

作者:安謀科技 (Arm China) 主任工程師 Ker Liu;安謀科技 (Arm China) 主任軟件工程師 蔡亦波
有客戶希望我們幫忙分析 Eigen gemm 基準測試的一些執(zhí)行情況。具體來說是為什么 L1D_CACHE_WR 的值會低于 L2D_CACHE_WR,這種情況令人費解。

通常,我們期望寫操作發(fā)生在 L1 數(shù)據緩存中。來自 L1 數(shù)據緩存的一些回寫可能會引發(fā) L2 緩存寫操作。一般來說,L1 數(shù)據緩存寫操作的數(shù)量應該高于 L2 緩存寫操作的數(shù)量。對于一些常用的工作負載(例如 Redis 和 Nginx),如果我們對 PMU 進行監(jiān)控,就會發(fā)現(xiàn) L1 數(shù)據緩存寫操作的數(shù)量會高于 L2 緩存寫操作的 PMU 值。但對于某些工作負載而言,L1 數(shù)據緩存寫操作的 PMU 值要低于 L2 緩存寫操作的 PMU 值。
本文中,我們將分析 L2D_CACHE_WR 的計數(shù),以及在何種情況下,L1D_CACHE_WR 的 PMU 值會低于 L2D_CACHE_WR。
驗證平臺
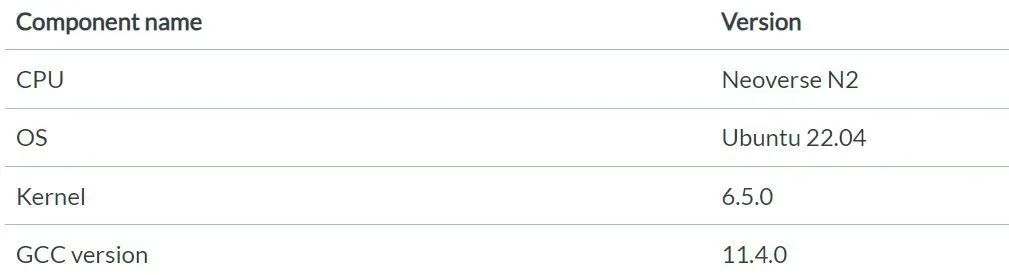
本文中的測試都是基于 Arm Neoverse N2 平臺的服務器。下表顯示了該服務器的硬件和軟件版本信息。
調查
對于大多數(shù)工作負載而言,L1D_CACHE_WR 的 PMU 值要高于 L2D_CACHE_WR。例如,對于 Redis 來說,一個 Redis 進程在Core 1 上運行。使用 Memtier 客戶端來生成讀寫混合請求。

以下是 Neoverse N2 PMU 指南[1]中 L1D_CACHE_WR 和 L2D_CACHE_WR 的定義。
L1D_CACHE_WR:此事件將統(tǒng)計在 L1 數(shù)據緩存中查找的任何內存寫入操作。此事件還將統(tǒng)計由數(shù)據緩存按虛擬地址清零 (DC ZVA) 指令所引發(fā)的訪問操作。
L2D_CACHE_WR:此事件將統(tǒng)計由 CPU 發(fā)出并在統(tǒng)一 L2 緩存中查找的任何內存寫入操作。無論 L2 緩存是否命中,該事件都將計數(shù)。此事件還將統(tǒng)計從 L1 數(shù)據緩存分配到 L2 緩存的任何回寫。此事件將 DC ZVA 操作視為存儲指令并統(tǒng)計這些訪問。來自 CPU 外部的監(jiān)聽不計算在內。
從 Neoverse N2 技術參考手冊[2]中我們知道,L1 緩存和 L2 緩存之間具有嚴格的包含關系。存在于 L1 緩存中的任何緩存行也同樣存在于 L2 緩存中。
經過分析研究,我們發(fā)現(xiàn)如下規(guī)律:
L2D_CACHE_WR 的 PMU 值約等于“L1 數(shù)據緩存重填”、“L1 指令緩存重填”和“L1 預取重填”的 PMU 值之和。
為什么我們要從這三個事件開始分析?
因為這三個事件都會引起 L1 數(shù)據緩存和 L1 指令緩存的替換行為,包括干凈替換 (clean evictions) 和臟替換 (dirty evictions)。如果仔細看 L2D_CACHE_WR 的定義,您會發(fā)現(xiàn)它將統(tǒng)計從 L1 數(shù)據緩存分配到 L2 緩存的任何回寫。L1 數(shù)據緩存回寫則統(tǒng)計從 L1 數(shù)據緩存到 L2 緩存的任何臟數(shù)據回寫,該值通常非常小,與 L2D_CACHE_WR 的值并不匹配,且沒有專門針對干凈替換的 PMU 計數(shù)器。因此,我們綜合考慮了所有可能導致緩存替換的事件(包括干凈替換和臟替換),從不同的角度進行分析,找到了這個規(guī)律。

我們已在幾個典型場景中驗證了這一發(fā)現(xiàn)。大多數(shù)測試用例確實遵循這種規(guī)律。
對于 Redis 的情況
我們使用 Memtier 客戶端作為負載生成器,為 Redis 進程生成混合讀寫請求,結果發(fā)現(xiàn) PMU 值遵循相應規(guī)律。

對于“Telemetry: ustress: l1d_cache_workload”[3]的情況
此基準測試僅讀取數(shù)據,旨在對 L1 數(shù)據緩存的未命中情況進行壓力測試,結果發(fā)現(xiàn) PMU 值遵循相應規(guī)律。

對于“Telemetry: ustress: l1i_cache_workload”[4]的情況
此基準測試將重復調用那些與頁面邊界對齊的函數(shù),旨在對 CPU L1 指令緩存的未命中情況進行壓力測試,結果發(fā)現(xiàn) PMU 值遵循相應規(guī)律。

對于 Eigen gemm 的情況
此基準測試包含許多讀取操作。L1D_CACHE_WR 的 PMU 值比較小,但 L1 緩存的預取操作導致 L2D 的 PMU 值很大。因此,我們得到的結果是 L1D_CACHE_WR 的 PMU 值要低于 L2D_CACHE_WR。PMU 值也遵循這種規(guī)律。

但是,流寫入是一個例外。我們使用“Telemetry: ustress: memcpy_workload”[5]基準測試,對加載-存儲 (load-store) 管線中完全處于 L1D 緩存內的 memcpy 進行壓力測試。memcpy 觸發(fā)流寫入,跳過 L1 并直接寫入 L2。此時,PMU 值并不遵循這種規(guī)律。

以下是 Neoverse N2 技術參考手冊中關于寫入流模式的描述。
Neoverse N2 核心支持寫入流模式(有時也稱為讀取分配模式),這一點同時適用于 L1 和 L2 緩存。
當發(fā)生讀取未命中或寫入未命中時,會向 L1 和 L2 緩存分配緩存行。但是,寫入大塊數(shù)據可能會導致不必要的數(shù)據浪費緩存空間。這也可能會浪費功率和性能,因為在執(zhí)行行填充后,如果 memset() 隨后寫入了整行數(shù)據,行填充數(shù)據將被丟棄。有些情況下,不需要在寫入時分配緩存行,例如在執(zhí)行 C 標準庫 memset() 函數(shù)以將一大塊內存清除為某個已知值時。
為了防止不必要的緩存行分配,內存系統(tǒng)可以在行填充完成之前檢測核心何時寫入完整的緩存行。如果在可配置數(shù)量的連續(xù)行填充中檢測到這種情況,系統(tǒng)就會切換到寫入流模式。
在寫入流模式下,讀取操作會正常執(zhí)行,仍可能引發(fā)行填充。寫入操作還是會先查找緩存,但如果未命中,它們就會寫入 L2 或系統(tǒng),而不是開始行填充。
總結
在基于 Neoverse N2 的服務器上,L2D_CACHE_WR 會統(tǒng)計來自 L1 緩存的所有緩存替換(包括干凈替換和臟替換)以及流寫入。
對于讀取大量數(shù)據的工作負載,我們會看到,L1D_CACHE_WR 的 PMU 值要低于 L2D_CACHE_WR。
-
ARM
+關注
關注
134文章
9309瀏覽量
375053 -
服務器
+關注
關注
13文章
9693瀏覽量
87291 -
數(shù)據緩存
+關注
關注
0文章
24瀏覽量
7315 -
PMU
+關注
關注
1文章
120瀏覽量
22100
原文標題:深入研究 Arm Neoverse N2 PMU 事件 L2D_CACHE_WR
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
Arm Neoverse家族新增V1和N2兩大平臺,突破高性能計算瓶頸
ARM Neoverse N2 PMU指南
Arm Neoverse V1 PMU指南
Arm Neoverse N2汽車硬件技術概述
ARM Neoverse?N2軟件優(yōu)化指南
Arm Neoverse? N1 PMU指南
Arm Neoverse? N2核心加密擴展技術參考手冊
ARM Neoverse?N1核心技術參考手冊
ARM Neoverse?N2核心技術參考手冊
互聯(lián)網巨頭紛紛啟用Arm CPU架構,Arm最新Neoverse V1和N2平臺加速云服務器芯片自研
Arm推出新一代平臺 Neoverse V2 平臺
Neoverse N2和CMN-700系統(tǒng)的PoC點在哪里?
Arm 更新 Neoverse 產品路線圖,實現(xiàn)基于 Arm 平臺的人工智能基礎設施
Arm新Arm Neoverse計算子系統(tǒng)(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3






 工商網監(jiān)
工商網監(jiān)

評論