") 分享一次海量數(shù)據(jù)平滑遷移實戰(zhàn)
分享一次海量數(shù)據(jù)平滑遷移實戰(zhàn)
背景
采購系統(tǒng)(BIP)在經(jīng)歷多年演進后,系統(tǒng)整體復雜度和數(shù)據(jù)量儼然已經(jīng)極具規(guī)模,本文著重討論海量數(shù)據(jù)的治理
存儲現(xiàn)狀:工程端實時訂單庫采用MySQL 5.5集群,其中主庫配置為32C/48G/6000G,無法歸檔的訂單熱數(shù)據(jù)占磁盤空間85%(5.1T)
痛點:6T磁盤已經(jīng)單容器最大,無法繼續(xù)擴容,剩余磁盤余量過小,難適應(yīng)未來發(fā)展
目標
降低磁盤容量,優(yōu)化數(shù)據(jù)模型,提升系統(tǒng)穩(wěn)定性
調(diào)研
首先,既然是要解決存儲容量的問題,就要對詳細的容量情況有個更加清楚的了解。總結(jié)下當前存儲容量問題,最大的表是訂單操作日志表lifecycle共1.3T,大于500G的表2張共1.5T;100G~500G的表10張共2.6T。以下是優(yōu)化前庫里大表(大于100G)的詳細空間占用情況:
| 序號 | 表名 | 空間大小(行數(shù)|總大小|數(shù)據(jù)大小|索引大小) |
|---|---|---|
| 1 | lifecycle | 46億 | 1.3T | 856G | 328G |
| 2 | cgfenpei | 5.8億 | 665G | 518G | 147G |
| 3 | cgtable | 5.8億 | 491G | 287G | 204G |
| 4 | cgdetail | 5.5億 | 405G | 308G | 97G |
| 5 | po_asn_receipt_detail | 4.5億 | 351G |167G | 184G |
| 6 | po_data | 2.5億 | 321G | 312G | 9G |
| 7 | purchase_order_extension | 4.2億 | 293G | 166G | 127G |
| 8 | po_stock_detail | 7.3億 | 204G | 104G | 100G |
| 9 | po_channel | 6.1億 | 191G | 70G | 121G |
| 10 | cgtablesubtable | 6億 | 154G | 62G | 92G |
| 11 | unduprecord | 4.2億 | 138G | 138G | 0G |
| 12 | po_stock | 2.8億 | 126G | 63G | 63G |
|
? |
合計 | 4.6T |
其次,確認當前最高效的優(yōu)化思路是將lifecycle表遷移到其他庫,原因有二:1.lifecycle表的含義是操作日志,在業(yè)務(wù)上不算訂單域內(nèi)最核心的模型,風險可控;2.占用空間大,單表46億行數(shù)據(jù),空間占用1.3T,一張表占了磁盤空間的22%,優(yōu)化的ROI高
最后,想說明下,為什么沒有直接將整個庫,從傳統(tǒng)MySQL切換到JED,原因也有二:1.JED和MySQL的查詢語法還是有一定差異,直接切換,成本和風險極高;2.切換存儲中間件,獲取分布式架構(gòu)下更大的存儲空間并不是銀彈,理智告訴我們要結(jié)合系統(tǒng)現(xiàn)狀,不可盲目下定論
挑戰(zhàn)
保障海量數(shù)據(jù)(存量46億行,增量600w+行/天,TPS峰值:500+,QPS峰值:200+)遷移期間讀、寫穩(wěn)定和準確。需要補充一下:lifecycle雖然不算訂單最核心業(yè)務(wù)模型,但依舊是輔助業(yè)務(wù)決策的關(guān)鍵數(shù)據(jù),也非常重要
例子:
方案
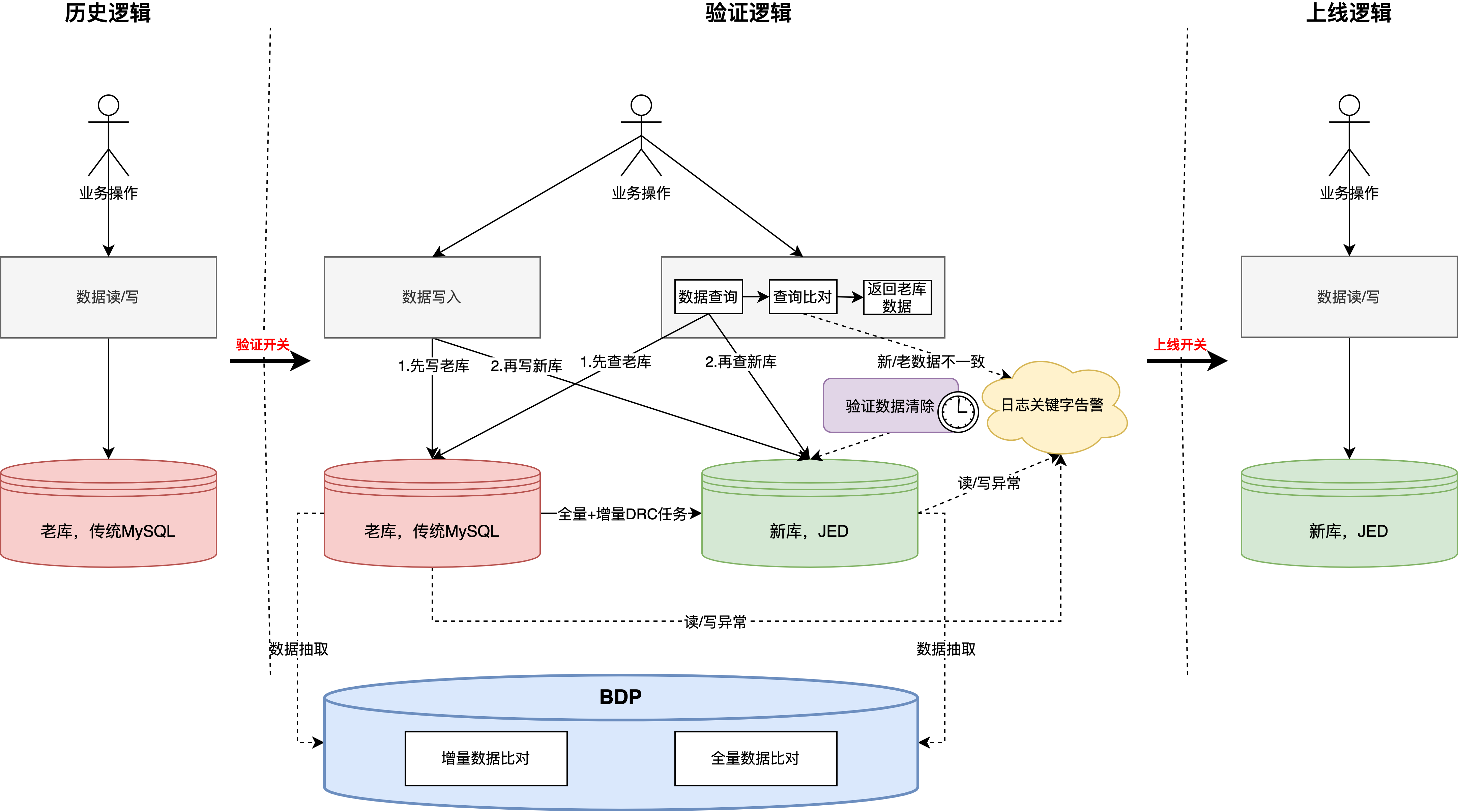
整體方案
數(shù)據(jù)同步 -> 雙讀 -> 雙寫 -> 離線驗證 -> 數(shù)據(jù)清理
詳細設(shè)計
?數(shù)據(jù)同步,通過DRC實現(xiàn),歷史全量+增量,其中有以下幾點使用心得:
?同步速度問題,本次是使用傳統(tǒng)MySQL5.5 -> JED 底層MySQL 8.0 單表同步,效率大概是4M/S,一共花了3天半左右
?數(shù)據(jù)同步過程中不要操作暫停,否則任務(wù)重啟后,會重新同步歷史數(shù)據(jù),導致數(shù)據(jù)同步周期變長。詳情參考: 關(guān)于全量任務(wù)暫停重啟之后數(shù)據(jù)同步慢的原因
?字段兼容問題,老庫歷史時間字段類型是datetime,新庫需要改為datetime(3),這種數(shù)據(jù)同步是可以兼容的(下文會講為什么要優(yōu)化時間字段精度)
?數(shù)據(jù)驗證問題,當時在歷史數(shù)據(jù)全量同步完畢后開啟了DRC數(shù)據(jù)驗證,但是許久未執(zhí)行完成,收到DRC運維告知出現(xiàn)大量報錯,最終結(jié)論是暫時不支持這兩個版本的數(shù)據(jù)比對(5.5->8.0),這也是為什么整體架構(gòu)上采用BDP抽數(shù)比對數(shù)據(jù)的主要原因
?數(shù)據(jù)驗證,業(yè)務(wù)程序完成雙寫、雙讀改造
?雙寫
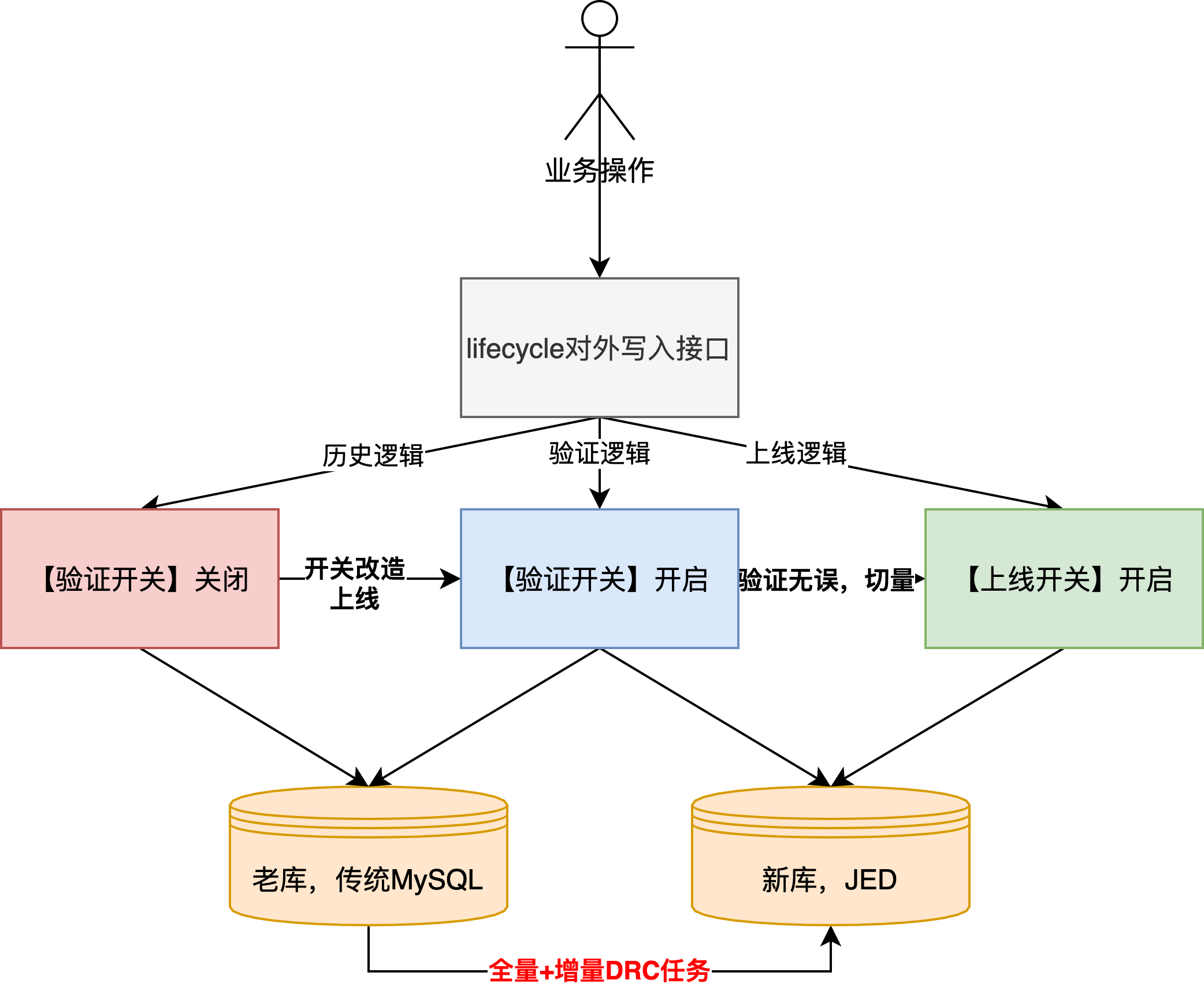
?為什么采用雙寫?答:控制風險。1.團隊內(nèi)還沒有應(yīng)用直接寫入多分片JED的先例,而且新、老庫的底層MySQL版本也差異比較大(5.5 vs 8.0),當時通過分批次灰度上線完成逐步切量驗證;2.方便進行數(shù)據(jù)驗證,lifecycle是業(yè)務(wù)操作日志,基本涵蓋了所有的寫入場景,其中因為歷史問題,不乏一部分邏輯和訂單更新在同一事務(wù)中,現(xiàn)在遷移到新庫,本地事務(wù)會存在不生效的場景
?具體改造方案:
?新增【驗證開關(guān)】,開啟后新/老庫雙寫,另外需要要引入vitess驅(qū)動,目前只支持JDK8及以上
?新增【上線開關(guān)】,開啟后只寫新庫,此開關(guān)是在驗證邏輯無問題后,最終切換的開關(guān),代表遷移完成
?注意,開關(guān)改造完成上線后,“全量+增量DRC任務(wù)”在驗證期間是一直啟用的,也就是說驗證期間,增量數(shù)據(jù)會寫兩份到新庫
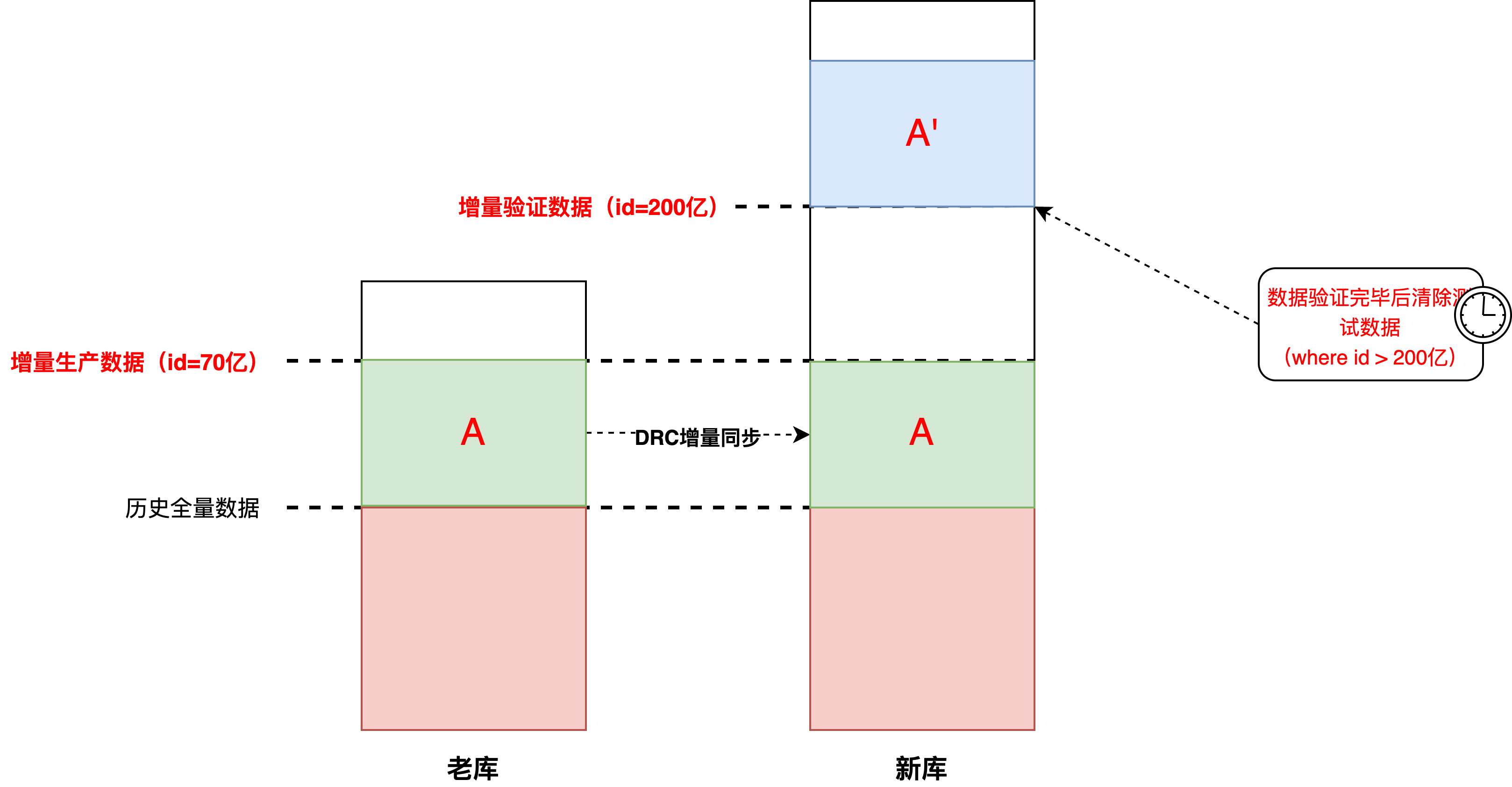
?一部分是實際的生產(chǎn)數(shù)據(jù),一部分是待驗證的測試數(shù)據(jù)。那么就帶來另一個問題,如何識別和區(qū)分這兩部分數(shù)據(jù),我們采用的方案是:JED建表指定趨勢自增的最小id(200億)+【驗證開關(guān)】開啟的時間戳進行區(qū)分
?如下圖,其中A和A'都是【驗證開關(guān)】切換后的增量數(shù)據(jù),由于老庫的id已經(jīng)自增寫到了70億,并且DRC同步任務(wù)也是指定id寫入,所以建表時指定新增數(shù)據(jù)id是200億(詳情參考: 數(shù)據(jù)庫自增ID列設(shè)置 ),和老數(shù)據(jù)之間存在一定gap方便識別。BDP腳本數(shù)據(jù)比對的也是:老庫.A和新庫.A'(這里默認DRC增量同步的數(shù)據(jù)是準確的)
?清除測試數(shù)據(jù),真正完成【上線開關(guān)】切換,需要提前清除測試數(shù)據(jù),只需指定id>200億的物理刪除即可。注意:針對多分片的JED物理刪除delete語句,我們程序上如果為了防止大事務(wù),而采用“for循環(huán)+limit n”的方式執(zhí)行,實際的每次SQL語句執(zhí)行結(jié)果是多個分片的n的聚合,而不是n,如果程序上對結(jié)果有判斷邏輯,需要額外注意
?雙讀
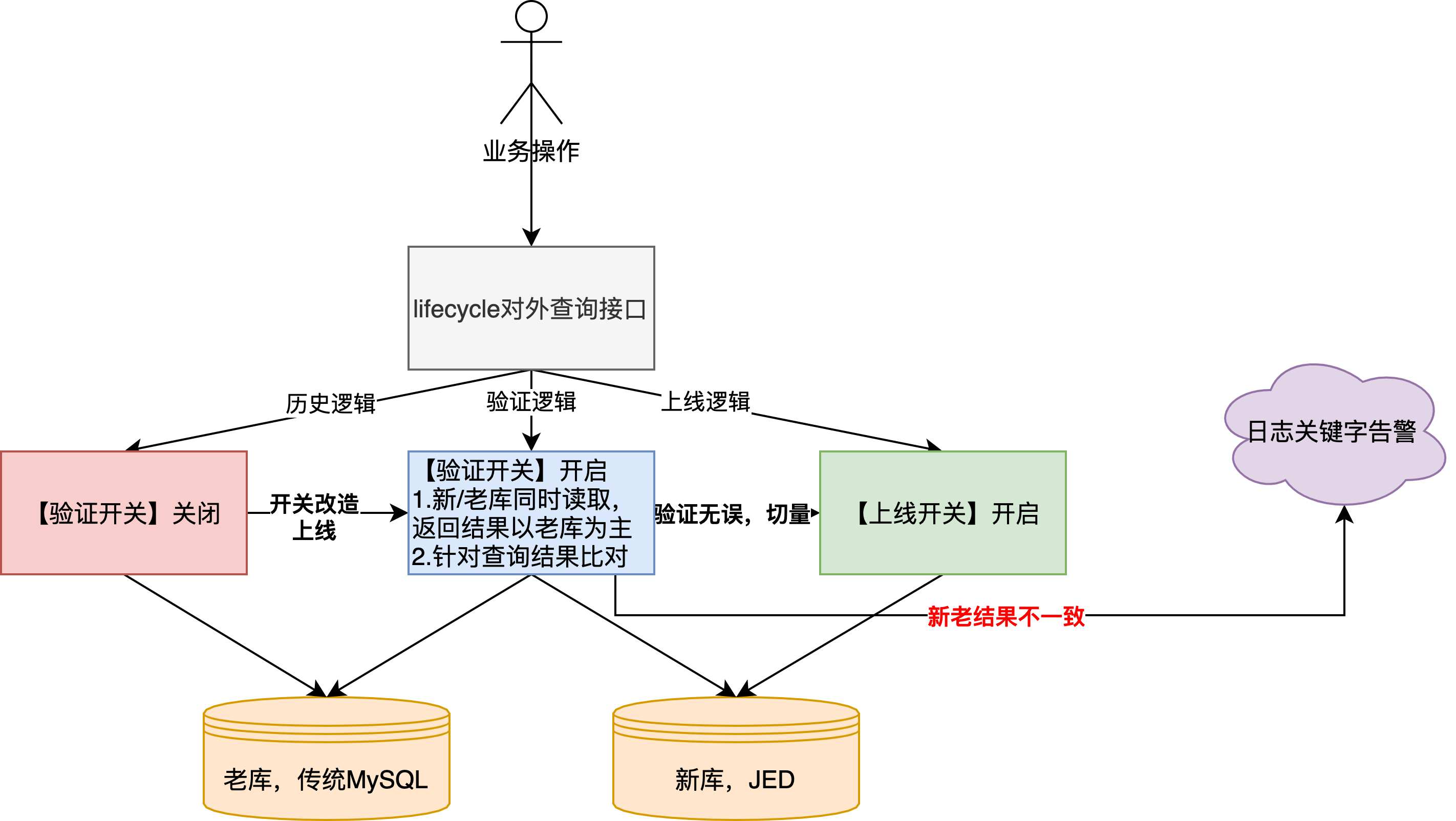
?整體邏輯基本復用寫入期間已有開關(guān),其中針對新庫當中DRC實時同步的數(shù)據(jù)(上圖:新庫.A)會根據(jù)開關(guān)開啟時間進行過濾
?其中,在驗證期間,新、老庫都會根據(jù)采購單號進行查詢并實際返回老庫的查詢結(jié)果,其中還會進行結(jié)果比對,出現(xiàn)數(shù)據(jù)不一致會輸出異常日志關(guān)鍵字
?另外,因為lifecycle操作日志數(shù)據(jù)是有先后順序的,老庫的處理方式是根據(jù)自增id進行倒排,到了新庫以后,由于采用的是JED分片(分布式存儲的磁盤空間更大),考慮到開發(fā)成本,數(shù)據(jù)id采用的是趨勢遞增的自增主鍵(詳情參考: Vitess全局唯一ID生成的實現(xiàn)方案 ),這時多集群并行寫入無法繼續(xù)使用基于id倒排的方式返回結(jié)果(后寫入的數(shù)據(jù)可能id較小,可以參考sequece發(fā)號器的ID生成),所以將原始的數(shù)據(jù)寫入時間戳從datetime提高精度到datetime(3),通過數(shù)據(jù)寫入時間進行倒排,這里也解釋了上文,新庫DRC數(shù)據(jù)同步為什么要考慮字段兼容的問題
?補充1:這里基于時間倒排在業(yè)務(wù)上是準確的,因為lifecycle數(shù)據(jù)是根據(jù)訂單號進行分片的,所以同一訂單一定落在單分片上,也就是說不存在不同分片時鐘偏移的問題,單訂單的操作日志的時間序列一定是按照寫入順序逐漸增加的
?補充2:新庫字段類型變更(datetime->datetime(3)),32分片,共46億行數(shù)據(jù),執(zhí)行了大概1小時,期間主從延遲最高30分鐘,容器負載正常
?補充3:應(yīng)用的關(guān)鍵字告警配置,日志文件僅支持以error.log、err.log、exception.log結(jié)尾,并開啟歷史日志的路徑
?最后,雙讀期間共通過業(yè)務(wù)的實際查詢流量發(fā)現(xiàn)數(shù)據(jù)不一致問題2個+,在并未影響到業(yè)務(wù)使用的前提下及時發(fā)現(xiàn)了系統(tǒng)異常
?離線驗證
?lifecycle歸根結(jié)底還是寫多讀少的業(yè)務(wù)場景,為了防止出現(xiàn)上文數(shù)據(jù)比對驗證的遺漏,我們會采用BDP離線任務(wù)會分別開啟增量數(shù)據(jù)+歷史全量數(shù)據(jù)驗證。通過對新、老庫的全量數(shù)據(jù)字段相互sql inner join的方式完成比對,其中會忽略id和寫入時間,因為新庫的id不是單調(diào)遞增、時間精確到了毫秒。期間共發(fā)現(xiàn)有效數(shù)據(jù)問題3個+,均是因為本地事務(wù)回滾導致的數(shù)據(jù)不一致的場景
?收尾工作
?完成【上線開關(guān)】切換,只讀、寫新庫,完成整體平滑遷移。在無QA參與前提下,驗證期間未出現(xiàn)過數(shù)據(jù)丟失、重復、錯誤等異常
?切換完成后,老庫老表和DRC同步任務(wù)依舊保留了一周的時間,防止出現(xiàn)場景遺漏,產(chǎn)生數(shù)據(jù)丟失
?46億行大表清理,采用drop+create的方式實現(xiàn)效率、穩(wěn)定性更高,在業(yè)務(wù)低峰期完成腳本執(zhí)行,大概花費10秒的時間,容器負載、內(nèi)存等指標正常。但是當時碰上了DBA的備份任務(wù),導致有一個從庫主從延遲升高,這個后續(xù)需要注意
審核編輯 黃宇
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7085瀏覽量
89220 -
存儲
+關(guān)注
關(guān)注
13文章
4332瀏覽量
85956 -
遷移
+關(guān)注
關(guān)注
0文章
33瀏覽量
7943
發(fā)布評論請先 登錄
相關(guān)推薦
MySQL數(shù)據(jù)遷移的流程介紹
一次電源與二次電源有什么不同
一次電池分類以及應(yīng)用場景詳解

labview如何做到一次觸發(fā)采集一次
一次消諧器的構(gòu)造
鴻蒙OS開發(fā):典型頁面場景【一次開發(fā),多端部署】實戰(zhàn)(設(shè)置典型頁面)
鴻蒙OS開發(fā):【一次開發(fā),多端部署】(視頻應(yīng)用)
拒絕無效嘗試,EMC問題解決實戰(zhàn)教學帶你一次性解決問題!

stm32f030的AD轉(zhuǎn)換,如何調(diào)用一次getadcvalue() 就采集一次數(shù)據(jù)?
STM32F429如何一次傳3000個數(shù)據(jù)?
配置SPI一次收發(fā)一個16位數(shù)據(jù),但抓的數(shù)據(jù)波形顯示,數(shù)據(jù)連續(xù)發(fā)送和接收了4次為什么?
基波是一次諧波么 基波與一次諧波的區(qū)別
M24C16為什么只能讀寫最后一次的數(shù)據(jù)?
電力系統(tǒng)一次設(shè)備和二次設(shè)備區(qū)別,二次回路的分類






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論