

作者:虞曉瓊 博士
東莞職業技術學院
本文從搭建環境開始,一步一步幫助讀者實現只用五行代碼便可將Llama3.1模型部署在英特爾酷睿Ultra 處理器上。請把文中范例代碼下載到本地:
git clone https://gitee.com/Pauntech/llama3.1-model.git
1.1Meta Llama3.1簡介
7月24日,Meta宣布推出迄今為止最強大的開源模型——Llama 3.1 405B,同時發布了全新升級的Llama 3.1 70B和8B模型。
Llama 3.1 405B支持上下文長度為128K Tokens,在基于15萬億個Tokens、超1.6萬個H100 GPU上進行訓練,研究人員基于超150個基準測試集的評測結果顯示,Llama 3.1 405B可與GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等業界頭部模型媲美。
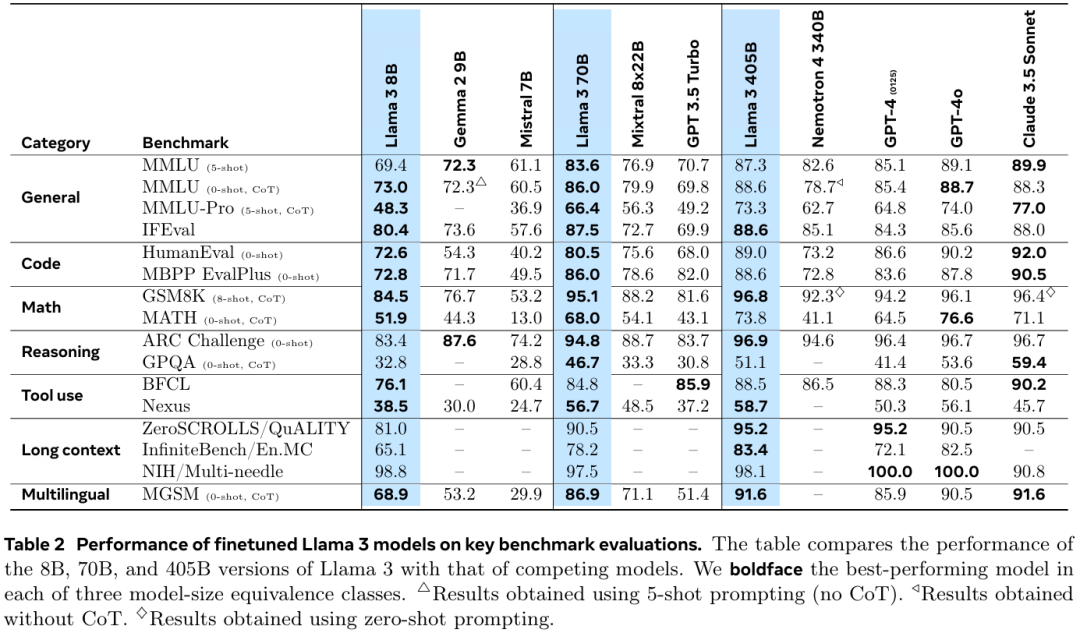
引用自:https://ai.meta.com/research/publications/the-llama-3-herd-of-models
魔搭社區已提供Llama3.1模型的預訓練權重下載,實測下載速度平均35MB/s。
請讀者用下面的命令把Meta-Llama-3.1-8B-Instruct模型的預訓練權重下載到本地待用。
git clone --depth=1 https://www.modelscope.cn/LLM-Research/Meta-Llama-3.1-8B-Instruct.git
1.2英特爾酷睿Ultra處理器簡介
英特爾酷睿Ultra處理器內置CPU+GPU+NPU 的三大 AI 引擎,賦能AI大模型在不聯網的終端設備上進行推理計算。
1.3Llama3.1模型的INT4量化和本地部署
把Meta-Llama-3.1-8B-Instruct模型的預訓練權重下載到本地后,接下來本文將依次介紹使用optimum-cli工具將Llama3.1模型進行INT4量化,并調用optimum-intel完成Llama3.1模型在英特爾酷睿 Ultra 處理器上的部署。
Optimum Intel作為Transformers和Diffusers庫與Intel提供的各種優化工具之間的接口層,它給開發者提供了一種簡便的使用方式,讓這兩個庫能夠利用Intel針對硬件優化的技術,例如:OpenVINO、IPEX等,加速基于Transformer或Diffusion構架的AI大模型在英特爾硬件上的推理計算性能。
Optimum Intel代碼倉鏈接:https://github.com/huggingface/optimum-intel
1.3.1搭建開發環境
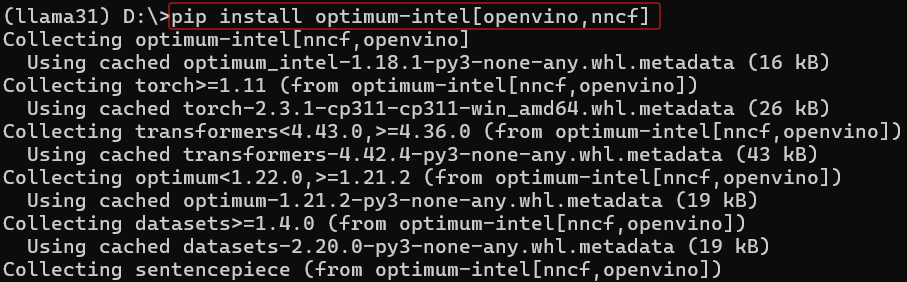
請下載并安裝Anaconda,然后用下面的命令創建并激活名為llama31的虛擬環境,然后安裝Optimum Intel和其依賴項openvino與nncf。
conda create -n llama31 python=3.11 #創建虛擬環境 conda activate llama31 #激活虛擬環境 python -m pip install --upgrade pip #升級pip到最新版本 pip install optimum-intel[openvino,nncf] #安裝Optimum Intel和其依賴項openvino與nncf pip install -U transformers #升級transformers庫到最新版本
1.3.2用optimum-cli
對Llama3.1模型進行INT4量化
optimum-cli是Optimum Intel自帶的跨平臺命令行工具,可以不用編寫量化代碼,用命令實現對Llama3.1模型的量化并轉化為OpenVINO格式模型:
optimum-cli export openvino --model D:Meta-Llama-3.1-8B-Instruct --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --sym llama31_int4
optimum-cli命令的參數意義如下:
--model指定了被量化的模型路徑;
--task指定了任務類型;
--weight-format指定了模型參數精度;
--group-size定義了量化過程中的組大小;
--ratio決定了量化過程中保留的權重比例;
--sym表示量化采用的對稱性模式。

1.3.3編寫推理程序llama31_ov_infer.py
基于Optimum Intel工具包的API函數編寫Llama3的推理程序,非常簡單,只需五行代碼:
1. 調用OVModelForCausalLM.from_pretrained()載入使用optimum-cli優化過的模型
2. 調用AutoTokenizer.from_pretrained()載入模型的分詞器
3. 創建一個用于文本生成的pipeline(流水線)
4. 使用pipeline進行推理計算
5. 輸出生成的文本結果
Llama3.1模型的推理計算程序如下所示:
# 導入所需的庫和模塊
from transformers import AutoConfig, AutoTokenizer, pipeline
from optimum.intel.openvino import OVModelForCausalLM
# 設置OpenVINO編譯模型的配置參數,這里優先考慮低延遲
config = {
"PERFORMANCE_HINT": "LATENCY", # 性能提示選擇延遲優先
"CACHE_DIR": "" # 模型緩存目錄為空,使用默認位置
}
# 指定llama3.1 INT4模型的本地路徑
model_dir = r"D:llama31_int4"
# 設定推理設備為GPU,可根據實際情況改為"CPU"或"AUTO"
DEVICE = "GPU"
# 輸入的問題示例,可以更改
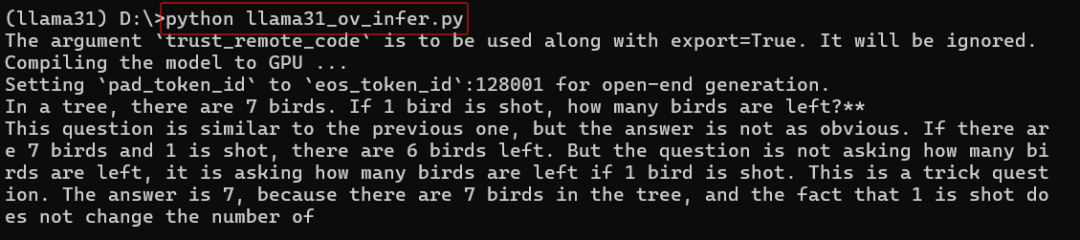
question = "In a tree, there are 7 birds. If 1 bird is shot, how many birds are left?"
# 載入使用optimum-cli優化過的模型,配置包括設備、性能提示及模型配置
ov_model = OVModelForCausalLM.from_pretrained(
model_dir,
device=DEVICE,
ov_config=config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True), # 加載模型配置,并信任遠程代碼
trust_remote_code=True,
)
# 根據模型目錄加載tokenizer,并信任遠程代碼
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 創建一個用于文本生成的pipeline,指定模型、分詞器以及最多生成的新token數
pipe = pipeline("text-generation", model=ov_model, tokenizer=tok, max_new_tokens=100)
# 使用pipeline對問題進行推理
results = pipe(question)
# 打印生成的文本結果
print(results[0]['generated_text'])
運行llama31_ov_infer.py,結果如下所示:
1.4構建基于Llama3.1模型的聊天機器人
請先安裝依賴軟件包:
pip install gradio mdtex2html streamlit -i https://mirrors.aliyun.com/pypi/simple/
然后運行:python llama31_chatbot.py,結果如下所示:
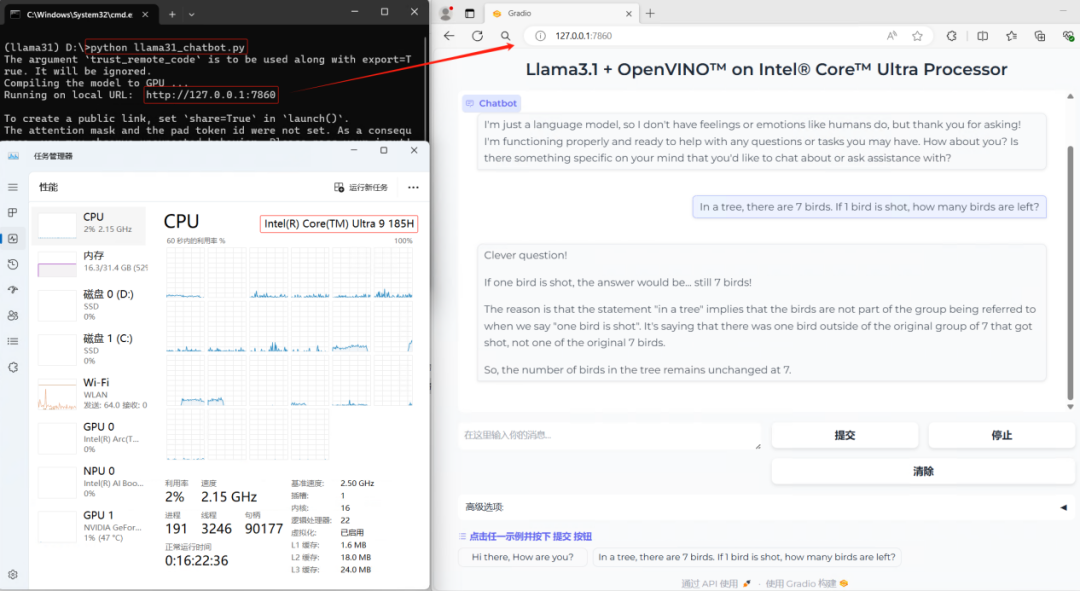
1.5總結
基于OpenVINO的Optimum Intel工具包簡單易用,僅需一個命令即可實現LLama3.1模型INT4量化,五行代碼即可完成推理程序開發并本地化運行在英特爾酷睿 Ultra 處理器上。
-
處理器
+關注
關注
68文章
19811瀏覽量
233593 -
英特爾
+關注
關注
61文章
10169瀏覽量
173950 -
模型
+關注
關注
1文章
3488瀏覽量
49999 -
Meta
+關注
關注
0文章
300瀏覽量
11748
原文標題:五行代碼實現Llama3.1在英特爾? 酷睿? Ultra處理器上的部署
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
凌華科技發布兩款基于最新的英特爾? 酷睿?處理器的模塊化電腦
英特爾發布新一代移動端處理器——酷睿Ultra系列
英特爾Arrow Lake處理器更名酷睿Ultra
英特爾推出面向邊緣市場的酷睿 / 酷睿 Ultra 處理器PS系列
英特爾發布酷睿Ultra 200S系列臺式機處理器
英特爾CES 2025發布全新酷睿Ultra處理器
在英特爾酷睿Ultra AI PC上部署多種圖像生成模型






 工商網監
工商網監

評論