 京東廣告投放平臺整潔架構演進之路
京東廣告投放平臺整潔架構演進之路
作者:京東零售 趙嘉鐸
前言
從去年開始京東廣告投放系統做了一次以領域驅動設計為思想內核的架構升級,在深入理解DDD思想的同時,我們基于廣告投放業務的本質特征大膽地融入了自己的理解和改造。新架構是從設計思想到落地框架都進行了徹底的革新,涉及內容比較多,因此我們希望通過一系列文章循序漸進地闡述本次架構升級的始末。新架構并不是一日而成的,而是經過了多次架構升級的演進,因此我們將本文作為該系列的第一篇文章,先讓大家通過廣告投放平臺的架構演進歷程來了解新架構的設計初衷。
如前言所述,本文主要聚焦于廣告投放系統歷代代碼架構的演進歷程,我們也不希望本文的篇幅過于冗長,因此對新架構中具體框架及API的說明淺嘗輒止,我們會在本系列接下來的數篇文章中逐步給出愈加具象的描述。
什么是好的代碼架構
大家都清楚在當前的工作中我們所面臨的主要矛盾是“越來越多的多場景化復雜業務需求與有限的研發人力之間的矛盾”。而要解決這一矛盾,就要求我們的系統能做到:設計易拓展、代碼易復用、邏輯易傳承、運行更穩定。這看起來像是一句空喊的口號,但其實每一個特性都有具體的要求:
?設計易拓展
一個好的架構應該能夠實現業務與技術組件的分離,使設計者能夠專注于業務流程,以填空的方式直接套用開箱即用的組件、框架和解決方案,不必進行大量的重復設計;另外好的架構也能夠引導設計者完成最小子問題的正交分解,將設計者從錯綜復雜的上層業務邏輯中拯救出來,逐個擊破,降低需求的復雜度和理解成本。
?代碼易復用
一個好的架構應該有良好的分層,強調正交子模塊的拆分與封裝,同層原子模塊之間避免互相依賴和耦合,讓上層系統能夠輕松實現底層業務邏輯的組合復用,以
?的實現復雜度支撐
?業務復雜度;另外我們的業務邏輯是建立在數據之上的,一個封裝良好的代碼架構在實現業務邏輯復用的同時應該有健全的數據模型維護和共享機制,避免同一個數據對象的重復查詢,并能夠輕松通過批量操作降低系統的I/O負載。
?邏輯易傳承
我們歷史上多次嘗試通過維護文檔的方式來建立業務知識庫,但都以失敗告終了。在這個過程中我們意識到業務功能都是由我們的代碼承接的,它天然具備業務知識庫的功能。因此一個好的代碼架構不僅能夠實現業務功能,而且要承擔起傳遞業務知識的職責:當有新同學加入時,代碼能夠以最直接的方式幫助他快速建立起對整個業務的宏觀認知,而進行具體的需求開發時,又能夠按圖索驥,快速定位改動點并深入了解其業務細節。
?運行更穩定
一個好的代碼架構在面對多場景化的需求時,可以做到場景隔離,避免不同場景的特有邏輯之間互相耦合干擾,出現一個場景需求上線后影響其他業務場景的問題;除此之外,一個好的架構應該通過設計良好的框架和標準模板在有益的程度上對開發者的編碼行為進行約束,把規范框架化,而不是過多的依賴人置和code review來實現規范統一。
架構演進之路
在上一章節列舉出來的特質也是評判一個架構優劣的標準,而我們新的架構方案也正是在一次次為了實現這些目標而采取的摸索中逐漸成型的。在接下來的幾個章節中,我們將從最早期的代碼架構開始,逐代剖析架構演進的歷程,通過這種方式讓大家了解每一次改進背后的設計動機和思路,從而更好的理解新架構的設計思想,也為大家推動架構向下一代演進打好基礎。
第一代:沒有架構的架構
最開始的時候我們的架構如下圖所示,這也是我們目前最常見一種代碼架構。可以看出它的特點就是“簡單”,沒有過多的封裝和設計,平鋪直敘,數據查詢和業務邏輯處理互相交織,是面向數據庫編程的典型案例。這種架構在早期場景單一、需求簡單的階段可以快速實現功能,沒有多余的設計成本,但是隨著業務的發展,系統服務的場景越來越多,這套架構就變得越來越不簡單了。

??
問題主要體現在兩個方面:
1.由于大家習慣“打補丁”式的開發,來了一個業務需求就在現有的流程中增加一個if...else分支,然后直接在新分支內實現業務邏輯。當業務流程積攢的足夠冗長時,就很容易忽視前置流程已經查詢好的數據對象,造成數據重復查詢。同時為了實現邏輯的復用,我們開始把一些常用邏輯封裝為單獨的方法,然后在上層業務流程中直接調用,然而我們在封裝底層方法往往會把數據的獲取邏輯封裝下來,這進一步加劇了數據重復查詢的問題,在有循環調用的場景中這個問題會更加突出。另外這種邏輯的復用方式還會造成數據庫訪問碎片化,我們很難利用批量操作的優勢優化系統性能。在最近剛結束的大促中,我們前期暴露的幾個性能問題基本都是這中模式導致的。
2.除了性能問題之外,由于不同業務場景的邏輯互相交織,代碼分支判斷邏輯缺少統一的規劃,if分支層層嵌套,導致我們的代碼邏輯圈復雜度不斷飆升,本來應該通用的邏輯對不同場景的適配性越來越低。漸漸的,我們發現新增需求的開發越來越“不簡單”了:在試圖復用一段看起來相似的代碼邏輯時會有很多糾結和不盡人意的地方,對代碼執行流程的認知也不似以往那么清晰了,為了防止對舊的業務流程造成影響,我們開始增加更多的if分支,這反過來進一步加劇了情況的惡化,于是我們的代碼中充斥著重復代碼、多達5、6層的嵌套...
為了緩解舊架構中的這些問題,我們引入了上下文機制,嘗試將數據的查詢邏輯與業務流程分離開來,由此引出了第二代基于上下文機制的代碼架構。
第二代:略有改善的上下文機制
上下文主要是為了解決數據重復查詢問題引入的,思路特別樸素,就是把一個完整業務流程中要用到的全部數據提前在方法一開始就查詢好,并做好校驗。查詢出來的數據對象保存到一個上下文對象中,這個上下文對象會貫穿整個業務流程,業務邏輯中需要用得到底層數據實體的時候統一從上下文對象中獲取。
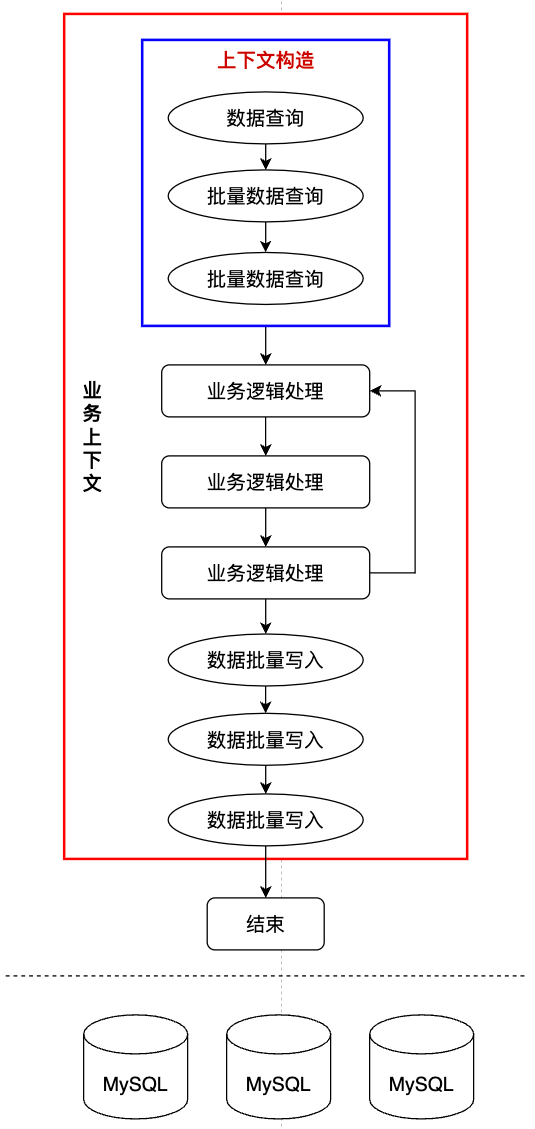
??
所有的數據集中在“上下文構造”步驟中查詢,整個業務流程運行在上下文對象中
通過上下文的引入,我們基本上解決了數據重復查詢的問題,另外我們數據的提前集中查詢也有助于啟發我們主動通過數據庫批量查詢進一步提升系統性能。而且上下文構造的過程其實也是數據校驗的過程,通過上下文的提前構建,我們在一定程度上實現了預校驗的邏輯,從而可以提前發現異常數據,避免寫入臟數據和不必要的數據回滾操作。
上下文的引入其實并不算什么架構上的改進,它主要是解決了數據對象重復查詢的問題,但是也引入了一些新的痛點,首先就是我們的數據模型中數據對象往往比較多且關系復雜,這導致我們的上下文構造邏輯十分冗長。而且同一個業務域內不同的接口使用的上下文對象中屬性有較大重疊,但是也有各自的差異,因此這些上下文對象的構造邏輯又開始出現大量的重復編碼或者混亂的封裝。比如詢量單的新建接口與修改接口對應的上下文中80%的屬性是相同的,這些屬性的查詢和關聯邏輯造成了大量的重復編碼。除了重復編碼問題之外,上下文機制也并沒有從根本上解決多場景下業務流程差異復雜度高的問題。
第三代:數據模型與業務模型的分離
在第二代架構中我們雖然將數據對象的查詢集中到了上下文構造步驟中執行,但是上下文對象的定義是和接口方法綁定的。對外暴露多少服務我們就會定義多少上下文對象,甚至不同的場景也會有各自的上下文構造邏輯,此時系統的數據模型依然隱藏在了具體的業務邏輯中。
在一次次的改進嘗試中,我們逐漸意識到多場景化的業務特性賦予我們一個動態的業務模型(或者說業務規則集),但是我們的數據模型卻是靜態的,數據模型的多場景化程度遠小于業務規則的多場景化程度,即:同一個功能模塊在不同場景下的業務規則存在差異,但卻始終在操作同一套數據模型。有些同學可能會對這一結論產生質疑:在不同的場景下我們對數據對象的構造也是不同的,比如只有快車的單元下才會有關鍵詞,京X的單元上綁定的是應用集,而直投單元上綁定的是流量包等等,這些例子是不是都說明我們的數據模型也在隨業務規則一起動態變化著呢?對于這個問題我們需要“細品”一下:“數據對象屬性值的設置和校驗”到底是屬于業務模型的范疇還是數據模型的范疇?其實我們所說的數據模型指的是實體及實體之間的關系, 不論某個產品線或計劃類型是否會去設置某個子屬性的值,只要我們的數據模型完成了定義,那么在任何場景下數據模型的中實體的定義及實體之間的關系都是不變的,實體只要定義出來,它會一直在那,只是某些場景下其屬性值為null而已。而實體屬性值的設置邏輯則是典型的業務模型的范疇。
在明確了“多場景化的動態業務模型是建立在一個相對靜態的數據模型之上”這一本質之后,為了解決上下文對象構造復雜度高及重復編碼的問題,我們需要做的就是數據模型的分離和下沉,為此我們引入了領域驅動設計思想中的“聚合”概念。在這篇文章里我們不需要教條地引用DDD中關于聚合的定義,它的含義可以通俗的理解為:一組關聯密切且關系明確的實體或值對象的集合,一個聚合通常會支撐著一個功能極其內聚的上層業務模塊。一個聚合中會定義唯一個聚合根對象,聚合根是整個聚合中實體操作的中心,聚合中的全部實體都可以通過聚合根直接或間接的訪問到。聚合根通常并不難確定,比如計劃聚合的聚合根自然就是Campaign實體,我們可以直接通過Campaign聚合根對象直接引用到計劃下的預算、投放時段等子實體信息。
將聚合的概念落地到代碼架構中我們需要做以下升級:
1.根據業務流程設計合理的數據模型,需要注意的是數據模型中的實體并不一定要與底層的庫表一一對應,而是應該從業務本質出發完成實體劃分和定義,另外在模型中也需要體現實體之間的關聯關系。
2.在業務流程和底層數據庫之間增加一個聚合層,在這一層中將第一步設計的數據模型定義為Java對象,其中實體之間的關系則轉化為類與屬性的關系。比如AdGroup領域對象內屬性除了體現ad_group表中定義的字段之外,也定義了單元下的人群、流量包、創意列表等子實體對應的屬性。
3.上層的業務流程對聚合中實體的訪問和修改都是通過聚合根實現的,而要想獲取聚合根則必須通過聚合層暴露出來的Repository接口。
第三步提到的Repository層接口是完全面向數據模型定義的,幾乎與業務無關,通常不會為某個特殊的業務場景定義專用的數據查詢或寫入方法,它定義的都是通用的數據訪問接口,讓上層業務以聲明式的方法獲取所需的聚合根對象(或集合)。Repository的將數據對象的查詢和實體關系的組裝邏輯屏蔽在其接口實現中,上層業務不需要再次執行聚合根下子實體對象的查詢和關聯邏輯。
?
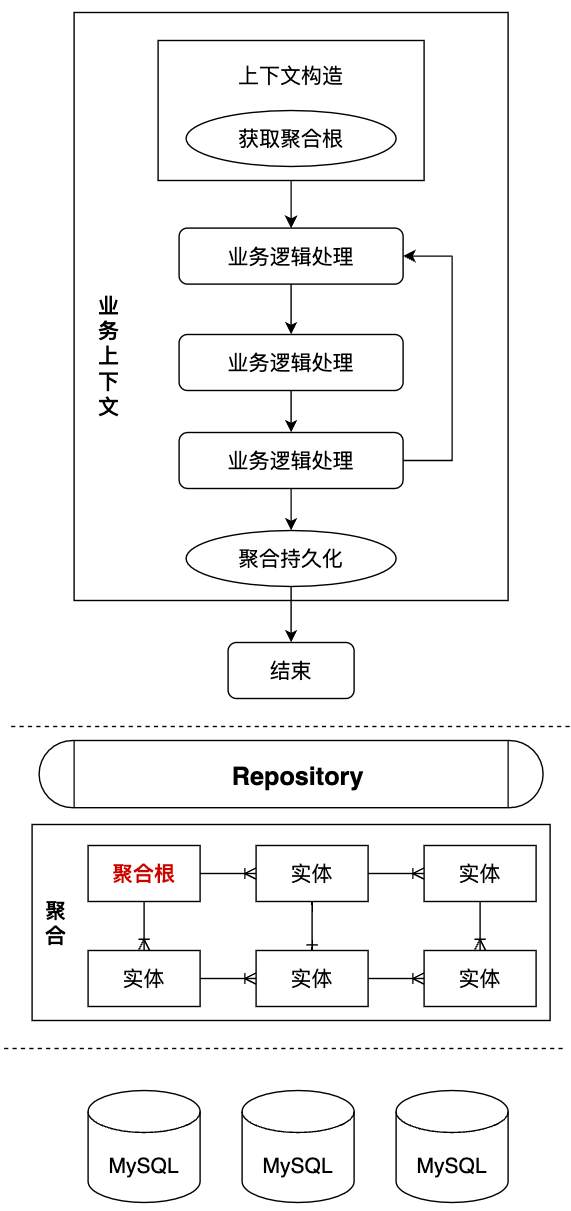
??
引入聚合后上下文的構造和數據的寫入流程得以極大地簡化
?
從上圖可以看出,由于上下文中的很多數據對象都被轉移到了聚合中,之前繁瑣的數據查詢和關聯邏輯被分離下沉到了Repository的實現中,業務模型中不同的服務接口可以直接復用Repository中沉淀的數據查詢和組裝邏輯,上下文構造得以極大的精簡,重復編碼問題也得到了根本性的解決,體現了我們架構目標中“代碼易復用”的要求。
除了更加靈活和優雅的復用數據查詢和組裝邏輯之外,聚合的引入讓我們實現了數據模型和業務模型的分離,聚合層幾乎與業務流程無關,直接體現數據模型的完整全貌。當有新同學加入的時候,可以通過閱讀聚合層代碼獲取最全、最準確的數據模型定義,不再需要從代碼中四處搜集對象關聯關系的蛛絲馬跡,這體現了我們架構目標中“邏輯易傳承”的要求。
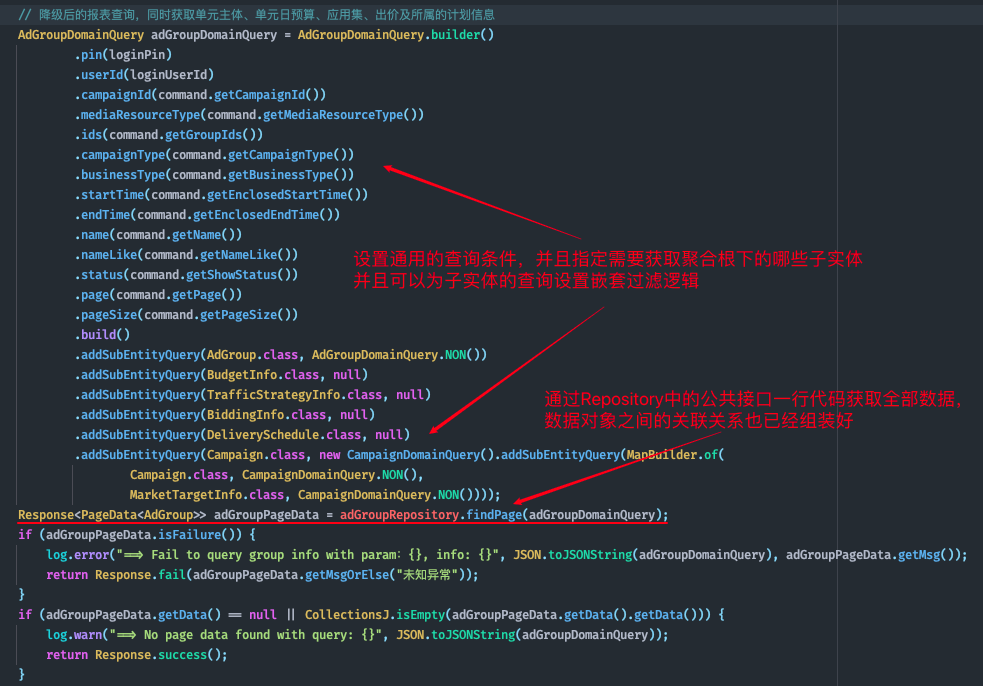
??
RE降級后的補數邏輯一直是一件令人頭痛的事情,聚合的引入可以極大地簡化這一流程
本文主要探討的是我們引入聚合的動機,關于數據模型的設計、Repository接口的實現和使用相關的實戰內容只是點到為止,關于這部分的詳細內容屬于多體系架構中的數據模型管理體系,我們將在該體系的設計中進行深入的探討。 其實就我個人的實踐經驗而言,在實現架構升級所作出的眾多嘗試中,聚合的引入是給我帶來幸福感最強的一項改進,但是我始終沒能找到一種合適的表達方式將我之所感無所保留地傳遞給大家,所言之語總是蒼白,或許聚合引入帶來的收益只有讓大家在實踐中去親身感受了。 另外熟悉領域驅動設計的同學可能已經從上面的設計中嗅到了一絲DDD的味道,但是可能又會覺得沒有那么DDD,關于這個問題限于當前陳述上下文的原因還不好直接給予解答,容筆者在這里賣個關子,在后面的系列文章中我們會詳細闡明這種設計的細節和考量。
第四代:領域能力拆分與編排
通過引入聚合我們基本上解決了數據查詢邏輯復用的問題,但是由于多平臺、多維度和多場景化帶來的業務復雜度的問題卻依然存在。而解決這個問題的基本思路其實祖師爺已經給我們準備好了,那就是組合復用原則。
作為一個典型的2B的平臺,我們的業務特點就是流程冗長復雜,一個業務流程通常由多個流程節點組成,比如單元新建流程,可以分為:基礎信息設置、單元名稱設置、投放周期設置、投放位置設置、定向設置、出價設置、關鍵詞設置等多個節點組成。這些節點再疊加上不同產品線(展位、快車、觸點)、站外不同媒體(頭、騰、百、快、京X)、不同的投放平臺(京準通、流量貨幣化、京易投)以及不同的站點(國內、泰國、印尼、出海)等多維度的業務場景,就使系統具備了
?業務復雜度,其中
?為不同業務細分維度下的場景復雜度,而組合復用原則就是專門為解決這一問題而生的。
組合復用原則強調復雜問題的拆分,拆分出來的最小子問題可以互不干擾地進行獨立的迭代。在此基礎上,上層模塊可以通過對最小子問題的組合編排實現一項完整的業務功能。由于最小子問題之間彼此正交,我們獨立維護各個最小子問題的編碼復雜度就可以降級為
?。基于該思想,我們在新架構中引入了領域能力拆分與編排機制。
領域能力的識別與拆分
在新架構中我們會將一個完整的業務流程正交分解為多個“能力節點”。這里所說的“正交分解”是指拆分出來的各個子模塊之間互不干擾,可以獨立進行迭代。舉個例子來說,在早期大家進行能力梳理的時候,有同學從單元新建流程中拆分出了“出價信息校驗”和“出價設置”兩個能力節點,這其實是不合理的。因為出價信息的校驗和出價屬性的設置并不正交,他們互相依賴,我們應該這兩段邏輯合并到一起,抽象為一個“出價設置”節點。
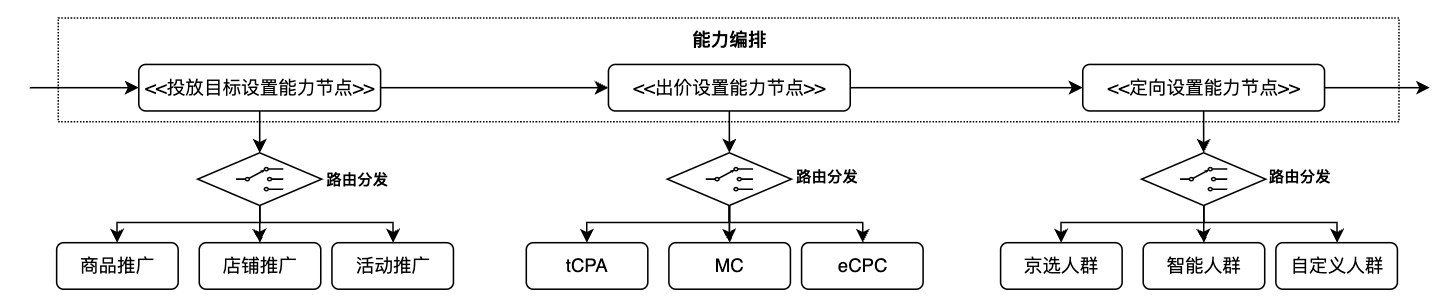
能力節點主要定義了系統中各個原子模塊的功能范圍。一般來說,一個能力節點通常包含一個能力門面和0到多個能力實例。能力門面并不承接具體的業務邏輯,它的作用是對外暴露統一的調用入口及請求轉發,具體的業務邏輯則由能力門面下的能力實例承接。比如出價設置節點下會按照出價類型劃分為:手動出價、tCPA智能出價、MC智能出價、eCPC智能出價幾個具體的領域能力實例,而在人群定向設置節點下則有京選店鋪人群設置、樂高人群設置和自定義人群設置幾個領域能力實例。
能力編排與請求路由
將整個系統劃分為多個獨立的能力節點之后,接下來就需要通過能力編排將這些能力節點串聯到一起組裝成一個完成的服務。如下圖所示,所謂的能力編排就是將業務流程中所需要的原子模塊對應的能力節點串聯起來,定義好他們之間數據傳遞的方式和編排規則。需要注意的是,能力編排操作的是能力節點而不是能力實例,在處理服務請求時,每一個能力節點負責將請求路由到正確的領域能力實例中進行處理。之所以這樣設計是因為我們的業務流程相對穩定,系統對外提供的服務流程中業務節點及節點間的執行順序很少會發生變化,需求迭代往往是對某個能力節點進行橫向的拓展,也就是對具體的領域能力實例進行增刪或者修改。通過能力節點的抽象及路由機制的引入,我們將動態變化著的部分從相對穩定的業務流程中分離出去,從而保障核心流程的穩定性不被頻繁變化著的需求所影響,這一點與我們當時做數據模型與業務模型分離的動機是一致的,本質上都是在隔離變化。
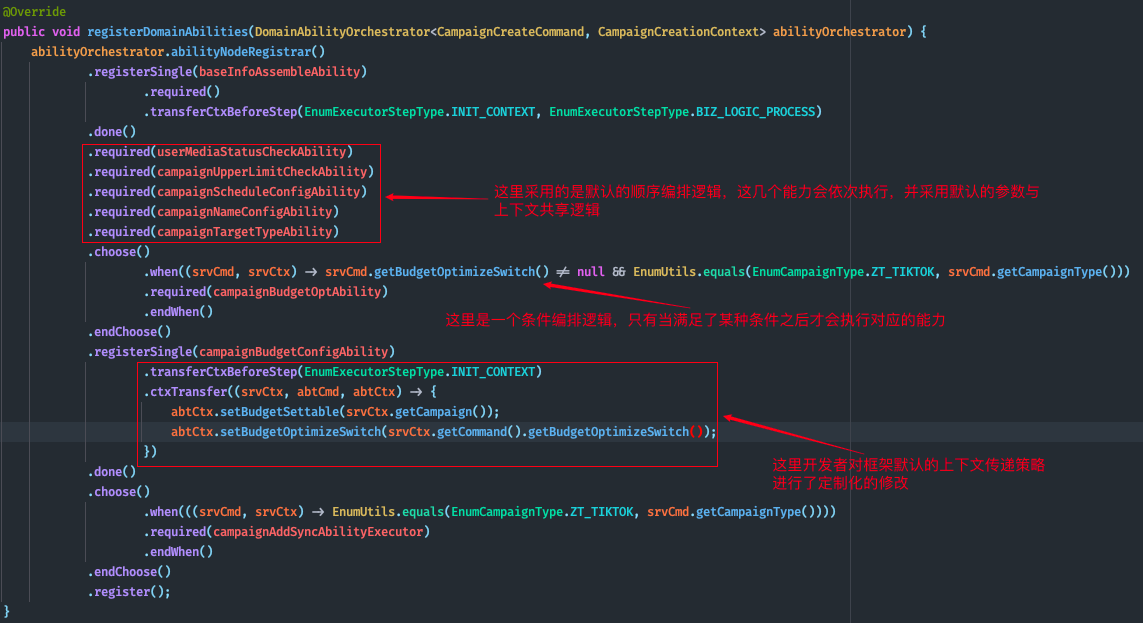
??
一個能力編排示例(點擊放大查看)
除了能力編排框架之外,能力實例的路由機制也是實現復雜度降維的關鍵。如下圖所示,路由機制通過將能力門面及門面下用于承接不同場景下具體業務規則的能力實例打包到一起,同時也將原子業務模塊內的場景復雜度封裝屏蔽在了模塊內部,使上層的業務流程定義只需要關注一次完整的請求需要使用哪些原子業務模塊(也就是能力節點),而無需關注這個節點下具體的能力實例,當請求到來時,處理流程流經相應的能力節點時,將通過當前請求上下文中的參數自動識別業務身份并將請求路由到相應的能力實例上進行處理。
??
能力編排操作的是能力節點而不是領域能力實例,這樣可以讓能力實例更靈活的進行橫向拓展(點擊放大查看)
上文提到了能力編排和路由機制都已經在新工程中提供了框架化的實現,本文主要是為了分享我們架構設計的動機,所以不會介紹這些功能的實現原理和使用方法,對此感興趣的同學可以觀看能力編排框架專門的視頻教程:https://cf.jd.com/pages/viewpage.action?pageId=954674772?
標準的業務執行模版
在第二、三代架構中,系統處理請求時會先執行全部參數的校驗,校驗通過后再將單元新建處理所需的全部數據對象查詢出來。在這個過程中可以充分利用批量查詢接口提升系統性能,同時也會對查詢出來的數據對象進行校驗,如果存在不合法的數據則終止處理流程,如果數據對象查詢一切正常,則執行后續的數據組裝和處理邏輯,最后批量執行數據的持久化。盡管會存在上文分析的一些問題,但是這種模式所帶來的收益依然具備十分重要的意義。
然而在新架構中我們將原先連貫的業務邏輯打散,按照邏輯的內聚性將他們重組到一個能力實例中,然后在領域服務中通過能力編排將這些能力實例組裝成一個完整的業務流程。這雖然貫徹了組合復用的原則,但是如果我們只是簡單地通過順序執行多個能力實例來組裝領域服務,那么由于每個能力內部又依次執行與一小撮業務屬性相關的參數校驗、依賴數據查詢、邏輯處理乃至數據持久化操作,從代碼邏輯的執行流程上看我們又回退到了“數據訪問與邏輯處理互相交織”的第一代架構上。除此之外,雖然服務之間邏輯上互相獨立,但是他們可能會依賴相同的數據對象,比如人群包的綁定與預算調整兩個能力都會依賴AdGroup對象,如果框架只是簡單地串聯執行這兩個能力,那么必然會造成數據的重復查詢。
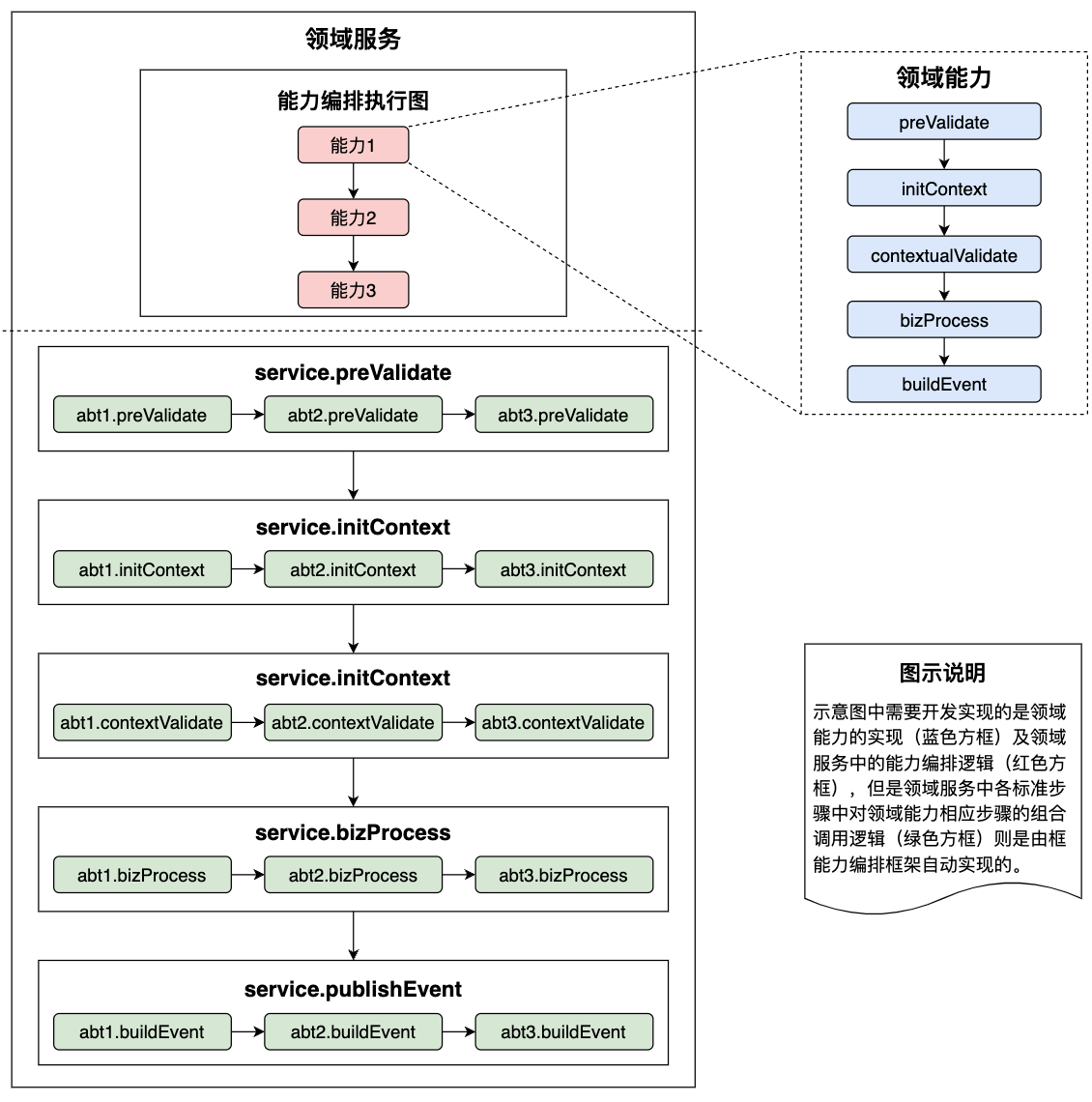
為了解決上述問題,我們引入了標準的業務流程Executor模板,它把業務業務流程抽象為:參數校驗、上下文初始化、上下文校驗、業務邏輯處理、數據持久化、發布事件幾個標準步驟,不論是領域能力的封裝還是領域服務的實現都必須繼承該模板。標準業務執行模板的引入一方面能夠規范開發者的設計和實現,另一方面也將代碼邏輯的串聯執行權從開發者手中轉移到了能力編排框架中,讓框架能夠實現邏輯的自動重組和執行,而開發者專注于業務邏輯并進行填空式開發。而框架在獲取到了代碼邏輯的串聯執行權之后就可以在領域服務的每個標準步驟中按照能力編排執行圖組裝調用的各個能力實例中相應標準步驟,從而將打散到不同能力實例中的業務邏輯次按照標準步驟的類別還原回連貫完整的業務邏輯,如下圖所示:
??
標準業務流程模版的引入讓框架進行業務流程還原成為可能
除了實現業務邏輯按標準步驟自動還原之外,由于標準流程模板對每一個標準步驟方法的執行參數、依賴的上下文及返回值對象都進行了通用化的抽象,能力編排框架也得以在各個能力標準步驟調用之間插入參數及上下文的映射和傳遞邏輯,從而在不同能力之間以及能力與領域服務之間實現數據分發和共享。需要說明的是盡管這些流程都可以采用默認的自動處理規則,開發者也可以通過能力編排框架提供的DSL對默認的串聯執行、數據傳遞、異常處理等規則進行修改。
在我們新架構中,我們通過領域能力拆分將復雜的問題域正交分解為多個互相獨立的最小問題域,讓設計者可以分而治之,逐個擊破,降低了問題的復雜度和設計成本,同時單個能力節點下不同業務場景下的業務邏輯被分離到了不同的領域能力實例中,避免出現不同業務場景互相交織,便于快速梳理業務邏輯,定位改動點,這些都體現了“設計易拓展”的設計目標。
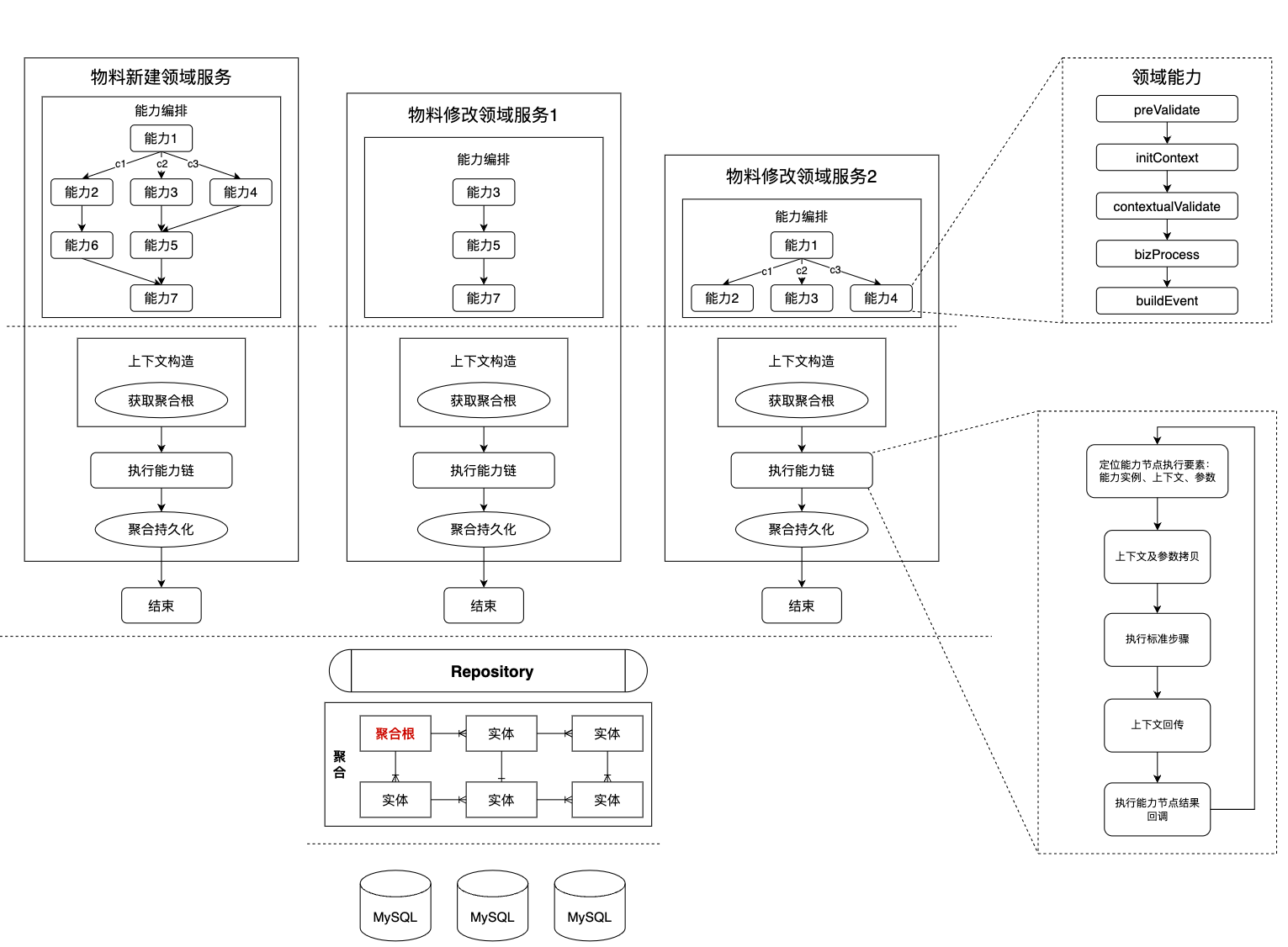
由于拆分出來的各個能力節點彼此正交,內部邏輯十分內聚,因此可以在各自的維度上進行迭代,比如同樣是在單元維度下的出價設置和人群設置能力就分別在出價類型和人群類型這兩個場景維度上各自進行路由,避免了不同場景互相交織帶來的圈復雜度上升問題,也能夠更加靈活在不同的業務場景中實現能力復用。同時由于我們的業務本質上就是對物料的創編,物料新建流程中的能力往往可以直接在物料修改流程中復用。還有一個特殊的場景就是批量物料操作類型的請求,借助能力編排框架提供的循環編排和數據共享機制,我們可以在領域服務的開始先批量完成所需數據的查詢,然后通過循環編排機制循環復用單個請求處理能力中的純內存調用的數據校驗及數據處理邏輯,最后在批量操作領域服務中批量完成聚合根對象集合的寫入,在實現邏輯復用的同時又能保證數據準確性及性能,以上特性都體現了“代碼易復用”的設計目標。
領域能力的編排邏輯提供了一個業務流程的全景視圖,當有新同學加入時,可以迅速通過閱讀能力編排邏輯快速建立起對業務的宏觀認知,再結合在第三代架構中引入的聚合機制,可以讓新同學快速熟悉數據模型與業務流程。同時通過路由機制系統中全部的業務規則打包拆分成數量有限且邊界清晰的能力節點,當需要快速梳理需求點對應業務規則時,可以由粗及細,先確定需求點歸屬的能力節點,然后根據場景定位到具體的能力實例,進而可以從代碼中獲取業務規則,這些特性都體現了“邏輯易傳承”的設計目標。
??
基于能力拆分與編排的代碼架構,最顯著的收益就是同一個能力可以在不同的領域服務中直接復用(點擊放大查看)
總結
以上便是我們為實現新架構所進行的種種嘗試,這些設計是否正確我們也正在通過需求實戰來進行驗證,把他們發出來不是要說服大家認同,而是想通過對架構演進歷程的推演幫助大家更好的理解我們新架構中各項功能的設計動機,從而更快的上手進行開發;另一方面也希望能夠激發大家的思考和討論,哪怕是對上述方案的質疑和批判,一個好的架構一定是在一次次批評聲中改進出來的,我至今還在懷念當初摸索新架構時那些與永亮(我的良師益友,部門內探索中臺化及領域驅動設計思想的第一人)爭論到凌晨2、3點的日子。
審核編輯 黃宇
-
DSL
+關注
關注
2文章
58瀏覽量
38293 -
數據模型
+關注
關注
0文章
49瀏覽量
10001 -
架構
+關注
關注
1文章
513瀏覽量
25468
發布評論請先 登錄
相關推薦
京東IM工具的架構演進





 工商網監
工商網監
評論