值 Y_mc = int(np.interp(Y_im, Y_cali_im, Y_cali_mc)) return X_mc, Y_mc
最后將全部的技術(shù)整合在一起就形成了一個(gè)完成的Agent了,就能夠?qū)崿F(xiàn)指哪打哪的功能。
https://www.youtube.com/watch?v=VlSQQJreIrI
總結(jié)
vlm_arm項(xiàng)目展示了將多個(gè)大模型與機(jī)械臂結(jié)合的巨大潛力,為人機(jī)協(xié)作和智能化應(yīng)用提供了新的思路和方法。這一案例不僅展示了技術(shù)的創(chuàng)新性和實(shí)用性,也為未來類似項(xiàng)目的開發(fā)提供了寶貴的經(jīng)驗(yàn)和參考。通過對(duì)項(xiàng)目的深入分析,我們可以看到多模型并行使用在提升系統(tǒng)智能化水平方面的顯著效果,為機(jī)器人技術(shù)的進(jìn)一步發(fā)展奠定了堅(jiān)實(shí)基礎(chǔ)。
離實(shí)現(xiàn)鋼鐵俠中的賈維斯越來越近了,未來電影中的畫面終將會(huì)成為現(xiàn)實(shí)。
審核編輯 黃宇
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238245 -
開源
+關(guān)注
關(guān)注
3文章
3309瀏覽量
42471 -
機(jī)械臂
+關(guān)注
關(guān)注
12文章
513瀏覽量
24554 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
從工業(yè)到醫(yī)療再到太空機(jī)器人 機(jī)械臂都有什么不同?
國產(chǎn)Cortex-A55人工智能教學(xué)實(shí)驗(yàn)箱_基于Python機(jī)械臂跳舞實(shí)驗(yàn)案例分享
開源工業(yè)機(jī)械臂開發(fā)套件
開源工業(yè)增強(qiáng)型機(jī)械臂
如何控制真實(shí)機(jī)械臂/機(jī)器人呢
如何導(dǎo)入機(jī)械臂的三維模型
機(jī)械臂的控制學(xué)習(xí)
一文看懂工業(yè)機(jī)器人和機(jī)械臂的區(qū)別
制造業(yè)最常見的機(jī)器人——機(jī)械臂
機(jī)械臂和移動(dòng)機(jī)器人的架構(gòu)介紹

機(jī)械臂焊接機(jī)器人軌跡控制原理
自動(dòng)化革命:大象機(jī)器人的Mercury A1機(jī)械臂
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論