
AI爆發,芯片致勝
AI進入爆發期,千億芯片市場空間

AI沉浮數十載,“預期-失望-進步-預期”周期中破浪前行。AI(人工智能)概念誕生于1956年達特茅斯(Dartmouth)會議,1959年劃時代論文《計算機器與智能》中提出AI領域著名的圖靈測試;此后算法和研究不斷迭代,經歷1956-1974年的推理黃金時代、1974-1980年的第一次瓶頸期、1980-1987年專家系統發展、1987-1993年的第二次寒冬及1993-2010年學習期復蘇,之后跟隨大數據、云計算興起,算法模型和并行運算的結合雙輪驅動人工智能發展,目前進入爆發期,表現在三個層面:
(1)生態基礎層面:移動互聯網、物聯網的快速發展為人工智能產業奠定生態基礎;
(2)軟件層面:已有數學模型被重新發掘,新興合適算法被發明,重要成果包括圖模型、圖優化、神經網絡、深度學習、增強學習等;
(3)硬件層面:摩爾定律助力,服務器強大的計算能力尤其是并行計算單元的引入使人工智能訓練效果顯著提速,除原有CPU外,GPU、FPGA、ASIC(包括TPU、NPU等AI專屬架構芯片)各種硬件被用于算法加速,提速人工智能在云端服務器和終端產品中的應用和發展。
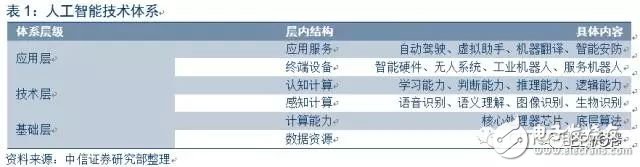
技術體系分層,核心處理芯片成基礎層關鍵。人工智能技術體系分為基礎層、技術層與應用層。基礎層主要包括人工智能核心處理芯片和大數據,是支撐技術層的圖像識別、語音識別等人工智能算法的基石。人工智能算法需要用到大量的卷積等特定并行運算,常規處理器(CPU)在進行這些運算時效率較低,適合AI的核心處理芯片在要求低延時、低功耗、高算力的各種應用場景逐漸成為必須。核心處理芯片和大數據,成為支撐人工智能技術發展的關鍵要素。
根據賽迪咨詢發布報告,2016年全球人工智能市場規模達到293億美元。人工智能芯片是人工智能市場中重要一環,根據英偉達,AMD,賽靈思,谷歌等相關公司數據,我們測算2016年人工智能芯片市場規模將達到23.88億美元,約占全球人工智能市場規模8.15%,而到2020年人工智能芯片市場規模將達到146.16億美元,約占全球人工智能市場規模12.18%。人工智能芯片市場空間極其廣闊。

芯片承載算法,是競爭的制高點
人工智能的基礎是算法,深度學習是目前最主流的人工智能算法。深度學習又叫深度神經網絡(DNN:Deep Neural Networks),從之前的人工神經網絡(ANN:Artificial Neural Networks)模型發展而來。這種模型一般采用計算機科學中的圖模型來直觀表達,深度學習的“深度”便指的是圖模型的層數以及每一層的節點數量。神經網絡復雜度不斷提升,從最早單一的神經元,到2012年提出的AlexNet(8個網絡層),再到2015年提出的ResNET(150個網絡層),層次間的復雜度呈幾何倍數遞增,對應的是對處理器運算能力需求的爆炸式增長。深度學習帶來計算量急劇增加,對計算硬件帶來更高要求。我們下文首先對深度學習算法進行簡單分析,闡述其和AI芯片的關系。

深度學習算法分“訓練”和“推斷”兩個過程。簡單來講,人工智能需要通過以大數據為基礎,通過“訓練”得到各種參數,把這些參數傳遞給“推斷”部分,得到最終結果。
“訓練”和“推斷”所需要的神經網絡運算類型不同。神經網絡分為前向計算(包括矩陣相乘、卷積、循環層)和后向更新(主要是梯度運算)兩類,兩者都包含大量并行運算。“訓練”所需的運算包括“前向計算+后向更新”;“推斷”則主要是“前向計算”。一般而言訓練過程相比于推斷過程計算量更大。一般來說,云端人工智能硬件負責“訓練+推斷”,終端人工智能硬件只負責“推斷”。
“訓練”需大數據支撐并保持較高靈活性,一般在“云端”(即服務器端)進行。人工智能訓練過程中,頂層上需要有一個海量的數據集,并選定某種深度學習模型。每個模型都有一些內部參數需要靈活調整,以便學習數據。而這種參數調整實際上可以歸結為優化問題,在調整這些參數時,就相當于在優化特定的約束條件,這就是所謂的“訓練”。云端服務器收集用戶大數據后,依靠其強大的計算資源和專屬硬件,實現訓練過程,提取出相應的訓練參數。由于深度學習訓練過程需要海量數據集及龐大計算量,因此對服務器也提出了更高的要求。未來云端AI服務器平臺需具備相當數據級別、流程化的并行性、多線程、高內存帶寬等特性。
“推斷”過程可在云端(服務器端)進行,也可以在終端(產品端)進行。等待模型訓練完成后,將訓練完成的模型(主要是各種通過訓練得到的參數)用于各種應用場景(如圖像識別、語音識別、文本翻譯等)。“應用”過程主要包含大量的乘累加矩陣運算,并行計算量很大,但和“訓練”過程比參數相對固化,不需要大數據支撐,除在服務器端實現外,也可以在終端實現。“推斷”所需參數可由云端“訓練”完畢后,定期下載更新到終端。

傳統CPU算力不足,新架構芯片支撐AI成必須。核心芯片決定計算平臺的基礎架構和發展生態,由于AI所需的深度學習需要很高的內在并行度、大量浮點計算能力以及矩陣運算,基于CPU的傳統計算架構無法充分滿足人工智能高性能并行計算(HPC)的需求,因此需要發展適合人工智能架構的專屬芯片。
專屬硬件加速是新架構芯片發展主流。目前處理器芯片面向人工智能硬件優化升級有兩種發展路徑:(1)延續傳統計算架構,加速硬件計算能力:以GPU、FPGA、ASIC(TPU、NPU等)芯片為代表,采用這些專屬芯片作為輔助,配合CPU的控制,專門進行人工智能相關的各種運算;(2)徹底顛覆傳統計算架構,采用模擬人腦神經元結構來提升計算能力,以IBM TrueNorth芯片為代表,由于技術和底層硬件的限制,第二種路徑尚處于前期研發階段,目前不具備大規模商業應用的可能性。從技術成熟度和商業可行性兩個角度,我們判斷使用AI專屬硬件進行加速運算是今后五年及以上的市場主流。
云端終端雙場景,三種芯片顯神通
我們把人工智能硬件應用場景歸納為云端場景和終端場景兩大類。云端主要指服務器端,包括各種共有云、私有云、數據中心等業務范疇;終端主要指包括安防、車載、手機、音箱、機器人等各種應用在內的移動終端。由于算法效率和底層硬件選擇密切相關,“云端”(服務器端)和“終端”(產品端)場景對硬件的需求也不同。我們對目前主要的AI芯片進行了列表梳理。

除CPU外,人工智能目前主流使用三種專用核心芯片,分別是GPU,FPGA,ASIC。專業術語比較枯燥,打個形象點的比方。如果把AI運算比喻成游泳運動,CPU,GPU,FPGA,ASIC相當于四類運動員:(1)CPU是身體素質很好的體校學員,會游泳,參賽比較費勁;(2)GPU相當于十項全能選手,本身就會游泳,直接可以上場參賽;(3)FPGA相當于可以變形的機器人選手,需預先變形后下水競爭,成績取決于編程效果;(4)ASIC相當于長時間培養的專業游泳選手,游得最快,但培養一個優秀專業運動員需要較長時間。
下面分別介紹。
GPU:先發制人的“十項全能”選手,云端終端均拔頭籌。GPU(Graphics Processing Unit)又稱圖形處理器,之前是專門用作圖像運算工作的微處理器。相比CPU,GPU由于更適合執行復雜的數學和幾何計算(尤其是并行運算),剛好與包含大量的并行運算的人工智能深度學習算法相匹配,因此在人工智能時代剛好被賦予了新的使命,成為人工智能硬件首選,在云端和終端各種場景均率先落地。目前在云端作為AI“訓練”的主力芯片,在終端的安防、汽車等領域,GPU也率先落地,是目前應用范圍最廣、靈活度最高的AI硬件。
FPGA:“變形金剛”,算法未定型前的階段性最佳選擇。FPGA(Field-ProgrammableGate Array)即現場可編程門陣列,是一種用戶可根據自身需求進行重復編程的“萬能芯片”。編程完畢后功能相當于ASIC(專用集成電路),具備效率高、功耗低的特點,但同時由于要保證編程的靈活性,電路上會有大量冗余,因此成本上不能像ASIC做到最優,并且工作頻率不能太高(一般主頻低于500MHz)。FPGA相比GPU具有低功耗優勢,同時相比ASIC具有開發周期快,更加靈活編程等特點。FPGA于“應用爆發”與“ASIC量產”夾縫中尋求發展,是效率和靈活性的較好折衷,“和時間賽跑”,在算法未定型之前具較大優勢。在現階段云端數據中心業務中,FPGA以其靈活性和可深度優化的特點,有望繼GPU之后在該市場爆發;在目前的終端智能安防領域,目前也有廠商采用FPGA方案實現AI硬件加速。
ASIC:“專精職業選手”,專一決定效率,AI芯片未來最佳選擇。ASIC(Application Specific Integrated Circuit)即專用集成電路,本文中特指專門為AI應用設計、專屬架構的處理器芯片。近年來涌現的類似TPU、NPU、VPU、BPU等令人眼花繚亂的各種芯片,本質上都屬于ASIC。無論是從性能、面積、功耗等各方面,AISC都優于GPU和FPGA,長期來看無論在云端和終端,ASIC都代表AI芯片的未來。但在AI算法尚處于蓬勃發展、快速迭代的今天,ASIC存在開發周期較長、需要底層硬件編程、靈活性較低等劣勢,因此發展速度不及GPU和FPGA。
下面兩章我們分別仔細分析云端和終端兩種應用場景下,這三種專屬AI芯片的應用現狀、發展前景及可能變革。
云端場景:GPU生態領先,未來多種芯片互補共存
核心結論: GPU、TPU等適合并行運算的處理器未來成為支撐人工智能運算的主力器件,既存在競爭又長期共存,一定程度可相互配合;FPGA有望在數據中心業務承擔較多角色,在云端主要作為有效補充存在;CPU會“變小”,依舊作為控制中心。未來芯片的發展前景取決于生態,有望統一在主流的幾個軟件框架下,形成云CPU+GPU/TPU+FPGA(可選)的多芯片協同場景。
依托大數據,科技巨頭不同技術路徑布局AI云平臺
基于云平臺,各大科技巨頭大力布局人工智能。云計算分為三層,分別是Infrastructure(基礎設施)-as-a-Service(IaaS),Platform(平臺)-as-a-Service(Paas),Software(軟件)-as-a-Service(Saas)。基礎設施在最下端,平臺在中間,軟件在頂端。IaaS公司提供場外服務器,存儲和網絡硬件。大數據為人工智能提供信息來源,云計算為人工智能提供平臺,人工智能關鍵技術是在云計算和大數據日益成熟的背景下取得了突破性進展。目前各大科技巨頭看好未來人工智能走向云端的發展態勢,紛紛在自有云平臺基礎上搭載人工智能系統,以期利用沉淀在云端的大數據挖掘價值。


千億美元云服務市場,AI芯片發展潛力巨大
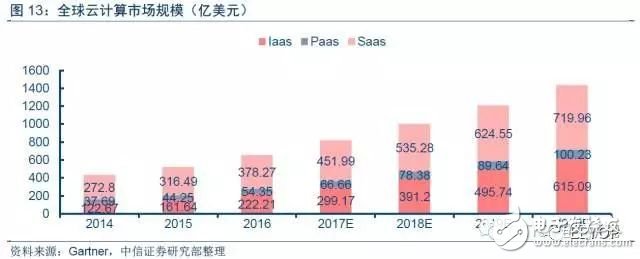
千億美元云服務市場,云計算硬件市場規模巨大。云計算的市場規模在逐漸擴大。據Gartner 的統計,2015年以IaaS、PaaS和SaaS為代表的典型云服務市場規模達到522.4億美元,增速20.6%,預計2020年將達到1435.3億美元,年復合增長率達22%。其中IaaS公司到2020年市場空間達到615億美元,占整個云計算市場達43%,云計算硬件市場空間巨大,而云計算和人工智能各種加速算法關系密切,未來的云計算硬件離不開AI芯片加速。
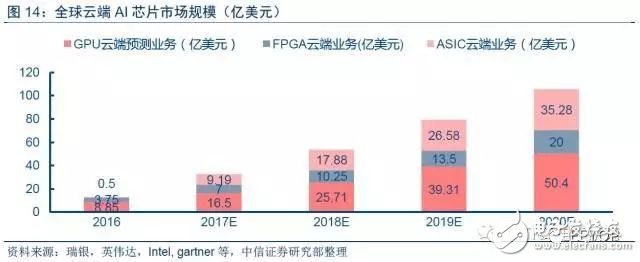
云端AI芯片發展潛力巨大。根據英偉達與AMD財務數據,我們預計GPU到2020年在數據中心業務中將達到約50億美元市場規模。同時根據賽靈思與阿爾特拉等FPGA廠商,我們預計2020年FPAG數據中心業務將達到20億美元。加上即將爆發的ASIC云端市場空間,我們預計到2020年云端AI芯片市場規模將達到105.68億美元,AI芯片在云端會成為云計算的重要組成部分,發展潛力巨大。
云端芯片現狀總結:GPU領先,FPGA隨后,ASIC萌芽

AI芯片在云端基于大數據,核心負責“訓練”。云端的特征就是“大數據+云計算”,用戶依靠大數據可進行充分的數據分析和數據挖掘、提取各類數據特征,與人工智能算法充分結合進行云計算,從而衍生出服務器端各種AI+應用。AI芯片是負責加速人工智能各種復雜算法的硬件。由于相關計算量巨大,CPU架構被證明不能滿足需要處理大量并行計算的人工智能算法,需要更適合并行計算的芯片,所以GPU、FPGA、TPU等各種芯片應運而生。AI芯片在云端可同時承擔人工智能的“訓練”和“推斷”過程。
云端芯片現狀:GPU占據云端人工智能主導市場,以TPU為代表的ASIC目前只運用在巨頭的閉環生態, FPGA在數據中心業務中發展較快。
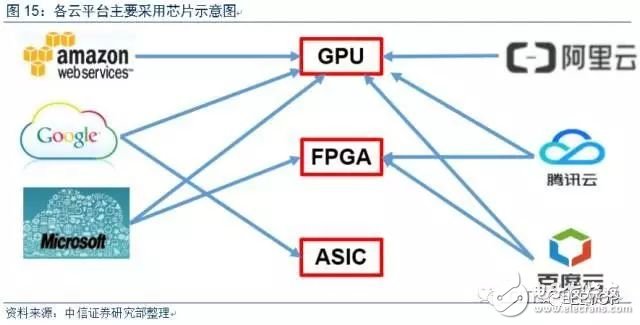
GPU應用開發周期短,成本相對低,技術體系成熟,目前全球各大公司云計算中心如谷歌、微軟、亞馬遜、阿里巴巴等主流公司均采用GPU進行AI計算;谷歌除大量使用GPU外,努力發展自己的AI專屬的ASIC芯片。今年5月推出的TPU與GPU相比耗電量降低60%,芯片面積下降40%,能更好的滿足其龐大的AI算力要求,但由于目前人工智能算法迭代較快,目前TPU只供谷歌自身使用,后續隨著TensorFlow的成熟,TPU也有外供可能,但通用性還有很長路要走。
百度等廠商目前在數據中心業務中也積極采用FPGA進行云端加速。FPGA可以看做從GPU到ASIC重點過渡方案。相對于GPU可深入到硬件級優化,相比ASIC在目前算法不斷迭代演進情況下更具靈活性,且開發時間更短。AI領域專用架構芯片(ASIC)已經被證明可能具有更好的性能和功耗,有望成為未來人工智能硬件的主流方向。
云端GPU:云端AI芯片主流,先發優勢明顯
1.1 發展現狀:GPU天然適合并行計算,是目前云端AI應用最廣的芯片
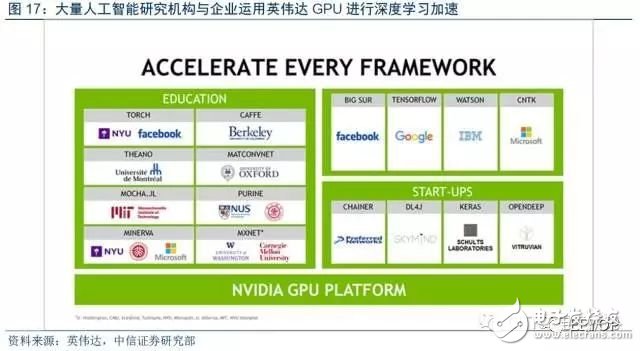
GPU目前云端應用范圍最廣。目前大量涉足人工智能的企業都采用GPU進行加速。根據英偉達官方資料,與英偉達合作開發深度學習項目的公司2016年超過19000家,對比2014年數量1500 家。目前百度、Google、Facebook 和微軟等IT巨頭都采用英偉達的GPU對其人工智能項目進行加速,GPU目前在云端AI深度學習場景應用最為廣泛, 由于其良好的編程環境帶來的先發優勢,預計未來仍將持續強勢。

GPU芯片架構脫胎圖像處理,并行計算能力強大。GPU(Graphics Processing Unit),又稱視覺處理器,是之前應用在個人電腦、工作站、游戲機、移動設備(如平板電腦、智能手機等)等芯片內部,專門用作圖像運算工作的微處理器。與CPU類似可以編程,但相比CPU更適合執行復雜的數學和幾何計算,尤其是并行運算。內部具有高并行結構(highly paralle lstructure),在處理圖形數據和復雜算法方面擁有比CPU更高的效率。
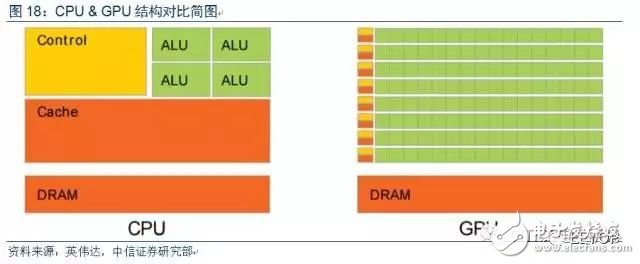
GPU較CPU結構差異明顯,更適合并行計算。對比GPU和CPU在結構上的差異,CPU大部分面積為控制器和寄存器,GPU擁有更多的ALU(Arithmetic Logic Unit,邏輯運算單元)用于數據處理,而非數據高速緩存和流控制,這樣的結構適合對密集型數據進行并行處理。CPU執行計算任務時,一個時刻只處理一個數據,不存在真正意義上的并行,而GPU具有多個處理器核,同一時刻可并行處理多個數據。
與CPU相比,GPU在AI領域的性能具備絕對優勢。深度學習在神經網絡訓練中,需要很高的內在并行度、大量的浮點計算能力以及矩陣運算,而GPU可以提供這些能力,并且在相同的精度下,相對傳統CPU的方式,擁有更快的處理速度、更少的服務器投入和更低的功耗。在2017年5月11日的加州圣何塞GPU技術大會上,NVIDIA就已經發布了Tesla V100。這個目前性能最強的GPU運算架構Volta采用臺積電12nm FFN制程并整合210億顆電晶體,在處理深度學習的性能上等同于250顆CPU。

1.2 生態格局:英偉達壟斷GPU市場
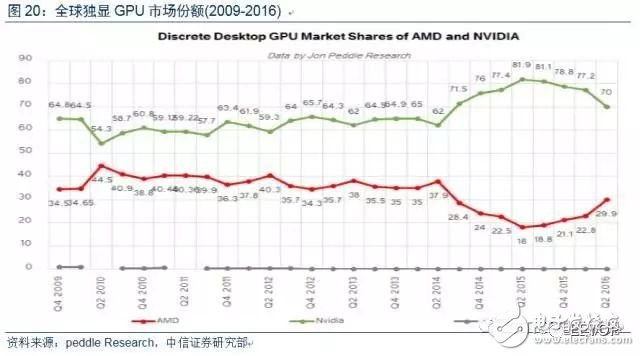
抓住人工智能契機,英偉達壟斷GPU市場。英偉達目前占據全球GPU行業的市場份額超過70%,遠超AMD等競爭對手。GPU作為英偉達公司的核心產品占據其84%的收入份額。英偉達應用領域涵蓋視頻游戲、電影制作、產品設計、醫學診斷以及科學研究等各個門類。主營產品包括游戲顯卡GeForceGPU,用于深度學習計算的Tesla GPU,以及為智能汽車處理設計Tegra 處理器等。得益于人工智能發展,英偉達營收利潤不斷攀升,成為人工智能產業最大受益公司之一。

編程環境良好,是英偉達GPU壟斷云端AI硬件主流的重要原因。由于廣泛應用于圖形圖像處理,GPU具備相對良好的編程環境和使用其編程的軟件工程師人群,因此成為目前最主流的深度學習硬件。英偉達公司發布的CUDA運算平臺,是專門針對開發者提供的一種并行計算平臺。開發者能通過CUDA平臺使用軟件語言很方便得開發英偉達GPU實現運算加速。由于CUDA平臺之前被廣泛認可和普及,積累了良好的編程環境,目前應用在人工智能領域、可進行通用計算的GPU市場基本被英偉達壟斷。

云端數據中心及車載等AI相關領域,成為英偉達業務成長新引擎。英偉達公司2017財年全年營收創下69.1億美元紀錄,較上2016財年的50.1億美元增長38%。按照終端用戶應用領域拆分,英偉達主營業務拆分為游戲、數據中心、專業可視化、汽車業務。游戲業務2017財年營收達到40.6億美元,占總營收58.8%,同比增長44.1%;數據中心和汽車的份額分別占總營收12%和7%,其中數據中心增長同比達到144.8%,汽車增長同比達到52.2%。公司從2017財年Q1季度到2018財年Q1季度,主營構成變動很大,數據中心業務占比11%增長至21%,成長速度迅猛,成為英偉達業務增長新引擎。
1.3 未來趨勢:從開環到專精,未來GPU在云端市場繼續強勢
GPU不斷適應AI的進化路徑,未來進化方向:從“開環”到“專精”。目前云端應用范圍最廣、效率最高的AI芯片仍是GPU。但AI芯片并非只有GPU一種路徑,ASIC與FPGA相關廠商相繼推出針對人工智能計算的芯片。谷歌推出ASIC芯片TPU2代,性能達到45 TFLOPS(一個TFLOPS等于每秒萬億次的浮點運算),而功耗僅僅40W。國內公司寒武紀推出的ASIC芯片DaDianNao性能達到5.585 TFLOPS,功耗僅為15.97W。眾多專屬ASIC芯片的推出,可能威脅到未來GPU的霸主地位。英偉達顯然意識到這一點,不斷推動技術創新,推出性能更加強勁、更適合AI運算的產品,不斷對其GPU進行深度優化,向更專精AI運算方向努力。2017年5月,英偉達發布旗艦芯片Tesla V100,對比上一代TeslaP100,最大變化就是增加了與深度學習高度相關的Tensor單元,Tensor性能可以達到120TFLOPS。GPU不斷適應AI的進化路徑,從從“開環通用”到“AI專精”方向進化,性能不斷提高,加之生態環境的先發優勢,預計未來2~3年,GPU仍是人工智能云端市場最重要的組成部分。

云端ASIC:以TPU為代表,性能取勝,爭奪未來AI制高點
2.1發展趨勢:ASIC—未來人工智能專屬核心芯片
ASIC目前在AI方向上的發展尚處于早期。ASIC全稱專用集成電路,是應針對特定場景、需求、算法而設計的專用芯片。目前人工智能類 ASIC 的發展仍處于早期。根本原因是目前人工智能算法尚未定型,迭代較快,而ASIC設計一旦設計制造完成后功能就基本固定,相對GPU、FPGA而言不夠靈活,且開發周期長、初期成本高。人工智能ASIC芯片公司需要既具備人工智能算法框架,又擅長芯片研發,進入門檻較高。
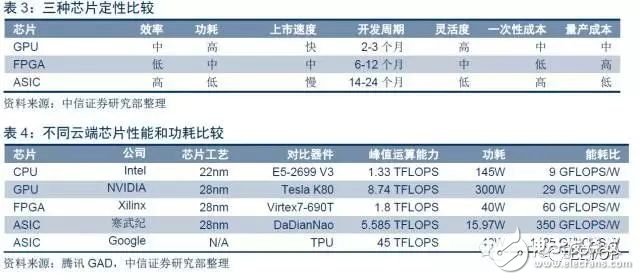
ASIC性能、能耗和大規模量產成本均顯著優于GPU和FPGA,是未來云端人工智能重要發展方向。針對特定云端應用,作為全定制設計的ASIC芯片,性能和能耗都要優于FPGA 和 GPU。谷歌最近研發出人工智能ASIC TPU,和傳統的GPU相比性能提升15倍,更是CPU 浮點性能的30倍。由于ASIC兼具性能和功耗雙重優點,加之大規模量產條件下ASIC單片成本大幅下降,我們判斷其定會成為人工智能未來的核心芯片。
2.2生態格局:谷歌TPU為目前自用最強ASIC,期待生態完善后外供
TPU:目前谷歌自用最強ASIC芯片,期待生態完善后外供。隨著 AlphaGo 橫掃人類頂尖棋手,谷歌在AlphaGo 中應用的 ASIC 芯片TPU受到業界熱捧,谷歌于 2016年 Google I/O 大會上正式介紹第一代 TPU 產品,在今年5 月的開發者 I/O 大會上, Google 正式公布了第二代 TPU,又稱為 Cloud TPU,其最大的特色在于相比初代TPU, 它既可以用于訓練神經網絡,又可以用于推理,這既為推理階段進行了優化,也為訓練階段進行了優化。在性能方面,第二代 TPU 可以達到 45 TFLOPs 的浮點性能。和傳統的 GPU 相比提升 15 倍,更是CPU浮點性能的30倍。生態方面,目前TPU僅支持自身的開源 TensorFlow 機器學習框架和生態系統。這和生態系統非常完善的GPU相比有一定的不足。不過谷歌也意識到了這個不足,為了彌補生態上面的不足,谷歌提出了TensorFlow Research Cloud計劃,為愿意分享自己工作成果的研究人員免費提供1000個Cloud TPU。相信隨著TPU生態的不斷完善,性能更加強悍的TPU將成為云端人工智能的未來。

3.云端FGPA:云端的有效補充,低延時場景具備充分優勢
3.1 會變形的萬能芯片,未來云端AI的最好補充
FPGA可編程,靈活性高。FPGA(Field-Programmable Gate Array),即現場可編程門陣列,它是在PAL、CPLD等可編程器件的基礎上進一步發展的產物。FPGA內部包含大量重復的IOB(輸入輸出模塊)、CLB(可配置邏輯塊,內部是基本的邏輯門電路,與門、或門等)和布線信道等基本單元。FPGA在出廠時是“萬能芯片”,用戶可根據自身需求,用硬件描述語言(HDL)對FPGA的硬件電路進行設計;每完成一次燒錄,FPGA內部的硬件電路就有了確定的連接方式,具有了一定的功能。FPGA可隨意定制內部邏輯的陣列,并且可以在用戶現場進行即時編程,以修改內部的硬件邏輯,從而實現任意邏輯功能。
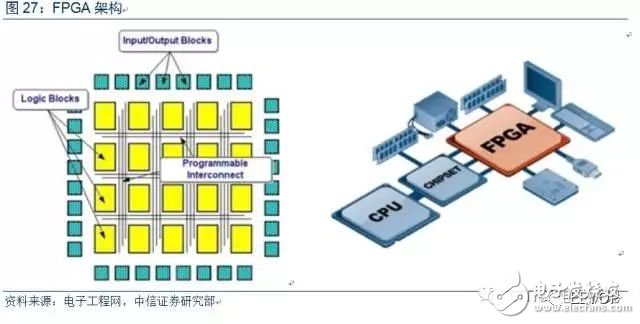
3.2 核心優勢:在云端算法性能高、功耗和延遲低
FPGA無指令、無共享內存,并行計算效率高。CPU、GPU都屬于馮·諾依曼結構,需要指令譯碼執行、共享內存,是傳統意義上的“軟件編程”。而FPGA每個邏輯單元的功能在重編程(燒寫)時就已經確定,不需要指令,屬于“硬件編程”;FPGA每個邏輯單元與周圍邏輯單元的連接在重編程時就已經確定,也不需要通過共享內存來通信。FPGA利用硬件并行的優勢,打破順序執行的模式,因此在每個時鐘周期內完成更多的處理任務,執行效率大幅提高。
FPGA相對CPU、GPU能耗優勢明顯。一方面,由于是直接燒錄成專用電路,FPGA沒有存取指令和指令譯碼操作,因此功耗優勢明顯。Intel的CPU指令譯碼就占整個芯片能耗的50%;在GPU里面,取指令和譯碼也消耗了10%~20%的功耗。另一方面,FPGA的主頻比CPU與GPU低很多,通常CPU與GPU都在1GHz到3GHz之間,而FPGA主頻一般在500MHz以下。微軟研究院2010年分析了CPU、GPU以及FPGA對矩陣運算的底層庫相同運算的加速性能以及能耗,對比執行GaxPy算法(一種常用矩陣算法)每次迭代的時間和能耗,結論是FPGA、GPU相對于CPU的加速比優勢明顯,與此同時FPGA的能耗僅是CPU與GPU的8%左右。
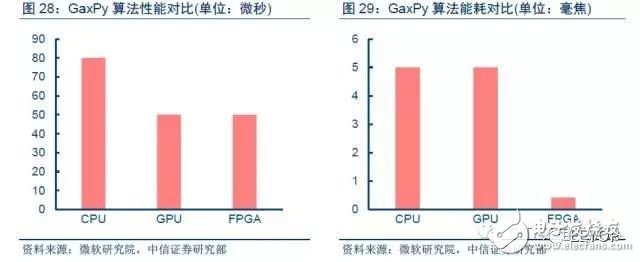
對于計算/通信密集型任務,FPGA比CPU、GPU延遲低。FPGA同時可擁有流水線并行和數據并行,而GPU幾乎只有數據并行(流水線深度受限)。當任務是逐個而非成批到達的時候,流水線并行比數據并行可實現更低的延遲,FPGA比GPU天生有延遲方面的優勢。對于通信密集型任務,FPGA相比CPU、GPU的低延遲優勢更明顯。使用FPGA和ASIC等低延遲和高吞吐量的硬件,運行在網絡的最低層,保證所有數據以安全及時的方式傳輸,能夠提高網絡可靠性并節省負載。
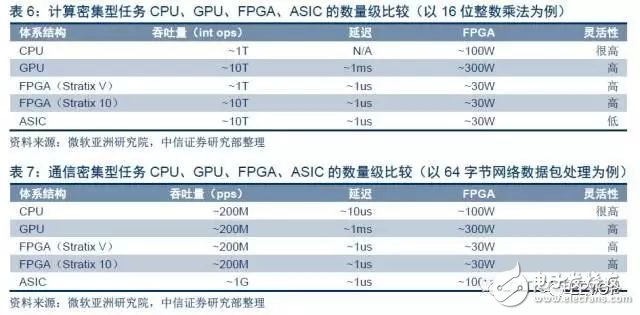
靈活性和效率的折衷,適應數據中心不斷變化的算法。FPGA在數據中心最大的特點就在高吞吐的同時能做到低延時。FPGA內部的資源都是可以重配置的,因此它可以很容易進行數據并行和流水并行,且易于在數據并行和流水并行之間平衡。而GPU幾乎只能做數據并行。與ASIC相比,FPGA的可編程性體現出很大的優勢。現在數據中心的各種算法每時每刻都在更新變化,沒有足夠穩定的時間讓ASIC完成長周期的開發。比如在一種神經網絡模型出來之后開始把它做成ASIC,也許還未投片生產,這個神經網絡模型已經被另一種神經網絡模型所替代。另一方面,FPGA可以在不同的業務需求之間做平衡。比如說白天用于為搜索業務排序的機器;在晚上請求很少的情況下,可以將這些FPGA重新配置成離線數據分析的功能,提供對離線數據進行分析的服務。目前騰訊云和百度云都大量部署FPGA在數據中心的服務器用于加速。

可編程性會導致面積和功耗冗余,長期看在云端比終端應用更廣泛。FPGA的工作模式,決定了需要預先布置大量門陣列以滿足用戶的設計需求,因此有“以面積換速度”的說法:使用大量的門電路陣列,消耗更多的FPGA內核資源,用來提升整個系統的運行速度。因此,FPGA的可編程性和靈活性必然會導致一定程度上的面積和功耗冗余,但很多場景中可編程性收益遠高于冗余成本,這些場景往往在云端更多。因為終端只做“推理”,特定場景算法更為固定,成本要求也更高,因此FPGA在終端最終會被ASIC取代。
3.3 市場空間:緊隨GPU受益云端數據中心市場爆發,2020年規模或達20億美元
FPGA數據中心業務將緊隨GPU爆發,預計未來5年潛在市場空間達20億美元。據 Gartner 統計, 2014 年全球 FPGA 市場規模達到 50 億美元,2015-2020 年的年均復合增長率為9%,到 2020 年將達到 84 億美元。FPGA 高性能、低能耗以及可硬件編程的特點使其適用范圍得以擴大。據Synergy Research Group數據,2016年底超大規模提供商運營的大型數據中心的數量已突破300個,預計到2018年大型數據中心將超過400個。數據中心的快速發展必然拉動FPGA市場增長,我們預計用于數據中心的FPGA市場規模在2020年將達到20億美元。

數據中心“瑜亮之爭”:既有GPU,還需FPGA?由于FPGA是硬件語言編程,需要耗費芯片設計工程師資源做上層軟件算法的底層硬件的“影射”,加之目前性能、成本上綜合來看還是GPU更好,所以GPU是目前數據中心主流。但未來FPGA在數據中心業務中前景光明,原因有兩點:第一,云巨頭企業本質上希望其算法優化從硬件底層起就可實現,而并非完全受控于英偉達GPU的編譯和運行性能,為未來底層硬件的自身完全定制化(做自己的ASIC)做準備,所以部分云廠商愿意面向未來,在FPGA開發上投入成本;第二,FPGA功耗特性較GPU好很多,數據中心業務運算量巨大,未來必須考慮功耗問題,如下表所示,各型號FPGA功耗比都優于GPU。在算法逐步穩定以后,針對數據中心不同應用場景,FPGA的萬能變形優勢會逐步體現。

3.4 生態格局:兩公司壟斷,巨頭并購凸顯云端AI有效補充地位
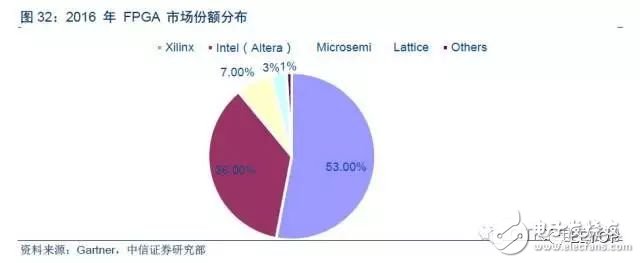
Altera與Xilinx兩公司壟斷FPGA市場。目前全球 FPGA 市場主要被 Altera 和 Xilinx瓜分,合計占有近90%的市場份額,合計專利達到 6000 多項,剩余份額被 Lattice 和Microsemi 兩家占據,合計共有超過 3000 項專利。技術專利的限制和漫長的開發周期使得 FPGA行業形成了很高的壁壘,這也進一步鞏固了 Altera 和 Xilinx 兩家公司的優勢地位和盈利水平。
Intel收購Altera,看好FPGA在未來數據中心的核心價值。2014年6月,微軟對外公布其針對數據處理的研發項目ProjectCatapult,研究結果顯示,將FPGA應用于Intel服務器,后者性能可以提升10倍,處理效率提升30%以上,能耗也顯著降低。2015年6月,Intel以167億美元收購FPGA龍頭公司Altera。Altera對于Intel的價值,核心在于數據中心業務。長久以來,Intel一直在PC、服務器、存儲市場以及數據中心領域占據絕對優勢地位。2017年一季度Intel數據中心業務收入同比增長6%至42億美元,二季度收入同比增長9%至44億美元,增長勢頭強勁。Altera FPGA技術結合IntelCPU制造技術,能夠將CPU的復雜數據處理能力與FPGA的數據并行處理能力結合,未來在數據中心應用領域顯現出強強聯合的優勢,構建未來云端人工智能的堅實基礎。
互聯網巨頭云端積極部署包含FPGA的數據中心,未來可期。由于FPGA在數據中心的獨特優勢,亞馬遜、微軟等企業在數據中心均紛紛部署FPGA。國內,騰訊云在年初部署了首個FPGA云服務器。2017年7月,百度云也宣布在其公有云服務器中部署基于賽靈思FPGA的應用加速服務。國內外主流云服務企業紛紛把目光聚焦在了FPGA上,這顯然不是巧合,這說明整個云服務行業似乎已經對FPGA在高性能計算上的重要性上達成了一致,FPGA在云端特別是底層的數據中心業務前景可期。

云端AI芯片未來:各自進化,走向融合,生態定義未來
云端不同的AI芯片在向彼此學習和進化。一方面,以英偉達為代表的GPU從通用到精進,不斷優化其GPU架構,使其針對人工智能算法進行優化,向更加專業化的人工智能領域擴展。另一方面,以谷歌TPU為代表的云端ASIC,為了滿足靈活性和通用性,也設計了眾多指令集同時支持訓練和推理,未來有望實現從閉環到開環的拓展。谷歌CEO在2017年5月的開發者大會上表示,谷歌將免費開放 1000 臺 Cloud TPU 供開發者和研究人員使用。相信隨著TensorFlow的框架完善、谷歌TPU自身的架構優化、靈活性加強與通用性的完善,我們預計未來TPU芯片也會從谷歌內部使用改為外供給其他云端服務器廠商。
云端有望形成“CPU+GPU/TPU+FPGA”的多芯片融合態勢。CPU繼續作為服務器的控制核心,GPU和ASIC(TPU等)將成為人工智能云端的運算主力,FPGA在延時要求高的計算/通信密集型任務中作為有效補充,未來有望形成CPU+GPU/TPU+FPGA多芯片融合共存的發展態勢。云計算巨頭紛紛推出多芯片融合的云端平臺。我們觀察到,2017年微軟在其最新上線的Azure云平臺中部署FPGA,配合原有的英特爾 CPU 和英偉達Tesla K80 GPU,實現性能的最大化提升。2017年3月騰訊云宣布,已形成包含CPU+GPU+FPGA全矩陣AI基礎設施計算平臺。

生態完善度或決定AI芯片市場未來
上層生態完善度或將決定AI芯片市場未來。完善的開源生態幫助AI核心芯片擁有更強的用戶粘性,幫助保持市場空間。或將決定AI芯片市場未來。AI芯片生態主要包括AI開源平臺支持與開發環境支持兩種生態。
目前開源平臺眾多,江湖未一統。AI開源平臺是一個深度學習的工具箱,用戶可以通過此開放平臺,基于底層計算芯片運行其算法系統。目前AI開發人員主要是利用開源平臺進行算法優化,因此AI硬件只有具備支持主流開源平臺的特性,才能形成穩定的客戶群體,牢牢占據市場空間。各大科技公司為了占據生態優勢也陸續推出各自的開源平臺系統,之前較流行的兩大開源平臺是Tensorflow與Caffe,近來Caffe2和mxnet也逐步興起,江湖尚未一統。對AI芯片廠商而言,目前需要選擇開源平臺進行支持。
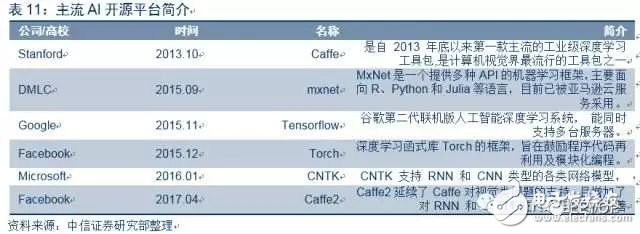
開源平臺生態支持方面,GPU相對完善,FPGA與ASIC加速跟進。以英偉達GPU為例,其支持包括Tensorflow,Caffe,Caffe2,CNTK,Torch等幾乎所有的開源平臺,完善的生態優勢使得GPU目前具備極強競爭力。FPGA與ASIC相關廠商也紛紛注意到生態的重要性,陸續推出支持主流開源平臺的產品。2016年,谷歌發布的TPU2代支持其自家的Tensorflow框架。2017年3月,Xilinx推出基于FPGA的reVISION堆棧解決方案,支持Caffe框架,并計劃未來拓展到更多的框架比如TensorFlow等框架上。開源平臺是支撐相關開發的基礎,目前尚處于群雄逐鹿階段。未來平臺生態之爭將是各家AI芯片能否占據市場的一大關鍵點。AI芯片廠商都會盡可能支持盡可能多的主流平臺,但相應的,也會帶來更多的開發任務量,需要折衷考慮。
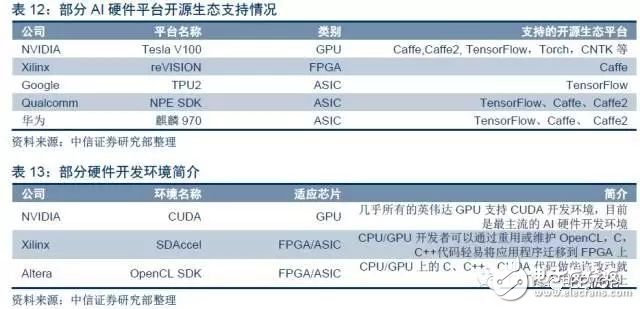
在AI硬件開發環境方面,同樣是GPU占據優勢,FPGA廠商加速完善。AI硬件開發環境是指專門針對AI硬件推出的適應于硬件計算的開發環境,用戶能利用如C,C++等軟件語言更方便的基于AI芯片進行頂層應用開發,并且能起到硬件加速的效果。英偉達推出的CUDA是目前最流行的AI硬件開發環境,幾乎所有英偉達主流GPU都支持CUDA開發。FPGA方面,為了減少FPGA設計的復雜度,Altera推出了 OpenCL SDK開發環境,Xilinx推出了SDAccel開發環境,這兩種FPGA開發環境都大大減輕開發者利用FPGA開發的難度。但目前基于FPGA的開發環境開發靈活度與推廣度依然不如CUDA。此外,由于ASIC直接采用底層硬件語言開發,目前不能用C語言等軟件語言,因此不存在開發環境問題。

未來有望在統一的軟件框架下,實現各類芯片在云端的融合共存。我們判斷各種芯片在云端將競爭并長期共存,云端上層會提供統一的軟件平臺對各類芯片進行支持。換句話說,上層的開發者未來不需要關心底層的硬件是哪種,可以使用統一的、支持各類底層硬件的開源平臺進行開發。云端具體采用哪種芯片架構,將根據云端實際應用需求確定。通過CPU+GPU/TPU+FPGA(可選)的靈活配置,更好地滿足和實現各種應用場景下不斷升級更新的AI算法的需求,使云端人工智能保持長期的靈活性。未來主流框架可能不止一種,類似TensorFlow、Caffe2等都有可能成為主流的Frame框架。
終端場景:按需求逐步落地,未來集成是趨勢
AI“下沉”終端,芯片負責推斷
云端受限于延時和安全性,催生AI向終端下沉。云端AI應用主要依靠網絡將云端計算結果與終端執行結果數據和增量環境參數進行交換。這個過程存在兩個問題:第一,使用網絡傳輸數據到云端會產生延遲,很可能數據計算的結果會需要等待數秒甚至數十秒才能傳回終端;第二,使用網絡傳送數據,傳輸過程中數據有被劫持的風險。因此,在某些對延遲和安全性要求較高的場景就有了將AI下沉到終端的需求。

下沉到終端的AI主要是“推斷”部分。由于模型更新快,計算更為復雜,且基于大數據,“訓練”一般在云端進行。由于數據和算力限制,未來在終端場景下,處理器主要負責執行人工智能的“推斷”過程。“推斷”下沉終端優勢在于實時性,可以在終端進行的操作不需要回傳云端處理,更有效滿足AI運算的實時性需求場景。終端可定期從云端下載訓練好的參數用于推斷參數更新,同時可選擇上傳云端需要的“訓練”信息。通俗來說,未來終端人工智能“大腦”的進化仍在云端進行。
需求決定硬件,場景逐漸落地
采用硬件實現終端人工智能是必然。理論上,智能終端利用原有CPU大腦,運行純軟件的AI算法,也可實現相關應用。但實時性要求高的場景(如安防、輔助駕駛等),對“最差情況下的最大延時”容忍度很低,如果只用CPU運算不能滿足實時性要求,必須有專屬硬件加速;而在手機、音箱、AR/VR眼鏡、機器人等使用電池、對功耗敏感的終端場景,采用純軟件運算功耗很大,不能滿足用戶對功耗的苛刻要求,同樣需要采用專屬芯片加速。
終端AI推斷需要硬件支持的需求場景有三種:(1)低延時;(2)低功耗;(3)高算力。按照需求落地先后順序,我們判斷AI芯片落地的終端子行業分別是:(1)智能安防;(2)輔助駕駛;(3)手機/音箱/無人機/機器人等其他消費終端。三個領域對終端AI硬件的要求各有側重:(1)智能安防、智能駕駛由于視頻信號的數據量較大,對數據流計算速度要求較高;(2)智能駕駛除計算能力外對硬件的穩定性和突發狀況處理速度要求較高;(3)智能手機、音箱、AR/VR終端受限于電池容量,對低功耗的要求更高些。下面我們逐個分析幾種AI+場景。

終端落地之AI+安防:GPU和FPGA先發落地,未來主控集成ASIC
1.1 智慧安防空間:AI產品持續滲透,長期千億市場空間
從“看得見”到“看得清”到“看得懂”,智能大數據分析需求迫切,AI+安防趨勢明顯。高清技術日益進步,圖像分辨率從D1到720P、1080P再到4K逐步進階,視頻監控設備持續高清化升級換代。根據IHS 數據,2013-2016年我國高清攝像機占比由13%增長至59%,首次超過模擬攝像機,實現了視頻監控從“看得見”到“看得清”的轉變,滿足智能化基礎需求。攝像頭高清化產生海量數據,傳統的人工查看方式已不滿足日益增長的安防需求。同時,安防領域每年產生大量非結構化數據,將海量非結構化數據結構化后進行智能處理能極大提高追蹤效率,人工智能的引入能滿足從事后追查到事前防范的安防根本需求。安防領域在實現高清化網絡化升級后,急切需要人工智能技術對海量數據進行處理,這些都促使攝像頭目前開始向“看得懂”進化,智能安防趨勢明顯。

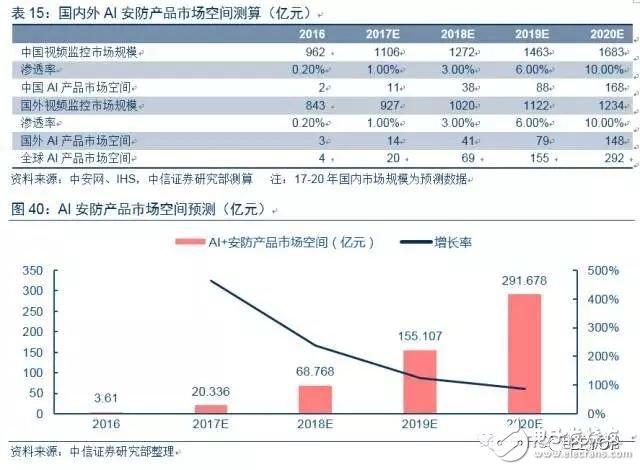
智慧安防產品首先在政府市場落地,長期千億市場空間。(1)短期而言:由于AI產品單價較高,且適用于處理遠距離的大數據,因此我們認為短期的增量空間主要看政府中的公安、交通等部門。假設國內/國外視頻監控行業增速分別為15%/10%,至2020年國內外視頻監控市場規模分別達1683/1234億元,保守估計,若AI產品滲透率提升至10%,則國內/國外AI產品市場空間分別為168/148億元。(2)長期來看:隨著性價比更高的芯片解決方推出,海思等主控廠商必然推出包含AI專屬TPU的IPC主控產品,以海康為首的安防廠商也必然研發推出適合自身的AI+芯片終端解決方案,AI產品單價將逐步回歸理性,智慧產品的滲透范圍有望快速滲透延伸至其他領域。未來AI產品滲透率若提升至35%,則全球AI產品市場空間將突破千億元。
1.2 現有生態:GPU是目前AI+安防方案主流,行業巨頭與英偉達攜手
“AI+安防”方案兩種:前端方案是未來趨勢,中后端AI方案是目前主流。對智能安防而言,目前有前端和中后端兩種解決方案。前端方案是AI攝像頭方案,即將AI芯片集成至攝像頭中,實現視頻采集智能化;中后端方案則是利用普通攝像機采集視頻信息后傳輸到中后端,在數據存儲前利用插入GPU等板卡的智能服務器進行匯總分析。由于中后端方案不需要更換攝像頭、可同時處理多路數據、部署成本相對較低,算法升級、運維方便,短期內中后端方案普及速更快。長期來看,海思等攝像頭主控芯片廠商必然在芯片內部集成用于AI計算的專屬硬件模塊,大規模應用后實現成本會急劇降低,前端(智能攝像頭)方案有望成為未來智能安防主流。目前無論是前端還是中后端解決方案,海康、大華等公司都采用英偉達GPU(Jetson TX1產品)實現,且以中后端AI方案為主。

安防巨頭緊密攜手英偉達,布局基于GPU的智能設備產品。目前海康、大華兩大安防巨頭的AI算法和相關產品都基于英偉達的GPU實現。 2016年,海康威視推出從前端到后端全系列的AI產品,發布基于英偉達GPU和深度學習技術“深眸”攝像機、“超腦”NVR、“臉譜”人臉分析服務器等多款AI系列產品。大華股份2016年第三季度成立AI研究院,2017年3月聯合英偉達發布多款“睿智”系列前端和后端智能設備。

海康威視:首提安防AI+,引領安防智能化發展。海康威視自2006年開始智能分析技術研發,2013年布局深度學習。憑借多年深度學習研究積累以及高達9000余人的業內最大研發團隊,公司在全球包括人臉識別、車輛識別、文字識別在內的多項圖像檢測比賽中取得第一。2015年公司率先推出AI 中心產品“獵鷹”、“刀鋒”智能服務器,2016年公司在安博會首提“安防AI+”概念,并與英偉達和Movidius達成合作,陸續推出基于GPU/VPU和深度學習技術的“深眸”、“超腦”、“神捕”、“臉譜”系列 AI 前后端產品,并融入相關解決方案。公司AI產品目前已應用到南昌“天網項目二期”、“一帶一路”峰會安保等重大項目中,有望引領安防智能化發展。
大華股份:緊隨布局人工智能,AI產品加速落地。大華從2015年開始人工智能研究,在深度學習基礎上研發出人臉識別、視頻結構化、異常行為分析、高密度人群分析等智能技術。16年大華在向國際權威的人臉識別公開測試庫LFW 提交測試結果,Dahua-FaceImage人臉識別準確率為 99.78%,保持世界第一水平。同期公司依托在CPU、DSP、GPU和FGPA等芯片平臺上多年積累的軟硬件研發能力,研發出包括前后端人臉識別、卡口電警、雙目立體視覺、多目全景拼接產品在內的一系列智能化產品。17年公司聯合英偉達發布多款“睿智”系列前端和后端智能設備并融入相關平安城市項目解決方案,大幅提高視頻數據利用率,推進大數據在安防領域加速落地。

1.3 未來趨勢:基于GPU成本是痛點,未來集成至IPC主芯片是趨勢
目前基于GPU的智能安防的成本較為昂貴。目前主流的智能安防解決方案多基于英偉達Jetson TX1 GPU芯片,單個芯片成本估算在70~150美元左右,模塊成本在200~300美元。依據配置不同,每個芯片可支持2~4路視頻流,單路實現成本較高。相關調研顯示,海康威視或已獨家壟斷英偉達TX1的GPU芯片供貨。其他安防廠商僅可購買英偉達的TX1模組(即包括芯片、存儲的GPU板),采購成本會更高。基于GPU的智能安防解決方案較為昂貴,目前阻礙了智能安防的滲透率快速提升。

FPGA成當前智能安防降低成本的可能方案。智能安防領域,目前國內公司深鑒科技已和大華股份、東方網力等安防廠商展開合作,推出基于Xilinx FPGA 的DPU產品,可以實現相對于GPU有 1個數量級的能效提升,同樣功耗降低80%。該方案可將AI單路成本控制在20美元以內,較GPU方案便宜。同時,另一家國內公司地平線機器人也嘗試將FPGA方案應用于安防和車載領域。在專用ASIC產品出現之前,FPGA有望成為部分安防場景降成本的有效手段。
ASIC未來將成為安防芯片主流。如前文所述,ASIC形態的AI芯片解決方案具備低成本、低功耗、高算力的優點。由于芯片存在大規模成本邊際效益遞減效應,專用芯片量產后,由AI模塊帶來的每顆芯片和相關存儲成本增加預計在2美元以下,采用ASIC方案的AI攝像頭實現成本將大幅度降低。換句話說,以后可能實現攝像頭在成本增加非常小的情況下就可以轉化成為AI攝像頭。我們預計,和手機芯片集成AI專屬模塊類似,華為海思等攝像頭主控芯片廠商,未來必然會集成適合安防場景的專屬AI模塊至主芯片中;同樣的,以海康為首的安防廠商,為優化自身解決方案,也有望自研或與相關芯片廠商合作開發其專屬的人工智能專用芯片。伴隨著社會對智慧安防能力的需求提升,未來包含AI功能的 ASIC主控芯片或將成為安防主流芯片。
2. 終端落地之AI+汽車:GPU占據主導,ASIC是未來趨勢
2.1 智能駕駛空間,芯片百億市場空間
智能駕駛空間廣闊,ADAS芯片是核心。智能駕駛是集導航、環境感知、控制與決策、交互等多項功能于一體的綜合汽車智能系統,是人工智能落地的重要領域之一。據iiMediaResearch估計,2016年全球智能駕駛汽車市場規模為40.0億美元,預計至2021年增長至70.3億美元,復合增長率11.8%。智能駕駛核心是高級駕駛輔助系統(ADAS),ADAS系統的核心是算法和芯片。根據IHS預測,2020年全球ADAS芯片市場空間將達到248億元,2016至2020年期間復合增長率高達10%。未來人工智能在車載領域具備廣闊的市場空間。

2.2 現有生態:巨頭與技術初創公司均大力布局AI+汽車
英偉達:2016年9月,Nvidia發布針對自動駕駛技術和汽車產品的芯片Xavier,采用自定義的八核CPU 架構,內建全新Volta GPU 架構作為自動駕駛汽車的計算機視覺加速器。Xavier 采用16nm FinFET 工藝,在提升性能的同時降低功耗,Xavier 運算性能達到20TOPS,功耗則只需20 瓦。英偉達在智能汽車領域的客戶包括21家汽車制造商,而且英偉達是其中16家的連接解決方案一級供應商。它在該領域最重要的客戶是特斯拉,英偉達的DRIVEPX 2平臺應用于特斯拉所有車輛的AutoPilot系統中,包括Model 3。
高通:高通作為移動終端處理器的優勢企業,在GMIC 2016上發布智能汽車芯片驍龍 820A。該處理器采用 CPU+GPU 模式,在快速處理數據信息的同時提升地圖的渲染效果,并降低處理器能耗。處理器包括64位Kryo CPU(中央處理器)、Adreno530 GPU(圖形處理器)。
地平線:2016年3月奇點汽車發布會上,國內人工智能公司地平線首次展示了其先進輔助駕駛系統(ADAS)原型系統—雨果平臺。從地平線官方的視頻和圖片資料來看,這套系統可以實時檢測車輛、車道線和行人,檢測效果優于NVDIA于2016年初CES上提供的展示效果。在2017年1月的CES上,地平線又攜手英特爾于全球消費電子展CES共同發布基于BPU架構的最新的高級輔助駕駛系統。在硬件方面,地平線將其BPU架構實現在ASIC上,并集成到雨果平臺上。地平線的第一代人工智能處理器“盤古”已于2017年6月在臺積電流片。產業調研顯示,地平線也是目前唯一在四大汽車市場—美國、德國、日本和中國,與頂級OEMs和Tier1s 建立重要客戶關系的中國初創企業。中國中央電視臺,美國MITTechnology Review等眾多媒體報道了地平線在自動駕駛和人工智能處理器設計方面的進展。
2.3 未來趨勢:專屬ASIC芯片是未來智能汽車市場主流
我們判斷,專屬ASIC芯片是智能汽車市場未來主流。得益于ASIC優良的性能,定制芯片可將車載信息的數據處理速度提升更快,并將能耗維持在相對較低水平,最重要的是,ASIC可以更好的滿足車載應用下重點關心的“最差情況處理”的延時問題。但鑒于其研發周期長且成本高昂,目前車載場景下,主流廠商仍然考慮采用GPU作為主流方案,預計隨著ADAS定制化需求的增加,未來專用芯片將成為主流。
3. 終端落地之AI+消費電子:百花齊放的未來最大應用場景
3.1 智慧產品空間:千億美元市場,AI或引領新一輪消費電子革命
ASIC將成為AI終端之消費電子的必然選擇。在過去的20年,主導消費電子的終端應用從PC切換到智能手機,然而蘋果發布 iPhone 已有十年,全球智能手機滲透率已近飽和。據 Gartner 預測, 2016~2019年PC 出貨將出現負增長,而智能手機的出貨增速僅維持在1~2%。因此從2015年以后,大家開始尋找消費電子行業下一個風口,紛紛開始關注無人機、AR/VR、智能音響等領域。此類智能硬件都可與AI結合,AI處理芯片的加入將加速此類消費電子行業的發展,重點落地在手機、無人機、AR/VR、智能音響、機器人等子領域。其中,手機是目前電子行業最強粘性終端之一,也是驅動行業發展的最重要下游產品。隨著AI芯片的加入,手機有望加速更新,繼功能手機向智能手機的變革之后,再次向智慧手機進化,有望迎來新一波換機潮。
3.2 智慧手機=AI+AR+智能手機:偉大的新一輪強粘性終端革命
人工智能元素使智能手機向智慧手機轉變,ASIC低成本低功耗低面積占據核心優勢。電子行業本身利用強粘性需求所驅動,驅動發展周期約為5到7年。2002年之前由個人電腦驅動,2007年之前由功能手機驅動,2015年之前由智能手機驅動。但2015年以后,包括A客戶推出“玫瑰金”“土豪金”這樣的微創新,都表現了電子行業滲透率達到一定程度之后創新開始變緩。從2015年以后,業界普遍開始尋找電子行業下一個風口,包括無人機、可穿戴AR/VR、智能音響等,但是目前此類智能硬件都不屬于強粘性終端。而只有類似手機每年出貨在15億到20億部這樣巨大量的強粘性終端才能夠支撐電子行業進一步的變革與發展。手機仍將是未來幾年不可替代的強粘性電子終端。目前AI在手機里面主要是輔助處理圖形圖像的識別(比如拍照的快速美顏)以及語音語義的識別等應用場景。但目前此類應用對AI算法處理速度的要求并不高。隨著如AR功能的引入,并隨著光學聲學等傳感器不斷演進,對AI的計算能力需求會迅速增加,因此需要引入AI芯片來增加手機的運算能力。AI硬件芯片的引入或集成將有益于解決手機終端創新不足及目前滲透率過高的問題,未來與手機AR和3D應用的結合,會進一步推動智慧手機AI硬件的發展,從而帶動手機產業鏈的發展。同時手機對功耗要求極低,ASIC低成本低功耗低面積將占據核心優勢。
蘋果:“Bionic神經引擎”助力蘋果迎來新一輪技術革新。蘋果在當地時間9月12日發布了本年度最重量級的產品——iPhone X(iPhone 10)。iPhone X 最引人關注的是其引入了Face ID解鎖功能,手機可通過對人面部識別實現瞬間解鎖。iPhone X集成了眾多傳感器,面部識別采集點達三萬個,采集完的臉部信息由神經網絡進行建模處理。為此,蘋果專門打造了專用神經網絡處理芯片A11“Bionic神經引擎”。該神經引擎使用雙核設計,每秒運算6000億次,面部信息數據都由A11引擎處理,不會送到云端。該芯片旨在將主處理器(CPU)和圖像處理器(GPU)巨大的計算量分開,把面部識別、語音識別等 AI 相關的任務卸載到 AI 專用模塊(ASIC)上處理,以提升 AI 算法效率,并延長電池壽命,并且最新發布的三款手機中所帶有的Siri 語音助手及增強現實(AR)功能都將利用“Bionic神經引擎”進行實時處理。A11 Bionic芯片內部的AI處理器和CPU、GPU等一起,讓新一代iPhone具備了更先進的AI能力,同時進一步降低AI處理任務對電池壽命的影響,AI元素助力蘋果迎來新一輪技術革新。
華為:引入AI芯片,差異化競爭優勢突出。2017年9月2日,在德國柏林舉行的 IFA 2017 展會上,華為正式發布了全球首款移動端 AI 芯片麒麟970,并將運用于即將發布的華為Mate10手機中。這是業內第一次在手機芯片中出現了專門用于進行人工智能方面計算的處理單元,它早于蘋果于9月12日發布的A11 Bionic中的 NeuralEngine。在麒麟 970 芯片的設計過程中,華為與寒武紀進行了深度合作,集成了專門用于神經網絡任務處理的 NPU,并且其面積僅有10×10毫米。相信隨著人工智能的興起,手機芯片中是否集成人工智能處理器,將會成為手機芯片,甚至是智能手機差異化競爭的關鍵點。
高通:即將發布AI移動芯片搶占AI手機高地。高通一直在和Yann LeCun在Facebook AI研究機構的團隊保持合作,共同開發用于實時推理的新型手機芯片。近日消息稱,高通即將發布人工智能專用移動芯片,搶占人工智能手機領域高地。
三星:收購AI系列公司意欲布局手機AI。2016年10月,有消息稱三星準備收購AI助手系統VivLabs公司,VivLabs的創始人也正是蘋果Siri的創造者,這一舉措,也證實了三星意欲布局人工智能手機領域。
3.3 智能音響:GPU目前占據主流,ASIC方案是未來
隨著人工智能以及物聯網的不斷發展,智能家居越來越受到人們的歡迎。目前,亞馬遜、谷歌、蘋果等科技巨頭紛紛開始布局智能家居市場。其中亞馬遜推出智能音箱 Echo,在支持音箱功能的同時,更支持語音搜索、購物、提醒等多項操作。其主要芯片包括德州儀器的 DSP 和集成電源管理 IC,三星的 RAM, SanDisk 的 4GB 閃存和高通的 Wi-Fi、藍牙模塊。國內京東與國內最大語音技術公司科大訊飛聯合開發叮咚音箱,能夠在為用戶提供音箱功能的同時,支持語音控制,并致力于在未來成為智能家居的集中控制中心,音箱主芯片采用全志四核 Cortex-A7CPU,并內置Mali400 GPU,旨在發揮其計算及音頻處理功能。除此之外,國內阿里、騰訊、百度、小米都紛紛推出智能音響產品。雖然目前市面上的智能音響解決方案或者是運用GPU或者是通過云端進行計算。但考慮到成本等因素,未來智能音響中ASIC將是必然方案。
3.4 無人機、VR/AR:ASIC將是必然選擇
英特爾于2016年11月完成對Movidius的收購,Movidius的Myriad 2視覺處理單元擁有相當于第一代產品20倍的超強性能,它專注于圖像處理,是一種領先的視覺處理芯片。該芯片功耗很低,能夠在0.5瓦的超低功耗下提供浮點運算性能,并且使用20納米工藝制造。全球著名的無人機公司大疆在其智能無人機Phantom4以及最新推出的Mavic產品上均采用了Movidius公司的芯片。Movidius的芯片目前廣泛用于VR/AR頭顯,室內導航,360°全景視頻等場景。因為GPU與FPGA的量產成本都相對較高,并且都具有較大的能耗,因此ASIC將成為消費電子龐大藍海的必然選擇。
終端AI未來:成本效能優化,作為協處理器內嵌
1.成本效益優化,終極形態向ASIC進化
GPU和FPGA不能滿足終端大規模、低成本應用需求。目前GPU和FPGA在終端雖然落地較快,但實現成本高、功耗大,不滿足大規模終端應用低功耗、低成本的場景要求。比如在安防領域,海康威視深眸雙目人臉智能攝像機目前方案采用GPU模塊,實現成本估算為幾百元甚至高達千元,大大增加了安防攝像頭成本,阻礙了AI攝像頭的普及速度。如果采用FPGA方案,目前單路攝像頭實現成本也需要百元以上,成本較GPU低但依舊昂貴。
從成本和效能兩個角度考慮,ASIC作為終端AI優勢明顯。同樣以安防攝像頭舉例,如果未來海思等攝像頭主控芯片供應商,未來在主芯片里內嵌入相關AI加速硬件IP,我們預估成本增加極有可能控制在2美元以內,能極大節約智能攝像頭實現成本,加速其應用普及。
未來:進化至ASIC是趨勢,內嵌入主芯片是形態。和云端幾種芯片長期共存不同,我們判斷,隨著AI推斷算法逐步穩定,無論安防、車載、消費電子,終端AI在終端各種場景下,都將最終進化至ASIC,以AI協處理器IP的方式,嵌入融合至現有的各種移動終端主控芯片中。對主控芯片公司而言,集成AI的IP模塊,能夠實現進化、維持長期競爭優勢。產業調研顯示,蘋果、高通、三星、華為、展訊等各大手機終端主芯片廠商都在各自開發專屬自己的人工智能加速ASIC協處理器。此外,ARM作為老牌CPU IP提供商,也在積極開發支持AI相關運算指令集的芯片產品。9月華為發布首款內嵌人工智能專屬處理器的手機主芯片(麒麟970),搭載在十月發布的Mate 10 新機中,便是典型例證,也將成為未來終端人工智能ASIC發展的里程碑式事件。我們判斷,華為隨后同樣會在其安防芯片中內嵌AI相關處理器。終端AI化普及已初現端倪。
2.關注“中華崛起”與“帝國反擊”
“中華崛起”:中國公司在終端專用AI硬件架構領域未落人后。目前國內已有多家優秀的AI芯片創業型公司成立,主要包括寒武紀,地平線機器人,深鑒科技、比特大陸等。2017年8月寒武紀獲得國投創業領投的1億美元融資,并且華為9月發布的首款人工智能手機處理器也搭載寒武紀NPU。深鑒科技成立于2016年,2017年公司獲得包括賽靈思在內的數千萬美元投資,目前深鑒科技推出的專業處理芯片DPU在終端相比GPU性能快80%。2016年3月奇點汽車發布會上,地平線機器人首次展示了基于雨果平臺的先進輔助駕駛系統(ADAS)原型系統,地平線計劃將其專屬ASIC處理器(BPU)集成到雨果平臺之上,預計計算性能將比目前提升 2-3 個數量級,并且未來地平線還將其BPU應用于智慧家居、智慧城市等多個領域。2017年比特大陸最新發布的BM1680專用芯片是其定制化的ASIC AI芯片,適用于CNN/RNN等深度學習網絡模型的預測和訓練計算加速,32位浮點運算性能達到4TFLOPS,其競爭目標是英偉達高端GPU產品。可以看出,國產終端專用AI硬件架構目前處于世界一級梯隊,未來前景廣闊。
“帝國反擊”:英偉達開源DLA阻擊新興ASIC廠商。2017年 5月 GTC 大會英偉達 CEO 黃仁勛宣布,為加速深度學習技術的普及和進步,將開源其 Xavier DLA(深度學習硬件加速器)供所有開發者使用、修改,爭取占據終端生態平臺優勢。我們認為這是重要的標志性事件。標志著英偉達在終端對ASIC技術路徑的認可,以及開始重視對新興廠商的阻擊。傳統 GPU 架構的功耗限制了其在終端市場的應用,為維持其在人工智能硬件的霸主地位,英偉達把自己的ASIC技術路徑和相關硬件代碼開源,來應對ASIC芯片廠商的挑戰。此次開源 Xavier DLA,英偉達就是瞄準嵌入式和 IoT 等終端市場,而這也是包括寒武紀、地平線、深鑒科技、Novomind 等在內的很多 AI 芯片創業公司重點耕耘的領域。英偉達試圖利用硬件的開源共享和自己的良好生態優勢,在終端繼續拓展自己的帝國版圖。我們認為這勢必對新興廠商造成一定程度的沖擊,具體影響尚不明確,但云端巨頭入局終端市場已成必然,新興ASIC廠商將面臨“看誰跑得快”的競爭新局面。

芯片前瞻:類腦,未來的另一種可能
類腦芯片——讓機器用人類的大腦思考
類腦芯片是通過模擬人腦結構、讓機器具備自主感知識別能力的AI方案。目前處理器芯片基本上基于傳統“馮?諾依曼”架構,和人腦處理信息的方式和流程有本質差異。人腦最大的優點除善于自我學習和認知外,消耗的功耗也比計算機低很多,同時能夠維持低功耗下的快速信息處理。類腦芯片可以看做機器對人大腦的模仿。它基于仿生學神經形態工程,借鑒人腦信息處理方式,采用與模擬人腦的新型存儲器件,致力于發展適合實時處理非結構化信息、和人腦功能類似、具備學習能力的超低功耗新型計算芯片。力圖在基本架構上模仿人腦工作原理,使用神經元和突觸的方式替代傳統“馮?諾依曼”架構體系,使芯片能夠進行異步、并行、低速和分布式處理信息數據的能力,同時具備自主感知、識別和學習的能力。
代表是IBM TrueNorth 類腦芯片。目前最具代表性的研究成果是IBMTrueNorth 類腦芯片。TrueNorth基于脈沖神經網絡設計,并且采用了邏輯時鐘為1KHz這樣的低頻率來模擬毫秒級別生物上的脈沖,這也使得TrueNorth功耗很低(70mW)。目前IBM 已經利用 16 顆 TrueNorth 芯片開發出一臺神經元計算機原型,具有一定的實時視頻處理能力。
政府、巨頭大力推動原型研發,尚不具備商用可能。包括美國、日本、德國、英國、瑞士等發達國家已經制定相應的類腦芯片發展戰略,中國的類腦科學研究項目目前也已經正式啟動。各國研究計劃梳理如下表。但由于目前對人腦機理的理解和真正意義上的模擬都仍存在諸多盲區,模擬神經元的存儲元器件(如憶阻器)尚不具備成熟量產能力,再加之目前以深度學習算法為基礎的AI芯片陣營蓬勃發展,我們判斷今后三年類腦芯片尚不具備成熟商用的可能。
除IBM類腦芯片外,我們也梳理了其他幾種新型在研的AI方案供投資人參考。
海外AI重點芯片公司梳理
-
NVIDIA:GPU市場壟斷者,業務逐漸由游戲轉向數據中心
-
Intel:業務中心由PC芯片拓展至數據中心、物聯網等領域
-
Google:利用TPU打造谷歌云核心競爭力
-
Xilinx:FPGA市場領導者,重點發力四大領域
-
Altera:緊隨Xilinx之后的市場巨頭,被Intel收購或迎加速發展
-
FPGA
+關注
關注
1642文章
21918瀏覽量
611864 -
人工智能
+關注
關注
1804文章
48449瀏覽量
244848 -
半導體芯片
+關注
關注
60文章
925瀏覽量
71128
原文標題:群芯逐鹿時代:AI未來,星辰大海——人工智能深度系列研究報告
文章出處:【微信號:eetop-1,微信公眾號:EETOP】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
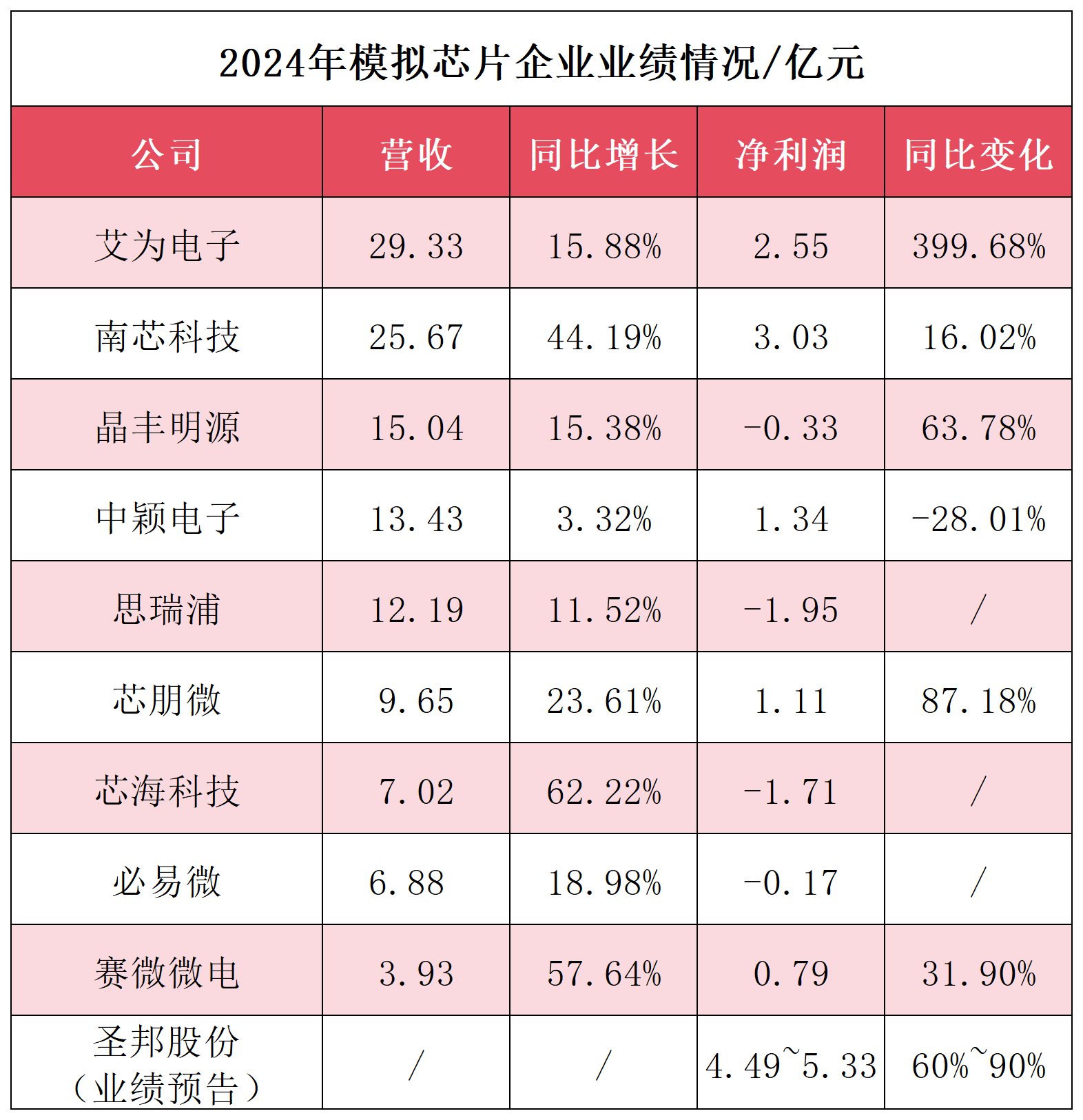
AI終端爆發!模擬芯片企業2024年狂攬市場,最高凈利暴增400%
算力租賃市場爆發,H20遭瘋搶!小心掉坑
蘋果入局,AI眼鏡市場即將爆發,國內芯片產業再臨機遇期
市場爆發!芯片廠商搶灘,AI玩具激發端側AI需求
當我問DeepSeek AI爆發時代的FPGA是否重要?答案是......
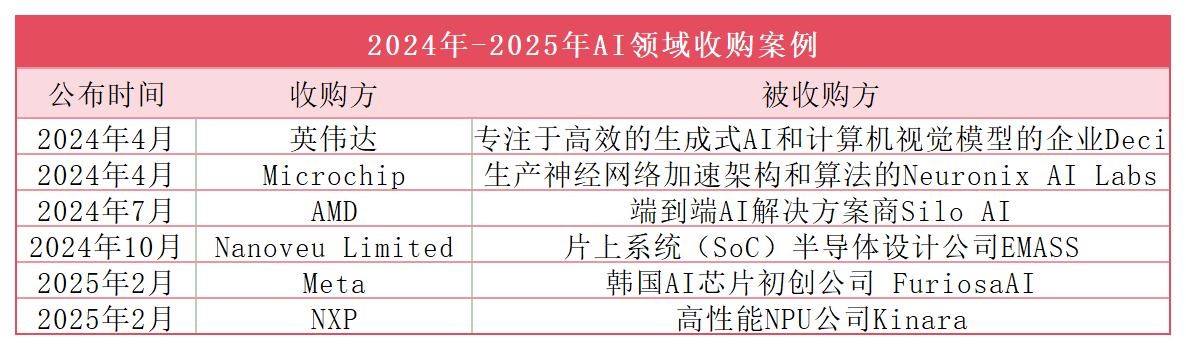
搶灘AI市場!Meta、NXP鎖定目標,2025又一重大并購來襲
AI賦能邊緣網關:開啟智能時代的新藍海
RISC-V,即將進入應用的爆發期
創星未來訪談|時擎科技:端側智能芯片領域的新銳力量

AI爆發期,光互連將給連接器帶來什么機遇?
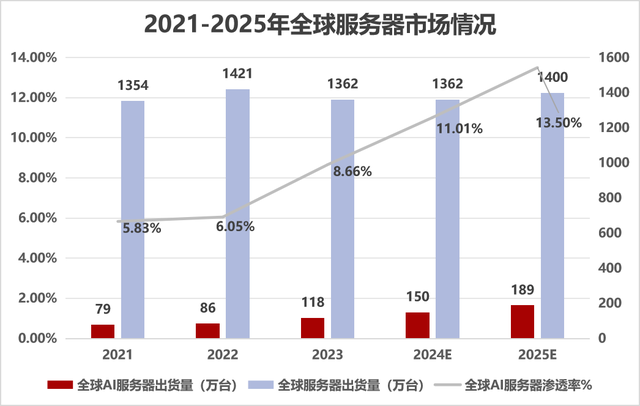
大疆入局eBike千億市場,芯片廠商有哪些機遇?

千億規模市場待導入!UVC-LED或迎增長小高峰
AI硬件產品銷售爆發,CPU、存儲、AI芯片如何創新






 工商網監
工商網監

評論