 突破FPGA限制:TS-M4i系列數字化儀利用GPU加速實現高效塊平均處理
突破FPGA限制:TS-M4i系列數字化儀利用GPU加速實現高效塊平均處理
一、應用背景
塊或分段內存平均模式常用于在不同應用當中,移除信號中不相干的噪聲。不管是哪家的數字化儀制造商,幾乎所有基于FPGA實現的塊平均模式都會受到塊或者段內存大小的限。該限制一般取決于FPGA的容量,最大樣品量通常在32k到500k之間。
本白皮書將展示如何使用TS-M4i系列數字化儀的高速PCIe流模式來在軟件中實現塊平均處理,從而突破FPGA的限制。我們用了TS-M4i.2230(1通道,5 GS/s,8位垂直分辨率,1.5 GHz帶寬)作為例子,對比硬件和軟件進行塊平均處理的效果。
二、什么是塊平均?
塊平均模式可以用來移除隨機噪聲成分,提高重復信號的保真度。該模式允許對多次單段采集進行處理、累積和平均。這個過程減少了隨機噪聲,提高了重復信號的可見性,平均后的信號具有增強的測量分辨率和更高的信噪比(SNR)。
塊平均模式可用于改善雷達測試、天文學、質譜學、醫學成像、超聲波測試、光纖測試和激光測距等各種不同應用中的測量。
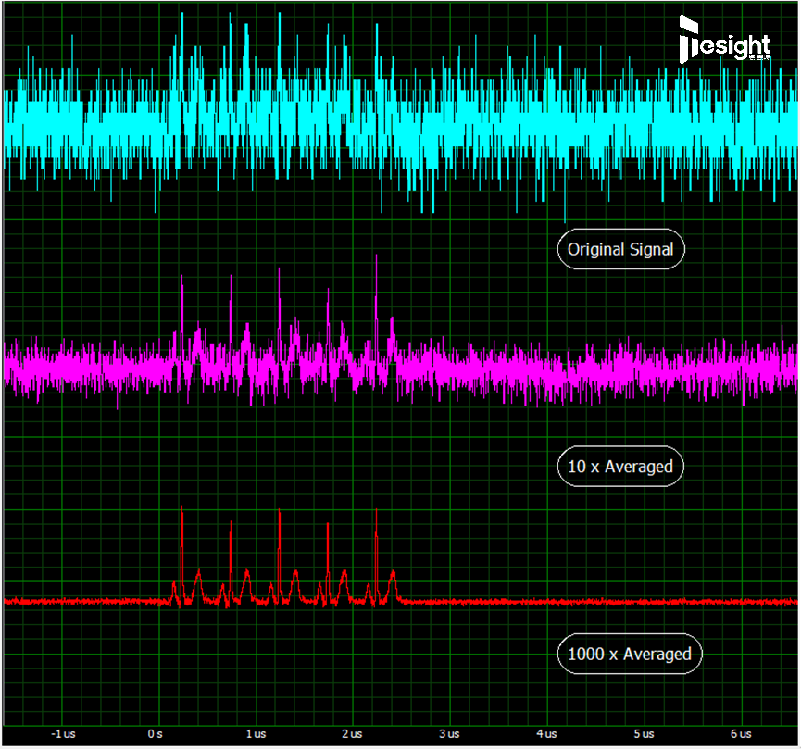
下面截圖顯示了一個較低電平的信號(大約2mV),完全被隨機噪聲覆蓋的情形,以及使用不同平均因子獲得的信號質量改進。雖然在原始單次采集中源信號基本無法看到,但10x平均時,能顯示出實際上有5個信號峰。執行1000x的塊平均可以進一步改善信號質量,揭示出帶有二次最大值和最小值峰的完整信號形狀。
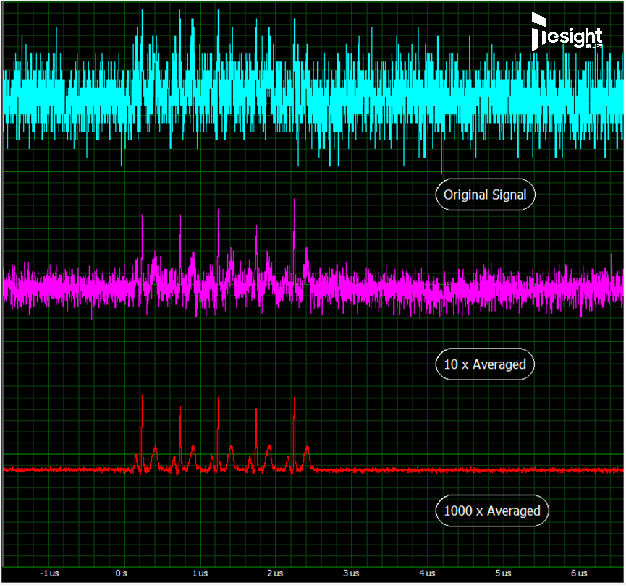
通過塊平均改善噪聲問題,該示例使用了一個500MS/s采樣率(每個采樣點2ns)和14位分辨率的數字化儀制作
三、系統配置
為了兼顧更多老舊設備的性能狀況,測試系統選用了一臺德思特公司內的舊辦公電腦,大致配置如下:
●主板:技嘉GA-H77-D3H
●運行內存:8 GB DDR3
●硬盤:120 GB固態
●操作系統:Win 7 64bit
● IDE:Visual Studio 2005標準版
主板上有一個空閑的PCIe Gen2 x8插槽,我們就使用該插槽來插數字化儀板卡。此時,德思特的TS-M4i板卡的流式傳輸可以達到滿速,約3.4 GB/s(不考慮數據處理的情況下)。
四、軟件實現
測試軟件使用純C++編寫,并基于德思特流式傳輸示例。數字化儀板卡通過外部觸發采集,板卡會自動在每個觸發事件后獲取一段數據。數據會先存儲在板載內存中,然后通過分散聚集式式DMA直接傳輸到PC的運行內存,并在運行內存中進行累積,進而執行塊平均操作。我們針對不同的配置方式和優化策略進行了測試,來看看分別能達到什么樣的性能水平。
摘錄出來的一小段源代碼顯示了多線程版本的主求和循環,這正是軟件處理的關鍵部分,也是決定速度的部分。

以下列表提供了具體實現各個方面的一些信息和備注:
●數據段大小:收到觸發事件后將獲取數據的樣本點數量
●平均次數:對于一個數據段,在算法重置前,整個過程中需要執行多少次平均前的累加操作。
●通知大小:硬件生成中斷所需的數據量。該參數決定了整個平均循環的速度。如果通知大小大于數據段大小,則會在一次中斷中傳輸多個數據段的內容,這將減少線程通信和中斷處理的額外開銷。
●緩沖區大小:DMA傳輸的目標緩沖區整體大小。在我們的實驗中,這個緩沖區固定等于通知大小的16倍。
●觸發速率:作為外部觸發的信號發生器的信號重復頻率。在結果表格中,我們給出的是在不填滿(溢出)緩沖區的情況下可以達到的最大觸發速率。
●線程數:為了加快求和過程,我們對該任務進行并行化優化,將其分割成多個不同的軟件線程。如果線程為1,則表示求和過程不使用額外線程,而是直接在主循環中直接執行。
● CPU負載:由于平均過程是用軟件完成的,具體來說就是CPU進行了所有的工作。幸好現代CPU往往包含多個內核,我們實際上可以輕松地在它們之間共享工作任務。
● SSE/SSE2指令:乍一看,這些命令似乎非常適合并行化求和過程,并似乎可以在不需要任何線程編程的情況下加快軟件的速度。但不幸的是,SSE命令集都是基于相同類型的數據的,而由于獲取的數據是8bit寬度,而平均緩沖區是32位寬,因此在本例中無法利用該指令集進行加速。
五、效果和比較
所有的測量都是使用一個采樣率高達5GS/s、垂直分辨率為8位,并且帶有外部觸發通道的數字化儀進行的。我們在表格中還列出了不同的程序配置以對比效果差異。
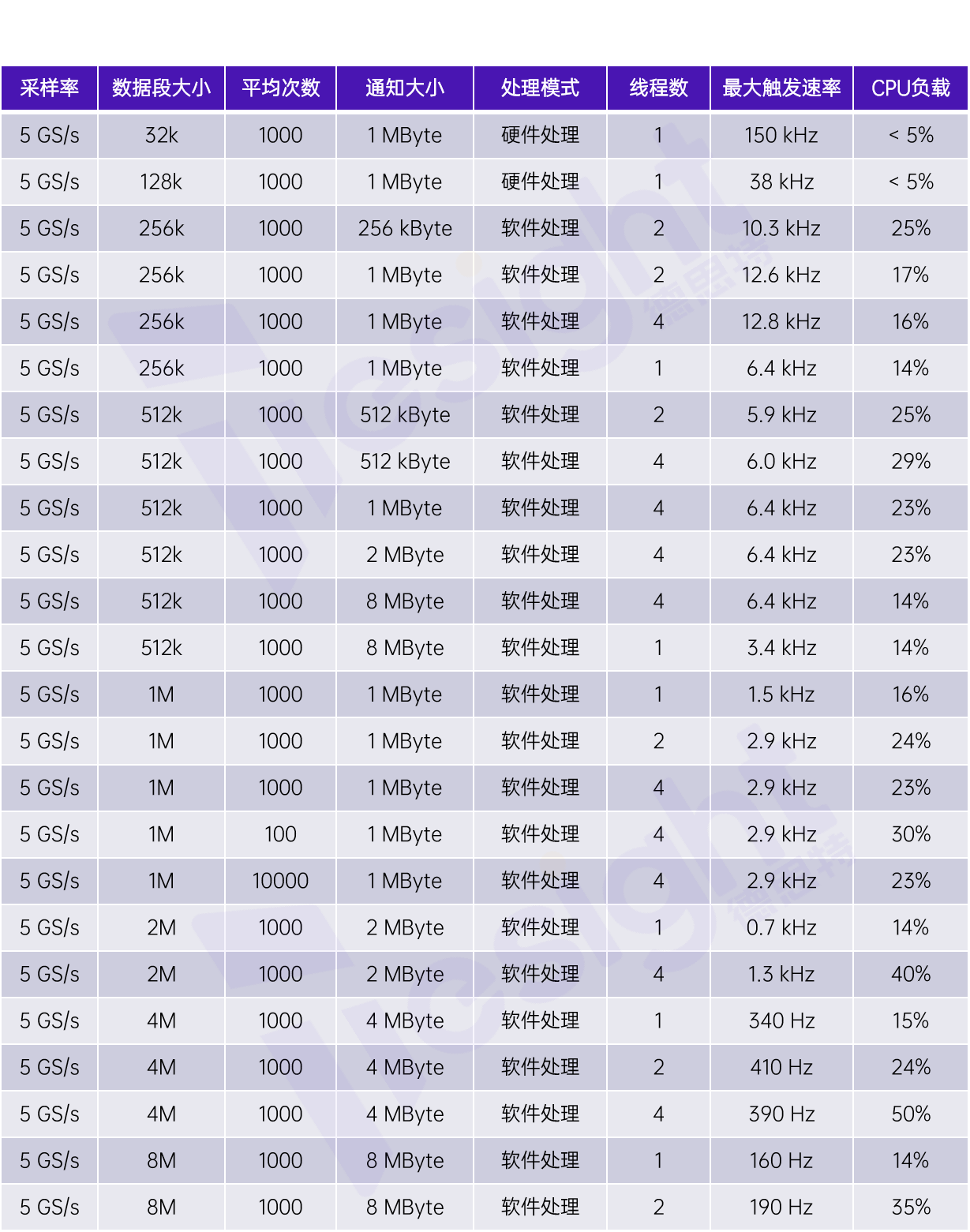
通過普通(性能偏低的)PC在時域上進行塊平均的性能對比
六、新方法:使用CUDA進行平均運算
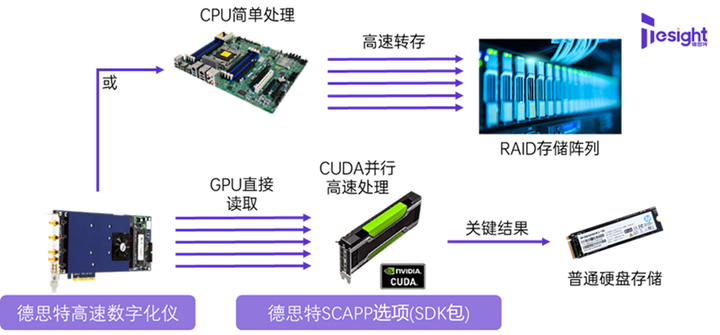
2018年11月,我們推出了一些使用SCAPP(通過CUDA訪問數據和并行處理)選項進行塊平均的示例,適用于非常高速的數據處理。其基本概念與前文所述相同,即數據由數字化儀采集并通過PCIe總線連續傳輸。不同之處在于,平均值的計算操作不是由CPU完成,而是在GPU中完成。GPU解決方案的一個主要優點在于,GPU本身就是為并行計算而設計,這使GPU成為各種類型的塊平均運算的理想選擇。
在實現上,SCAPP允許用戶直接將數據傳送到GPU,這使用了RDMA(遠程直接內存存取)技術,然后可以在GPU上執行高速時域和頻域信號的平均,并突破通常在CPU和FPGA中出現的數據長度或算力限制。
比如,TS-M4i.2220數字化儀可以以2.5 GS/s的速度連續采樣信號,我們可以做到在不丟失樣品點的情況下,進行長達數秒的平均運算。類似地,我們還有14位垂直分辨率的TS-M4i.4451數字化儀可以以450 MS/s的速度同時對四個通道的信號進行同一功能的采樣。數字化儀板卡還提供了靈活的觸發、捕獲和讀出模式設置,從而使它們能夠在觸發速率極高的情況采回原始信號,進而做平均處理。相比之下,FPGA方案需要最高性能級別的FPGA來同時滿足數據拉取和平均運算,而GPU方案則可以輕松跑滿數字化儀的全速,即使是使用入門級GPU也不會成為瓶頸。
以下表格展示了使用GPU,并在和之前表格中板卡參數相同的情況下的測試結果:
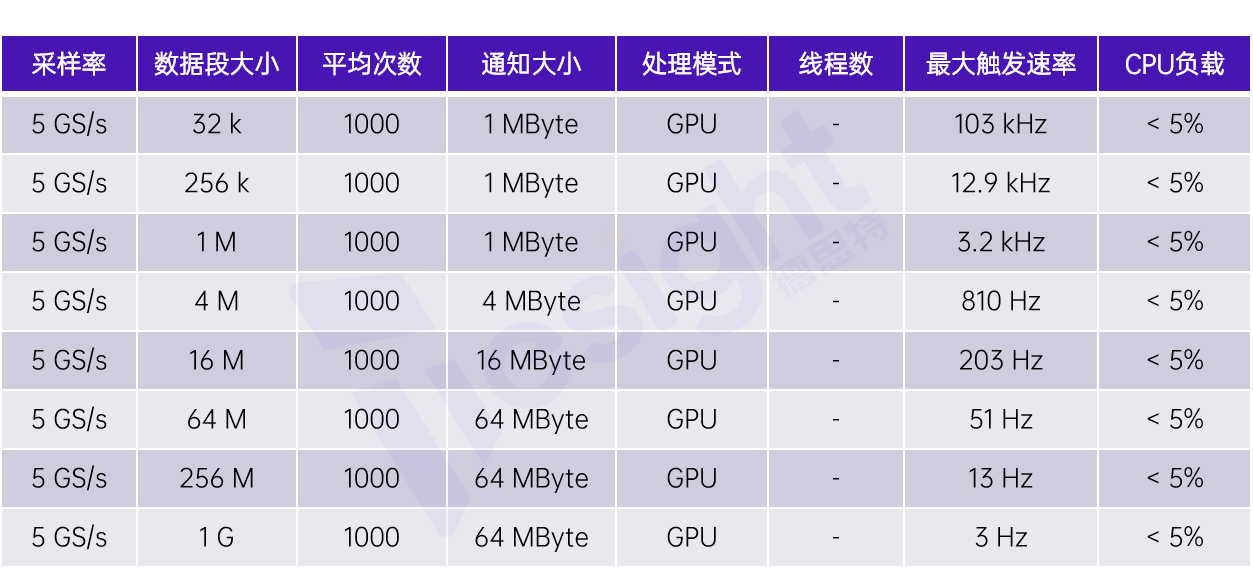
在時域上使用GPU進行塊平均的測試結果
這些結果是在使用一張Quadro P2000 GPU獲得的。如表所示,數據段大小和通知大小并未限制性能,我們遇到唯一限制的瓶頸是GPU內存(顯存)。
七、使用GPU進行頻域平均
在需要進行頻域平均的情況下,也建議使用GPU,因為GPU允許比FPGA方案更大的平均塊大小。頻域的平均運算過程包含兩個步驟,一個是針對塊數據的FFT運算,另一個是對FFT結果求和(然后取平均)。其中FFT計算在處理能力方面要求非常高,因此對于頻率域平均而言,除了FPGA外,GPU是唯一的可行方案,CPU并不適合在高速下進行FFT轉換。
以下表格顯示了使用最大采樣率為500 MS/s的TS-M4i.4451數字化儀(4通道,14位垂直分辨率)的一些測試結果。最終表明該方案能高效地實現無間隙數據采集,將每個塊中的原始數據轉換為對應電壓值,然后再轉換至頻率域做平均。
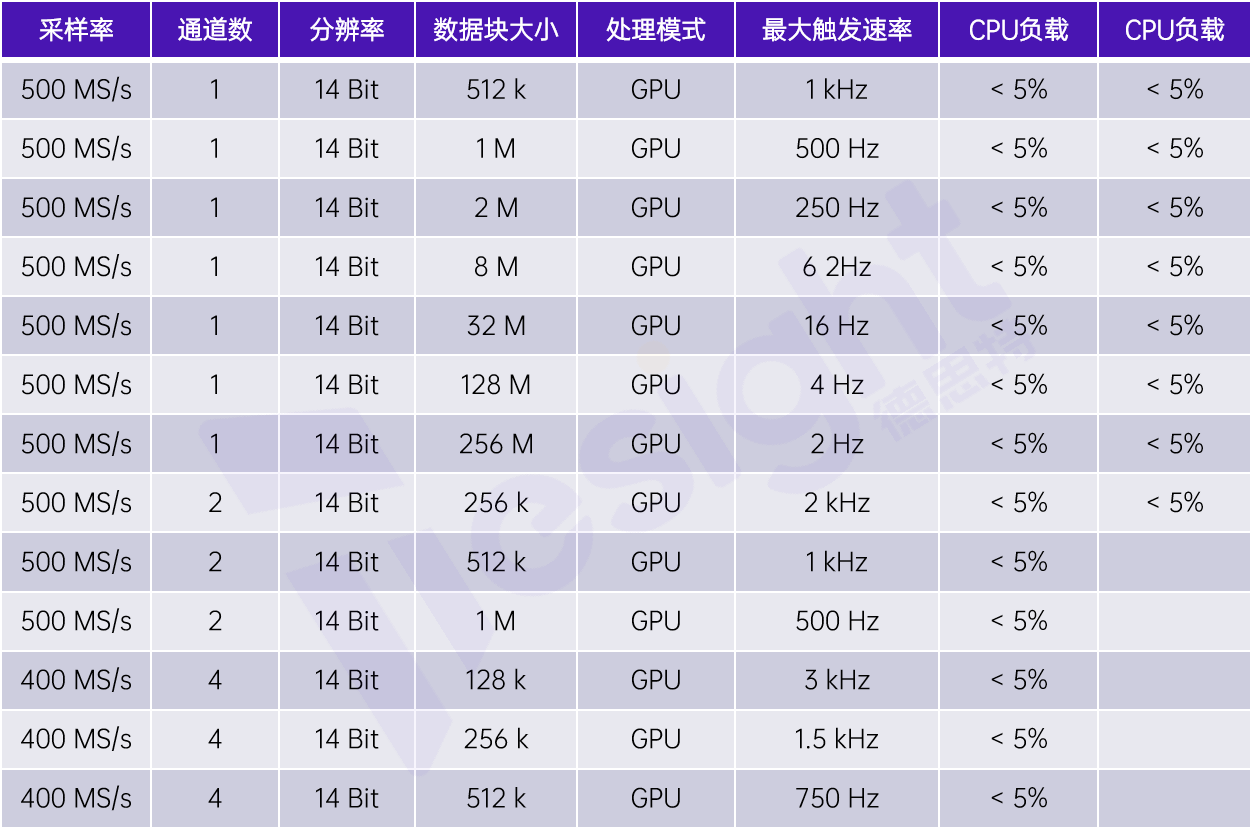
使用GPU進行頻率域塊平均的測試結果
八、結論
如上述結果所示,只要重復率不算太高,得益于PCIe總線的高速數據傳輸率,使用基于CPU的軟件在進行塊平均時,可以實現比FPGA更大的總數據段大小,從而平均更長時間的樣本;而使用GPU時,更是可以達到PCIe總線傳輸所限制的上限速度。對于需要處理更高重復觸發率的情況,會對總線傳輸速度提出更高的要求,此時基于FPGA硬件的塊平均仍將是最佳選擇。
上述測試程序也可以提供給您,以便您自己進行重復測試,或者作為實現其他軟件程序的基礎。其中GPU示例是SCAPP軟件選項的一部分,在選購后,德思特的客戶可按照NDA協議使用。
總的來說,通知大小設為1 MByte時,可獲得最佳性能。具體執行的平均次數對測試性能并沒有明顯的影響。因為復制結果段和清除結果緩沖所需的時間相對于樣本求和運算而言微不足道。
由于在同時采集多個通道時,整個的數據處理和求和過程并沒有本質區別,因此只需等價成一個把所有數據都合并到一起的新通道即可(等效采樣率= 每通道采樣率 × 通道數)。以下設置對應的最大觸發速率完全相同:
●1通道5 GS/s @ 數據段大小S1
●2通道2.5 GS/s @ 數據段大小S1/2
●4通道1.25 GS/s @ 數據段大小S1/4
將采樣速度降低到2.5 GS/s時,可以在理論上使軟件針對1個通道執行平均運算的速度最大化。對于1 M樣本點的數據段大小,外加死區長度為160個樣本點時,理論上的最大觸發速率為:(2.5 GS/s) / (1 MS+ 160 S) = 2.38 kHz。
注意,這確實會明顯低于單純采集時的最大觸發速率:2.9 kHz @ 5 GS/s。
審核編輯 黃宇
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603018 -
gpu
+關注
關注
28文章
4729瀏覽量
128897 -
數字化儀
+關注
關注
0文章
143瀏覽量
17926
發布評論請先 登錄
相關推薦
助力AIoT應用:在米爾FPGA開發板上實現Tiny YOLO V4
Spectrum高速數字化儀:從雷達脈沖測試到信號分析的廣泛應用!

解鎖TS-M4i.66xx AWG潛能:深度探索序列模式與實時波形控制

精準高效,頂堅單北斗工作記錄儀:行業數字化轉型的得力助手

德思特分享 突破FPGA限制:德思特TS-M4i系列數字化儀利用GPU加速實現高效塊平均處理
TLV990-21完整的CCD信號處理器/數字化儀數據表

TS高速數字化儀板卡數據采集與存儲的優化策略
從探頭到傳感器:德思特數字化儀的全面結合與應用
工業數字化平臺是什么
數字化技術革新PMC管理,賦能企業高效運營新篇章
數字化儀:為何成為示波器的理想替代品?——PCIe8910M

如何正確使用數字化儀前端信號調理?(二)
如何正確使用數字化儀前端信號調理?(一)

如何使用SBench6軟件對數字化儀采集信號進行處理?(二)——平均運算功能






 工商網監
工商網監
評論