 基于高光譜數據的典型地物分類識別方法研究
基于高光譜數據的典型地物分類識別方法研究
一、引 言
隨著光譜學的不斷發展,人們對地物光譜屬性、特征的認知也在不斷深入,許多隱藏在狹窄光譜范圍內的地物特性逐漸得以發現。高光譜數據具有光譜范圍廣、光譜分辨率高、數據量大等特點,更容易獲取地物的局部精細信息,對光譜細節特征具有良好的表現能力。自從高光譜技術誕生以來,已有大批學者在農作物識別與分類、土壤重金屬污染監測、植被識別與分類等高光譜分類領域進行廣泛研究。如何探究不同樣本間光譜特征差異以及提高分類識別精度是當前高光譜分類領域需解決的重要問題。
針對上述科學問題,諸多學者分別開展了基于對原始光譜數據進行光譜變換、平滑等預處理技術,然后通過主成分分析、支持向量機等傳統方法應用于高光譜分類識別研究。傳統方法可以應用于高光譜分類識別研究,但預處理方法有很多種,如何選擇和組合這些方法會對分類結果產生很大影響,由此造成的耗時長、分類精度較低等問題一直難以解決。
隨著數據集規模的增加和人工智能(AI)快速的發展,機器學習(ML)在各個科學領域的應用越來越流行。深度學習作為機器學習領域中一個新的研究方向,近年來也逐漸應用于光譜分類、光譜檢測等領域中。
隨著成像光譜儀器的廣泛應用,利用光譜數據進行物質分類與識別已經成為一項重要的研究內容,研究不同分類算法對最終的目標識別準確度具有重要意義。目前現有研究中主要分為傳統方法和深度學習方法,傳統方法存在耗時長、分類精度較低等問題,深度學習方法能夠簡化預處理步驟,取得較高精度,但大多數研究只進行單次訓練,并沒有針對錯分樣本進行精細研究,很難從光譜特征分析的角度解釋分類結果。首先,利用連續投影算法(SPA)進行基礎波段篩選,探究特征波段對原始光譜的信息承載能力,由此探究不同地物間光譜特征的差異。
二、實驗數據與分析
2.1研究區域與樣本
本次實驗所選區域為黑龍江省雙鴨山市友誼農場,糧食作物有大豆、玉米、水稻等,經濟作物有甜菜、葵花籽、白瓜籽、烤煙等。測量地物為玉米、大豆和水稻,其中5月由于播種時間較短,玉米、大豆在土壤中屬于剛出芽的狀態,因此將5月的玉米和大豆樣本劃分為裸土類別。共選取697個樣本,其中大豆204個樣本、玉米190個樣本、水稻40個樣本、裸土263個樣本。
2.2 儀器設備與采集方法
本次測量可使用萊森光學便攜式地物光譜儀,其光譜測量范圍覆蓋近紫外-可見光-近紅外波段。光譜測量在野外進行,選擇地表覆蓋均勻且場地最短邊長度不小于50m的人工或天然場地為本次反射率測量場地。對基本采樣單元采用十字五點采樣法進行光譜采集。測量了大豆、玉米、水稻和裸土的反射率光譜并拍照記錄各類地物表面狀態,如圖1所示。測量時,光譜儀探頭距離地物1m,因此采集到的大豆、玉米光譜為葉片和土壤的混合光譜,水稻光譜為葉片和水體的混合光譜。

圖1 4類地物表面狀態。(a)大豆;(b)玉米;(c)水稻;(d)裸土
2.3光譜預處理
對采集到的4類地物原始光譜數據進行分析,如圖2所示。波長范圍在350~1800nm內,各個地物光譜曲線較為平滑,沒有明顯的光譜噪聲,在波長為1800nm附近存在嚴重的噪聲,這是由于在波長為1800nm處存在水汽吸收通道,與地物的含水量有關。此外,由于測量在野外進行,天氣環境和操作的影響導致在波長為1800nm之后的光譜信息有較大的波動且含有噪聲數據。如果采用全波段光譜數據進行后續分析處理,會對所建分類模型的精度產生極大影響,導致模型不可靠。因此,選擇采用波長范圍在350~1800nm的光譜數據進行相關分析,為了簡化傳統方法采用一些預處理步驟,不再對光譜數據進行其他變換,直接利用截取后的光譜數據進行后續分析處理。
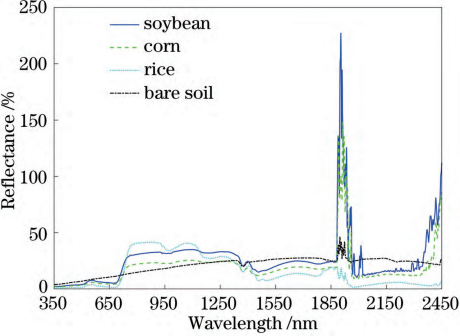
圖2 350~2500 nm 四類地物平均反射率光譜曲線
2.4光譜特征分析
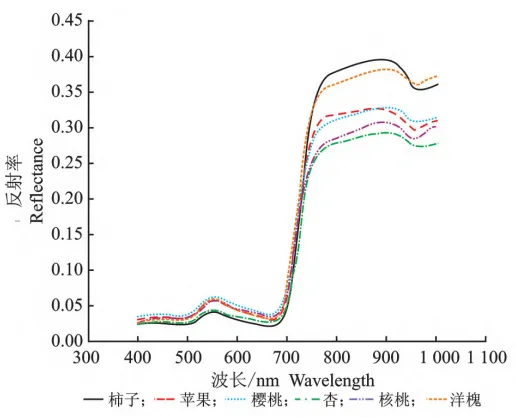
波長范圍在350~1800nm的4類地物光譜數據,如圖3所示。由圖3可知,大豆、玉米和水稻等3種地圖2350~2500nm四類地物平均反射率光譜曲線物的反射光譜曲線走勢一致,同其他綠色植被一樣,在波長為670nm的紅光波段有一處吸收帶,其反射率較低;在波長為550nm的綠光波段有一個明顯的反射峰;在波長為700nm處反射率急速增高,至波長為1100nm的近紅外波段反射率達到高峰,這是植被的獨有特征;在波長為1300nm之后,因綠色植物含水量的影響,吸收率增大,反射率大大下降,在水的吸收帶形成低谷。在部分波段范圍內,3種地物的光譜曲線存在一些差異,例如波長范圍在450~650nm內,水稻的光譜反射率最低,這是由于測量的水稻光譜為葉片和水體的混合光譜,水的反射率較低。大豆和玉米在整個波段范圍內光譜反射率相近,二者難以區分。裸土的光譜曲線比較平滑,沒有明顯的峰值和谷值,但在整個波段范圍內,裸土的反射率與其他3種地物有較大部分的重合,容易出現混淆的現象。
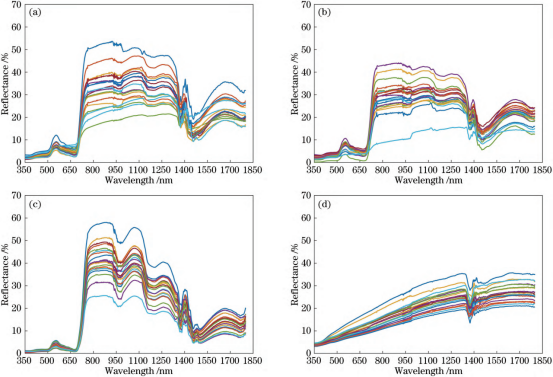
圖3 350~1800nm四類地物部分樣本光譜曲線(20條)。(a)大豆;(b)玉米;(c)水稻;(d)裸土
結果與討論
3.1數據集劃分
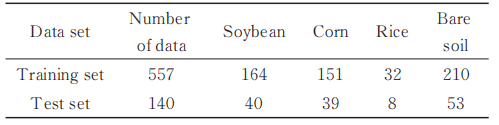
本次實驗將數據集按8∶2劃分為訓練集和測試集,如表1所示,各個樣本隨機選樣。
表 1數據集統計
3.2特征波段選取
高光譜數據一些相鄰波段之間存在著較強的相關性,導致光譜數據包含大量的冗余信息,如果直接將原始光譜數據輸入到深度學習模型,可能會導致模型出現過擬合現象,嚴重影響模型的處理速度。因此,選擇使用SPA對原始光譜數據進行特征波段篩選,通過篩選后的少量波段信息承載原始高維信息。
3.3 SPA原理
SPA是前向特征變量選擇方法。SPA利用向量的投影分析,通過將波長投影到其他波長上,比較投影向量大小,以投影向量最大的波長為待選波長,然后基于矯正模型選擇最終的特征波長。SPA選擇的是含有最少冗余信息及最小共線性的變量組合。該算法簡要步驟如下:記初始迭代向量為xk()0,需提取的變量個數為N,光譜矩陣為J列。
1)任選光譜矩陣的1列(第j列),將建模集的第j列賦值給xj,記為xk()0。
2)將未選入的列向量位置的集合記為s:
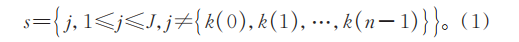
3)分別計算xj對剩余列向量的投影:
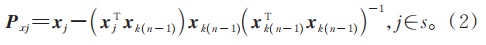
4)提取最大投影向量的光譜波長:
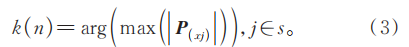
5)令xj=Px,j∈s。6)n=n+1,若n
最后,提取出的變量為{xk( )n=0,1,?,N-1}。對應每一次循環中的k(0)和N,其中最小的均方根誤差(RMSE)對應的k(0)和N就是最優值。一般SPA選擇的特征波長分數N不能很大。
3.4 特征波段集合
利用SPA,根據RMSE最小化原則,選出最能有效區分不同地物類型的特征波段,如圖4所示。
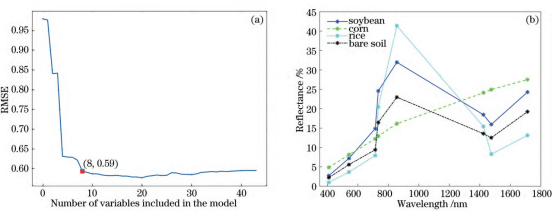
圖4SPA特征波段選擇結果。(a)RMSE;(b)平均光譜反射率
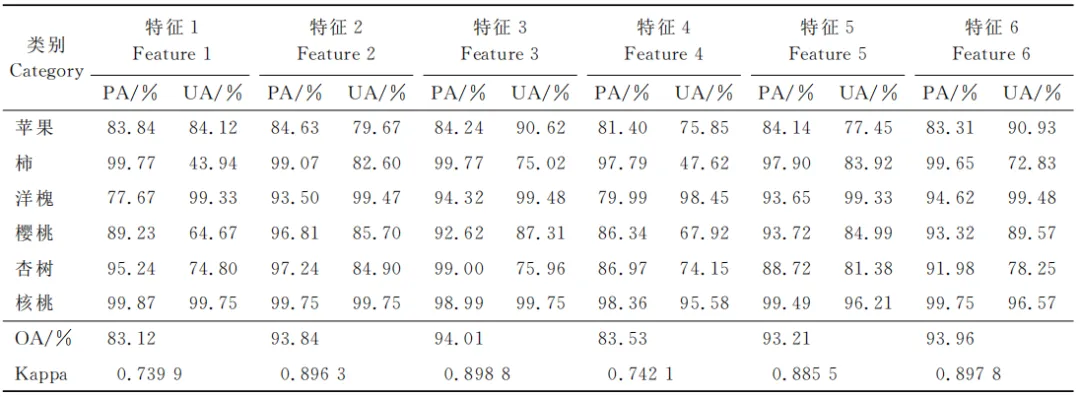
共選擇8個波段,分別為410nm、542nm、714nm、734nm、856nm、1423nm、1475nm、1712nm。各類地物樣本點在不同特征波段組合方式下的分布情況能夠反映出各類地物在不同波段上的特征,可以初步判斷所篩選的特征波段能有效區分各類地物。以4類地物在410nm波段和其他波段相互組合為例,如圖5所示,4類地物都表現出了不同特征:其中大豆和玉米的樣本點在各個波段上分布都較為分散,且出現大量交集,說明這兩種地物的光譜特征相近,僅憑篩選特征波段無法實現有效區分;水稻和裸土的樣本點出現聚集現象,其中水稻的樣本點與玉米的樣本點有小部分重合,裸土的樣本點與大豆的樣本點有小部分重合,在分類時容易混淆。總體來看,篩選出的特征波段能夠有效代表4類地物的特征信息,可以初步區分部分地物樣本,但效果并不理想,尤其是難以區分大豆和玉米。因此,需利用不同分類識別方法開展進一步研究。
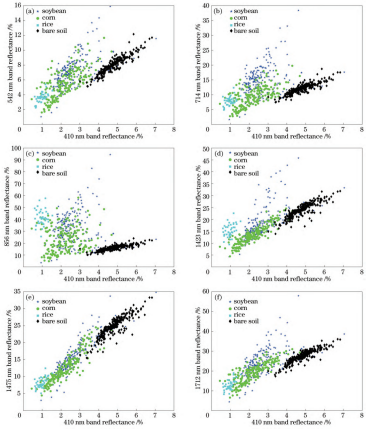
圖5地物樣本點分布。(a)410nm和542nm;(b)410nm和714nm;(c)410nm和856nm;(d)410nm和1423nm;(e)410nm和1475nm;(f)410nm和1712nm
推薦:
地物光譜儀iSpecField-HH/NIR/WNIR
地物光譜儀是萊森光學專門用于野外遙感測量、土壤環境、礦物地質勘探等領域的最新明星產品,獨有的光路設計,噪聲校準技術、可以實時自動校準暗電流,采用了固定全息光柵一次性分光,測試速度快,最短積分時間最短可達20μs,操作靈活、便攜方便、光譜測試速度快、光譜數據準確,廣泛應用于遙感測量、農作物監測、森林研究、海洋學研究和礦物勘察等各領域。

審核編輯 黃宇
-
高光譜
+關注
關注
0文章
330瀏覽量
9934 -
地物光譜儀
+關注
關注
0文章
75瀏覽量
3241
發布評論請先 登錄
相關推薦
一種混合顏料光譜分區間識別方法
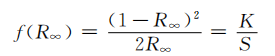
地物高光譜儀的發展趨勢如何?
地物光譜儀在森林樹冠研究中的具體應用
基于地物光譜儀的水面溢油污染監測方法研究

基于高光譜影像的南磯濕地光譜特征分析1.0
基于無人機高光譜遙感的荒漠化草原地物分類研究2.0
不同地物分類方法在長江中下游典型湖區應用對比分析

地物光譜儀在土壤中油脂分析中的應用
比較基于無人機高光譜影像和傳統方法的土壤類型分類精度






 工商網監
工商網監
評論