

TaD:任務(wù)感知解碼技術(shù)(Task-aware Decoding,簡稱TaD),京東聯(lián)合清華大學(xué)針對大語言模型幻覺問題提出的一項技術(shù),成果收錄于IJCAI2024。
RAG:檢索增強(qiáng)生成技術(shù)(Retrieval-augmented Generation,簡稱RAG),是業(yè)內(nèi)解決LLM幻覺問題最有效的系統(tǒng)性方案。
1. 背景介紹
近來,以ChatGPT為代表的生成式大語言模型(Large Language Model,簡稱LLM)掀起了新一輪AI熱潮,并迅速席卷了整個社會的方方面面。得益于前所未有的模型規(guī)模、訓(xùn)練數(shù)據(jù),以及引入人類反饋的訓(xùn)練新范式,LLM在一定程度上具備對人類意圖的理解和甄別能力,可實現(xiàn)生動逼真的類人對話互動,其回答的準(zhǔn)確率、邏輯性、流暢度都已經(jīng)無限接近人類水平。此外,LLM還出現(xiàn)了神奇的“智能涌現(xiàn)”現(xiàn)象,其產(chǎn)生的強(qiáng)大的邏輯推理、智能規(guī)劃等能力,已逐步應(yīng)用到智能助理、輔助創(chuàng)作、科研啟發(fā)等領(lǐng)域。京東在諸多核心業(yè)務(wù)如AI搜索、智能客服、智能導(dǎo)購、創(chuàng)意聲稱、推薦/廣告、風(fēng)控等場景下,均對LLM的落地應(yīng)用進(jìn)行了深入探索。這一舉措提升了業(yè)務(wù)效率,增強(qiáng)了用戶體驗。
盡管具備驚艷的類人對話能力,大語言模型的另外一面——不準(zhǔn)確性,卻逐漸成為其大規(guī)模落地的制約和瓶頸。通俗地講,LLM生成不準(zhǔn)確、誤導(dǎo)性或無意義的信息被稱為“幻覺”,也就是常說的“胡說八道”。當(dāng)然也有學(xué)者,比如OpenAI的CEO Sam Altman,將LLM產(chǎn)生的“幻覺”視為“非凡的創(chuàng)造力”。但是在大多數(shù)場景下,模型提供正確回答的能力至關(guān)重要,因此幻覺常常被認(rèn)為是一種缺陷;尤其是在一些對輸出內(nèi)容準(zhǔn)確性要求較高的場景下,比如醫(yī)療診斷、法律咨詢、工業(yè)制造、售后客服等,幻覺問題導(dǎo)致的后果往往是災(zāi)難性的。
本文主要探索針對LLM幻覺問題的解決方案。
2. 相關(guān)調(diào)研
眾所周知,大語言模型的本質(zhì)依然是語言模型(Language Model,簡稱LM),該模型可通過計算句子概率建模自然語言概率分布。具體而言,LM基于統(tǒng)計對大量語料進(jìn)行分析,按順序預(yù)測下一個特定字/詞的概率。LLM的主要功能是根據(jù)輸入文本生成連貫且上下文恰當(dāng)?shù)幕貜?fù),即生成與人類語言和寫作的模式結(jié)構(gòu)極為一致的文本。注意到,LLM并不擅長真正理解或傳遞事實信息。故而其幻覺不可徹底消除。亞利桑那州立大學(xué)教授Subbarao Kambhampati認(rèn)為:LLM所生成的全都是幻覺,只是有時幻覺碰巧和你的現(xiàn)實一致而已。新加坡國立大學(xué)計算學(xué)院的Ziwei Xu和Sanjay Jain等也認(rèn)為LLM的幻覺無法完全消除[1]。
雖然幻覺問題無法徹底消除,但依然可以進(jìn)行優(yōu)化和緩解,業(yè)內(nèi)也有不少相關(guān)的探索。有研究[2]總結(jié)了LLM產(chǎn)生幻覺的三大來源:數(shù)據(jù)、訓(xùn)練和推理,并給出了對應(yīng)的緩解策略。
2.1 數(shù)據(jù)引入的幻覺
“病從口入”,訓(xùn)練數(shù)據(jù)是LLM的糧食,數(shù)據(jù)缺陷是使其致幻的一大原因。數(shù)據(jù)缺陷既包括數(shù)據(jù)錯誤、缺失、片面、過期等,也包括由于領(lǐng)域數(shù)據(jù)不足所導(dǎo)致的模型所捕獲的事實知識利用率較低等問題。以下是針對訓(xùn)練數(shù)據(jù)類幻覺的一些技術(shù)方案:
數(shù)據(jù)清洗
針對數(shù)據(jù)相關(guān)的幻覺,最直接的方法就是收集更多高質(zhì)量的事實數(shù)據(jù),并進(jìn)行數(shù)據(jù)清理。訓(xùn)練數(shù)據(jù)量越大、質(zhì)量越高,最終訓(xùn)練得到的LLM出現(xiàn)幻覺的可能性就可能越小[3]。但是,訓(xùn)練數(shù)據(jù)總有一定的覆蓋范圍和時間邊界,不可避免地形成知識邊界,單純從訓(xùn)練數(shù)據(jù)角度解決幻覺問題,并不是一個高性價比的方案。
針對“知識邊界”問題,有兩種主流方案:一種是知識編輯,即直接編輯模型參數(shù)彌合知識鴻溝。另一種是檢索增強(qiáng)生成(Retrieval-augmented Generation,簡稱RAG),保持模型參數(shù)不變,引入第三方獨立的知識庫。
知識編輯
知識編輯有兩種方法:1)編輯模型參數(shù)的方法可以細(xì)粒度地調(diào)整模型的效果,但難以實現(xiàn)知識間泛化能力,且不合理的模型編輯可能會導(dǎo)致模型產(chǎn)生有害或不適當(dāng)?shù)妮敵鯷4];2)外部干預(yù)的方法(不編輯模型參數(shù))對大模型通用能力影響較小,但需要引入一個單獨的模塊,且需要額外的資源訓(xùn)練這個模塊。
如何保持原始LLM能力不受影響的前提下,實現(xiàn)知識的有效更新,是LLM研究中的重要挑戰(zhàn)[2]。鑒于知識編輯技術(shù)會給用戶帶來潛在風(fēng)險,無論學(xué)術(shù)界還是業(yè)界都建議使用包含明確知識的方法,比如RAG。
檢索增強(qiáng)生成(RAG)
RAG引入信息檢索過程,通過第三方數(shù)據(jù)庫中檢索相關(guān)信息來增強(qiáng)LLM的生成過程,從而提高準(zhǔn)確性和魯棒性,降低幻覺。由于接入外部實時動態(tài)數(shù)據(jù),RAG在理論上沒有知識邊界的限制,且無需頻繁進(jìn)行LLM的訓(xùn)練,故已經(jīng)成為LLM行業(yè)落地最佳實踐方案。下圖1為RAG的一個標(biāo)準(zhǔn)實現(xiàn)方案[11],用戶的Query首先會經(jīng)由信息檢索模塊處理并召回相關(guān)文檔;隨后RAG方法將Prompt、用戶query和召回文檔一起輸入LLM,最終由LLM生成最終的答案。
圖1. RAG架構(gòu)圖
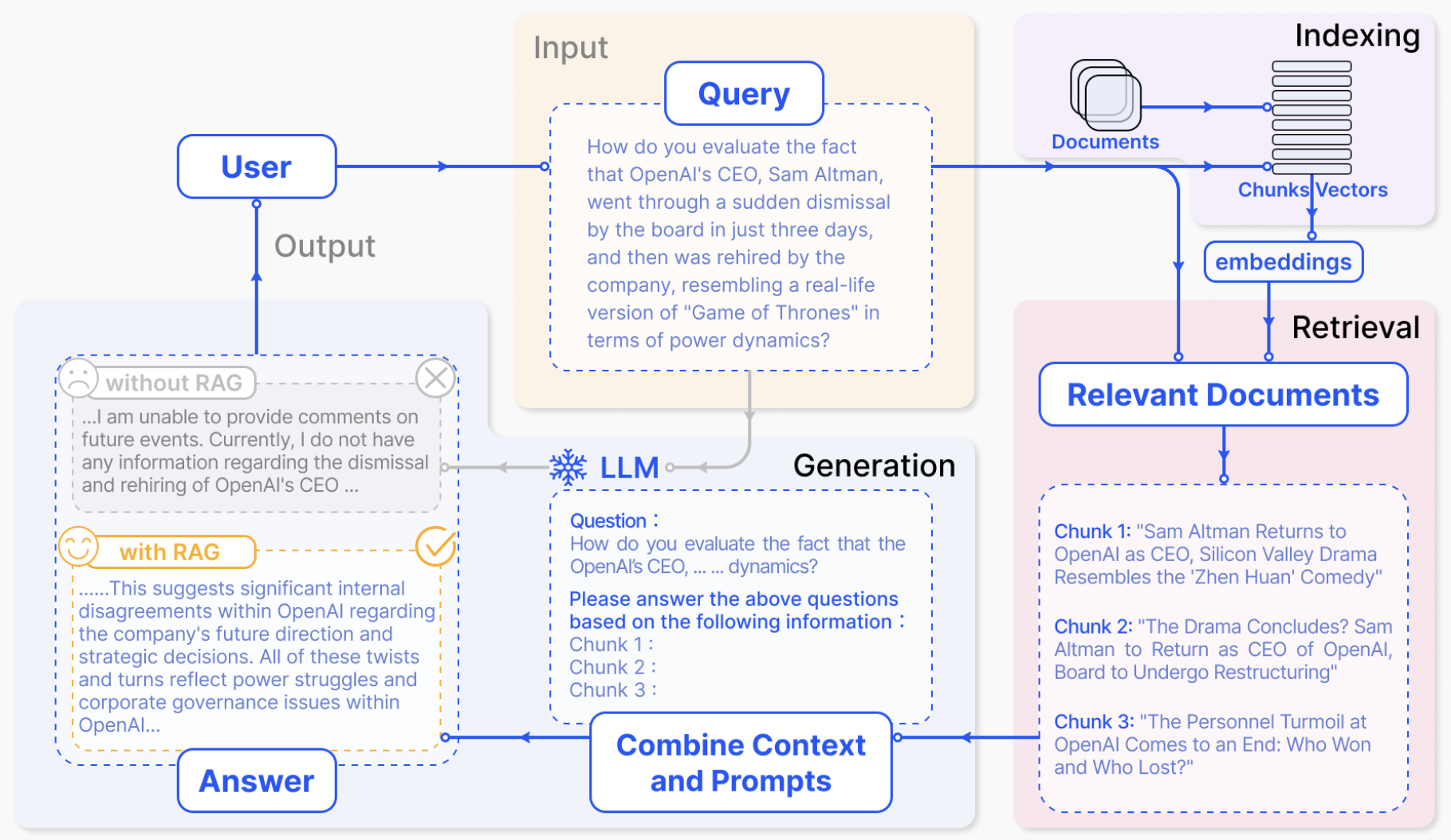
RAG借助信息檢索,引入第三方事實知識,大大緩解了單純依靠LLM生成答案而產(chǎn)生的幻覺,但由LLM生成的最終輸出仍然有較大概率產(chǎn)生幻覺。因此,緩解LLM本身的幻覺,對整個RAG意義重大。
2.2 模型訓(xùn)練引入的幻覺
LLM的整個訓(xùn)練過程,都可能會引入幻覺。首先,LLM通常是transformer結(jié)構(gòu)的單向語言模型,通過自回歸的方式建模目標(biāo),天然存在單向表示不足、注意力缺陷[6]、曝光偏差[7]等問題;其次,在文本對齊階段,無論是監(jiān)督微調(diào)(SFT)還是人類反饋的強(qiáng)化學(xué)習(xí)(RLHF),都有可能出現(xiàn)有標(biāo)注數(shù)據(jù)超出LLM知識邊界、或者與LLM內(nèi)在知識不一致的問題;這一系列對齊問題很可能放大LLM本身的幻覺風(fēng)險[8]。
對于訓(xùn)練過程引入的幻覺,可以通過優(yōu)化模型結(jié)構(gòu)、注意力機(jī)制、訓(xùn)練目標(biāo)、改進(jìn)偏好模型等一系列手段進(jìn)行緩解。但這些技術(shù)都缺乏通用性,難以在現(xiàn)有的LLM上進(jìn)行遷移,實用性不高。
2.3 推理過程引入的幻覺
推理過程引入的幻覺,一方面源自于解碼策略的抽樣隨機(jī)性,它與幻覺風(fēng)險的增加呈正相關(guān),尤其是采樣溫度升高導(dǎo)致低頻token被采樣的概率提升,進(jìn)一步加劇了幻覺風(fēng)險[9]。另一方面,注意力缺陷如上下文注意力不足、Softmax瓶頸導(dǎo)致的不完美解碼都會引入幻覺風(fēng)險。
層對比解碼(DoLa)
針對推理過程解碼策略存在的缺陷,一項具有代表性且較為有效的解決方案是層對比解碼(Decoding by Contrasting Layers, 簡稱DoLa)[9]。模型可解釋性研究發(fā)現(xiàn),在基于Transformer的語言模型中,下層transformer編碼“低級”信息(詞性、語法),而上層中包含更加“高級”的信息(事實知識)[10]。DoLa主要通過強(qiáng)調(diào)較上層中的知識相對于下層中的知識的“進(jìn)步”,減少語言模型的幻覺。具體地,DoLa通過計算上層與下層之間的logits差,獲得輸出下一個詞的概率。這種對比解碼方法可放大LLM中的事實知識,從而減少幻覺。
圖2. DoLa示意圖
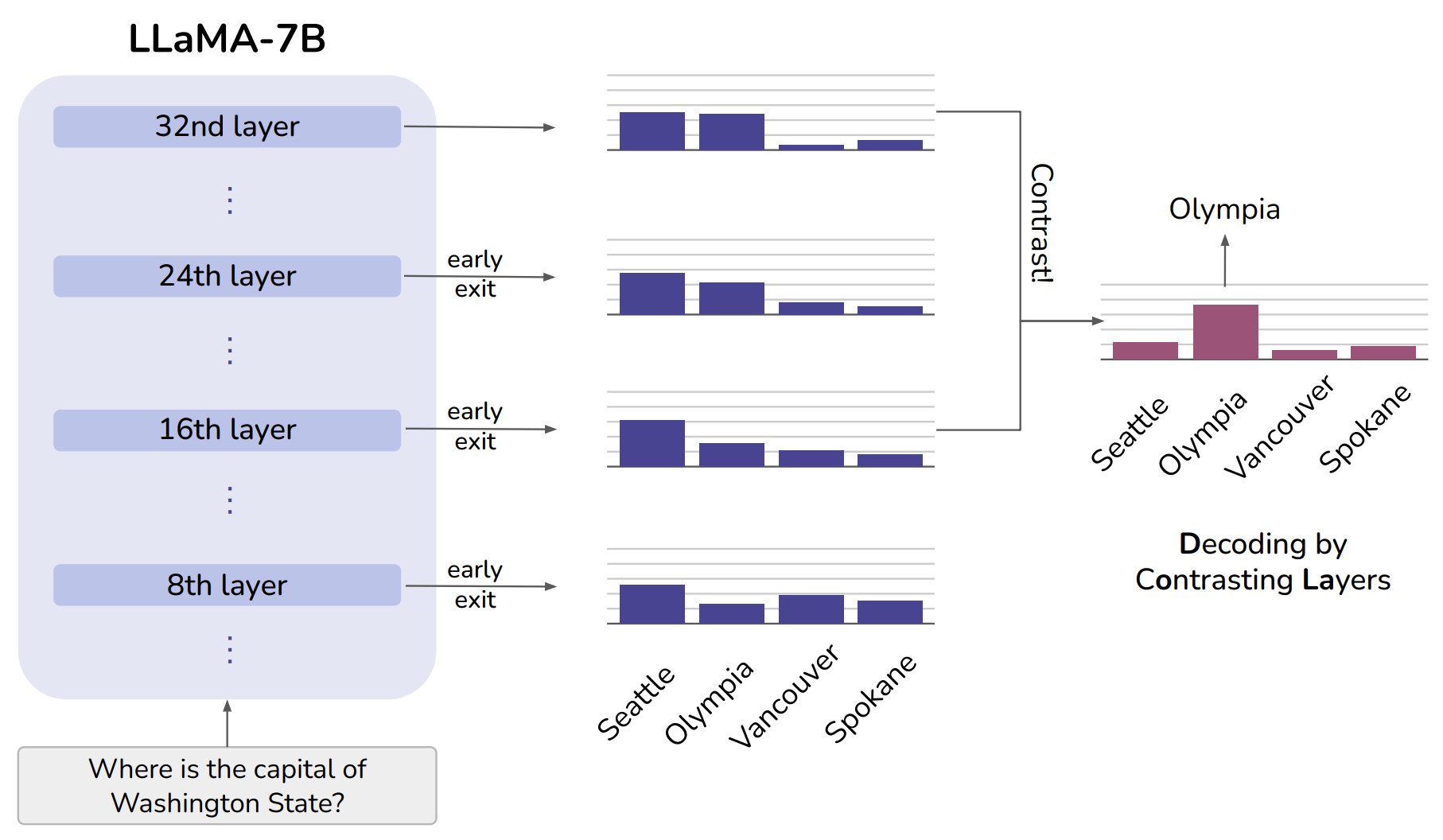
上圖2是DoLa的一個簡單直觀的示例。“Seattle”在所有層上都保持著很高的概率,可能僅僅因為它是一個從語法角度上講比較合理的答案。當(dāng)上層通過層對比解碼注入更多的事實知識后,正確答案“Olympia”的概率會增加。可見,層對比解碼(DoLa)技術(shù)可以揭示真正的答案,更好地解碼出LLM中的事實知識,而無需檢索外部知識或進(jìn)行額外微調(diào)。此外,DoLa還有動態(tài)層選擇策略,保證最上層和中間層的輸出差別盡可能大。
可見,DoLa的核心思想是淡化下層語言/語法知識,盡可能放大事實性知識,但這可能導(dǎo)致生成內(nèi)容存在語法問題;在實驗中還發(fā)現(xiàn)DoLa會傾向于生成重復(fù)的句子,尤其是長上下文推理場景。此外,DoLa不適用有監(jiān)督微調(diào),限制了LLM的微調(diào)優(yōu)化。
3. 技術(shù)突破
通過以上分析,RAG無疑是治療LLM幻覺的一副妙方,它如同LLM的一個強(qiáng)大的外掛,讓其在處理事實性問題時如虎添翼。但RAG的最終輸出仍然由LLM生成,緩解LLM本身的幻覺也極為重要,而目前業(yè)內(nèi)針對LLM本身幻覺的技術(shù)方案存在成本高、實用落地難、易引入潛在風(fēng)險等問題。
鑒于此,京東零售聯(lián)合清華大學(xué)進(jìn)行相關(guān)探索,提出任務(wù)感知解碼(Task-aware Decoding,簡稱TaD)技術(shù)[12](成果收錄于IJCAI2024),可即插即用地應(yīng)用到任何LLM上,通過對比有監(jiān)督微調(diào)前后的輸出,緩解LLM本身的幻覺。該方法通用性強(qiáng),在多種不同LLM結(jié)構(gòu)、微調(diào)方法、下游任務(wù)和數(shù)據(jù)集上均有效,具有廣泛的適用場景。
任務(wù)感知解碼(TaD)技術(shù)
關(guān)于LLM知識獲取機(jī)制的一些研究表明,LLM的輸出并不能總是準(zhǔn)確反映它們所擁有的知識,即使一個模型輸出錯誤,它仍然可能擁有正確的知識[13]。此項工作主要探索LLM在保留預(yù)訓(xùn)練學(xué)到的公共知識的同時,如何更好地利用微調(diào)過程中習(xí)得的下游任務(wù)特定領(lǐng)域知識,進(jìn)而提升其在具體任務(wù)中的效果,緩解LLM幻覺。
TaD的基本原理如圖3所示。微調(diào)前LLM和微調(diào)后LLM的輸出詞均為“engage”,但深入探究不難發(fā)現(xiàn)其相應(yīng)的預(yù)測概率分布發(fā)生了明顯的改變,這反映了LLM在微調(diào)期間試圖將其固有知識盡可能地適應(yīng)下游任務(wù)的特定領(lǐng)域知識。具體而言,經(jīng)過微調(diào),更加符合用戶輸入要求(“專業(yè)的”)的詞“catalyze”的預(yù)測概率明顯增加,而更通用的反映預(yù)訓(xùn)練過程習(xí)得的知識卻不能更好滿足下游任務(wù)用戶需求的詞“engage”的預(yù)測概率有所降低。TaD巧妙利用微調(diào)后LLM與微調(diào)前LLM的輸出概率分布的差異來構(gòu)建知識向量,得到更貼切的輸出詞“catalyze”,進(jìn)而增強(qiáng)LLM的輸出質(zhì)量,使其更符合下游任務(wù)偏好,改善幻覺。
圖3. TaD原理圖
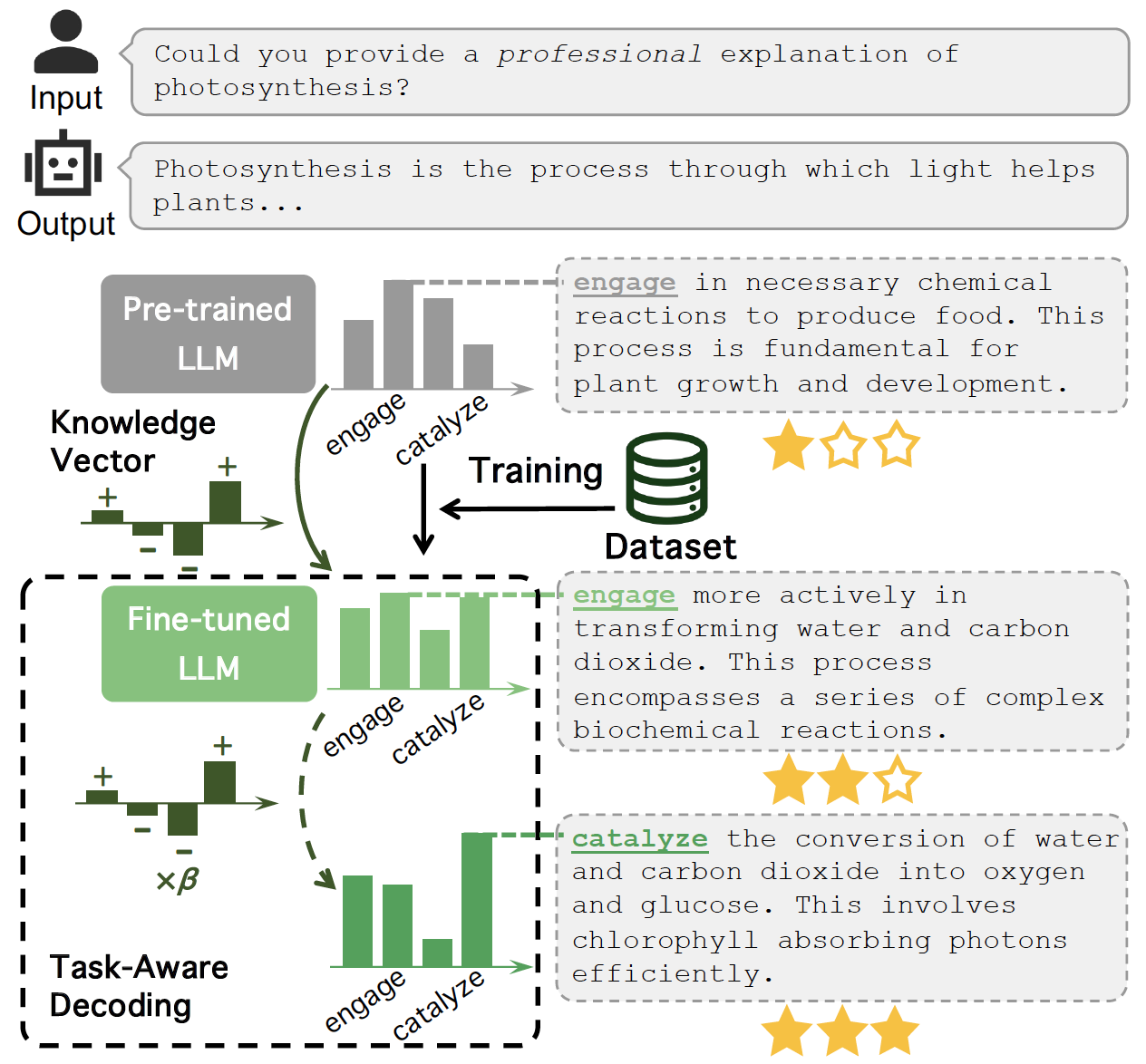
知識向量
為了直觀理解LLM在微調(diào)階段學(xué)習(xí)到的特定領(lǐng)域知識,我們引入知識向量的概念,具體如圖4所示。微調(diào)前LLM的輸出條件概率分布為pθ,微調(diào)后LLM的輸出條件概率分布為 p?。知識向量反應(yīng)了微調(diào)前后LLM輸出詞的條件概率分布變化,也代表著LLM的能力從公共知識到下游特定領(lǐng)域知識的適應(yīng)。基于TaD技術(shù)構(gòu)建的知識向量可強(qiáng)化LLM微調(diào)過程中習(xí)得的領(lǐng)域特定知識,進(jìn)一步改善LLM幻覺。
圖4. 知識向量
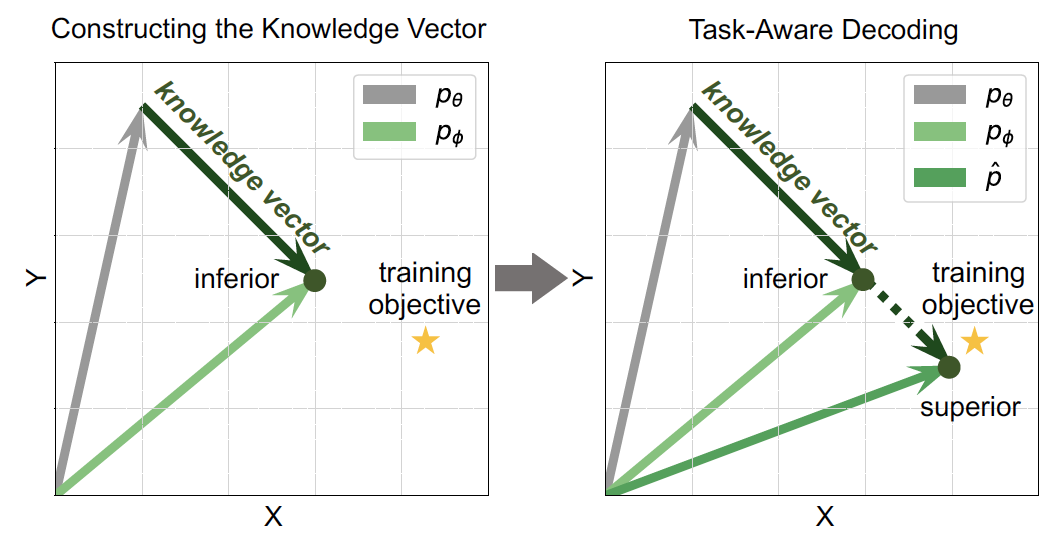
特別地,當(dāng)微調(diào)數(shù)據(jù)較少時,LLM的輸出條件概率分布遠(yuǎn)遠(yuǎn)達(dá)不到最終訓(xùn)練目標(biāo)。在此情形下,TaD技術(shù)增強(qiáng)后的知識向量可以加強(qiáng)知識對下游任務(wù)的適應(yīng),在訓(xùn)練數(shù)據(jù)稀缺場景下帶來更顯著的效果提升。
實驗結(jié)果
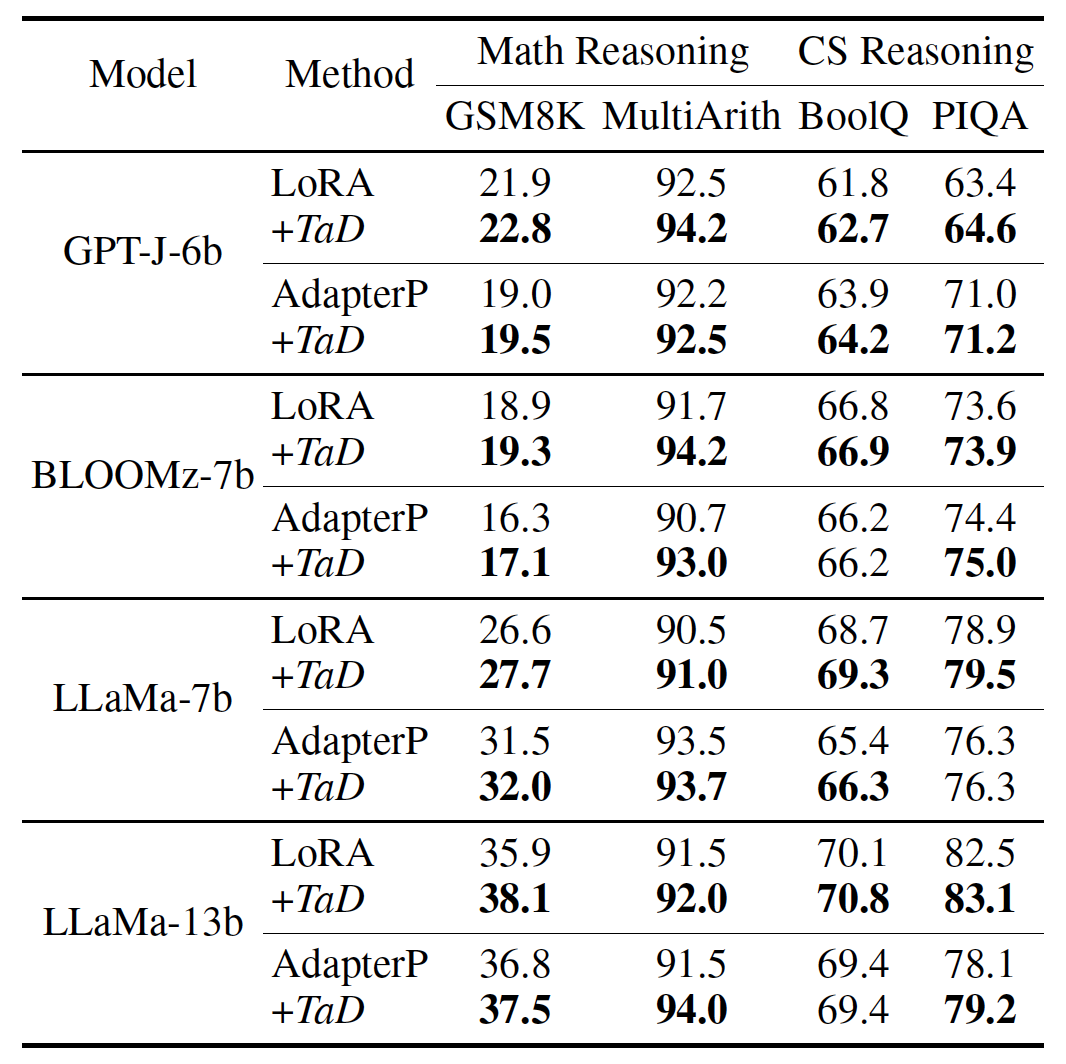
1)針對不同的LLM,采用LoRA、AdapterP等方式、在不同的任務(wù)上進(jìn)行微調(diào),實驗結(jié)果如下表1和表2所示。注意到,TaD技術(shù)均取得了明顯的正向效果提升。
表1. Multiple Choices和CBQA任務(wù)結(jié)果
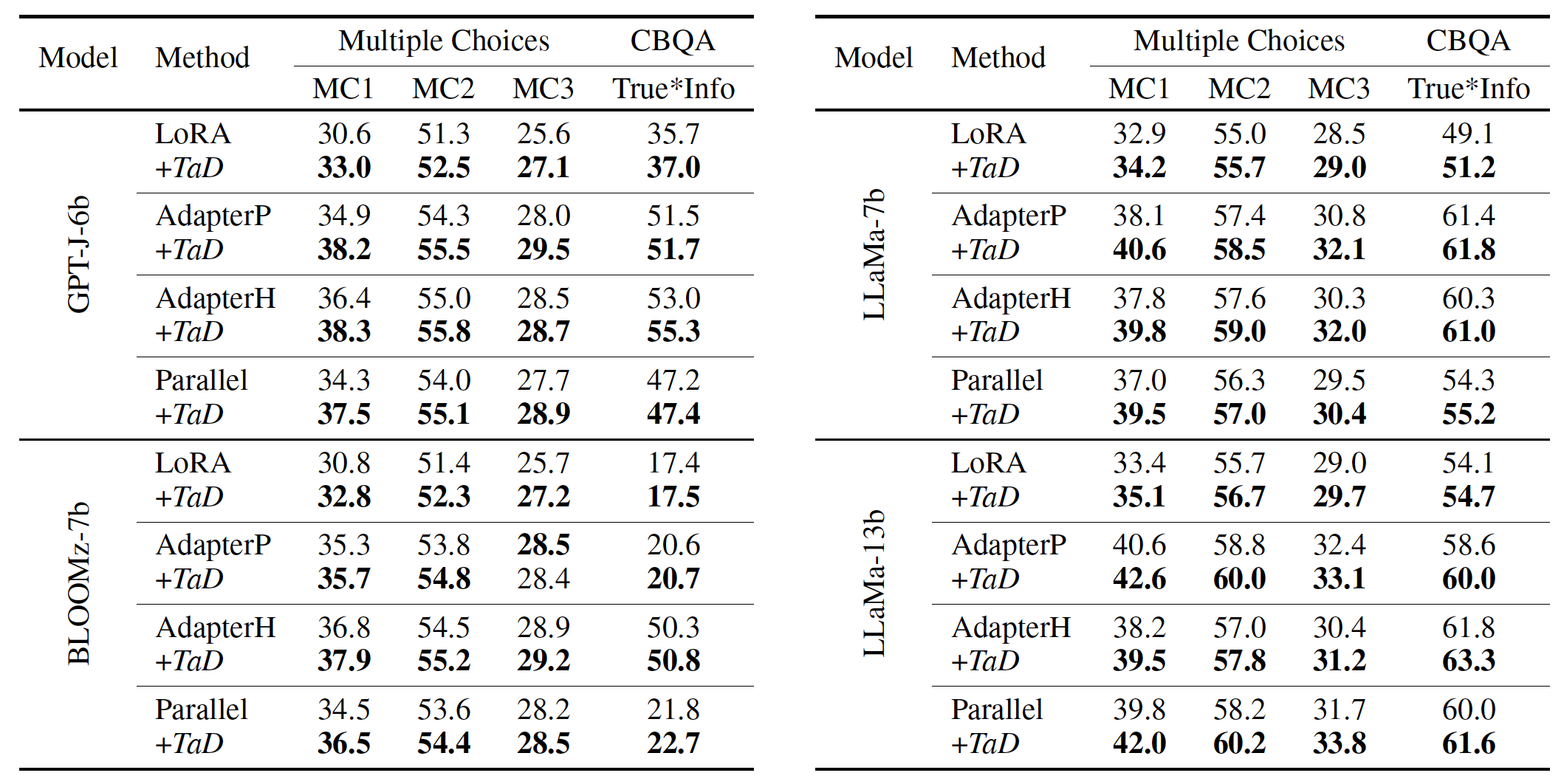
表2. 更具挑戰(zhàn)性的推理任務(wù)結(jié)果
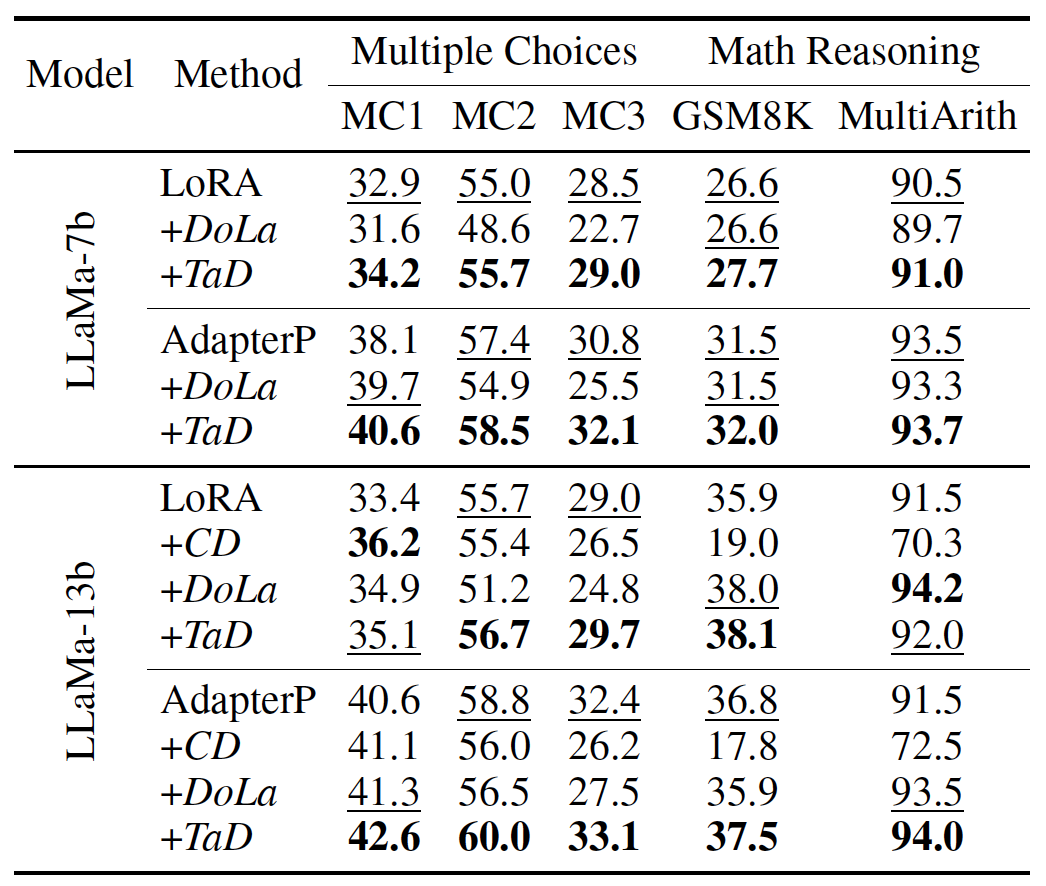
2)相比較其他對比解碼技術(shù),TaD技術(shù)在絕大部分場景下效果占優(yōu),具體如表3所示。需要特別強(qiáng)調(diào)的一點是,其他技術(shù)可能會導(dǎo)致LLM效果下降,TaD未表現(xiàn)上述風(fēng)險。
表3. 不同對比解碼技術(shù)結(jié)果
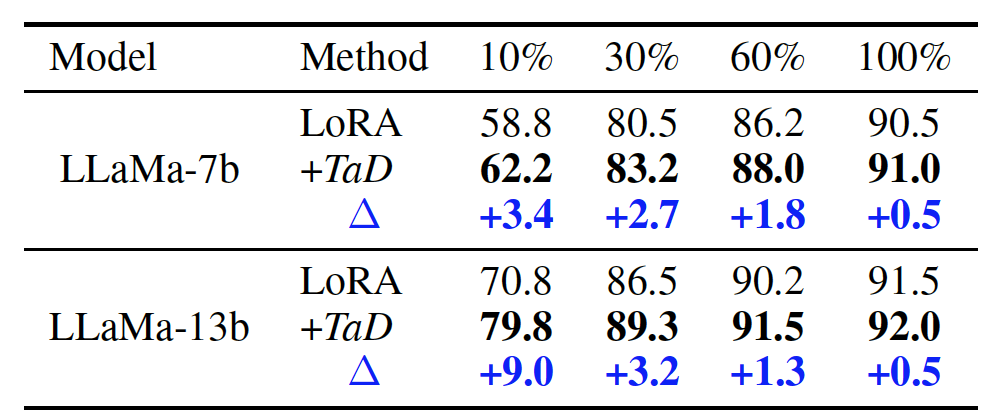
3)針對不同比例的訓(xùn)練樣本進(jìn)行實驗,發(fā)現(xiàn)一個非常有趣的結(jié)果:訓(xùn)練樣本越少,TaD技術(shù)帶來的收益越大,具體如表4所示。因此,即使在有限的訓(xùn)練數(shù)據(jù)下,TaD技術(shù)也可以將LLM引導(dǎo)到正確的方向。由此可見,TaD技術(shù)能夠在一定程度上突破訓(xùn)練數(shù)據(jù)有限情形下LLM的效果限制。
表4. 不同數(shù)據(jù)比例下的結(jié)果
可見,TaD可以即插即用,適用于不同LLM、不同微調(diào)方法、不同下游任務(wù),突破了訓(xùn)練數(shù)據(jù)有限的瓶頸,是一項實用且易用的改善LLM自身幻覺的技術(shù)。
4. 落地案例
自從以ChatGPT為代表的LLM誕生之后,針對其應(yīng)用的探索一直如火如荼,然而其幻覺已然成為限制落地的最大缺陷。綜上分析,目前檢索增強(qiáng)生成(RAG)+低幻覺的LLM是緩解LLM幻覺的最佳組合療法。在京東通用知識問答系統(tǒng)的構(gòu)建中,我們通過TaD技術(shù)實現(xiàn)低幻覺的LLM,系統(tǒng)層面基于RAG注入自有事實性知識,具體方案如圖5所示,最大程度緩解了LLM的生成幻覺 。
圖5. TaD+RAG的知識問答系統(tǒng)
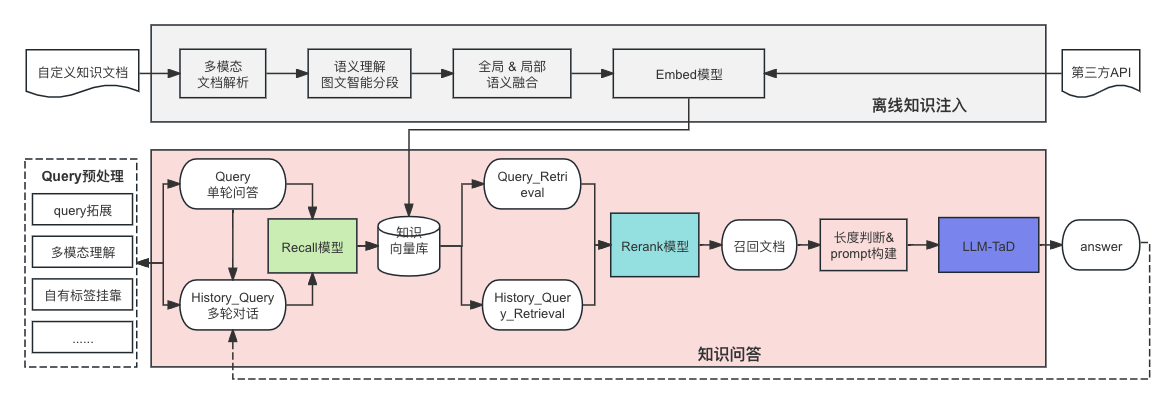
目前知識問答系統(tǒng)已經(jīng)接入京東6000+業(yè)務(wù)場景,為用戶提供準(zhǔn)確、高效、便捷的知識性問答,大大節(jié)省了運營、運維等人力開銷。
5. 思考與展望
如果LLM依然按照語言模型的模式發(fā)展,那么其幻覺就無法徹底消除。目前業(yè)內(nèi)還沒有一種超脫語言模型范疇,且可以高效完成自然語言相關(guān)的任務(wù)新的模型結(jié)構(gòu)。因此,緩解LLM的生成幻覺,仍然是未來一段時期的探索路徑。以下是我們在系統(tǒng)、知識、LLM三個層面的一些簡單的思考,希望能夠拋磚引玉。
系統(tǒng)層面——RAG+Agent+More的復(fù)雜系統(tǒng)
RAG技術(shù)確實在一些常見的自然語言處理任務(wù)中發(fā)揮出色的作用,尤其是針對簡單問題和小型文檔集。但是遇到一些復(fù)雜的問題和大型文檔集時,RAG技術(shù)就顯得力不從心。近期有一些研究認(rèn)為RAG+Agent才是未來的趨勢[14],Agent能夠輔助理解并規(guī)劃復(fù)雜的任務(wù)。我們認(rèn)為可能未來的系統(tǒng)可能不僅僅局限于Agent和RAG,可能還要需要多種多樣的內(nèi)外工具調(diào)用、長短期記憶模塊、自我學(xué)習(xí)模塊......
知識層面——與LLM深度融合的注入方式
任何一個深度模型都會存在知識邊界的問題,LLM也不例外。RAG通過檢索的方式召回外部知識,以Prompt的形式送入LLM進(jìn)行最終的理解和生成,一定程度上緩解LLM知識邊界問題。但是這種知識注入的方式和LLM生成的過程是相對割裂的。即便已經(jīng)召回了正確的知識,LLM也可能因為本身知識邊界問題生成錯誤的回答。因此探索如何實現(xiàn)外部知識和LLM推理的深度融合,或許是未來的一個重要的課題。
LLM層面——低幻覺LLM
LLM本身的幻覺是問題的根本和瓶頸,我們認(rèn)為隨著LLM更廣泛的應(yīng)用,類似TaD可緩解LLM本身幻覺的探索一定會成為業(yè)內(nèi)的更大的研究熱點。
6. 結(jié)語
緩解LLM幻覺一定是個復(fù)雜的系統(tǒng)問題,我們可以綜合不同的技術(shù)方案、從多個層級協(xié)同去降低LLM的幻覺。雖然現(xiàn)有方案無法保證從根本上解決幻覺,但隨著不斷探索,我們堅信業(yè)內(nèi)終將找到限制LLM幻覺的更有效的方案,也期待屆時LLM相關(guān)應(yīng)用的再次爆發(fā)式增長。
京東零售一直走在AI技術(shù)探索的前沿,隨著公司在AI領(lǐng)域的不斷投入和持續(xù)深耕,我們相信京東必將產(chǎn)出更多先進(jìn)實用的技術(shù)成果,為行業(yè)乃至整個社會帶來深遠(yuǎn)持久的影響。
【參考文獻(xiàn)】
[1] Hallucination is Inevitable: An Innate Limitation of Large Language Models
[2] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
[3] Unveiling the Causes of LLM Hallucination and Overcoming LLM Hallucination
[4] Editing Large Language Models: Problems, Methods, and Opportunities
[5] ACL 2023 Tutorial: Retrieval-based Language Models and Applications
[6] Theoretical Limitations of Self-Attention in Neural Sequence Models
[7] Sequence level training with recurrent neural networks.
[8] Discovering language model behaviors with model-written evaluations
[9] Dola: Decoding by contrasting layers improves factuality in large language models
[10] Bert rediscovers the classical nlp pipeline
[11] Retrieval-Augmented Generation for Large Language Models: A Survey
[12] TaD: A Plug-and-Play Task-Aware Decoding Method toBetter Adapt LLM on Downstream Tasks
[13] Inference-time intervention: Eliciting truthful answers from a language model
[14] Beyond RAG: Building Advanced Context-Augmented LLM Applications
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
33711瀏覽量
274465 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1585瀏覽量
8708 -
大模型
+關(guān)注
關(guān)注
2文章
2960瀏覽量
3706 -
LLM
+關(guān)注
關(guān)注
1文章
317瀏覽量
656
發(fā)布評論請先 登錄
名單公布!【書籍評測活動NO.52】基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術(shù)解讀
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+第一章初體驗
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】RAG基本概念
《AI Agent 應(yīng)用與項目實戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識庫
人類新療法的第一項研究證明了這是一種無創(chuàng)、無害的癌癥殺手
新興的人工智能(AI)技術(shù)具有加速和轉(zhuǎn)變對分子療法的搜索的潛力
基于磁共振成像的心房顫動新療法
大模型現(xiàn)存的10個問題和挑戰(zhàn)

最新研究綜述——探索基礎(chǔ)模型中的“幻覺”現(xiàn)象
幻覺降低30%!首個多模態(tài)大模型幻覺修正工作Woodpecker

全球首款支持 8K(8192)輸入長度的開源向量模型發(fā)布
利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(下)

什么是RAG,RAG學(xué)習(xí)和實踐經(jīng)驗
RAG的概念及工作原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論