") 算法與數(shù)據(jù)結(jié)構(gòu)——雙向鏈表
算法與數(shù)據(jù)結(jié)構(gòu)——雙向鏈表
周立功教授數(shù)年之心血之作《程序設(shè)計與數(shù)據(jù)結(jié)構(gòu)》以及《面向AMetal框架與接口的編程(上)》,書本內(nèi)容公開后,在電子行業(yè)掀起一片學(xué)習(xí)熱潮。經(jīng)周立功教授授權(quán),本公眾號特對《程序設(shè)計與數(shù)據(jù)結(jié)構(gòu)》一書內(nèi)容進行連載,愿共勉之。
第三章為算法與數(shù)據(jù)結(jié)構(gòu),本文為3.3 雙向鏈表。
>>> 3.3 雙向鏈表
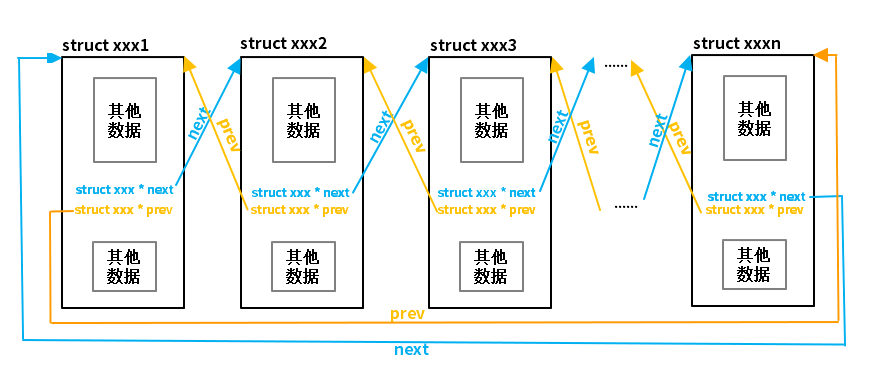
單向鏈表的添加、刪除操作,都必須找到當(dāng)前結(jié)點的上一個結(jié)點,以便修改上一個結(jié)點的p_next指針完成相應(yīng)的操作。由于單向鏈表的結(jié)點沒有指向其上一個結(jié)點的指針,因此只有從頭結(jié)點開始遍歷鏈表。當(dāng)某一結(jié)點的p_next指向當(dāng)前結(jié)點時,表明它為當(dāng)前結(jié)點的上一個結(jié)點。顯然每次都要從頭開始遍歷,其效率極為低下。在單向鏈表中,之所以可以直接獲取單向鏈表中當(dāng)前結(jié)點的下一個結(jié)點,是因為結(jié)點中包含了指向下一個結(jié)點的指針p_next。如果在雙向鏈表的結(jié)點中再增加一個指向它的前一個結(jié)點的前向指針p_prev,則一切問題將迎刃而解。那么,既有指向下一個結(jié)點的指針,又有指向前一個結(jié)點的指針的鏈表稱之為雙向鏈表,示意圖詳見圖3.15。

圖3.15 雙向鏈表示意圖
與單向鏈表一樣,雙向鏈表也定義了一個頭結(jié)點,基于單向鏈表將應(yīng)用數(shù)據(jù)與鏈表結(jié)構(gòu)相關(guān)數(shù)據(jù)完全分離的設(shè)計思想,則雙向鏈表結(jié)點僅保留p_next和p_prev指針。其數(shù)據(jù)結(jié)構(gòu)定義如下:

其中,dlist是double list 的縮寫,表明該結(jié)點是雙向鏈表結(jié)點。由此可見,雖然前向指針使得尋找鏈表的上一個結(jié)點變得非常容易,但由于結(jié)點中新增了一個指針,因此其內(nèi)存開銷將會是單向鏈表的兩倍。在實際應(yīng)用中,應(yīng)該權(quán)衡效率與內(nèi)存空間,在內(nèi)存資源非常緊缺的場合,如果結(jié)點的添加、刪除操作很少,一點效率的影響可以接受,則選擇使用單向鏈表。而不是一味地追求效率,認(rèn)為雙向鏈表比單向鏈表好,始終選擇使用雙向鏈表。
在圖3.15中,頭結(jié)點的p_prev和尾結(jié)點的p_next直接被設(shè)置為了NULL,此時,如果要直接由頭結(jié)點找到尾結(jié)點,或者由尾結(jié)點找到頭結(jié)點,都必須遍歷整個鏈表。可以對這兩個指針稍加利用,使頭結(jié)點的p_prev指向尾結(jié)點,尾結(jié)點的p_next指向頭結(jié)點,此時,該雙向鏈表就成了一個循環(huán)雙向鏈表,示意圖詳見圖3.16。
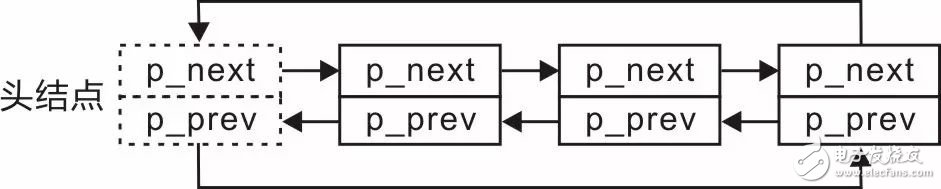
圖3.16 循環(huán)雙向鏈表示意圖
由于循環(huán)雙向鏈表的效率更高,可以直接從頭結(jié)點找到尾結(jié)點,或者從尾結(jié)點找到頭結(jié)點,且沒有額外的內(nèi)存空間消耗,僅僅是使用了兩個不打算使用的指針,算是廢物利用,因此下面介紹的雙向鏈表均視為循環(huán)雙向鏈表。
類似于單向鏈表,雖然頭結(jié)點與普通結(jié)點的內(nèi)容完全相同,但它們的含義卻有所區(qū)別,頭結(jié)點是鏈表的頭,代表了整個鏈表,擁有此頭結(jié)點,就表示其擁有了整個鏈表。為了便于區(qū)分頭結(jié)點與普通結(jié)點,可以單獨定義一個頭結(jié)點類型。比如:
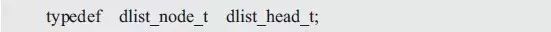
當(dāng)需要使用雙向鏈表時,首先需要使用該類型定義一個頭結(jié)點。比如:

由于此時還沒有添加其它任何結(jié)點,僅存在一個頭結(jié)點,因此該頭結(jié)點既是第一個結(jié)點(頭結(jié)點),又是最后一個結(jié)點(尾結(jié)點)。按照循環(huán)鏈表的定義,尾結(jié)點的p_next指向頭結(jié)點,頭結(jié)點的p_prev指向尾結(jié)點,僅有一個結(jié)點的示意圖詳見圖3.17。
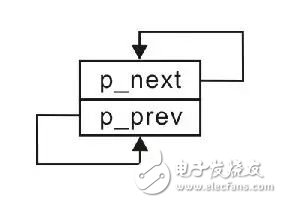
圖3.17 空鏈表
顯然,僅有頭結(jié)點時,其p_next和p_prev都指向本身。即:

為了避免用戶直接操作成員,需要定義一個初始化函數(shù),專門用于初始化鏈表頭結(jié)點中各個成員的值,其函數(shù)原型(dlist.h)為:

其中,p_head指向待初始化的鏈表頭結(jié)點。其調(diào)用形式如下:

dlist_init()函數(shù)的實現(xiàn)詳見程序清單3.33。
程序清單3.33 雙向鏈表初始化函數(shù)

與單向鏈表類似,將提供一些基礎(chǔ)的操作接口,它們的函數(shù)原型如下:

對于dlist_prev_get()和dlist_next_get(),在鏈表結(jié)點中已經(jīng)存在指向前驅(qū)后后繼的指針,詳見程序清單3.34。
程序清單3.34 得到結(jié)點前驅(qū)和后繼的函數(shù)實現(xiàn)

dlist_tail_get()函數(shù)用于得到鏈表的尾結(jié)點,在循環(huán)雙向鏈表中,頭結(jié)點的p_reev即指向了尾結(jié)點,詳見程序清單3.35。
程序清單3.35 dlist_tail_get()函數(shù)實現(xiàn)

dlist_begin_get()函數(shù)用于得到第一個用戶結(jié)點,詳見程序清單3.36。
程序清單3.36 dlist_begin_get()函數(shù)實現(xiàn)

dlist_end_get()用于得到鏈表的結(jié)束位置,當(dāng)雙向鏈表設(shè)計為循環(huán)雙向鏈表時,則頭結(jié)點的p_prev和尾結(jié)點的p_next都被有效地利用了,任何有效結(jié)點的p_next和p_prev都不再為NULL。顯然,不能再以NULL作為結(jié)束位置了,當(dāng)從第一個結(jié)點開始順序訪問鏈表的各個結(jié)點時,尾結(jié)點的下一個結(jié)點就是鏈表頭結(jié)點(head),因此結(jié)束位置就是頭結(jié)點本身。dlist_end_get()的實現(xiàn)詳見程序清單3.37。
程序清單3.37 dlist_end_get()函數(shù)實現(xiàn)

3.3.1 添加結(jié)點
假定還是將結(jié)點添加到鏈表尾部,其函數(shù)原型為:

其中,p_head為指向鏈表頭結(jié)點的指針,p_node為指向待添加結(jié)點的指針,其使用范例詳見程序清單3.38。
程序清單3.38 dlist_add_tail()函數(shù)使用范例

為了實現(xiàn)該函數(shù),可以先查看添加結(jié)點前后鏈表的變化,詳見圖3.18。

圖3.18 添加結(jié)點示意圖
由此可見,添加一個結(jié)點至鏈表尾部,需要4個指針(圖中虛線箭頭):
-
新結(jié)點的p_prev指向尾結(jié)點;
-
新結(jié)點的p_next指向頭結(jié)點;
-
尾結(jié)點的p_next由指向頭結(jié)點變?yōu)橹赶蛐陆Y(jié)點;
-
頭結(jié)點的p_prev由指向尾結(jié)點修改為指向新結(jié)點。
通過這些操作后,當(dāng)結(jié)點添加到鏈表尾部后,就成為了新的尾結(jié)點,詳見程序清單3.39。
程序清單3.39 dlist_add_tail()函數(shù)實現(xiàn)

實際上循環(huán)鏈表,無論是頭結(jié)點、尾結(jié)點還是普通結(jié)點,其本質(zhì)上都是一樣的,均為p_next成員指向下一個結(jié)點,p_prev成員指向其上一個結(jié)點。因此,對于添加結(jié)點而言,無論將結(jié)點添加到鏈表頭、鏈表尾還是其它任意位置,其操作方法完全相同。為此,需要提供一個更加通用的函數(shù),可以將結(jié)點添加到任意結(jié)點之后,其函數(shù)原型為:

其中,p_head為指向鏈表頭結(jié)點的指針,p_pos指定了添加的位置,新結(jié)點即添加在該指針指向的結(jié)點之后;p_node為指向待添加結(jié)點的指針。比如,同樣將結(jié)點添加到鏈表尾部,其使用范例詳見程序清單3.40。
程序清單3.40 dlist_add()函數(shù)使用范例

由此可見,將尾結(jié)點作為結(jié)點添加的位置,同樣可以將結(jié)點添加至尾結(jié)點之后,即添加到鏈表尾部。顯然,也就沒有必要再編寫dlist_add_tail()實現(xiàn)代碼了,使用dlisd_add()即可,修改dlist_add_tail()函數(shù)的實現(xiàn),詳見程序清單3.41。
程序清單3.41 dlist_add_tail()函數(shù)實現(xiàn)

為了實現(xiàn)dlist_add()函數(shù),可以先查看添加一個結(jié)點到任意結(jié)點之后的情況,詳見圖3.19。圖中展示的是一種通用的情況,由于結(jié)點的添加位置(頭、尾或其它任意位置)與添加結(jié)點的方法沒有關(guān)系,因此沒有特別標(biāo)明頭結(jié)點和尾結(jié)點。
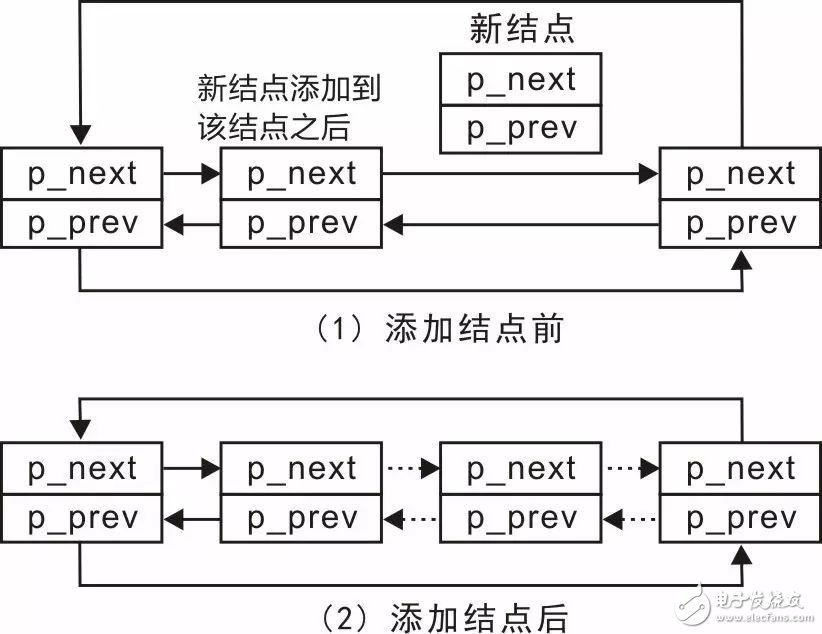
圖3.19 添加結(jié)點示意圖
其實,對比圖3.18和圖3.19可以發(fā)現(xiàn),圖3.18展示的只是圖3.19的一個特例,即恰好圖3.19中的新結(jié)點之前的結(jié)點就是尾結(jié)點,添加結(jié)點的過程同樣需要修改4個指針的值。為便于描述,將新結(jié)點前的結(jié)點稱之為前結(jié)點,新結(jié)點之后的結(jié)點稱之為后結(jié)點。顯然,在添加新結(jié)點之前,前結(jié)點的下一個結(jié)點即為后結(jié)點。對設(shè)置4個指針值的描述如下:
-
新結(jié)點的p_prev指向前結(jié)點;
-
新結(jié)點的p_next指向后結(jié)點;
-
前結(jié)點的p_next由指向后結(jié)點變?yōu)橹赶蛐陆Y(jié)點;
-
后結(jié)點的p_prev由指向前結(jié)點修改為指向新結(jié)點。
對比將結(jié)點添加到鏈表尾部的描述,只要將描述中的“前結(jié)點”換為“尾結(jié)點”,“后結(jié)點”換為“頭結(jié)點”,它們的含義則完全一樣,顯然將結(jié)點添加到鏈表尾部只是這里的一個特例,添加結(jié)點的函數(shù)實現(xiàn)詳見程序清單3.42。
程序清單3.42 dlist_add()函數(shù)實現(xiàn)

盡管上面的函數(shù)在實現(xiàn)時并沒有用到參數(shù)p_head,但還是將p_head參數(shù)傳進來了,因為實現(xiàn)其它的功能時將會用到p_head參數(shù),比如,判斷p_pos是否在鏈表中。
有了該函數(shù),添加結(jié)點到任意位置就非常靈活了,比如,提供一個添加結(jié)點到鏈表的頭部,使其作為鏈表的第一個結(jié)點的函數(shù),其函數(shù)原型為:
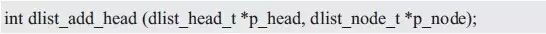
此時,頭結(jié)點即為新添加結(jié)點的前結(jié)點,直接調(diào)用dlist_add()即可實現(xiàn),其實現(xiàn)范例詳見程序清單3.43。
程序清單3.43 dlist_add_head()函數(shù)實現(xiàn)

3.3.2 刪除結(jié)點
基于添加結(jié)點到任意位置的思想,需要實現(xiàn)一個刪除任意結(jié)點的函數(shù)。其函數(shù)原型為:

其中,p_head為指向鏈表頭結(jié)點的指針, p_node為指向待刪除結(jié)點的指針,使用范例詳見程序清單3.44。
程序清單3.44 dlist_del()使用范例程序

為了實現(xiàn)dlisd_del()函數(shù),可以先查看刪除任意結(jié)點的示意圖,圖 3.20(1)為刪除節(jié)點前的示意圖,圖 3.20(2)為刪除節(jié)點后的示意圖。

圖 3.20添加結(jié)點示意圖
由此可見,僅需要修改兩個指針的值:
-
將“刪除結(jié)點”的前結(jié)點的p_next修改為指向“刪除結(jié)點”的后結(jié)點;
-
將“刪除結(jié)點”的后結(jié)點的p_prev修改為指向“刪除結(jié)點”的前結(jié)點。
刪除結(jié)點函數(shù)的實現(xiàn)詳見程序清單3.45。
程序清單3.45 dlist_del()函數(shù)實現(xiàn)

為了防止刪除頭結(jié)點,程序中對p_head與p_node進行了比較,當(dāng)p_node為頭結(jié)點時,則直接返回錯誤。
3.3.3 遍歷鏈表
與單向鏈表類似,需要一個遍歷鏈表各個結(jié)點的函數(shù),其函數(shù)原型(dlist.h)為:

其中,p_head指向鏈表頭結(jié)點,pfn_node_process為結(jié)點處理回調(diào)函數(shù),每遍歷到一個結(jié)點時,均會調(diào)用該函數(shù),便于用戶處理結(jié)點。dlist_node_process_t類型定義如下:

dlist_node_process_t類型參數(shù)為一個p_arg指針和一個結(jié)點指針,返回值為int類型的函數(shù)指針。每遍歷到一個結(jié)點均會調(diào)用pfn_node_process指向的函數(shù),便于用戶根據(jù)需要自行處理結(jié)點數(shù)據(jù)。當(dāng)調(diào)用該回調(diào)函數(shù)時,傳遞給p_arg的值即為用戶參數(shù),其值與dlist_traverse()函數(shù)的第3個參數(shù)一樣,即該參數(shù)的值完全是由用戶決定的;傳遞給p_node 的值即為指向當(dāng)前遍歷到的結(jié)點的指針。當(dāng)遍歷到某個結(jié)點時,如果用戶希望終止遍歷,此時,只要在回調(diào)函數(shù)中返回負(fù)值即可終止繼續(xù)遍歷。一般地,若要繼續(xù)遍歷,則函數(shù)執(zhí)行結(jié)束后返回0即可。dlist_foreach()函數(shù)的實現(xiàn)詳見程序清單3.46。
程序清單3.46 鏈表遍歷函數(shù)的實現(xiàn)

為了便于查閱,如程序清單3.47所示展示了dlist.h文件的內(nèi)容。
程序清單3.47 dlist.h文件內(nèi)容

同樣以int類型數(shù)據(jù)為例,來展示這些接口的使用方法。為了使用鏈表,首先應(yīng)該定義一個結(jié)構(gòu)體,將鏈表結(jié)點作為其一個成員,此外,再添加一些應(yīng)用相關(guān)的數(shù)據(jù),如定義如下包含鏈表結(jié)點和int型數(shù)據(jù)的結(jié)構(gòu)體:

綜合范例程序詳見程序清單3.48。
程序清單3.48 綜合范例程序

與單向鏈表的綜合范例程序比較可以發(fā)現(xiàn),程序主體是完全一樣的,僅僅是各個結(jié)點的類型發(fā)生了改變。對于實際的應(yīng)用,如果由使用單向鏈表升級為雙向鏈表,雖然程序主體沒有發(fā)生改變,但由于類型的變化,則不得不修改所有程序代碼。這是由于應(yīng)用與具體數(shù)據(jù)結(jié)構(gòu)沒有分離造成的,因此可以進一步將實際應(yīng)用與具體的數(shù)據(jù)結(jié)構(gòu)分離,將鏈表等數(shù)據(jù)結(jié)構(gòu)抽象為“容器”的概念。
-
周立功
+關(guān)注
關(guān)注
38文章
130瀏覽量
37869 -
鏈表
+關(guān)注
關(guān)注
0文章
80瀏覽量
10626
原文標(biāo)題:周立功:高效使用雙向鏈表
文章出處:【微信號:ZLG_zhiyuan,微信公眾號:ZLG致遠(yuǎn)電子】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
數(shù)據(jù)結(jié)構(gòu)中最簡單的鏈表
數(shù)據(jù)結(jié)構(gòu)與算法分析(Java版)(pdf)
Linux Kernel數(shù)據(jù)結(jié)構(gòu):鏈表
常見的數(shù)據(jù)結(jié)構(gòu)
數(shù)據(jù)結(jié)構(gòu)鏈表的基本操作
Linux內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)的一點認(rèn)識
數(shù)據(jù)結(jié)構(gòu)與算法習(xí)題
數(shù)據(jù)結(jié)構(gòu)與算法
java數(shù)據(jù)結(jié)構(gòu)學(xué)習(xí)
大牛分享平時如何學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)與算法
區(qū)塊鏈的基本數(shù)據(jù)結(jié)構(gòu)解析
你知道Linux內(nèi)核數(shù)據(jù)結(jié)構(gòu)中雙向鏈表的作用?
Linux內(nèi)核的鏈表數(shù)據(jù)結(jié)構(gòu)
Linux內(nèi)核中使用的數(shù)據(jù)結(jié)構(gòu)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論