 光學識別輸入的基本原理是什么
光學識別輸入的基本原理是什么
光學字符識別(Optical Character Recognition,OCR)是一種將不同格式的文檔(如掃描的紙張文檔、PDF文件或數字相機拍攝的圖片)轉換成可編輯和可搜索的數據的技術。OCR技術能夠識別文本、表格、數字等信息,并將它們轉換為電子格式,以便進一步處理和分析。
1. 光學識別輸入的發展歷程
光學識別輸入技術的發展可以追溯到20世紀50年代,當時主要用于郵政編碼的自動識別。隨著計算機技術的發展,OCR技術逐漸成熟,并被廣泛應用于各種領域,如文檔數字化、自動數據錄入等。
2. 光學識別輸入的基本原理
2.1 圖像預處理
圖像預處理是OCR過程的第一步,其目的是提高圖像質量,以便后續的字符識別更加準確。預處理步驟通常包括:
- 去噪 :去除圖像中的噪聲,如掃描過程中產生的斑點或灰塵。
- 二值化 :將圖像轉換為黑白兩色,以便于字符分割。
- 傾斜校正 :如果圖像傾斜,需要進行校正,使文本行水平。
- 去陰影 :去除由于光照不均造成的陰影,提高字符的可識別性。
2.2 字符分割
字符分割是將預處理后的圖像分割成單個字符的過程。這一步非常關鍵,因為字符分割的準確性直接影響到后續的識別效果。字符分割的方法包括:
- 投影法 :通過水平或垂直投影來確定字符的邊界。
- 連通域分析 :識別圖像中的連通區域,并將它們分割成單個字符。
- 基于規則的方法 :根據字符的形狀和大小,使用規則來分割字符。
2.3 字符識別
字符識別是OCR技術的核心,它涉及將分割后的字符圖像與已知字符模板進行匹配,以識別字符。字符識別的方法包括:
- 模板匹配 :將字符圖像與預先定義的字符模板進行比較,找到最佳匹配。
- 特征提取 :提取字符圖像的特征,如邊緣、角點等,然后使用這些特征進行識別。
- 機器學習方法 :使用機器學習算法,如支持向量機(SVM)、卷積神經網絡(CNN)等,來訓練模型并識別字符。
2.4 后處理
后處理是對識別結果進行校正和優化的過程,以提高識別的準確性。后處理步驟包括:
- 語言模型 :使用語言模型來糾正識別過程中的錯誤,如拼寫錯誤。
- 上下文分析 :根據上下文信息來調整識別結果,提高準確性。
- 人工校驗 :在自動化識別后,人工檢查和校正識別結果,確保最終輸出的準確性。
3. 光學識別輸入的應用
光學識別輸入技術在多個領域有著廣泛的應用,包括:
- 文檔數字化 :將紙質文檔轉換為電子格式,便于存儲和檢索。
- 自動數據錄入 :自動識別表格、發票等文檔中的數據,減少人工輸入的工作量。
- 郵政編碼識別 :自動識別郵件上的郵政編碼,提高郵件分揀的效率。
- 車牌識別 :自動識別車輛的車牌號碼,用于交通管理和監控。
4. 光學識別輸入的挑戰
盡管OCR技術已經取得了顯著的進展,但仍面臨一些挑戰,包括:
- 復雜背景 :在復雜背景中識別文本,如帶有水印或圖案的文檔。
- 字體和樣式變化 :不同字體和樣式的文本識別難度較大。
- 低質量圖像 :圖像質量差,如模糊、傾斜或光照不均,會影響識別效果。
- 多語言識別 :同時識別多種語言的文本,需要更復雜的算法和模型。
5. 光學識別輸入的未來趨勢
隨著人工智能和機器學習技術的發展,OCR技術也在不斷進步。未來的發展趨勢可能包括:
- 深度學習 :利用深度學習算法提高字符識別的準確性和魯棒性。
- 多模態學習 :結合圖像、聲音等多種數據源,提高識別的準確性。
- 實時識別 :實現實時的文本識別,如在視頻監控中的應用。
- 跨平臺應用 :OCR技術在移動設備和云平臺上的應用,提高其可訪問性和便利性。
結論
光學識別輸入技術是一種強大的工具,能夠將紙質文檔轉換為電子格式,提高信息處理的效率。隨著技術的不斷進步,OCR技術將在更多領域發揮重要作用,為人們的工作和生活帶來便利。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
計算機
+關注
關注
19文章
7490瀏覽量
87889 -
數字相機
+關注
關注
0文章
10瀏覽量
10693 -
編碼
+關注
關注
6文章
942瀏覽量
54820 -
光學識別
+關注
關注
0文章
11瀏覽量
3125
發布評論請先 登錄
相關推薦
線性電源的基本原理是什么
多路線性電源 AC-DC穩壓電源 低紋波電源 可調線性電源 原理圖PCB目錄多路線性電源 AC-DC穩壓電源 低紋波電源 可調線性電源 原理圖PCB基本原理芯片選型原理圖&3D-PCB具體
發表于 07-30 07:47
PWM模式輸入基本原理實驗
測量PWM波頻率PWM模式輸入基本原理實驗(PWM輸入部分代碼)PWM模式輸入該方式是在STM32輸入捕獲模式基礎上擴展升級的功能,可以測量
發表于 08-16 09:01
無線充電的基本原理是什么
一 、無線充電基本原理無線充電的基本原理就是我們平時常用的開關電源原理,區別在于沒有磁介質耦合,那么我們需要利用磁共振的方式提高耦合效率,具體方法是在發送端和接收端線圈串并聯電容,是發送線圈處理諧振
發表于 09-15 06:01
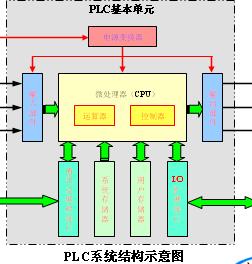
PLC的基本原理及組成
PLC的基本原理及組成.pptPLC的基本原理一、工作方式—— 周期循環掃描二、工作過程——自診斷、輸入采樣、程序掃描、輸出刷新幾個外階段。三、掃描周期 &nbs
發表于 11-20 18:01
?0次下載

指紋識別采集方式及其基本原理的介紹
判斷兩個指紋圖像是否來自同一手指。 指紋識別基本原理 我們可以看到,指紋識別核心的準確、高效的采集指紋分析。指紋識別采集技術的發展大致分為三個方式:
發表于 10-13 11:12
?20次下載
語音識別芯片的基本原理是什么?
。九芯電子NRK330X語音識別芯片那么它的基本原理是什么呢?嵌入式語音識別系統都采用了模式匹配的原理。錄入的語音信號首先經過預處理,包括語音信號的采樣、反混疊濾

光學識別的過程包含哪些
光學識別(Optical Character Recognition,OCR)是一種將圖像中的文字轉換為機器可讀文本的技術。這個過程涉及多個步驟,包括圖像預處理、文本檢測、字符分割、字符識別和后處理
光學識別字符是自動識別技術嗎
光學識別字符(Optical Character Recognition,簡稱OCR)是一種自動識別技術,它能夠將各種類型文檔(如掃描的紙質文檔、PDF文件或數字相機拍攝的圖片)中的文字轉換成可編
光學識別技術的工作原理是什么?
光學識別技術(Optical Character Recognition,簡稱OCR)是一種將圖像中的文字信息轉換成可編輯和可搜索的文本數據的技術。它廣泛應用于文檔掃描、數據錄入、自動識別等領域





 工商網監
工商網監
評論