 通過多樣的幾何形狀來訓練機器人從仿真到現實轉換的裝配技能
通過多樣的幾何形狀來訓練機器人從仿真到現實轉換的裝配技能
家庭和工業環境中的大多數物品都由多個部件組裝而成。而裝配工作一般交給人工,但在汽車等一些行業,機器人裝配已十分普遍。
這些機器人大多用于執行重復性較高的任務,它們被部署在精心設計的環境中,處理特定的部件。在多品種的小批量制造中(即小批量生產各種產品的流程),機器人還必須適應不同的零件、姿態和環境。在保持高精度和高準確度的前提下實現這種適應性是機器人技術所面臨的一大挑戰。
得益于 NVIDIA 在接觸豐富交互的超實時仿真技術方面的最新進展,現在已經可以對機器人裝配任務(如插入等)進行仿真,詳見通過使用 NVIDIA Isaac 的新型仿真方法推進機器人裝配技術發展。這使得使用數據饑渴的學習算法來訓練仿真機器人智能體成為可能:
https://developer.nvidia.com/blog/advancing-robotic-assembly-with-a-novel-simulation-approach-using-nvidia-isaac/
后續關于機器人裝配從仿真到現實的遷移研究提出了使用強化學習 (RL) 在仿真中解決少量裝配任務的算法,以及在現實世界中成功部署所學技能的方法。詳見將工業機器人裝配任務從仿真遷移到現實:
https://developer.nvidia.com/blog/transferring-industrial-robot-assembly-tasks-from-simulation-to-reality/
本文將介紹 AutoMate,這一新型框架被用來訓練使用機械臂裝配不同形狀零件的專家和通才策略;然后對訓練策略從仿真到現實的零樣本遷移進行演示,這意味著無需額外調整在仿真中學習到的裝配技能,即可直接應用于現實環境。
什么是 AutoMate?
AutoMate 是首個基于仿真的框架,用于學習各種裝配任務中的專業(部件特定)和通用(統一)裝配技能。例如:在汽車制造領域,AutoMate 可以幫助工人掌握發動機部件的特定裝配技巧以及整車的統一裝配流程。這項工作成果來自于南加州大學與 NVIDIA 西雅圖機器人實驗室的密切合作。
AutoMate 的主要貢獻有:
100 個裝配體和現成仿真環境的數據集。
一種有效訓練仿真機器人解決各種仿真裝配任務的新型算法組合。
有效綜合各種學習方法,將多種專業裝配技能的知識提煉成一種通用裝配技能,并通過 RL 進一步提高通用裝配技能的性能。
一個能夠在以感知為初始的工作流中,部署通過仿真訓練獲得的裝配技能的真實世界系統。
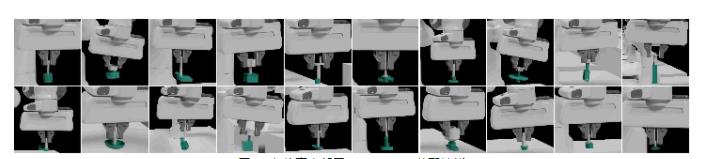
圖 1. 在仿真中部署 AutoMate 裝配技能

圖 2. 在現實中部署 AutoMate 裝配技能
數據集和仿真環境
AutoMate 提供了一個包含 100 個裝配體的數據集,這些裝配體與仿真兼容,并可以在現實世界中進行 3D 打印。同時,它還為所有 100 個裝配體提供了并行化仿真環境。這 100 個裝配體基于 Autodesk 的大型裝配體數據集。在這項工作成果中,術語“插頭”指的是必須插入的部件(圖 3 中用白色表示),“插座”指的是與插頭配合的部件(圖 3 中用綠色表示)。

圖 3. AutoMate 數據集中 100 個裝配體的可視化圖

圖 4. AutoMate 數據集中的裝配體仿真環境
在多種形狀上學習專家技能
盡管 NVIDIA 之前的工作成果 IndustReal 表明,純 RL 方法可以解決接觸豐富的裝配任務,但它只能解決一小部分裝配體。在 AutoMate 數據集中的 100 個裝配體中,大部分都無法通過純 RL 方法解決。但仿真學習可以讓機器人通過觀察和模仿演示來習得復雜的技能。AutoMate 引入了包含三種不同算法的新型組合。該組合通過將 RL 與仿真學習相結合,使機器人能夠有效掌握適用于各種裝配體的技能。
使用仿真學習增強 RL 面臨以下三個挑戰:
生成裝配演示
將仿真學習目標整合到 RL 中
選擇在學習過程中使用的演示
下文將探討如何逐一解決這三個挑戰。
利用拆解-組裝來生成示范
裝配運動學是一個狹窄通道問題,機器人必須操縱部件通過狹窄空間,并且不能與障礙物相撞。使用運動規劃器自動采集裝配演示非常困難。要采集人類演示,還需要有技能嫻熟的人類操作員和先進的遠程操作界面,而這些都十分昂貴。
“拆解-組裝”的概念告訴我們,在裝配一個物體前,首先要了解如何拆卸它。受到這一概念的啟發,可以先采集拆卸演示,然后按相反步驟操作便可進行裝配。在仿真中,命令機器人將插頭從插座上拆下,每個裝配體記錄 100 次成功的拆卸演示。

圖 5. 在仿真中生成拆卸演示的過程
帶有模仿目標的 RL
RL 中的獎勵是向智能體發出的一個信號,該信號表明智能體在規定步驟中的表現有多好。獎勵可作為反饋,指導智能體學習和調整其行動,以逐漸使其累積獎勵最大化(從而成功完成任務)。受 DeepMimic 等角色動畫工作成果的啟發,獎勵函數中加入了一個模仿項,以便通過模仿目標增強 RL,鼓勵機器人在學習過程中模仿演示。每個時間步的模仿獎勵被定義為規定裝配體所有演示的最大獎勵。
除了模仿項,獎勵公式中還包含以下項:
目標距離懲罰
仿真誤差懲罰
獎勵任務難度
這與之前的 InsutReal 工作相一致。
通過動態時間扭曲來選擇演示
如要確定模仿哪個演示(即哪個演示在當前時間步提供最大獎勵),第一步是計算每個演示與當前機器人末端執行器路徑之間的距離,然后模仿距離最小的路徑。與機器人末端執行器路徑相比,演示路徑的路徑點分布可能不均勻,路徑點數量也可能不同,因此很難確定演示路徑中的路徑點與機器人末端執行器路徑之間的對應關系。
動態時間扭曲 (DTW) 是一種用于測量兩個速度可能不同的時間序列之間相似性的算法。在這項工作中,DTW 被用于找出機器人末端執行器路徑和每個演示路徑之間的映射,從而使末端執行器路徑上的每個路徑點與演示路徑上的匹配路徑點之間的距離總和最小(圖 6)。根據 DTW 返回的距離,計算每條演示路徑的模仿獎勵,并選擇模仿獎勵最高的演示路徑。
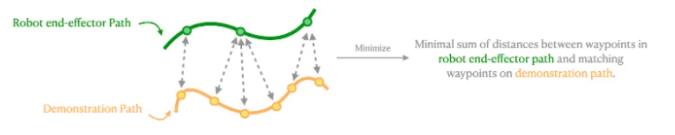
圖 6. DTW 將末端執行器路徑與演示路徑之間的映射可視化
所提出的拆解-組裝組合、帶有模仿目標的 RL 和使用 DTW 匹配軌跡的組合方法在各種裝配體中都表現出一致的性能。在仿真中,專家策略在 80 個不同裝配體上的成功率約為 80% 以上,在 55 個不同裝配體上的成功率約為 90% 以上。在現實世界中,專家策略在 20 個組件上的平均成功率為 86.5%,比在仿真中用于這些組件時僅下降了 4.2%(圖 7)。
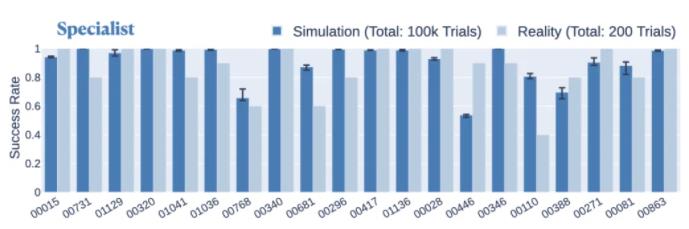
圖 7. 專家策略在現實世界與仿真中解決每個裝配體的成功率比較
學習通用裝配技能
為了訓練一種能夠解決多種裝配任務的通用技能,需要重新使用已訓練的專家技能中的知識,然后使用基于課程的 RL 進一步提高性能。所提出的方法包含三個階段:
首先,使用標準行為克隆 (BC),即從已經訓練過的專家技能中采集演示,并使用這些演示監督通才技能的訓練。
隨后,使用 DAgger(數據集聚合)完善通才技能,方法是執行通才技能,并在通才技能訪問的狀態下主動查詢專家技能(即獲取專家技能預測的操作)以進行監督。
最后,對通才技能執行 RL 微調階段。在微調階段,使用 IndustReal 工作中基于采樣的課程。隨著通才技能任務成功率的提高,部件的初始參與度會逐漸降低。
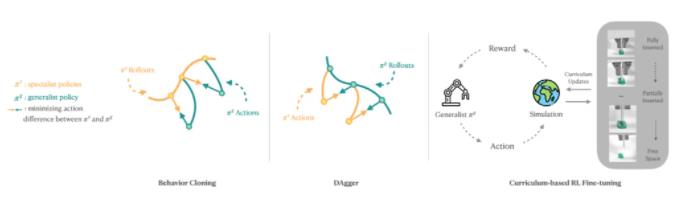
圖 8. 行為克隆、DAgger 和基于課程的 RL 微調示意圖
使用剛才提出的三階段方法在 20 個裝配體上進行通才技能訓練。在仿真中,通才策略可以聯合解決 20 個裝配體,成功率為 80.4%。在現實世界中,通才策略在同一組裝配體上的平均成功率為 84.5%,比在仿真中提高了 4.1%(圖 9)。
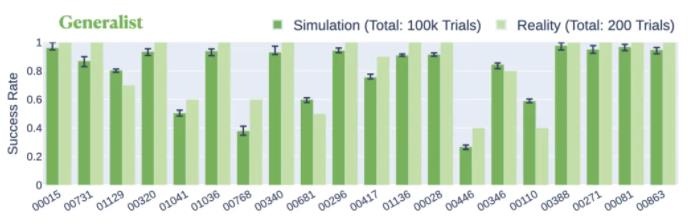
圖 9. 通才策略在現實世界和仿真中解決每個裝配體的成功率比較
現實世界環境和感知初始化工作流
現實世界環境包括一個 Franka Panda 機械臂、一個安裝在手腕上的英特爾 RealSense D435 攝像頭、一個 3D 打印插頭和插座,以及一個用于固定插座的 Schunk EGK40 抓取器。在感知初始化工作流中:
插頭被隨意放置在泡沫塊上,插座被隨意放置在 Schunk 抓取器中。
通過安裝在手腕上的攝像頭捕捉 RGB-D 圖像,然后對部件進行 6D 姿態估計 (FoundationPose)。
機器人抓取插頭、將其移動到插座上,并使用在仿真中訓練的裝配技能。
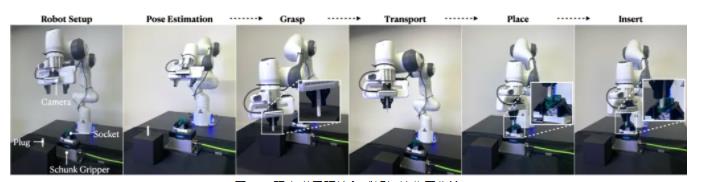
圖 10. 現實世界環境和感知初始化工作流
專家和通才技能在感知初始化工作流中被進行評估。專家技能的平均成功率為 90.0%,通才技能的成功率為 86.0%。這些結果表明,6-DOF 姿態估計、抓取優化和所提出的學習專家和通才策略的方法可以有效結合,從而在現實條件下使用研究級硬件實現可靠的裝配。
總結
AutoMate 是我們第一次嘗試利用學習方法和仿真來解決各種裝配問題。通過這項工作,NVIDIA 研究人員立足于現實世界的部署,逐步建立了工業機器人的大型模型范例。
未來的工作重點是解決需要高效序列規劃(即決定下一個裝配部件)的多部件裝配體,并進一步提高技能,以達到具有行業競爭力的性能指標。
-
機器人
+關注
關注
211文章
28380瀏覽量
206916 -
NVIDIA
+關注
關注
14文章
4978瀏覽量
102987 -
仿真
+關注
關注
50文章
4070瀏覽量
133552 -
工業機器人
+關注
關注
91文章
3360瀏覽量
92624
原文標題:通過多樣的幾何形狀來訓練機器人從仿真到現實轉換的裝配技能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
NVIDIA通過加速AWS上的機器人仿真推進物理AI的發展
從市場角度對機器人的基本解讀

“0元購”智元靈犀X1機器人,軟硬件全套圖紙和代碼全公開!資料免費下載!
在NVIDIA Isaac Lab中訓練四足機器人運動
柔性機器人與剛性機器人區別與聯系






 工商網監
工商網監
評論