

在絕大部分使用電池供電和插座供電的系統中,功耗成為需要考慮的第一設計要素。Xilinx決定使用20nm工藝的UltraScale器件來直面功耗設計的挑戰,本文描述了在未來的系統設計中,使用Xilinx 20nm工藝的UltraScale FPGA來降低功耗的19種途徑。
1、制造工藝:TSMC使用20SoC工藝來生產Xilinx 20nm的UltraScale器件,該工藝采用TSMC第二代gate-last HKMG(high-K絕緣層+金屬柵極)技術和第三代SiGe (silicon-germanium)應變技術來實現在低功耗時提高性能。跟TSMC 28nm工藝相比,20SoC工藝技術能做到器件密度增加1.9倍,同時速度提升30%。
2、電壓調整:TSMC 20SoC工藝有兩種模式,一種是高性能模式(Vcc = 0.95V),還有一種是低功耗模式(Vcc = 0.9V)。20SoC高性能模式與TSMC 28HP和28HPL工藝相比,能提供更高的性能以及更低的靜態功耗。低功耗模式跟TSMC 28HP工藝相比,靜態功耗要低65%,使用TSMC 20SoC工藝制造的器件的Vcc空間使得Xilinx能選擇功耗分布曲線上的合適的部分,即在Vcc降低到0.9V時,在性能上仍然有不錯的表現,但此時的動態功耗卻可以下降大約10%。

20nm工藝UltraScale器件,性能和功耗對比:非常顯著的優勢
3、選擇功耗最低的器件:Xilinx 20nm UltraScale FPGA中,在0.95V或者0.9V下都可以工作的器件被定義為-1L,這是基于它們在0.95V下的速度等級來定義的。-1L UltraScale器件的性能和0.95V,速度等級為-1的器件性能相同,和工作在0.9V,速度等級為-1的器件性能也一致,但是-1L的定義表示,這類器件的靜態功耗是特別低。在0.9V時,光是Vcc的下降就可以使得靜態功耗下降大約30%。相比其他UltraScale FPGA器件,Xilinx對-1L器件的速度和漏電有著更加嚴格的定義標準,換句話說,只有那些漏電最低、性能最高的UltraScale器件才能稱為-1L器件。
4、管理3D IC的工藝變動:20nm UltraScale FPGA規模較大,實際上是3D IC,采用了Xilinx第二代堆疊硅片互聯(SSI)技術,它可以把一個封裝里的多個FPGA die連接起來。Xilinx通過在一個封裝中組合較高和較低漏電的die(都在說明書中)來控制整個3D IC的靜態漏電功耗,結果是整個封裝器件的漏電功耗要遠遠低于只使用一個die(具備相同可編程邏輯容量)的封裝。
5、通過3D IC集成來縮減I/O功耗:和傳統的多芯片設計相比,在具備相同的I/O帶寬的情況下,基于SSI的3D IC技術可以使I/O互連功耗減小100倍。這個激動人心的結果就是通過把所有的連接都保留在芯片內部來實現的,與把信號驅動到芯片外部相比,這種做法的功耗顯著降低,這種設計理念可以在低功耗的情況下獲得令人難以置信的高速度。
6、低功耗設計不僅僅停留在工藝級別:在20nm工藝節點上,Xilinx從每一個角度去聚焦功耗效率。基于動態功耗能減少的百分比,Xilinx對很多選項都進行了評估,每一項都會產生相應的風險以及實現的時間。每一個降低功耗的技術,它在性能、成本、設計流程方法以及總體進度方面的影響也會被評估,被挑選出來的選項最終實現在所有Xilinx 20nm UltraScale器件中。
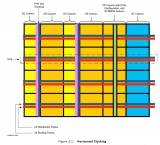
7、類似ASIC的時鐘設計使得功耗降低:跟所有以往的FPGA架構相比,UltraScale架構中的時鐘布線和時鐘buffer進行了徹底地重新設計,可以提供更大程度的靈活性。在縱橫兩個方向上,大量的時鐘布線和時鐘分布路徑產生了許許多多的全局時鐘buffer,數量是以往架構中的20倍以上,那個架構有著無數個布局的選項。實際上,在一個UltraScale FPGA中,時鐘網絡的“中心點”(時鐘偏移開始累積的起始點)可以被放在任何一個時鐘域。和ASIC相同的是,哪里需要時鐘,哪里的時鐘網絡才開始工作。UltraScale架構可以向可編程邏輯設備提供偏移最小、性能最快的時鐘網絡,這些時鐘網絡只有在源需要向目的發送時鐘信號時才產生功耗。

UltraScale 類ASIC時鐘設計
8、精細化的時鐘門控:可以通過精細化的時鐘門控技術來進一步降低動態時鐘功耗。在一個設計中,當相關邏輯不需要工作的時候,可以動態門控關閉時鐘驅動。這個特性可以靜態或者以一個時鐘周期的粒度來動態執行。最大的20nm UltraScale器件中,除了常見的全局門控時鐘之外,還有數以千計的末梢門控時鐘。時鐘樹功耗(CV2f)實際上大部分是發生在橫向buffer和時鐘樹末梢時鐘這一級,因為在這一級上,驅動了數以千計的負載,這一級上的時鐘門控可以使得動態功耗消減非常明顯。另外,降低扇出可以減小時鐘buffer功耗,因為這個時候,時鐘buffer僅僅驅動幾個負載,這也能降低時鐘樹的功耗。因為有著大量的可門控的時鐘,一些基于20nm UltraScale器件的設計可以節省10-15%的時鐘樹功耗,當然,這還要取決于時鐘的使能率。
9、充分使用每一個CLB來減少CLB的使用數量:UltraScale架構采用了加強的可配置邏輯單元(CLB),可以效率更高地使用這些可用的CLB資源。對于可能的封裝選項而言,CLB結構上的許多改變提供了更多的靈活性。每一個6-輸入LUT都是由兩個觸發器組成,每個觸發器都有專用的輸入和輸出信號,使得一個CLB中的所有部件既可以一起使用,也可以完全獨立。控制信號在數量和靈活性上的提高使得觸發器更加易用,包括:可用的時鐘使能信號數量翻倍;可選擇“忽略”時鐘使能和復位端口的輸入;可選擇復位信號反向,使得同一個CLB中的觸發器的復位信號電平既可以是高有效,也可以是低有效;一個額外的時鐘信號用于移位寄存器和分布式RAM。總而言之,這些加強特性可以讓Vivado設計套件把更多的設計部件(經常是在功能上相互沒有關系)封裝在一個CLB中。通過對器件總體利用上的最大化來消耗盡可能最低的功耗。

充分使用每一個UltraScale CLB來減少CLB的使用數量
10、更少的CLB意味著CLB之間的布線更少:CLB利用率的顯著提高使得設計的封裝更緊密,性能更高。緊密的封裝最終體現為更短的連線長度,因此連線電容更小,這有助于一個設計的總體功耗的降低。
11、關掉不用的Block RAM:UltraScale架構支持電源門控,可以關掉不用的Block RAM。降低Block RAM的靜態漏電功耗對降低整個器件的漏電功耗非常有幫助。
12、Block RAM級聯降低動態功耗:UltraScale 的Block RAM支持高速存儲器級聯(用于數據級聯布線)以及輸出復用,這樣可以實現速度更快、動態功耗更低的大容量Block RAM陣列。多個Block RAM可以級聯到一起而不影響Block RAM的時序,這個特性可以在任何特定時刻使工作的Block RAM數量最小化,這樣可以進一步降低動態功耗。
13、使用更少的DSP Slice:盡管Virtex-7 FPGA的DSP Slice性能已經是業界的領導者,Xilinx還是在UltraScale架構中,對DSP Slice性能進行了較大的提升。這樣,在布線更少、DSP外部邏輯資源使用更少的同時,實現更快的數字信號處理。舉例來說,用UltraScale架構中DSP模塊的27x18位寬的乘法器來實現IEEE Std 754雙精度算法,所用的DSP模塊資源比用Xilinx 7系列器件來實現相同功能要減少三分之二。
14、降低I/O功耗:對于總體功耗而言,I/O功耗已經成為一個重要的組成部分。隨著可編程器件的技術改進,內核功耗已經有了很大的減少,但是直到最近(隨著Xilinx 7系列可編程器件的出現),I/O功耗的降低卻并不明顯,特別是對于一些存儲器密集型的應用來說,大量的I/O帶來的功耗會占到一個設計的總體功耗的50%。Xilinx在7系列FPGA中,通過可編程的電壓轉換速率和驅動強度來降低I/O功耗,UltraScale器件采用了相同的節省功耗的方法。
15、使用DDR4存儲器:UltraScale架構升級了存儲器接口,支持多個DDR3/4兼容的SDRAM存儲器控制器,并且把DDR物理層接口(PHY)模塊集成到片內。當從DDR3到DDR4轉變時,你可以看到功耗上有20%的下降,原因是DDR4工作在一個更低的1.2V的電壓下。
16、降低高速串行收發器功耗:Xilinx 20nm UltraScale器件的SerDes都為了高性能和低抖動而進行了優化設計,能提供一些低功耗操作的特性。UltraScale架構中,對GTH收發器進行了重新設計,跟7系列FPGA中的GTX和GTH收發器相比,可以削減50%的總體的功耗。
17、在不需要DFE的時候關閉它:許多無背板的應用場合不需要在SerDes收發器中使用判決反饋均衡器(DFE)電路。因為DFE需要消耗額外的功耗,因此,當SerDes端口用作其它用途時,Xilinx UltraScale器件允許設計人員關閉DFE。為了節省功耗,你可以關掉DFE電路,而使用線性均衡器(LE),跟DFE相比,因為LE自身更低的Rx增益和最小化的電路,所以功耗要小很多。
18、增加硬IP模塊:用集成的硬核模塊來代替軟IP,可以降低10倍的功耗。Xilinx實現了一個集成的Interlaken IP核用于片間的連接,可以達到150Gbps。Xilinx的IP核是基于業界領導和最廣泛的部署來實現的,對Interlaken接口協議規范rev1.2的實現具有靈活性、高性能和低功耗的特點,可以支持12.5Gbps和25Gbps的收發器。結合了UltraScale架構的收發器技術以及靈活的協議層,集成IP核可以實現片間互連的管腳個數和功耗的最小化。同相同的軟IP解決方案相比,集成IP核的延遲更小,這樣可以預先知道IP的性能。

使用硬IP核節省功耗
19、把降低功耗的思想深入到設計工具中:Vivado設計套件直接可以支持UltraScale架構的許多降功耗的特性,比如說,Vivado設計套件為了能夠把設計的一部分進行電源門控,會產生一些邏輯來驅動時鐘末梢buffer的開關。這個工具還會自動產生邏輯來支持對Block RAM的靜態和動態功耗的門控,能推斷出是否要把Block RAM進行級聯。
-
Xilinx
+關注
關注
73文章
2179瀏覽量
123999 -
UltraScale
+關注
關注
0文章
119瀏覽量
31746
發布評論請先 登錄
關于賽靈思(Xilinx) 20nm公告最新常見問題解答
唱響2013,20nm FPGA背后蘊藏的巨大能量
Xilinx 推出擁有ASIC級架構和ASIC增強型設計方案的20nm All Programmable UltraScale產品系列
Xilinx Ultrascale系列FPGA的時鐘資源與架構解析





 工商網監
工商網監

評論