 計算機視覺怎么給圖像分類
計算機視覺怎么給圖像分類
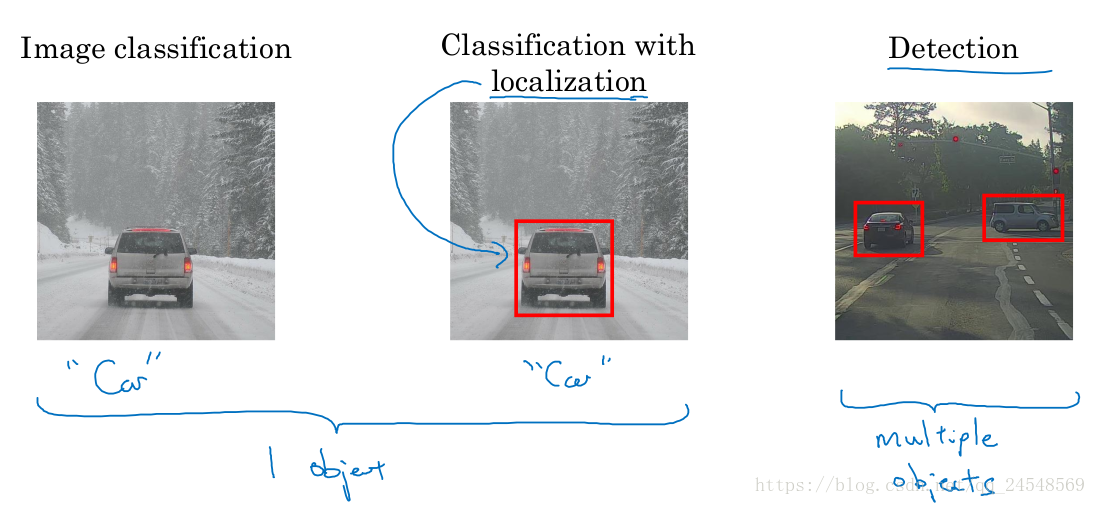
圖像分類是計算機視覺領域中的一項核心任務,其目標是將輸入的圖像自動分配到預定義的類別集合中。這一過程涉及圖像的特征提取、特征表示以及分類器的設計與訓練。隨著深度學習技術的飛速發展,圖像分類的精度和效率得到了顯著提升。本文將從圖像分類的基本概念、流程、常用算法以及未來發展趨勢等方面進行詳細闡述。
一、圖像分類的基本概念
圖像分類是指利用計算機視覺技術,將輸入的圖像根據其內容自動分配到預定義的類別中的過程。在計算機視覺中,圖像通常是以像素矩陣的形式表示,每個像素包含顏色、亮度等信息。圖像分類的任務就是通過對這些像素的處理和分析,最終輸出一個類別標簽。
二、圖像分類的流程
圖像分類的流程主要包括數據準備、特征提取、特征表示、分類器訓練與評估等步驟。
1. 數據準備
數據準備是圖像分類的第一步,也是至關重要的一步。它包括收集并準備用于訓練和測試的圖像數據集。數據集通常被劃分為訓練集、驗證集和測試集,分別用于模型的訓練、參數調整和性能評估。在準備數據集時,需要對圖像進行標注,即給每張圖像分配一個或多個類別標簽。
2. 特征提取
特征提取是將原始圖像轉化為可用于分類的特征向量的過程。在傳統的計算機視覺方法中,特征提取通常依賴于手工設計的特征描述子,如SIFT(尺度不變特征變換)、HOG(方向梯度直方圖)等。然而,這些方法在處理復雜圖像時往往效果不佳。近年來,隨著深度學習技術的興起,自動特征提取成為主流。卷積神經網絡(CNN)是圖像分類領域最常用的深度學習模型之一,它能夠自動從圖像中學習并提取出具有代表性的特征。
3. 特征表示
特征表示是將提取出來的特征向量轉化為一個可用于分類的固定維度的向量的過程。在傳統的機器學習方法中,特征表示通常涉及特征選擇、降維等操作。而在深度學習中,特征表示是通過卷積神經網絡中的卷積層、池化層等自動完成的。這些層能夠逐步將圖像的特征從低級(如邊緣、紋理)抽象到高級(如形狀、對象),最終形成可用于分類的特征表示。
4. 分類器訓練與評估
分類器訓練是將轉化后的特征向量輸入到分類器中,通過學習預定義類別的樣本來進行分類的過程。常用的分類器包括支持向量機(SVM)、K近鄰(KNN)、決策樹、隨機森林等。然而,在深度學習領域,卷積神經網絡本身就可以作為一個強大的分類器。通過反向傳播算法和梯度下降等優化方法,可以不斷調整網絡參數以最小化損失函數,從而提高分類的準確率。
模型評估是檢驗分類器性能的重要環節。通常使用驗證集對訓練得到的分類器進行評估,并根據評估結果調整模型參數。最后,使用測試集對訓練好的分類器進行測試評估,計算模型的準確率、精度、召回率等指標以衡量其性能。
三、常用算法與模型
1. 卷積神經網絡(CNN)
卷積神經網絡是圖像分類領域最常用的深度學習模型之一。它由卷積層、池化層、全連接層等組成,能夠自動地從圖像中學習并提取出具有代表性的特征。CNN通過卷積操作實現局部感受野和權值共享,大大降低了模型的復雜度并提高了計算效率。同時,通過池化操作實現特征降維和平移不變性,進一步提高了模型的魯棒性。
2. 經典CNN模型
- LeNet :最早的卷積神經網絡之一,由Yann LeCun等人于1998年提出,主要用于手寫數字的識別任務。
- AlexNet :由Alex Krizhevsky等人于2012年在ImageNet圖像分類競賽中獲得了第一名,是一個具有深度結構的卷積神經網絡。
- VGGNet :由Karen Simonyan和Andrew Zisserman提出,通過多個3x3的卷積層和池化層進行特征提取,并使用全連接層進行分類。
- GoogLeNet :由Google研究團隊提出,創新性地使用了Inception模塊,提高了模型的表示能力。
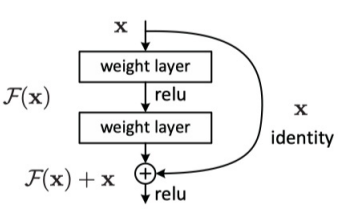
- ResNet :由Microsoft Research Asia提出,通過引入殘差連接解決了深度神經網絡訓練中的梯度消失或梯度爆炸問題,使得網絡可以更加深入地學習圖像特征。
3. 其他算法與模型
除了卷積神經網絡外,還有一些其他算法和模型也被應用于圖像分類任務中。例如,支持向量機(SVM)是一種基于最大間隔原則的分類算法,在圖像分類中表現出色。此外,還有一些基于圖像分割、目標檢測等技術的圖像分類方法,它們能夠在更細粒度的層面上對圖像進行分類。
四、當前狀況及未來趨勢趨勢
計算機視覺(Computer Vision,CV)作為人工智能領域的一個重要分支,近年來取得了顯著的發展。以下是對計算機視覺領域當前狀況及未來趨勢的詳細分析:
1.當前狀況
- 技術創新與突破
- 分割技術 :如Meta AI開發的Segment Anything Model(SAM),幾乎可以分割圖像中的任何事物,為跨各種數據集的復雜分割任務開辟了新途徑。
- 多模態大型語言模型 :如GPT-4等模型,彌合了文本和視覺數據之間的差距,使AI能夠理解和解釋復雜的多模態輸入。
- 物體檢測 :YOLOv8等模型憑借其增強的速度和準確性,為物體檢測樹立了新標準。YOLO系列的最新版本如YOLOv10,進一步提高了性能和效率。
- 自監督學習 :DINOv2等模型展示了自監督方法使用較少的標記圖像訓練高質量模型的潛力。
- 文本轉圖像和視頻 :Midjourney creations、DALL-E 3、Stable Diffusion XL、Imagen 2等模型,以及Runway、Pika Labs和Emu Video等T2V模型,極大地提高了AI根據文本描述生成圖像和視頻的質量和真實感。
- 應用領域的擴展
- 技術挑戰
- 數據隱私 :隨著圖像數據的大量收集和分析,如何保護個人隱私成為一個重要問題。
- 算法偏見 :機器學習模型可能會學習到訓練數據中的偏見,導致不公平的結果。
- 模型可解釋性 :深度學習模型通常被認為是“黑箱”,提高模型的可解釋性是一個挑戰。
2.未來趨勢
- 動態實時數據分析
- 未來的計算機視覺技術將更加注重動態實時數據的分析,優化動態數據追蹤及檢測的相關算法,以滿足實時應用的需求。
- 多場景融合應用
- 在應用領域方面,多場景融合應用將是重要的發展方向。計算機視覺將不僅局限于單一領域的應用,而是會與其他領域進行深度融合,如社會科學、人體健康等。
- 構建多維數據集
- 視覺數據方面,需要構建多維、全面、立體的數據集。結合物聯技術、遙感技術、AI技術的成熟,將跨時空、跨地域、跨物種的視覺數據進行綜合疊加,構建全周期、全過程視覺數據集。
- 視覺生成與內容理解統一建模
- 通過自監督、多模態預訓練產生的基礎大模型,可以指導產生更加可控、有意義的圖像、視頻生成。反過來,生成模型的建模方式也越來越多地成為解決復雜視覺理解任務的新思路。
- 邊緣計算
- 邊緣計算將變得更加普遍。在設備上處理視覺數據將提高數據處理的速度和效率,適用于自動駕駛、智能安全系統等對實時性要求高的應用。
- 道德與隱私保護
- 隨著計算機視覺的廣泛應用,道德和隱私問題將越來越受到關注。開發更加平衡、更加注重隱私的技術將是未來的重要趨勢。
綜上所述,計算機視覺領域正處于快速發展階段,技術創新不斷涌現,應用領域持續擴展。然而,也面臨著數據隱私、算法偏見和模型可解釋性等挑戰。未來,隨著技術的不斷進步和應用領域的不斷擴展,計算機視覺將在更多領域發揮重要作用,并推動人工智能技術的進一步發展。
-
圖像分類
+關注
關注
0文章
93瀏覽量
12000 -
計算機視覺
+關注
關注
8文章
1703瀏覽量
46244 -
深度學習
+關注
關注
73文章
5527瀏覽量
121878
發布評論請先 登錄
相關推薦
深度解析計算機視覺的圖像分割技術

機器視覺與計算機視覺的關系簡述

基于計算機視覺的多維圖像智能
如何快速學習計算機視覺圖像的分類





 工商網監
工商網監
評論