


Cache相關(guān)概念
3Outer&Inner R/W allocate
表示分配方式為外部和內(nèi)部都是讀寫(xiě)分配。
讀/寫(xiě)分配是一種內(nèi)存訪問(wèn)策略,用于確定處理器在訪問(wèn)內(nèi)存時(shí)是否需要將數(shù)據(jù)加載到高速緩存中。具體來(lái)說(shuō):
讀分配:當(dāng)處理器需要從內(nèi)存中讀取數(shù)據(jù)時(shí),如果該數(shù)據(jù)不在高速緩存中,則會(huì)將相應(yīng)的數(shù)據(jù)塊加載到高速緩存中,以便處理器能夠更快地訪問(wèn)和處理數(shù)據(jù)。
寫(xiě)分配:當(dāng)處理器需要向內(nèi)存寫(xiě)入數(shù)據(jù)時(shí),如果寫(xiě)入的數(shù)據(jù)不在高速緩存中,則會(huì)先將相應(yīng)的數(shù)據(jù)塊加載到高速緩存中,并在高速緩存中進(jìn)行寫(xiě)操作,然后再將更新后的數(shù)據(jù)寫(xiě)入到內(nèi)存中。讀/寫(xiě)分配可以影響系統(tǒng)的性能表現(xiàn),合理選擇讀/寫(xiě)分配策略可以提高數(shù)據(jù)訪問(wèn)的效率和速度。
如果外部和內(nèi)部都是讀/寫(xiě)分配,表示處理器在與外部存儲(chǔ)器和內(nèi)部緩存之間的數(shù)據(jù)交互時(shí),都采用讀/寫(xiě)分配的方式來(lái)管理數(shù)據(jù)的加載和寫(xiě)入操作。這樣的設(shè)置可以根據(jù)具體場(chǎng)景提高數(shù)據(jù)訪問(wèn)的效率和性能。
4Write-Back,Write-Through
Write-back寫(xiě)回,和Write-Through寫(xiě)透是兩種不同的緩存策略,它們?cè)谔幚砥髟L問(wèn)數(shù)據(jù)時(shí)的行為有所不同:在寫(xiě)回策略下,當(dāng)處理器要寫(xiě)入數(shù)據(jù)時(shí),數(shù)據(jù)首先被寫(xiě)入到緩存中,而不是直接寫(xiě)入到內(nèi)存中。只有在緩存行被替換出去時(shí),才會(huì)將被修改的數(shù)據(jù)寫(xiě)回到內(nèi)存中。這樣可以減少對(duì)內(nèi)存的頻繁寫(xiě)入操作,提高緩存的利用率和性能。
在寫(xiě)透策略下,當(dāng)處理器要寫(xiě)入數(shù)據(jù)時(shí),數(shù)據(jù)會(huì)同時(shí)被寫(xiě)入到緩存和內(nèi)存中。每次寫(xiě)操作都會(huì)導(dǎo)致數(shù)據(jù)被同步寫(xiě)入到內(nèi)存,確保內(nèi)存和緩存中的數(shù)據(jù)一致性。雖然可以保證數(shù)據(jù)的一致性,但可能會(huì)增加寫(xiě)操作的延遲。
效率上來(lái)說(shuō),寫(xiě)回策略通常比寫(xiě)透策略效率更高。這是因?yàn)閷?xiě)回策略減少了對(duì)內(nèi)存的頻繁寫(xiě)入,利用了緩存的特性來(lái)減少內(nèi)存訪問(wèn)次數(shù),提高了系統(tǒng)整體的性能。然而,寫(xiě)回策略需要額外的控制邏輯來(lái)管理緩存中數(shù)據(jù)與內(nèi)存之間的一致性,因此需要更多的硬件支持。選擇哪種策略取決于系統(tǒng)的設(shè)計(jì)需求和性能優(yōu)化目標(biāo)。
5Outer&Inner non-allocate
外部和內(nèi)部都是非分配的意味著在存儲(chǔ)器屬性中指定了不進(jìn)行分配(non-allocate)的方式。這意味著處理器在訪問(wèn)這種類型的內(nèi)存時(shí),不會(huì)將數(shù)據(jù)加載到高速緩存中進(jìn)行緩存,而是直接在內(nèi)存中讀取或?qū)懭霐?shù)據(jù)。
當(dāng)外部和內(nèi)部都是非分配時(shí),處理器在訪問(wèn)這段內(nèi)存時(shí)不會(huì)將其內(nèi)容緩存起來(lái),而是每次都直接從內(nèi)存讀取或?qū)懭霐?shù)據(jù)。這種方式可能會(huì)增加內(nèi)存訪問(wèn)的延遲,但可以確保處理器訪問(wèn)的數(shù)據(jù)是最新的,適用于對(duì)數(shù)據(jù)實(shí)時(shí)性要求較高的場(chǎng)景。
6Outer&Inner non-cacheable
表示外部和內(nèi)部都不開(kāi)緩存
7Non-transient可以理解為非瞬態(tài)
"transient" 通常用來(lái)描述一種短暫存在或暫時(shí)性的狀態(tài)或?qū)傩浴6?"non-transient" 則表示相反的情況,即不是短暫的或不是暫時(shí)的。
在代碼中提到的 "non-transient" 和 "transient" 可能用來(lái)描述內(nèi)存訪問(wèn)屬性的持久性或持續(xù)性。例如,如果一個(gè)內(nèi)存區(qū)域被標(biāo)記為 "non-transient",可能意味著該區(qū)域的屬性在一段時(shí)間內(nèi)保持不變,而不是臨時(shí)性的或隨機(jī)變化的。

點(diǎn)擊可查看大圖
這里要注意的一點(diǎn)是:如上圖紅框所示CortexR52的內(nèi)核的write-back被當(dāng)成是write-through來(lái)對(duì)待。
System ram的MPU配置說(shuō)明

點(diǎn)擊可查看大圖
這里的ATTRINDEX1對(duì)應(yīng)的就是Attr1的配置,其它的序號(hào)也是一一對(duì)應(yīng)的。
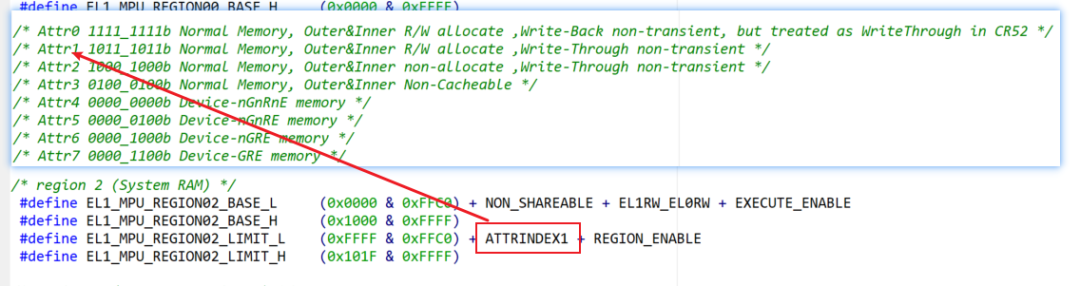
點(diǎn)擊可查看大圖
Attr1可以看出他的配置是正常存儲(chǔ)設(shè)備,內(nèi)外部讀寫(xiě)分配,并且是寫(xiě)透的cache策略,這面要注意的是,打開(kāi)cache一定要是non_shareable。
我們?cè)倏匆幌孪聢D中System RAM mirror:的MPU配置策略與system ram正好相反,ATTRINDEX3對(duì)應(yīng)的Attr3是沒(méi)有使能cache,卻是“outer_shareable”的狀態(tài)。這個(gè)也好理解,因?yàn)殚_(kāi)cache,又開(kāi)共享的話會(huì)影響數(shù)據(jù)一致性的。

點(diǎn)擊可查看大圖
下個(gè)章節(jié)將介紹Cortex R52具體的緩存操作的實(shí)踐和性能測(cè)試。
-
處理器
+關(guān)注
關(guān)注
68文章
19924瀏覽量
235803 -
內(nèi)核
+關(guān)注
關(guān)注
3文章
1417瀏覽量
41497 -
Cortex
+關(guān)注
關(guān)注
2文章
203瀏覽量
47417
原文標(biāo)題:解密Cortex R52內(nèi)核Cache:操作實(shí)踐、性能測(cè)試與深度解析(2)
文章出處:【微信號(hào):瑞薩MCU小百科,微信公眾號(hào):瑞薩MCU小百科】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
瑞薩RA2L2產(chǎn)品特色功能、配套評(píng)估板和相關(guān)開(kāi)發(fā)工具集合

瑞薩RZ T2H更換DDR流程和工具介紹
在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
瑞薩RA8快速上手指南:Cortex-M85內(nèi)核瑞薩RA8開(kāi)發(fā)環(huán)境搭建 并點(diǎn)亮一個(gè)LED

如何從R52_0使用SD Boot啟動(dòng)S32z ?
具有OTFD和安全功能的高性能和優(yōu)化的實(shí)時(shí)響應(yīng)MPU RZ/T2ME數(shù)據(jù)手冊(cè)
可實(shí)現(xiàn)工業(yè) AC Servo 和控制器高速處理的多功能 MPU RZ/T2M 數(shù)據(jù)手冊(cè)
通過(guò)EtherCAT實(shí)現(xiàn)高速、高精度實(shí)時(shí)控制的高性能MPU RZ/T2L數(shù)據(jù)手冊(cè)

集成應(yīng)用處理功能和高精度實(shí)時(shí)控制性能的高端 MPU RZ/T2H數(shù)據(jù)手冊(cè)
STM32WBA52CEU可以用標(biāo)準(zhǔn)庫(kù)開(kāi)發(fā)嗎?
R5F(MCU2_0)上OpenVx主機(jī)的概念驗(yàn)證啟用

解析Arm Neoverse N2 PMU事件L2D_CACHE_WR

Arm Cortex-R82AE賦能高性能區(qū)域控制器設(shè)計(jì)
RM57L843基于ARM? Cortex?-R內(nèi)核的Hercules?微控制器數(shù)據(jù)表
TMS570LC4357基于ARM Cortex?-R內(nèi)核的Hercules?微控制器數(shù)據(jù)表





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論