 SLM片內監控IP數據分析顯著減少測試成本
SLM片內監控IP數據分析顯著減少測試成本
SLM片內監控IP數據分析為高價值應用提供了更為自動化的數據分析手法。
一直以來,片內監控IP是為開發者提供量測芯片內部工作狀態,評估產品功耗等關鍵性能指標的核心技術方案。片內監控IP(例如常見的ring oscillator)采集的數據有助于在芯片制造階段(即芯片放入最終設備之前)了解和判斷芯片是否滿足必要的功耗或性能要求。然而,這個過程中的挑戰在于:即便能在制造測試不同階段期間收集所有數據,但數據分析方法仍大量依賴于手動操作,而且需要經驗豐富的產品開發者運用專業知識來預處理和解釋數據分析結果。
如今,芯片生命周期管理(Silicon Lifecycle Management )解決方案的生產和監控分析方案取得了長足進步,大大提高了分析過程的自動化程度,幫助用戶進一步自動化識別產品功耗和性能等關鍵問題,大大提升了開發效率。此外,片內監控IP數據分析還首次實現了對Vmin優化等關鍵應用的自動化處理。將嵌入式監控IP的數據與前沿機器學習算法相結合,有助于確定更低、更優的Vmin值,從而降低器件功耗并延長現場使用壽命,并顯著減少測試成本。
SLM片內監控IP
如圖1所示,在完成產品設計和流片后,可能會遇到這樣的問題:實際芯片的運行速度比規格值慢,設計中的某些IP不起作用(例如,4核器件設計的其中2個內核不起作用),或者芯片已完全失效。
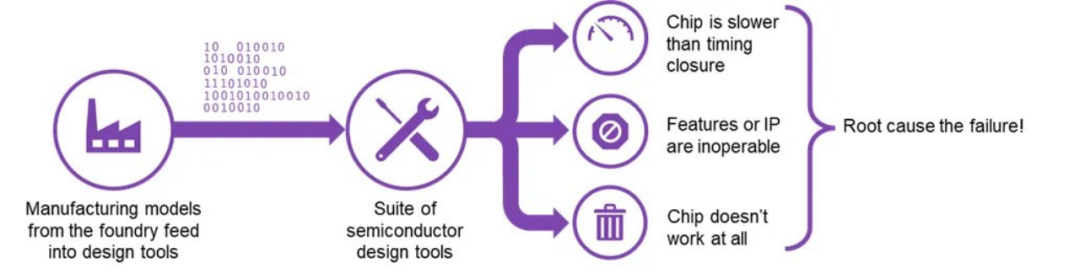
▲圖 1:首次流片中遇到的典型問題
此時,產品良率負責人或產品開發者需要準確了解芯片內部發生的情況,嘗試找出這些問題的根本原因并加以調試。這通常要用到嵌入式SLM片內監控IP。另外,工藝、電壓和溫度(PVT)傳感器也可以為根本原因分析提供關鍵信息。
雖然PVT IP用途很廣,但在目前的先進SoC中,用于測量芯片功耗和性能的工藝檢測IP正日益發揮關鍵價值。電壓傳感IP的分析數據有助于檢測芯片的具體壓降狀況,并直接與測試儀上特定的測試失敗情況相關聯。與此類似,溫度傳感IP的分析數據可以揭示芯片內部的溫度梯度(例如芯片某區域存在過熱問題),并直接對應到測試儀上的特定測試失效結果,進而協助找出失效的根本原因。
相對來說工藝檢測IP主要用于測量芯片的工藝健康狀況,屬于hard IP,是專為特定代工廠的各個工藝節點而設計的。此類器件中包含由各種反相器、NAND或NOR標準單元構成的環形振蕩器鏈(ring oscillator),在設計中通常用于組成簡單、獨立且同構的邏輯集群。例如,采用反相器標準單元的環形振蕩器由奇數個反相器組成,每個反相器的輸出端都連接到下一個反相器的輸入端,而最后一個單元的輸出端則連接至第一個單元的輸入端,從而形成閉環。正如其名,器件導通時,這些RO鏈將會自限性地快速振蕩。在正常情況下,RO鏈將以盡可能高的頻率運行;而一旦芯片出現異常或失效,其振蕩頻率會顯著降低。
從這些監控IP獲得的數據通常需經過手動分析并繪制成圖表,以便與代工廠的流片前時序模型進行比較。在極端情況下,可能會遇到保持時間違例等時序相關問題,例如實際芯片比時序模型快,或者芯片的運行速度達不到設計性能要求。在這兩種情況下,都可以通過SLM片內傳感IP數據分析方案來進一步找出根本原因,并識別導致這些時序問題的具體cell。此外,如果性能表現在正常范圍內,但設計的裕量過大,則可以在確保仍滿足性能要求的前提下,通過選擇速度較慢的cell來進一步降低功耗。
Path Margin Monitor是一種新型嵌入式監控IP,目前也正廣泛采用。這些監控IP會在產品制造測試期間,測量特定功能邏輯路徑的裕量,以此來提高芯片特征測量結果的質量。不過,與作為hard IP且放置在芯片裸片外圍的工藝檢測IP不同,PMM屬于soft IP,可以獨立于工藝節點合成到設計中,并放置在任何邏輯路徑旁。通過定期測量路徑的裕度,PMM使開發者能夠評估器件在使用壽命內的老化情況。器件的裕度可能會隨器件老化而降低。而PMM的數據可以提示是否需要調整器件的頻率或工作電壓,從而能夠延長器件的使用壽命,此外還有助于開發者在器件發生故障之前識別并召回所有即將出現故障的器件。
SLM片內監控分析的興起
分析來自片內監控IP的數據一直都需要手動操作,非常耗時費力。這個過程通常涉及收集和存儲大量數據,然后還要從數據庫中下載數據。繼而,開發者必須花費數小時手動分類,定義合并和堆疊數據集以生成一些圖表。期間還需要自行評估并確定是否存在要采取糾正措施的問題。這是一個繁瑣而緩慢的過程,必須周而復始地進行。在芯片的生命周期中,從早期新產品導入(NPI)階段到大批量制造(HVM)期間的維護狀態下,都必須執行這個過程,以此觀察芯片隨時間推移的運行情況。因此,SLM In-Chip Monitor Analytics的目標是自動執行這一繁瑣分析過程,讓開發者可以一鍵獲得可行的信息,從而將相關耗時從數小時縮短至幾分鐘。
為實現這個自動化目標,需要將以下幾個要素整合到同一個分析解決方案中:
來自監控IP的數據
來自這些監控器的設計元數據,例如物理特征 - 2/3/4鰭片變體、SVT/LVT/ULVT Vt或閾值電壓樣式
仿真元數據,例如FF/TT/SS/FS/SFcorner 條件
測試元數據,例如測試芯片時的電壓、頻率和溫度
下方圖2為自動化目標差距分析的結果。這是一個標準漏斗圖,描繪了所有生產的芯片中,具有相同物理特性的RO鏈在不同電壓下的測試結果,并與foundry的仿真設計目標進行了比較。實際上,就是獲取測試儀的測量結果并將其除以TT(Typical, Typical)目標值,其中TT代表典型PMOS和典型NMOS仿真時序結果。此外,為了完善漏斗圖的邊界,圖中還加入了FF(Fast, Fast)目標值和SS(Slow, Slow)目標值,并將它們同樣除以TT目標值,以確定在漏斗圖中的相對位置。
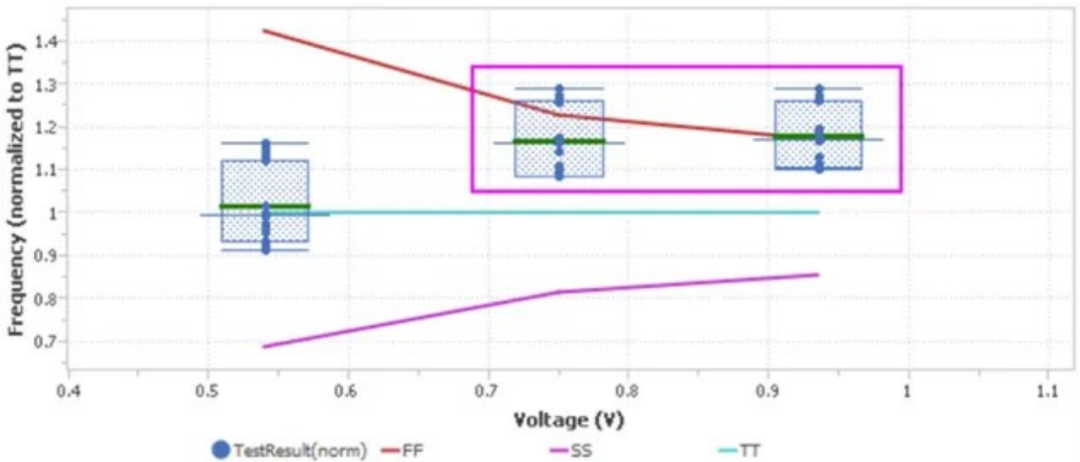
▲圖 2:單個環形振蕩器鏈在三(3)種不同電壓下測試的漏斗圖
理想情況下,如果沒有異樣或偏差,所有經測試的芯片性能都應該位于青色的TT線上。但在本例中,測試期間提高電壓時,有一半芯片的運行速度要比FF目標值快,這表示存在掃描鏈hold timing violation。因此,如果這些器件發生掃描鏈失效,可以借助此監控分析來找出問題的根本原因。
如下方圖3所示,監控分析已擴展到包含3條具有獨特物理特征的RO鏈。它們的鰭片數量、柵極類型以及負載電容均相同,但Vt(例如閾值電壓)不同。對于其各自的不同Vt,測試中分別標記為VT1、VT2和VT3。
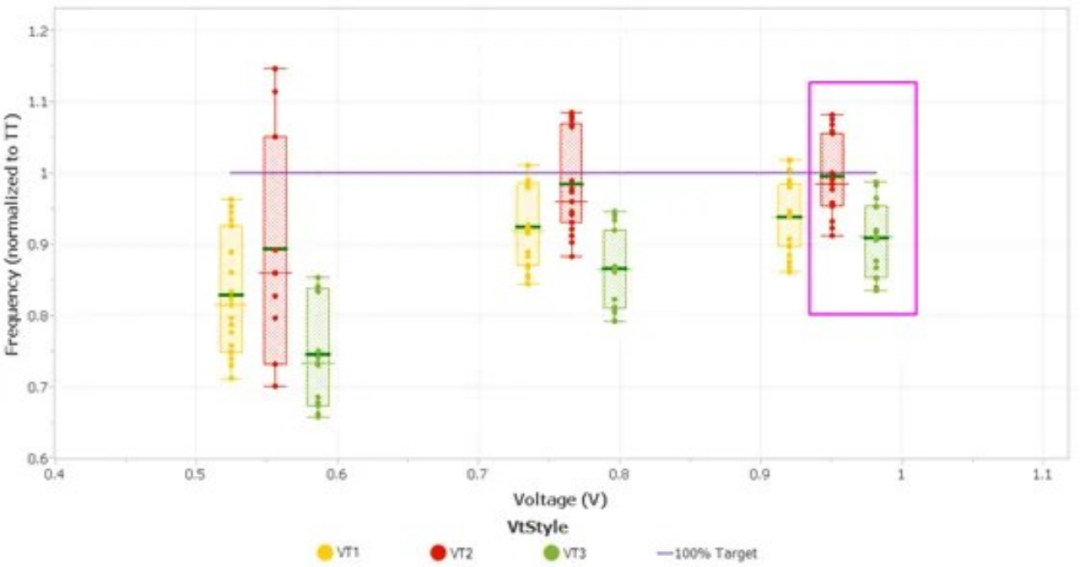
▲圖 3:Vt不同的3個獨特RO鏈的箱線圖
結果顯示,在較高電壓下,RO鏈間的偏差較大,其中VT2大致達到目標,而VT3低于目標。此類偏差預示著潛在的時序故障。
監控分析解決方案可以提供更多分析信息,以便進行詳盡的實驗設計(DOE),了解各種物理晶體管特征會如何影響多個RO鏈中的性能,從而確定DOE的哪個部分對與TT目標值的差距影響最大。
例如,下方圖4顯示了一個多變量DOE,可以獨立執行一系列詳盡的物理實驗,確認圖3中所示的研究結果,即在統計上,VT3與目標的差距明顯比VT2要大。此外,所有實驗的相關性表明,Vt類型對該差距的影響要比鰭片、柵極類型等更大。
圖4中還包含了一個回歸樹。回歸樹是一種統計方法,可以通過分類變量來分解連續變量。本例中,分類變量為RO DOE,即構成RO的所有物理特征;連續變量為與目標的差距。對整個芯片總體進行實驗排列之后,回歸樹可以指示在其中哪個分類變量(例如物理屬性)對連續變量的影響最大。在本例中,Vt類型是導致目標差距最大的相關因素。對于某條關鍵路徑,如果懷疑存在負裕量問題或遇到了芯片故障,且認為這些問題是由VT3引起的,則可以考慮將VT3單元更換為VT2單元,因為VT2的性能更具可預測性。
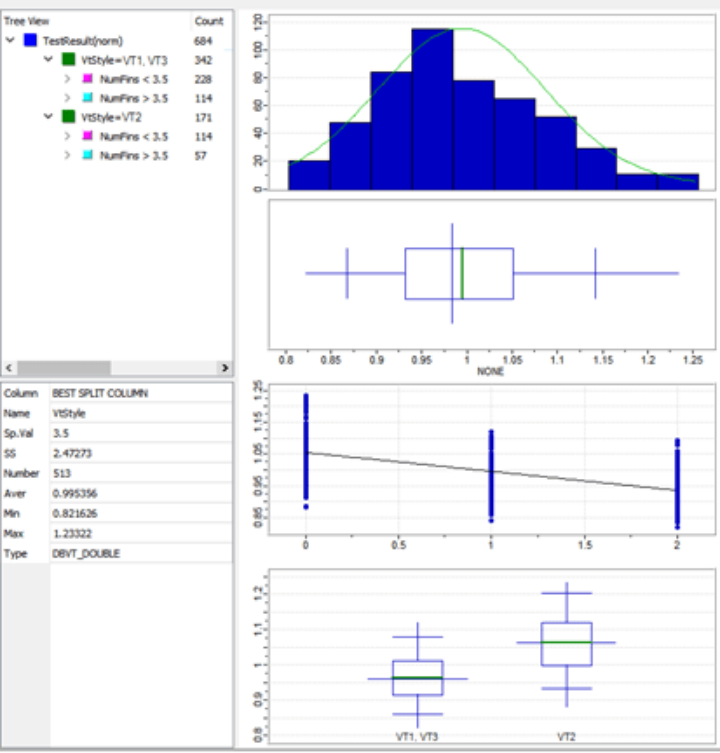
▲圖 4:確定哪些物理特征對與TT目標值的差距影響最大的多變量DOE
使用監控分析解決方案對芯片進行工藝分類以實現自動化的例子還有很多,圖5為一個典型分析工具輸出模板,用戶可以從中選擇和查看多種不同的分析輸出報告。
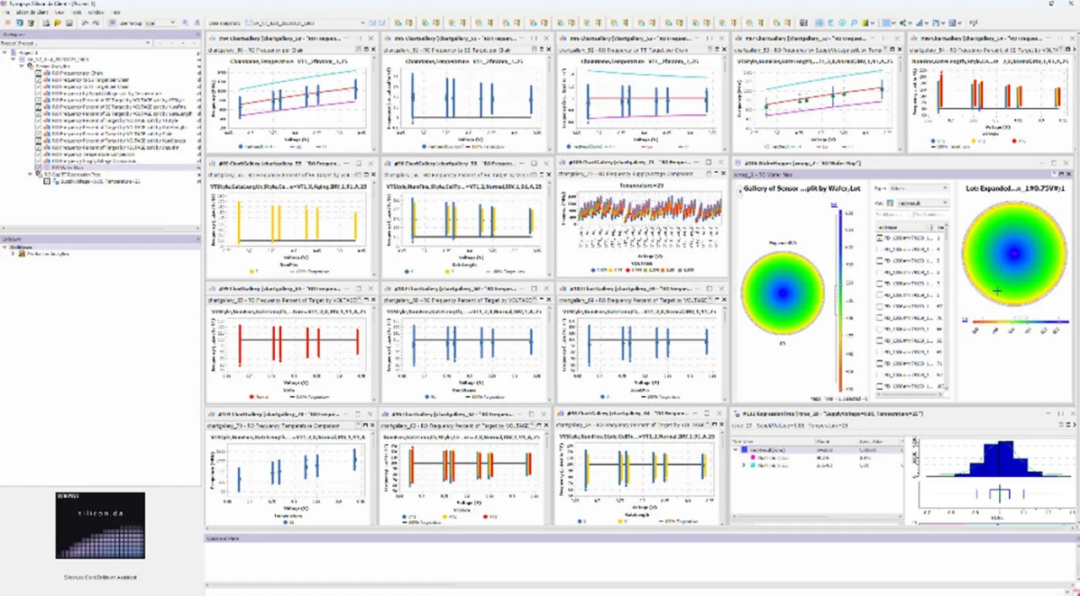
▲圖 5:由Silicon.da Monitor Analytics執行的工藝分類分析報告。
不過,工藝分類只是監控分析的主要用例之一。其他用例還有許多,例如Vmin預測。
Vmin預測
Vmin預測具有諸多優勢,目前也正日益普及。首先,確定器件在滿足性能要求情況下的最低運行電壓對于提升器件能效有著重大影響。運行電壓越低,器件消耗的電量就越少。這主要體現在兩個方面:(1)提高器件/設備(例如手機)的性能;(2)最終延長器件/設備的使用壽命。不過,盡管這非常重要,但每個器件的最低工作電壓各不相同,這并不容易實現。要想獲得每個器件的真實Vmin,就必須大量進行制造測試,這不僅耗費大量時間,影響產品上市進程,還會增加測試成本。如果有一種方法可以精確預測真實的Vmin,且無需大量投入時間和成本,無疑將為產品開發者創造巨大價值。
盡管多年來開發者們一直在嘗試預測Vmin,但并不是所有的方法都能取得理想效果。為了塑造準確的Vmin預測模型,需要以下幾個關鍵要素:(1)穩健的機器學習(ML)模型;(2)實際測量并收集器件樣本的Vmin,以協助訓練模型;(3)來自監控IP的數據(例如前面討論過的PVT和PMM),以提供器件的更多特征,從而提高模型的準確度。
下方圖6顯示了兩種不同Vmin預測模型的準確度差異。預測模型越好,測量值與預測值之間的相關性就越緊密(右側圖表)。理想情況是模型可以準確預測要測量對象的Vmin。
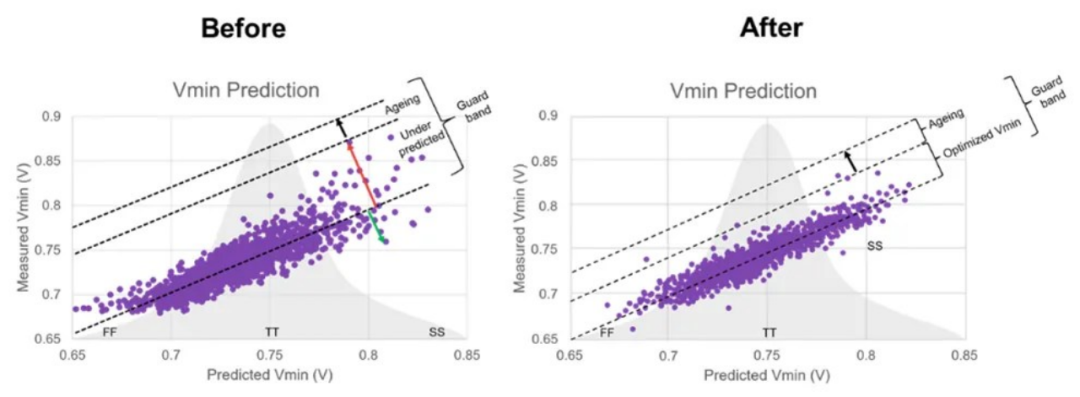
▲圖 6:準確度不同的兩個Vmin預測模型
圖中,x=y線下方表示預測的Vmin與該器件的Vmin測量值相同或較之更高,因此線下方的器件均符合要求。而線上方則表示預測值小于測量值,相關器件不符合要求。為了確保器件良率足夠高,同時考慮補償器件老化影響,考慮在Vmin預測值的基礎上增加一個小幅度電壓(guard band)。不過,在補償電壓之前,如果大多數器件已符合要求,則可能不需要額外的guard band。在這種情況下,可以將預測的Vmin作為測試起點,進一步展開Vmin測試,尋找更優Vmin。
要將Vmin預測模型投入實際應用,可參考圖7在生產中建立該模型的相關規程。
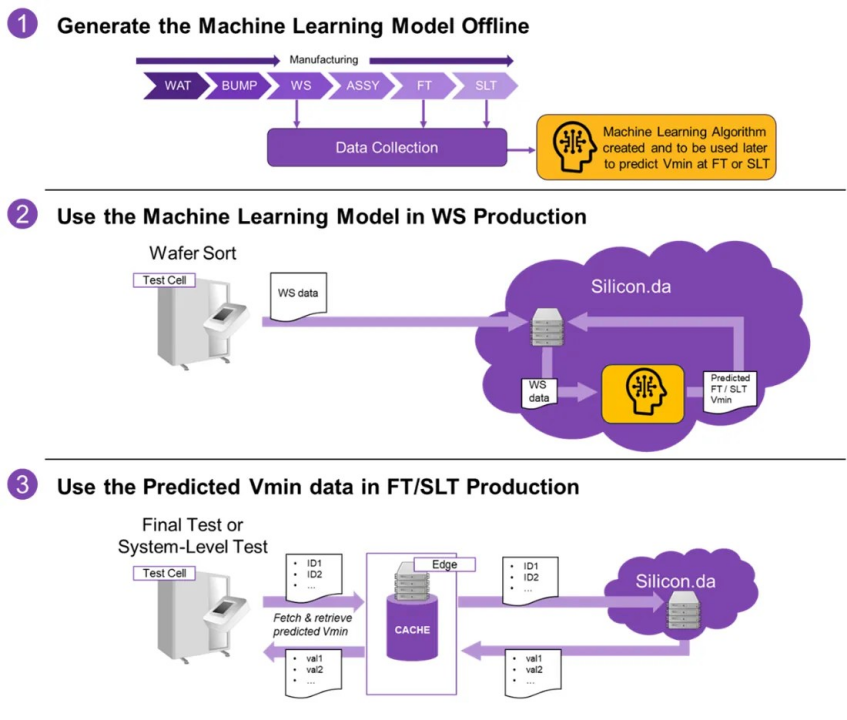
▲圖 7:Vmin預測的相關規程
其中第一步是在預先確定的一組器件上創建和訓練ML模型。這一步需實際測量Vmin,收集的Vmin測量數據是訓練模型的關鍵要素。
第二步是將下一批新芯片在晶圓分類過程中收集的生產數據應用于該模型。請注意,此時不再需要實際執行Vmin測試,因為ML模型將能預測在FT和/或SLT期間要使用的Vmin值。預測的Vmin將離線存儲在數據庫中,以供FT或SLT測試期間使用。
第三步(也是最后一步)為在FT或SLT測試期間利用預測的Vmin。測試開發者可以將該預測值作為最終產品的Vmin;如需改進結果,可以將Vmin 預測值用作進一步測量Vmin測試的起點。開發者可以將此值作為起點,對測量的Vmin進一步展開測試。利用預測值作為起始點,從而顯著減少測試時間。
為綜上所言,為了在整個生命周期內監控和維護器件的健康狀況,并改善功耗和性能等關鍵運行指標,開發者需要了解復雜SoC中的實際運行情況。不然就像無頭蒼蠅,只能通過耗費大量的開發和測試成本才能加以改進。新思SLM Analytics的片內監控IP數據分析方案另辟蹊徑為廣大開發者提供了直觀呈現監控數據和自動生成數據分析的技術思路,從而更高效地實現這些關鍵KPI。
-
芯片
+關注
關注
455文章
50714瀏覽量
423137 -
機器學習
+關注
關注
66文章
8406瀏覽量
132558 -
數據分析
+關注
關注
2文章
1445瀏覽量
34050
原文標題:芯片開發者的Next Level:如何在制造階段快速精準實現那些關鍵KPI?
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MTIE、TDEV數據分析說明
數據分析需要的技能
加快MIMO測試速度和降低測試成本的方法
RF整合到SOC怎么減少測試成本?
BI分享秀——高度開放的數據分析經驗共享
BI數據分析軟件使用指南
電商數據分析攻略,讓你輕松搞定數據分析!
利用測試排序儀器降低測試成本
用標準數據分析方案做數據可視化更省成本
使用校準降低衛星設計和測試成本





 工商網監
工商網監
評論