 史無前例,移植V8虛擬機到純血鴻蒙系統
史無前例,移植V8虛擬機到純血鴻蒙系統
作者:京東科技 于飛躍
一、背景
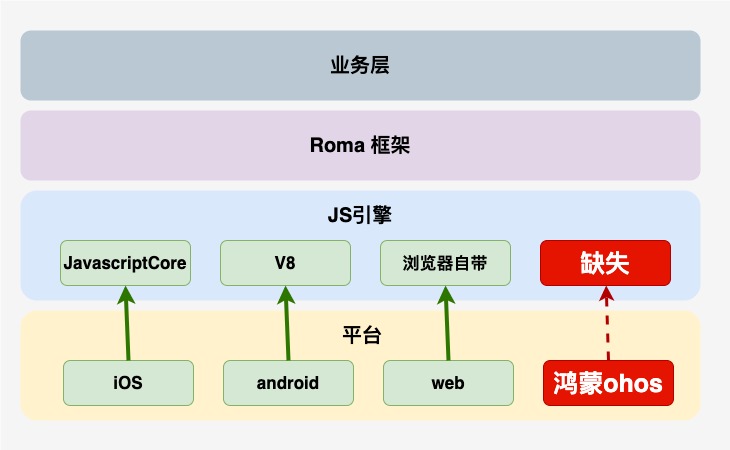
如圖所示,Roma框架是我們自主研發的動態化跨平臺解決方案,已支持iOS,android,web三端。目前在京東金融APP已經有200+頁面,200+樂高樓層使用,為保證基于Roma框架開發的業務可以零成本、無縫運行到鴻蒙系統,需要將Roma框架適配到鴻蒙系統。
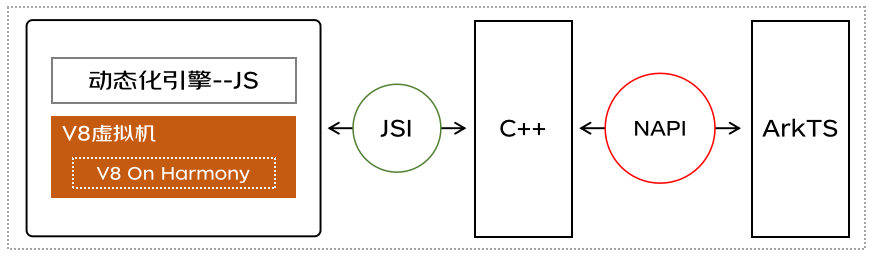
Roma框架是基于JS引擎運行的,在iOS系統使用系統內置的JavascriptCore,在Android系統使用V8,然而,鴻蒙系統卻沒有可以執行Roma框架的JS引擎,因此需要移植一個JS引擎到鴻蒙平臺。
二、JS引擎選型
目前主流的JS引擎有以下這些:
| 引擎名稱 | 應用代表 | 公司 |
|---|---|---|
| V8 | Chrome/Opera/Edge/Node.js/Electron | |
| SpiderMonkey | firefox | Mozilla |
| JavaScriptCore | Safari | Apple |
| Chakra | IE | Microsoft |
| Hermes | React Native | |
| JerryScript/duktape/QuickJS | 小型并且可嵌入的Javascript引擎/主要應用于IOT設備 | - |
其中最流行的是Google開源的V8引擎,除了Chrome等瀏覽器,Node.js也是用的V8引擎。Chrome的市場占有率高達60%,而Node.js是JS后端編程的事實標準。另外,Electron(桌面應用框架)是基于Node.js與Chromium開發桌面應用,也是基于V8的。國內的眾多瀏覽器,其實也都是基于Chromium瀏覽器開發,而Chromium相當于開源版本的Chrome,自然也是基于V8引擎的。甚至連瀏覽器界獨樹一幟的Microsoft也投靠了Chromium陣營。V8引擎使得JS可以應用在Web、APP、桌面端、服務端以及IOT等各個領域。
三、V8引擎的工作原理
V8的主要任務是執行JavaScript代碼,并且能夠處理JavaScript源代碼、即時編譯(JIT)代碼以及執行代碼。v8是一個非常復雜的項目,有超過100萬行C++代碼。
下圖展示了它的基本工作流程:
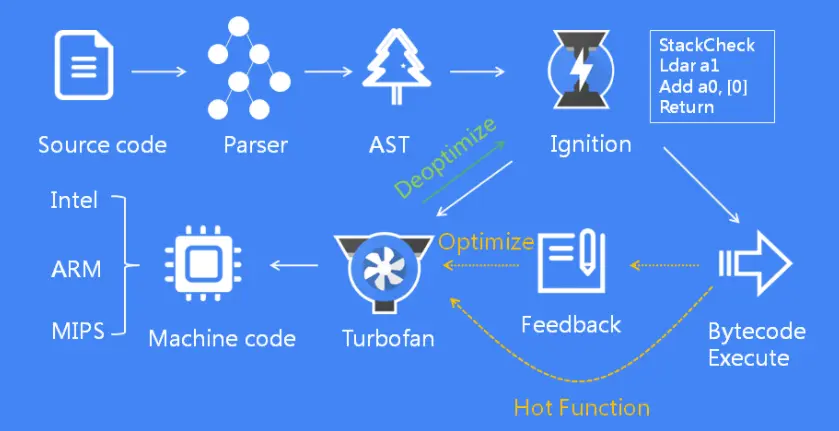
如圖所示,它通過詞法分析、語法分析、字節碼生成與執行、即時編譯與機器碼生成以及垃圾回收等步驟,實現了對JavaScript源代碼的高效執行。此外,V8引擎還通過監控代碼的執行情況,對熱點函數進行自動優化,從而進一步提高了代碼的執行性能。其中Parser(解析器)、Ignition(解釋器)、TurboFan(編譯器)、Orinoco(垃圾回收)是 V8 中四個核心工作模塊,對應的V8源碼目錄如下圖。
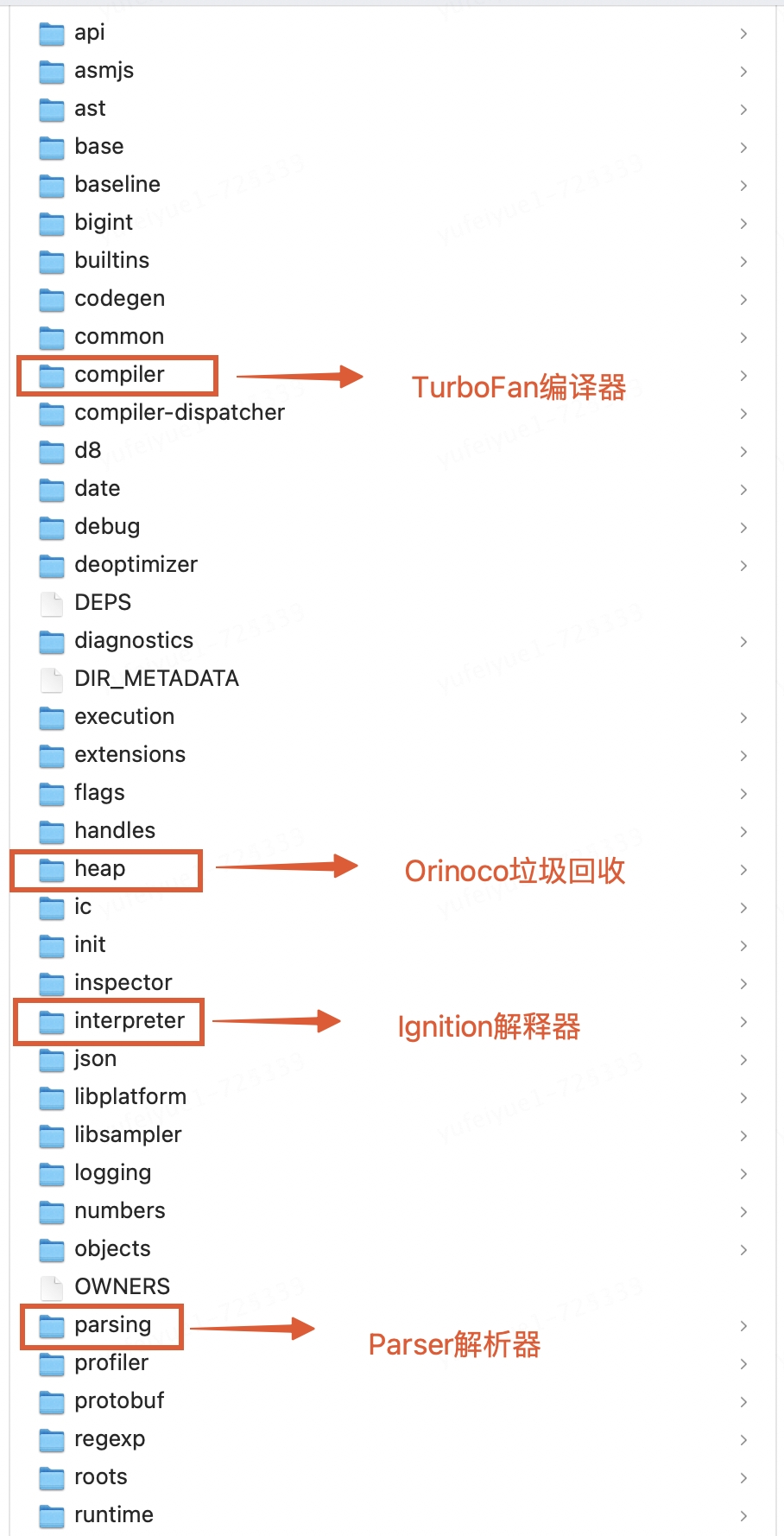
1、Parser:解析器
負責將JavaScript源碼轉換為Abstract Syntax Tree (AST)抽象語法樹,解析過程分為:詞法分析(Lexical Analysis)和語法分析(Syntax Analysis)兩個階段。
1.1、詞法分析
V8 引擎首先會掃描所有的源代碼,進行詞法分析(Tokenizing/Lexing)(詞法分析是通過 Scanner 模塊來完成的)。也稱為分詞,是將字符串形式的代碼轉換為標記(token)序列的過程。這里的token是一個字符串,是構成源代碼的最小單位,類似于英語中單詞,例如,var a = 2;經過詞法分析得到的tokens如下:
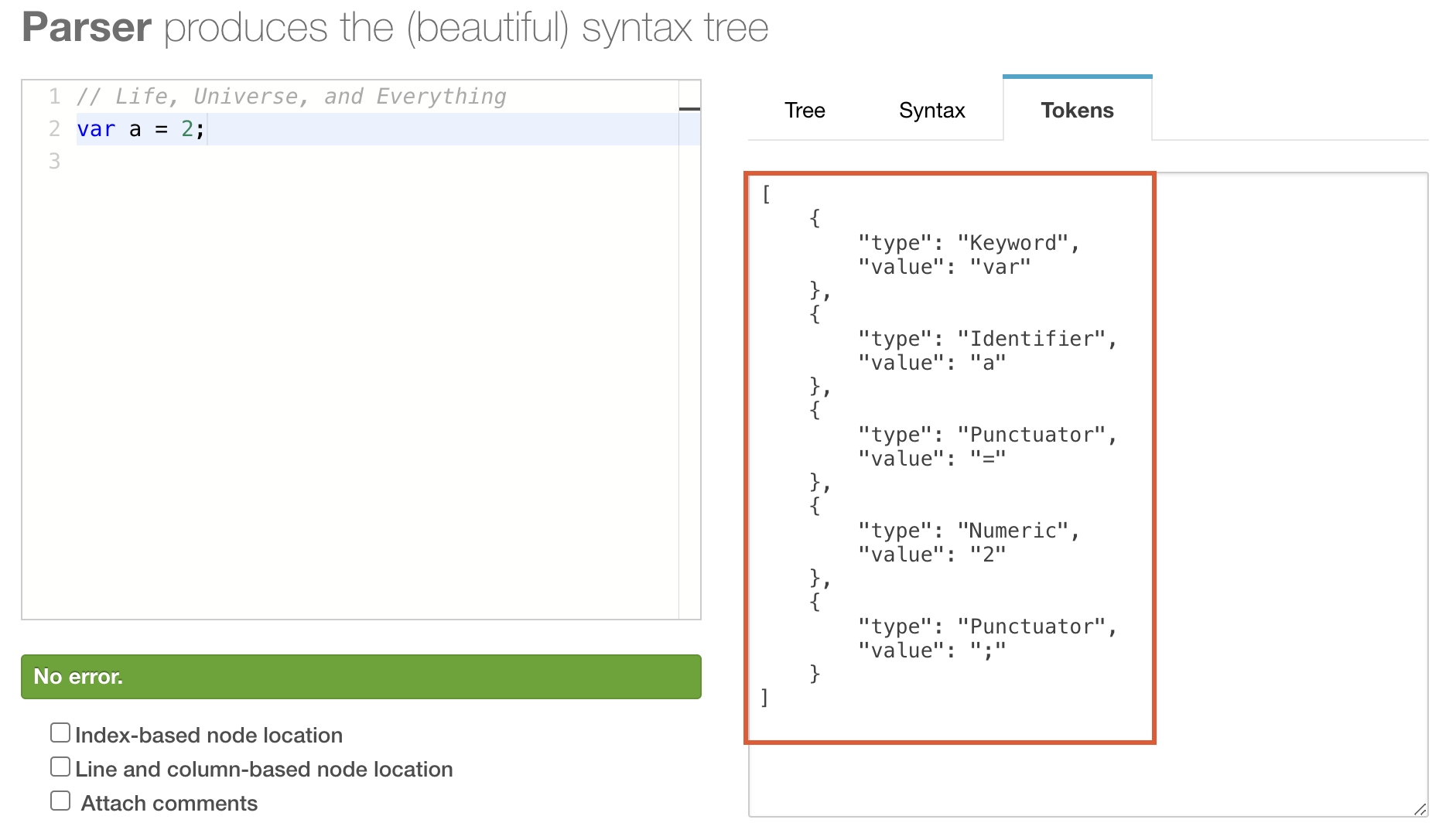
從上圖中可以看到,這句代碼最終被分解出了五個詞法單元:
var 關鍵字
a 標識符
= 運算符
2 數值
;分號
一個可以在線查看Tokens的網站: https://esprima.org/demo/parse.html
1.2、語法分析
語法分析是將詞法分析產生的token按照某種給定的形式文法(這里是JavaScript語言的語法規則)轉換成抽象語法樹(AST)的過程。也就是把單詞組合成句子的過程。這個過程會分析語法錯誤:遇到錯誤的語法會拋出異常。AST是源代碼的語法結構的樹形表示。AST包含了源代碼中的所有語法結構信息,但不包含代碼的執行邏輯。
例如,var a = 2;經過語法分析后生成的AST如下:
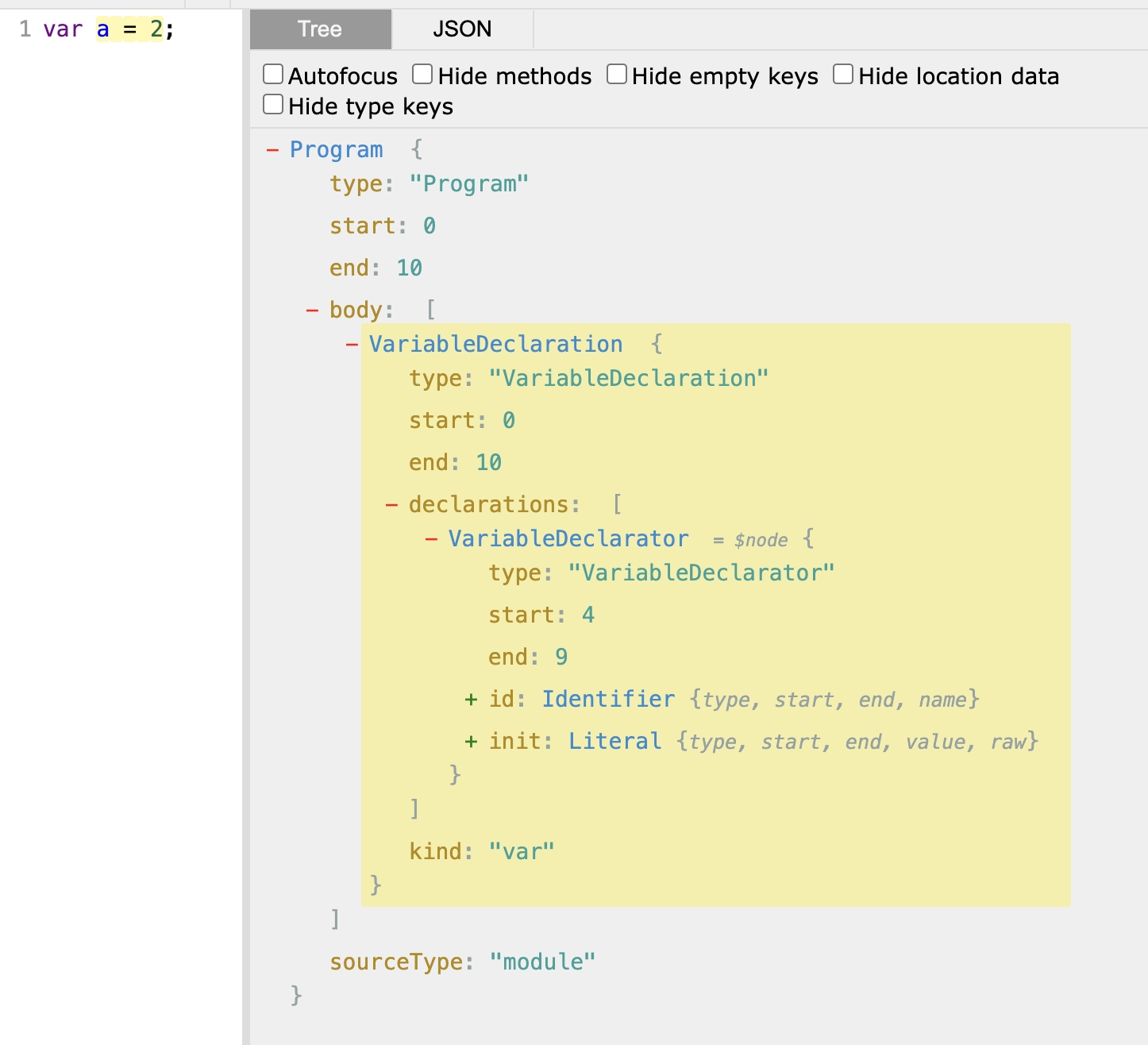
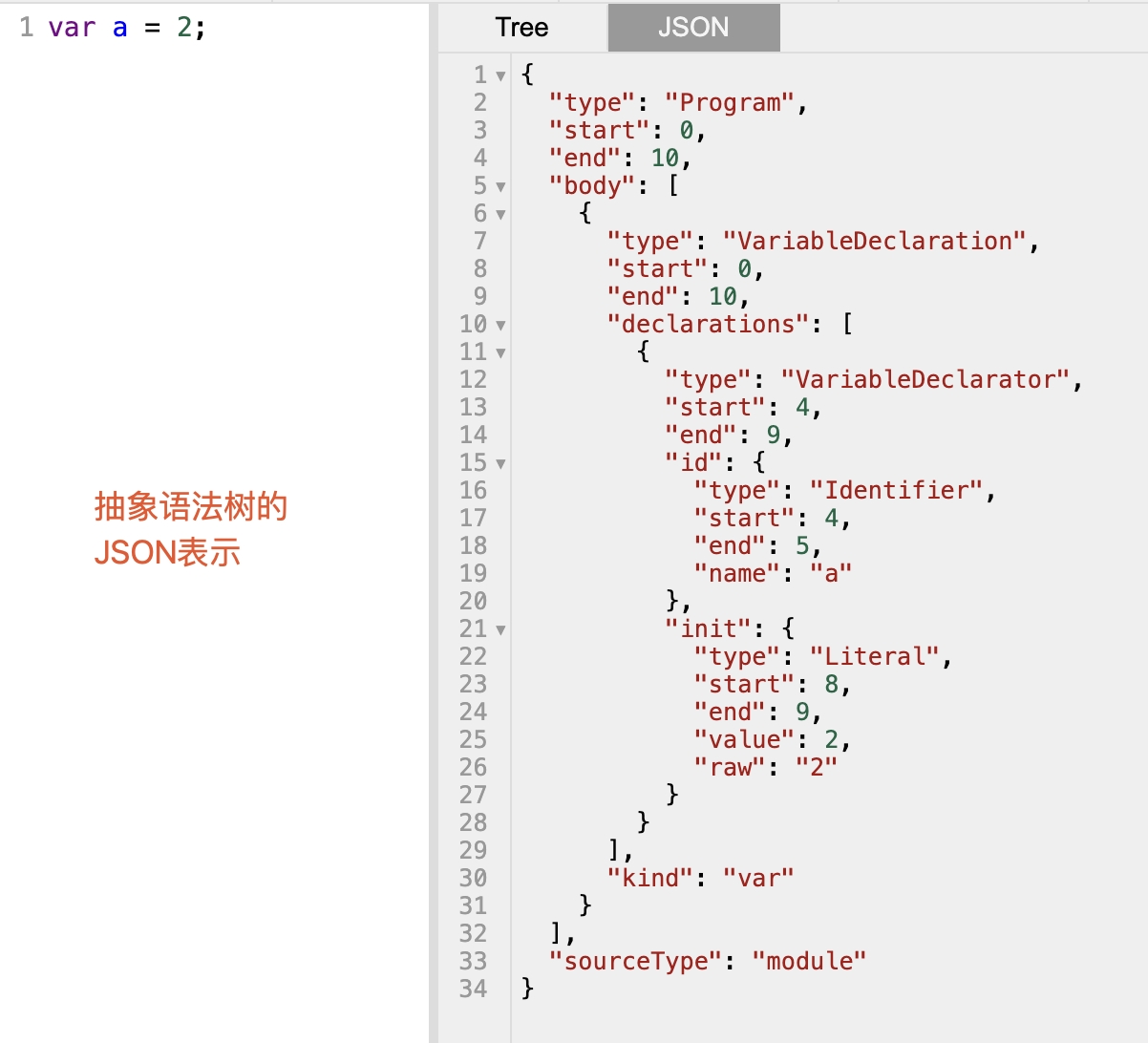
可以看到這段程序的類型是VariableDeclaration,也就是說這段代碼是用來聲明變量的。
一個可以在線查看AST結構的網站:https://astexplorer.net/
2、Ignition:(interpreter)解釋器
負責將AST轉換成字節碼(Bytecode)并逐行解釋執行字節碼,提供快速的啟動和較低的內存使用,同時會標記熱點代碼,收集TurboFan優化編譯所需的信息,比如函數參數的類型。
2.1、什么是字節碼?
字節碼(Bytecode)是一種介于AST和機器碼之間的中間表示形式,它比AST更接近機器碼,它比機器碼更抽象,也更輕量,與特定機器代碼無關,需要解釋器轉譯后才能成為機器碼。字節碼通常不像源碼一樣可以讓人閱讀,而是編碼后的數值常量、引用、指令等構成的序列。
2.2、字節碼的優點
?不針對特定CPU架構
?比原始的高級語言轉換成機器語言更快
?字節碼比機器碼占用內存更小
?利用字節碼,可以實現Compile Once,Run anywhere(一次編譯到處運行)。
早期版本的 V8 ,并沒有生成中間字節碼的過程,而是將所有源碼轉換為了機器代碼。機器代碼雖然執行速度更快,但是占用內存大。
2.3、查看字節碼
Node.js是基于V8引擎實現的,因此node命令提供了很多V8引擎的選項,我們可以通過這些選項,查看V8引擎中各個階段的產物。使用node的--print-bytecode選項,可以打印出Ignition生成的Bytecode。
示例test.js如下
//test.js function add(a, b){ return a + b; } add(1,2); //V8不會編譯沒有被調用的函數,因此需要在最后一行調用add函數
運行下面的node命令,打印出Ignition生成的字節碼。
node --print-bytecode test.js [generated bytecode for function: add (0x29e627015191 )] Bytecode length: 6 Parameter count 3 Register count 0 Frame size 0 OSR urgency: 0 Bytecode age: 0 33 S> 0x29e627015bb8 @ 0 : 0b 04 Ldar a1 41 E> 0x29e627015bba @ 2 : 39 03 00 Add a0, [0] 44 S> 0x29e627015bbd @ 5 : a9 Return Constant pool (size = 0) Handler Table (size = 0) Source Position Table (size = 8) 0x29e627015bc1
控制臺輸出的內容非常多,最后一部分是add函數的Bytecode。
字節碼的詳細信息如下:
?[generated bytecode for function: add (0x29e627015191)]: 這行告訴我們,接下來的字節碼是為 add 函數生成的。0x29e627015191 是這個函數在內存中的地址。
?Bytecode length: 6: 整個字節碼的長度是 6 字節。
?Parameter count 3: 該函數有 3 個參數。包括傳入的 a,b 以及 this。
?Register count 0: 該函數沒有使用任何寄存器。
?Frame size 0: 該函數的幀大小是 0。幀大小是指在調用棧上分配給這個函數的空間大小,用于存儲局部變量、函數參數等。
?OSR urgency: 0: On-Stack Replacement(OSR)優化的緊急程度是 0。OSR 是一種在運行時將解釋執行的函數替換為編譯執行的函數的技術,用于提高性能。
?Bytecode age: 0: 字節碼的年齡是 0。字節碼的年齡是指它被執行的次數,年齡越高,說明這個字節碼被執行的越頻繁,可能會被 V8 引擎優化。
?Ldar a1 表示將寄存器中的值加載到累加器中 ,這行是字節碼的第一條指令
?Add a0, [0] 從 a0 寄存器加載值并且將其與累加器中的值相加,然后將結果再次放入累加器 。
?Return 結束當前函數的執行,并把控制權傳給調用方,將累加器中的值作為返回值
?S> 表示這是一個“Safepoint”指令,V8 引擎可以在執行這條指令時進行垃圾回收等操作。
?E> 表示這是一個“Effect”指令,可能會改變程序的狀態。
?Constant pool (size = 0): 常量池的大小是 0。常量池是用來存儲函數中使用的常量值的。
?Handler Table (size = 0): 異常處理表的大小是 0。異常處理表是用來處理函數中可能出現的異常的。
?Source Position Table (size = 8): 源代碼位置表的大小是 8。源代碼位置表是用來將字節碼指令與源代碼行號關聯起來的,方便調試。
?0x29e627015bc1 : 這行是源代碼位置表的具體內容,顯示了每個字節碼指令對應的源代碼行號和列號。
可以看到,Bytecode某種程度上就是匯編語言,只是它沒有對應特定的CPU,或者說它對應的是虛擬的CPU。這樣的話,生成Bytecode時簡單很多,無需為不同的CPU生產不同的代碼。要知道,V8支持9種不同的CPU,引入一個中間層Bytecode,可以簡化V8的編譯流程,提高可擴展性。如果我們在不同硬件上去生成Bytecode,生成代碼的指令是一樣的.
3、TurboFan:(compiler)編譯器
V8 的優化編譯器也是v8實現即時編譯(JIT)的核心,負責將熱點函數的字節碼編譯成高效的機器碼。
3.1、什么是JIT?
我們需要先了解一下JIT(Just in Time)即時編譯。
在運行C、C++以及Java等程序之前,需要進行編譯,不能直接執行源碼;但對于JavaScript來說,我們可以直接執行源碼(比如:node server.js),它是在運行的時候先編譯再執行,這種方式被稱為即時編譯(Just-in-time compilation),簡稱為JIT。因此,V8也屬于JIT編譯器。
實現JIT編譯器的系統通常會不斷地分析正在執行的代碼,并確定代碼的某些部分,在這些部分中,編譯或重新編譯所獲得的加速將超過編譯該代碼的開銷。 JIT編譯是兩種傳統的機器代碼翻譯方法——提前編譯(AOT)和解釋——的結合,它結合了兩者的優點和缺點。大致來說,JIT編譯將編譯代碼的速度與解釋的靈活性、解釋器的開銷以及額外的編譯開銷(而不僅僅是解釋)結合起來。
除了V8引擎,Java虛擬機、PHP 8也用到了JIT。
3.2、V8引擎的JIT
V8的JIT編譯包括多個階段,從生成字節碼到生成高度優化的機器碼,根據JavaScript代碼的執行特性動態地優化代碼,以實現高性能的JavaScript執行。看下圖Ignition和TurboFan的交互:
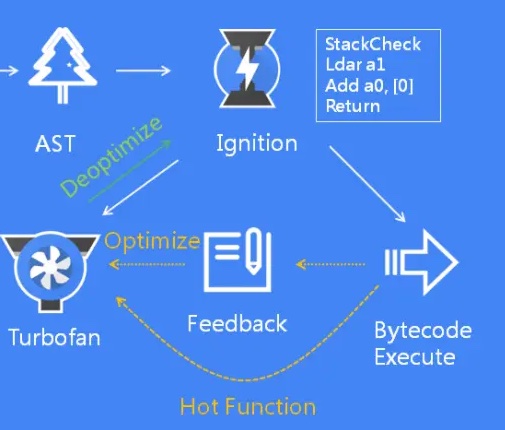
當 Ignition 開始執行 JavaScript 代碼后,V8 會一直觀察 JavaScript 代碼的執行情況,并記錄執行信息,如每個函數的執行次數、每次調用函數時,傳遞的參數類型等。如果一個函數被調用的次數超過了內設的閾值,監視器就會將當前函數標記為熱點函數(Hot Function),并將該函數的字節碼以及執行的相關信息發送給 TurboFan。TurboFan 會根據執行信息做出一些進一步優化此代碼的假設,在假設的基礎上將字節碼編譯為優化的機器代碼。如果假設成立,那么當下一次調用該函數時,就會執行優化編譯后的機器代碼,以提高代碼的執行性能。
如果假設不成立,上圖中,綠色的線,是“去優化(Deoptimize)”的過程,如果TurboFan生成的優化機器碼,對需要執行的代碼不適用,會把優化的機器碼,重新轉換成字節碼來執行。這是因為Ignition收集的信息可能是錯誤的。
例如:
function add(a, b) { return a + b; } add(1, 2); add(2, 2); add("1", "2");
add函數的參數之前是整數,后來又變成了字符串。生成的優化機器碼已經假定add函數的參數是整數,那當然是錯誤的,于是需要進行去優化,Deoptimize為Bytecode來執行。
TurboFan除了上面基于類型做優化和反優化,還有包括內聯(inlining)和逃逸分析(Escape Analysis)等,內聯就是將相關聯的函數進行合并。例如:
function add(a, b) { return a + b } function foo() { return add(2, 4) }
內聯優化后:
function fooAddInlined() { var a = 2 var b = 4 var addReturnValue = a + b return addReturnValue } // 因為 fooAddInlined 中 a 和 b 的值都是確定的,所以可以進一步優化 function fooAddInlined() { return 6 }
使用node命令的--print-code以及--print-opt-code選項,可以打印出TurboFan生成的匯編代碼。
node --print-code --print-opt-code test.js
4、Orinoco:垃圾回收
一個高效的垃圾回收器,用于自動管理內存,回收不再使用的對象內存;它使用多種垃圾回收策略,如分代回收、標記-清除、增量標記等,以實現高效內存管理。
Orinoco的主要特點包括:
?并發標記: Orinoco使用并發標記技術來減少垃圾回收的停頓時間(Pause Time)。這意味著在應用程序繼續執行的同時,垃圾回收器可以在后臺進行標記操作。
?增量式垃圾回收: Orinoco支持增量式垃圾回收,這允許垃圾回收器在小的時間片內執行部分垃圾回收工作,而不是一次性處理所有的垃圾。
?更高效的內存管理: Orinoco引入了一些新的內存管理策略和數據結構,旨在減少內存碎片和提高內存利用率。
?可擴展性: Orinoco的設計考慮了可擴展性,使得它可以適應不同的工作負載和硬件配置。
?多線程支持: Orinoco支持多線程環境,可以利用多核CPU來加速垃圾回收過程。
四、V8移植工具選型
我們的開發環境各式各樣可能系統是Mac,Linux或者Windows,架構是x86或者arm,所以要想編譯出可以跑在鴻蒙系統上的v8庫我們需要使用交叉編譯,它是在一個平臺上為另一個平臺編譯代碼的過程,允許我們在一個平臺上為另一個平臺生成可執行文件。這在嵌入式系統開發中尤為常見,因為許多嵌入式設備的硬件資源有限,不適合直接在上面編譯代碼。交叉編譯需要一個特定的編譯器、鏈接器和庫,這些都是為目標平臺設計的。此外,開發者還需要確保代碼沒有平臺相關的依賴,否則編譯可能會失敗。

v8官網上關于交叉編譯Android和iOS平臺的V8已經有詳細的介紹。尚無關于鴻蒙OHOS平臺的文檔。V8官方使用的構建系統是gn + ninja。gn是一個元構建系統,最初由Google開發,用于生成Ninja文件。它提供了一個聲明式的方式來定義項目的依賴關系、編譯選項和其他構建參數。通過運行gn gen命令,可以生成一個Ninja文件。類似于camke + make構建系統。
gn + ninja的構建流程如下:

通過查看鴻蒙sdk,我們發現鴻蒙提供給開發者的native構建系統是cmake + ninja,所以我們決定將v8官方采用的gn + ninja轉成cmake + ninja。這就需要將gn語法的構建配置文件轉成cmake的構建配置文件。
1、CMake簡介
CMake是一個開源的、跨平臺的構建系統。它不僅可以生成標準的Unix Makefile配合make命令使用,還能夠生成build.ninja文件配合ninja使用,還可以為多種IDE生成項目文件,如Visual Studio、Eclipse、Xcode等。這種跨平臺性使得CMake在多種操作系統和開發環境中都能夠無縫工作。
cmake的構建流程如下:
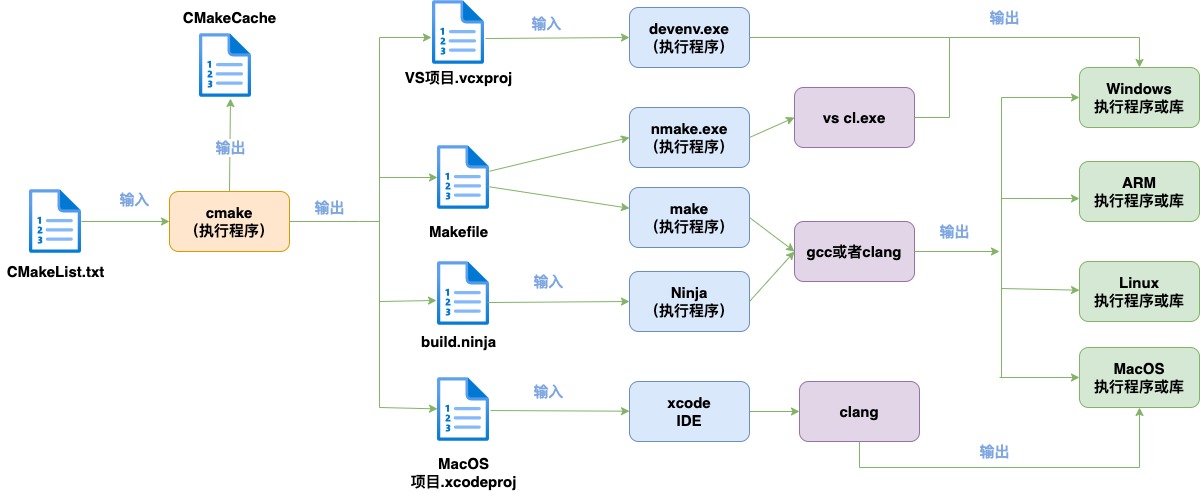
CMake構建主要過程是編寫CMakeLists.txt文件,然后用cmake命令將CMakeLists.txt文件轉化為make所需要的Makefile文件或者ninja需要的build.ninja文件,最后用make命令或者ninja命令執行編譯任務生成可執行程序或共享庫(so(shared object))。
完整CMakeLists.txt文件的主要配置樣例:
# 1. 聲明要求的cmake最低版本 cmake_minimum_required( VERSION 2.8 ) # 2. 添加c++11標準支持 #set( CMAKE_CXX_FLAGS "-std=c++11" ) # 3. 聲明一個cmake工程 PROJECT(camke_demo) MESSAGE(STATUS "Project: SERVER") #打印相關消息 # 4. 頭文件 include_directories( ${PROJECT_SOURCE_DIR}/../include/mq ${PROJECT_SOURCE_DIR}/../include/incl ${PROJECT_SOURCE_DIR}/../include/rapidjson ) # 5. 通過設定SRC變量,將源代碼路徑都給SRC,如果有多個,可以直接在后面繼續添加 set(SRC ${PROJECT_SOURCE_DIR}/../include/incl/tfc_base_config_file.cpp ${PROJECT_SOURCE_DIR}/../include/mq/tfc_ipc_sv.cpp ${PROJECT_SOURCE_DIR}/../include/mq/tfc_net_ipc_mq.cpp ${PROJECT_SOURCE_DIR}/../include/mq/tfc_net_open_mq.cpp ) # 6. 創建共享庫/靜態庫 # 設置路徑(下面生成共享庫的路徑) set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/lib) # 即生成的共享庫在工程文件夾下的lib文件夾中 set(LIB_NAME camke_demo_lib) # 創建共享庫(把工程內的cpp文件都創建成共享庫文件,方便通過頭文件來調用) # 這時候只需要cpp,不需要有主函數 # ${PROJECT_NAME}是生成的庫名 表示生成的共享庫文件就叫做 lib工程名.so # 也可以專門寫cmakelists來編譯一個沒有主函數的程序來生成共享庫,供其它程序使用 # SHARED為生成動態庫,STATIC為生成靜態庫 add_library(${LIB_NAME} STATIC ${SRC}) # 7. 鏈接庫文件 # 把剛剛生成的${LIB_NAME}庫和所需的其它庫鏈接起來 # 如果需要鏈接其他的動態庫,-l后接去除lib前綴和.so后綴的名稱,以鏈接 # libpthread.so 為例,-lpthread target_link_libraries(${LIB_NAME} pthread dl) # 8. 編譯主函數,生成可執行文件 # 先設置路徑 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/bin) # 可執行文件生成 add_executable(${PROJECT_NAME} ${SRC}) # 鏈接這個可執行文件所需的庫 target_link_libraries(${PROJECT_NAME} pthread dl ${LIB_NAME})
一般把CMakeLists.txt文件放在工程目錄下,使用時先創建一個叫build的文件夾(這個并非必須,因為cmake命令指向CMakeLists.txt所在的目錄,例如cmake ..表示CMakeLists.txt在當前目錄的上一級目錄。cmake執行后會生成很多編譯的中間文件,所以一般建議新建一個新的目錄,專門用來編譯),通常構建步驟如下:
1.mkdir build 2.cd build 3.cmake .. 或者 cmake -G Ninja .. 4.make 或者 ninja
其中cmake ..在build文件夾下生成Makefile。make命令在Makefile所在的目錄下執行,根據Makefile進行編譯。
或者cmake -G Ninja ..在build文件夾下生成build.ninja。ninja命令在build.ninja所在的目錄下執行,根據build.ninja進行編譯。
2、CMake中的交叉編譯設置
配置方式一:
直接在CMakeLists.txt文件中,使用CMAKE_C_COMPILER和CMAKE_CXX_COMPILER這兩個變量來指定C和C++的編譯器路徑。使用CMAKE_LINKER變量來指定項目的鏈接器。這樣,當CMake生成構建文件時,就會使用指定的編譯器來編譯源代碼。使用指定的鏈接器進行項目的鏈接操作。
以下是一個簡單的設置交叉編譯器和鏈接器的CMakeLists.txt文件示例:
# 指定CMake的最低版本要求 cmake_minimum_required(VERSION 3.10) # 項目名稱 project(CrossCompileExample) # 設置C編譯器和C++編譯器 set(CMAKE_C_COMPILER "/path/to/c/compiler") set(CMAKE_CXX_COMPILER "/path/to/cxx/compiler") # 設置鏈接器 set(CMAKE_LINKER "/path/to/linker") # 添加可執行文件 add_executable(myapp main.cpp)
另外我們還可以使用單獨工具鏈文件配置交叉編譯環境。
配置方式二:CMake中使用工具鏈文件配置
工具鏈文件(toolchain file)是將配置信息提取到一個單獨的文件中,以便于在多個項目中復用。包含一系列CMake變量定義,這些變量指定了編譯器、鏈接器和其他工具的位置,以及其他與目標平臺相關的設置,以確保它能夠正確地為目標平臺生成代碼。它讓我們可以專注于解決實際的問題,而不是每次都要手動配置編譯器和工具。
一個基本的工具鏈文件示例如下:
創建一個名為toolchain.cmake的文件,并在其中定義工具鏈的路徑和設置:
該項目需要為ARM架構的Linux系統進行交叉編譯
# 設置C和C++編譯器 set(CMAKE_C_COMPILER "/path/to/c/compiler") set(CMAKE_CXX_COMPILER "/path/to/cxx/compiler") # 設置鏈接器 set(CMAKE_LINKER "/path/to/linker") # 指定目標系統的類型 set(CMAKE_SYSTEM_NAME Linux) set(CMAKE_SYSTEM_PROCESSOR arm) # 其他與目標平臺相關的設置 # ...
在執行cmake命令構建時,使用-DCMAKE_TOOLCHAIN_FILE參數指定工具鏈文件的路徑:
cmake -DCMAKE_TOOLCHAIN_FILE=/path/to/toolchain.cmake /path/to/source
這樣,CMake就會使用工具鏈文件中指定的編譯器和設置來為目標平臺生成代碼。
五、V8和常規C++庫移植的重大差異
常規C++項目按照上述交叉編譯介紹的配置即可完成交叉編譯過程,但是V8的移植必須充分理解builtin和snapshot才能完成!一般的庫,所謂交叉編譯就是調用目標平臺指定的工具鏈直接編譯源碼生成目標平臺的文件。比如一個C文件要給android用,調用ndk包的gcc、clang編譯即可。但由于v8的builtin實際用的是v8自己的工具鏈體系編譯成目標平臺的代碼,所以并不能套用上面的方式。
1、builtin
1.1、builtin是什么
在V8引擎中,builtin即內置函數或模塊。V8的內置函數和模塊是JavaScript語言的一部分,提供了一些基本的功能,例如數學運算、字符串操作、日期處理等。另外ignition解析器每一條字節碼指令實現也是一個builtin。
V8的內置函數和模塊是通過C++代碼實現的,并在編譯時直接集成到V8引擎中。這些內置函數和模塊不需要在JavaScript代碼中顯式地導入或引用,就可以直接使用。
以下是一些V8的內置函數和模塊的例子:
?Math對象:提供了各種數學運算的函數,例如Math.sin()、Math.cos()等。
?String對象:提供了字符串操作的函數,例如String.prototype.split()、String.prototype.replace()等。
?Date對象:提供了日期和時間處理的函數,例如Date.now()、Date.parse()等。
?JSON對象:提供了JSON數據的解析和生成的函數,例如JSON.parse()、JSON.stringify()等。
?ArrayBuffer對象:提供了對二進制數據的操作的函數,例如ArrayBuffer.prototype.slice()、ArrayBuffer.prototype.byteLength等。
?WebAssembly模塊:提供了對WebAssembly模塊的加載和實例化的函數,例如WebAssembly.compile()、WebAssembly.instantiate()等。
這些內置函數和模塊都是V8引擎的重要組成部分,提供了基礎的JavaScript功能。它們是V8運行時最重要的“積木塊”;
1.2、builtin是如何生成的
v8源碼中builtin的編譯比較繞,因為v8中大多數builtin的“源碼”,其實是builtin的生成邏輯,這也是理解V8源碼的關鍵。
builtin和snapshot都是通過mksnapshot工具運行生成的。mksnapshot是v8編譯過程中的一個中間產物,也就是說v8編譯過程中會生成一個mksnapshot可執行程序并且會執行它生成v8后續編譯需要的builtin和snapshot,就像套娃一樣。
例如v8源碼中字節碼Ldar指令的實現如下:
IGNITION_HANDLER(Ldar, InterpreterAssembler) { TNode value = LoadRegisterAtOperandIndex(0); SetAccumulator(value); Dispatch(); }
上述代碼只在V8的編譯階段由mksnapshot程序執行,執行后會產出機器碼(JIT),然后mksnapshot程序把生成的機器碼dump下來放到匯編文件embedded.S里,編譯進V8運行時(相當于用JIT編譯器去AOT)。
builtin被dump到embedded.S的對應v8源碼在v8/src/snapshot/embedded-file-writer.h
void WriteFilePrologue(PlatformEmbeddedFileWriterBase* w) const { w->Comment("Autogenerated file. Do not edit."); w->Newline(); w->FilePrologue(); }
上述Ldar指令dump到embedded.S后匯編代碼如下:
Builtins_LdarHandler: .def Builtins_LdarHandler; .scl 2; .type 32; .endef; .octa 0x72ba0b74d93b48fffffff91d8d48,0xec83481c6ae5894855ccffa9104ae800 .octa 0x2454894cf0e4834828ec8348e2894920,0x458948e04d894ce87d894cf065894c20 .octa 0x4d0000494f808b4500001410858b4dd8,0x1640858b49e1894c00000024bac603 .octa 0x4d00000000158d4ccc01740fc4f64000,0x2045c749d0ff206d8949285589 .octa 0xe4834828ec8348e289492024648b4800,0x808b4500001410858b4d202454894cf0 .octa 0x858b49d84d8b48d233c6034d00004953,0x158d4ccc01740fc4f64000001640 .octa 0x2045c749d0ff206d89492855894d0000,0x5d8b48f0658b4c2024648b4800000000 .octa 0x4cf7348b48007d8b48011c74be0f49e0,0x100000000ba49211cb60f43024b8d .octa 0xa90f4fe800000002ba0b77d33b4c0000,0x8b48006d8b48df0c8b49e87d8b4cccff .octa 0xcccccccccccccccc90e1ff30c48348c6 .byte 0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc
builtin在v8源代碼v8srcbuiltinsbuiltins-definitions.h中定義,這個文件還include一個根據ignition指令生成的builtin列表以及torque編譯器生成的builtin定義,一共1700+個builtin。每個builtin,都會在embedded.S中生成一段代碼。
builtin生成的v8源代碼在:v8srcbuiltinssetup-builtins-internal.cc
void SetupIsolateDelegate::SetupBuiltinsInternal(Isolate* isolate) { Builtins* builtins = isolate->builtins(); DCHECK(!builtins->initialized_); PopulateWithPlaceholders(isolate); // Create a scope for the handles in the builtins. HandleScope scope(isolate); int index = 0; Code code; #define BUILD_CPP(Name) code = BuildAdaptor(isolate, Builtin::k##Name, FUNCTION_ADDR(Builtin_##Name), #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_TFJ(Name, Argc, ...) code = BuildWithCodeStubAssemblerJS( isolate, Builtin::k##Name, &Builtins::Generate_##Name, Argc, #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_TFC(Name, InterfaceDescriptor) /* Return size is from the provided CallInterfaceDescriptor. */ code = BuildWithCodeStubAssemblerCS( isolate, Builtin::k##Name, &Builtins::Generate_##Name, CallDescriptors::InterfaceDescriptor, #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_TFS(Name, ...) /* Return size for generic TF builtins (stub linkage) is always 1. */ code = BuildWithCodeStubAssemblerCS(isolate, Builtin::k##Name, &Builtins::Generate_##Name, CallDescriptors::Name, #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_TFH(Name, InterfaceDescriptor) /* Return size for IC builtins/handlers is always 1. */ code = BuildWithCodeStubAssemblerCS( isolate, Builtin::k##Name, &Builtins::Generate_##Name, CallDescriptors::InterfaceDescriptor, #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_BCH(Name, OperandScale, Bytecode) code = GenerateBytecodeHandler(isolate, Builtin::k##Name, OperandScale, Bytecode); AddBuiltin(builtins, Builtin::k##Name, code); index++; #define BUILD_ASM(Name, InterfaceDescriptor) code = BuildWithMacroAssembler(isolate, Builtin::k##Name, Builtins::Generate_##Name, #Name); AddBuiltin(builtins, Builtin::k##Name, code); index++; BUILTIN_LIST(BUILD_CPP, BUILD_TFJ, BUILD_TFC, BUILD_TFS, BUILD_TFH, BUILD_BCH, BUILD_ASM); #undef BUILD_CPP #undef BUILD_TFJ #undef BUILD_TFC #undef BUILD_TFS #undef BUILD_TFH #undef BUILD_BCH #undef BUILD_ASM // ... }
BUILTIN_LIST宏內定義了所有的builtin,并根據其類型去調用不同的參數,在這里參數是BUILD_CPP, BUILD_TFJ...這些,定義了不同的生成策略,這些參數去掉前綴代表不同的builtin類型(CPP, TFJ, TFC, TFS, TFH, BCH, ASM)
mksnapshot執行時生成builtin的方式有兩種:
?直接生成機器碼,ASM和CPP類型builtin使用這種方式(CPP類型只是生成適配器)
?先生成turbofan的graph(IR),然后由turbofan編譯器編譯成機器碼,除ASM和CPP之外其它builtin類型都是這種
例如:DoubleToI是一個ASM類型builtin,功能是把double轉成整數,該builtin的JIT生成邏輯位于Builtins::Generate_DoubleToI,如果是x64的window,該函數放在v8/src/builtins/x64/builtins-x64.cc文件。由于每個CPU架構的指令都不一樣,所以每個CPU架構都有一個實現,放在各自的builtins-ArchName.cc文件。
x64的實現如下:
void Builtins::Generate_DoubleToI(MacroAssembler* masm) { Label check_negative, process_64_bits, done; // Account for return address and saved regs. const int kArgumentOffset = 4 * kSystemPointerSize; MemOperand mantissa_operand(MemOperand(rsp, kArgumentOffset)); MemOperand exponent_operand( MemOperand(rsp, kArgumentOffset + kDoubleSize / 2)); // The result is returned on the stack. MemOperand return_operand = mantissa_operand; Register scratch1 = rbx; // Since we must use rcx for shifts below, use some other register (rax) // to calculate the result if ecx is the requested return register. Register result_reg = rax; // Save ecx if it isn't the return register and therefore volatile, or if it // is the return register, then save the temp register we use in its stead // for the result. Register save_reg = rax; __ pushq(rcx); __ pushq(scratch1); __ pushq(save_reg); __ movl(scratch1, mantissa_operand); __ Movsd(kScratchDoubleReg, mantissa_operand); __ movl(rcx, exponent_operand); __ andl(rcx, Immediate(HeapNumber::kExponentMask)); __ shrl(rcx, Immediate(HeapNumber::kExponentShift)); __ leal(result_reg, MemOperand(rcx, -HeapNumber::kExponentBias)); __ cmpl(result_reg, Immediate(HeapNumber::kMantissaBits)); __ j(below, &process_64_bits, Label::kNear); // Result is entirely in lower 32-bits of mantissa int delta = HeapNumber::kExponentBias + base::Double::kPhysicalSignificandSize; __ subl(rcx, Immediate(delta)); __ xorl(result_reg, result_reg); __ cmpl(rcx, Immediate(31)); __ j(above, &done, Label::kNear); __ shll_cl(scratch1); __ jmp(&check_negative, Label::kNear); __ bind(&process_64_bits); __ Cvttsd2siq(result_reg, kScratchDoubleReg); __ jmp(&done, Label::kNear); // If the double was negative, negate the integer result. __ bind(&check_negative); __ movl(result_reg, scratch1); __ negl(result_reg); __ cmpl(exponent_operand, Immediate(0)); __ cmovl(greater, result_reg, scratch1); // Restore registers __ bind(&done); __ movl(return_operand, result_reg); __ popq(save_reg); __ popq(scratch1); __ popq(rcx); __ ret(0); }
看上去很像匯編(編程的思考方式按匯編來),實際上是c++函數,比如這行movl
__ movl(scratch1, mantissa_operand);
__是個宏,實際上是調用masm變量的函數(movl)
#define __ ACCESS_MASM(masm) #define ACCESS_MASM(masm) masm->
而movl的實現是往pc_指針指向的內存寫入mov指令及其操作數,并把pc_指針前進指令長度。
ps:一條條指令寫下來,然后把內存權限改為可執行,這就是JIT的基本原理。
除了ASM和CPP的其它類型builtin都通過調用CodeStubAssembler API(下稱CSA)編寫,這套API和之前介紹ASM類型builtin時提到的“類匯編API”類似,不同的是“類匯編API”直接產出原生代碼,CSA產出的是turbofan的graph(IR)。CSA比起“類匯編API”的好處是不用每個平臺各寫一次。
但是類匯編的CSA寫起來還是太費勁了,于是V8提供了一個類javascript的高級語言:torque,這語言最終會編譯成CSA形式的c++代碼和V8其它C++代碼一起編譯。
例如Array.isArray使用torque語言實現如下:
namespace runtime { extern runtime ArrayIsArray(implicit context: Context)(JSAny): JSAny; } // namespace runtime namespace array { // ES #sec-array.isarray javascript builtin ArrayIsArray(js-implicit context: NativeContext)(arg: JSAny): JSAny { // 1. Return ? IsArray(arg). typeswitch (arg) { case (JSArray): { return True; } case (JSProxy): { // TODO(verwaest): Handle proxies in-place return runtime::ArrayIsArray(arg); } case (JSAny): { return False; } } } } // namespace array
經過torque編譯器編譯后,會生成一段復雜的CSA的C++代碼,下面截取一個片段
TNode Cast_JSProxy_1(compiler::CodeAssemblerState* state_, TNode p_context, TNode p_o, compiler::CodeAssemblerLabel* label_CastError) { // other code ... if (block0.is_used()) { ca_.Bind(&block0); ca_.SetSourcePosition("../../src/builtins/cast.tq", 162); compiler::CodeAssemblerLabel label1(&ca_); tmp0 = CodeStubAssembler(state_).TaggedToHeapObject(TNode{p_o}, &label1); ca_.Goto(&block3); if (label1.is_used()) { ca_.Bind(&label1); ca_.Goto(&block4); } } // other code ... }
和上面講的Ldar字節碼一樣,這并不是跑在v8運行時的Array.isArray實現。這段代碼只運行在mksnapshot中,這段代碼的產物是turbofan的IR。IR經過turbofan的優化編譯后生成目標機器指令,然后dump到embedded.S匯編文件,下面才是真正跑在v8運行時的Array.isArray:
Builtins_ArrayIsArray: .type Builtins_ArrayIsArray, %function .size Builtins_ArrayIsArray, 214 .octa 0xd10043ff910043fda9017bfda9be6fe1,0x540003a9eb2263fff8560342f81e83a0 .octa 0x7840b063f85ff04336000182f9401be2,0x14000007d2800003540000607110907f .octa 0x910043ffa8c17bfd910003bff85b8340,0x35000163d2800020d2800023d65f03c0 .octa 0x540000e17102d47f7840b063f85ff043,0xf94da741f90003e2f90007ffd10043ff .octa 0x17ffffeef85c034017fffff097ffb480,0xaa1b03e2f9501f41d2800000f90003fb .octa 0x17ffffddf94003fb97ffb477aa0003e3,0x840000000100000002d503201f .octa 0xffffffff000000a8ffffffffffffffff .byte 0xff,0xff,0xff,0xff,0x0,0x1,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc
在這個過程中,JIT編譯器turbofan同樣干的是AOT的活。
1.3、builtin是怎么加載使用的
mksnapshot生成的包含所有builtin的產物embedded.S會和其他v8源碼一起編譯成最終的v8庫,embedded.S中聲明了四個全局變量,分別是:
?v8_Default_embedded_blob_code_:初始化為第一個builtin的起始位置(全部builtin緊湊的放在一個代碼段里)
?v8_Default_embedded_blob_data_:指向一塊數據,這塊數據包含諸如各builtin相對v8_Default_embedded_blob_code_的偏移,builtin的長度等等信息
?v8_Default_embedded_blob_code_size_:所有builtin的總長度
?v8_Default_embedded_blob_data_size_:v8_Default_embedded_blob_data_數據的總長度
在v8/src/execution/isolate.cc中聲明了幾個extern變量,鏈接embedded.S后v8/src/execution/isolate.cc就能引用到那幾個變量:
extern "C" const uint8_t* v8_Default_embedded_blob_code_; extern "C" uint32_t v8_Default_embedded_blob_code_size_; extern "C" const uint8_t* v8_Default_embedded_blob_data_; extern "C" uint32_t v8_Default_embedded_blob_data_size_;
v8_Default_embedded_blob_data_中包含了各builtin的偏移,這些偏移組成一個數組,放在isolate的builtin_entry_table,數組下標是該builtin的枚舉值。調用某builtin就是builtin_entry_table通過枚舉值獲取起始地址調用。
2、snapshot
在V8引擎中,snapshot是指在啟動時將部分或全部JavaScript堆內存的狀態保存到一個文件中,以便在后續的啟動中可以快速恢復到這個狀態。這個技術可以顯著減少V8引擎的啟動時間,特別是在大型應用程序中。
snapshot文件包含了以下幾個部分:
?JavaScript堆的內存布局:包括了所有對象的地址、大小和類型等信息。
?JavaScript代碼的字節碼:包括了所有已經編譯的JavaScript函數的字節碼。
?全局對象的狀態:包括了全局對象的屬性值、函數指針等信息。
?其他必要的狀態:例如,垃圾回收器的狀態、Just-In-Time (JIT) 編譯器的緩存等。
當V8引擎啟動時,如果存在有效的Snapshot文件,V8會直接從這個文件中讀取JavaScript堆的狀態和字節碼,而不需要重新解析和編譯所有的JavaScript代碼。這可以大幅度縮短V8引擎的啟動時間。V8的Snapshot技術有以下幾個優點:
?快速啟動:可以顯著減少V8引擎的啟動時間,特別是在大型應用程序中。
?低內存占用:由于部分或全部JavaScript堆的狀態已經被保存到文件中,所以在啟動時可以節省內存。
?穩定性:Snapshot文件是由V8引擎生成的,保證了與引擎的兼容性和穩定性。
如果不是交叉編譯,snapshot生成還是挺容易理解的:v8對各種對象有做了序列化和反序列化的支持,所謂生成snapshot,就是序列化,通常會以context作為根來序列化。
mksnapshot制作快照可以輸入一個額外的腳本,也就是生成snapshot前允許執行一段代碼,這段代碼調用到的函數的編譯結果也會序列化下來,后續加載快照反序列化后等同于執行過了這腳本,就免去了編譯過程,大大加快的啟動的速度。
mksnapshot制作快照是通過調用v8::SnapshotCreator完成,而v8::SnapshotCreator提供了我們輸入外部數據的機會。如果只有一個Context需要保存,用SnapshotCreator::SetDefaultContext就可以了,恢復時直接v8::Context::New即可。如果有多于一個Context,可以通過SnapshotCreator::AddContext添加,它會返回一個索引,恢復時輸入索引即可恢復到指定的存檔。如果保存Context之外的數據,可以調用SnapshotCreator::AddData,然后通過Isolate或者Context的GetDataFromSnapshot接口恢復。
//保存 size_t context_index = snapshot_creator.AddContext(context, si_cb); //恢復 v8::Local context = v8::Context::FromSnapshot(isolate, context_index, di_cb).ToLocalChecked();
結合交叉編譯時就會有個很費解的地方:我們前面提到mksnapshot在交叉編譯時,JIT生成的builtin是目標機器指令,而js的運行得通過跑builtin來實現(Ignition解析器每個指令就是一個builtin),這目標機器指令(比如arm64)怎么在本地(比如linux 的x64)跑起來呢?mksnapshot為了實現交叉編譯中目標平臺snapshot的生成,它做了各種cpu(arm、mips、risc、ppc)的模擬器(Simulator)
通過查看源碼交叉編譯時,mksnapshot會用一個目標機器的模擬器來跑這些builtin:
//srccommonglobals.h #if !defined(USE_SIMULATOR) #if (V8_TARGET_ARCH_ARM64 && !V8_HOST_ARCH_ARM64) #define USE_SIMULATOR 1 #endif // ... #endif //srcexecutionsimulator.h #ifdef USE_SIMULATOR Return Call(Args... args) { // other code ... return Simulator::current(isolate_)->template Call( reinterpret_cast(fn_ptr_), args...); } #else DISABLE_CFI_ICALL Return Call(Args... args) { // other code ... } #endif // USE_SIMULATOR
如果交叉編譯,將會走USE_SIMULATOR分支。arm64將會調用到v8/src/execution/simulator-arm64.h,v8/src/execution/simulator-arm64.cc實現的模擬器。上面Call的處理是把指令首地址賦值到模擬器的_pc寄存器,參數放寄存器,執行完指令從寄存器獲取返回值。
六、V8移植的具體步驟
一般我們將負責編譯的機器稱為host,編譯產物運行的目標機器稱為target。
?本文使用的host機器是Mac M1 ,Xcode版本Version 14.2 (14C18)
?鴻蒙IDE版本:DevEco Studio NEXT Developer Beta5
?鴻蒙SDK版本是HarmonyOS-NEXT-DB5
?目標機器架構:arm64-v8a
如果要在Mac M1上交叉編譯鴻蒙arm64的builtin,步驟如下:
?調用本地編譯器,編譯一個Mac M1版本mksnapshot可執行程序
?執行上述mksnapshot生成鴻蒙平臺arm64指令并dump到embedded.S
?調用鴻蒙sdk的工具鏈,編譯鏈接embedded.S和v8的其它代碼,生成能在鴻蒙arm64上使用的v8庫
1.首先安裝cmake及ninja構建工具
鴻蒙sdk自帶構建工具我們可以將它們加入環境變量中使用

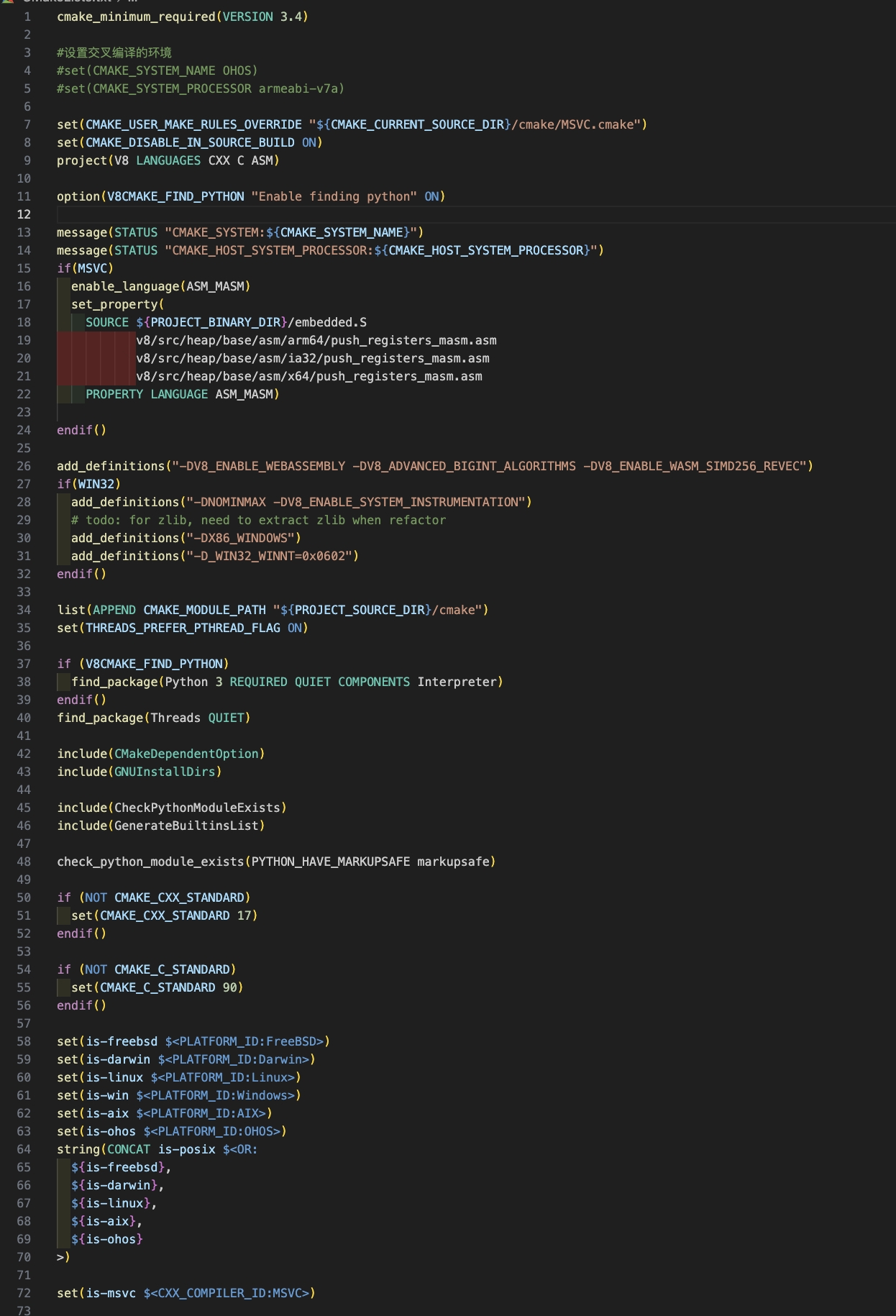
2.編寫交叉編譯V8到鴻蒙的CMakeList.txt
總共有1千多行,部分CMakeList.txt片段:
3.使用host本機的編譯工具鏈編譯
$ mkdir build $ cd build $ cmake -G Ninja .. $ ninja 或者 cmake --build .
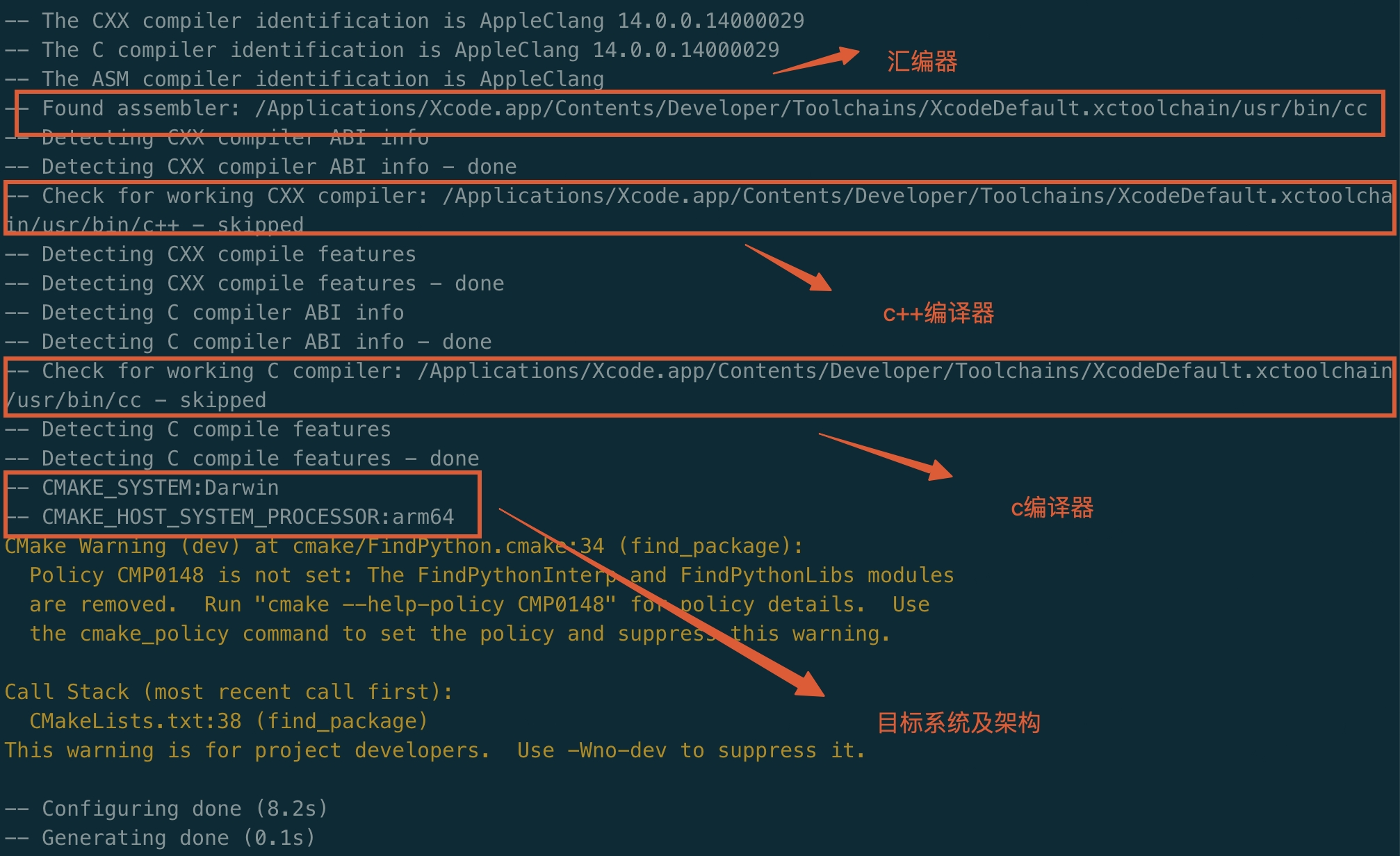
首先創建一個編譯目錄build,打開build執行cmake -G Ninja ..生成針對ninja編譯需要的文件。
下面是控制臺打印的工具鏈配置信息,使用的是Mac本地xcode的工具鏈:
build文件夾下生成以下文件:
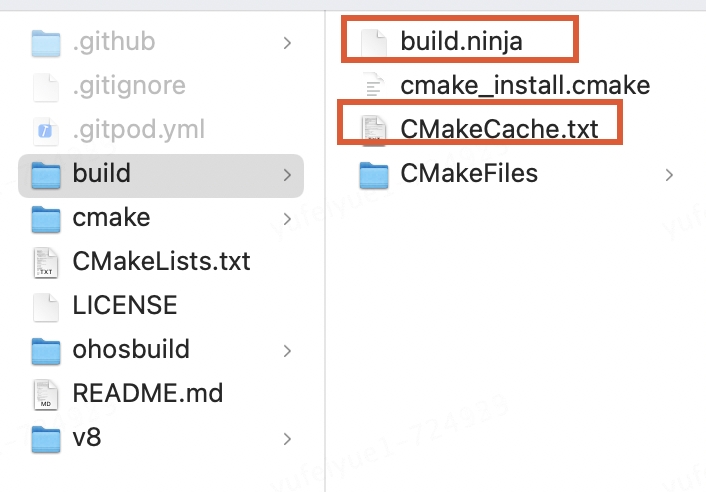
其中CMakeCache.txt是一個由CMake生成的緩存文件,用于存儲CMake在配置過程中所做的選擇和決策。它是根據你的項目的CMakeLists.txt文件和系統環境來生成一個初始的CMakeCache.txt文件。這個文件包含了所有可配置的選項及其默認值。
build.ninja文件是Ninja的主要輸入文件,包含了項目的所有構建規則和依賴關系。
這個文件的內容是Ninja的語法,描述了如何從源文件生成目標文件。它包括了以下幾個部分:
?規則:定義了如何從源文件生成目標文件的規則。例如,編譯C++文件、鏈接庫等。
?構建目標:列出了項目中所有需要構建的目標,包括可執行文件、靜態庫、動態庫等。
?依賴關系:描述了各個構建目標之間的依賴關系。Ninja會根據這些依賴關系來確定構建的順序。
?變量:定義了一些Ninja使用的變量,例如編譯器、編譯選項等。
然后執行cmake --build .或者ninja
查看build文件夾下生成的產物:
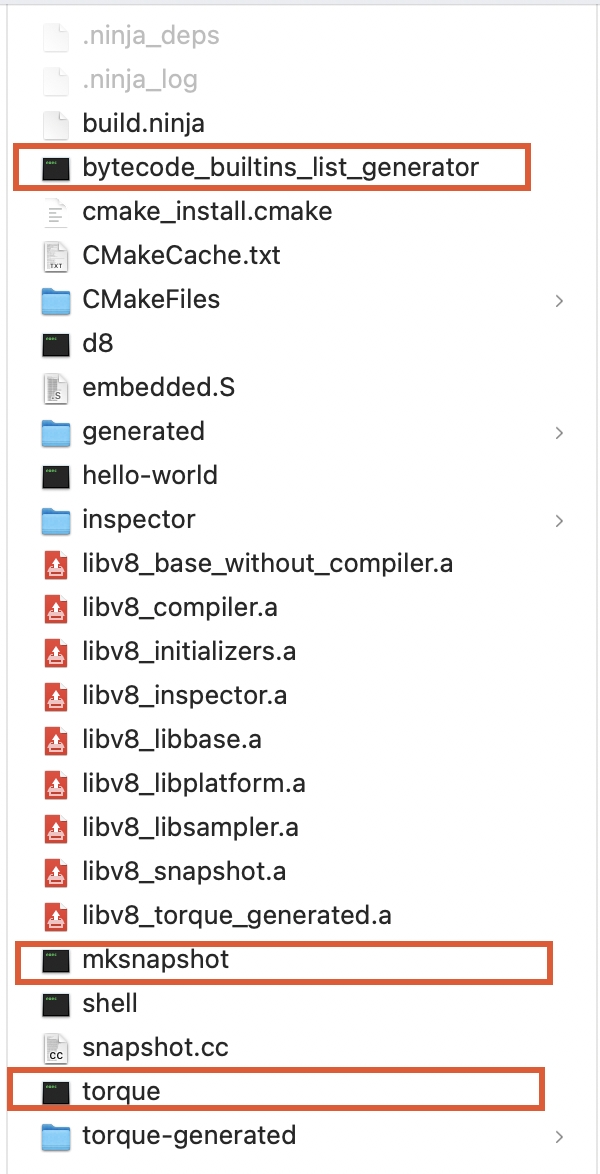
其中紅框中的三個可執行文件是在編譯過程中生成,同時還會在編譯過程中執行。bytecode_builtins_list_generator主要生成是字節碼對應builtin的生成代碼。torque負責將.tq后綴的文件(使用torque語言編寫的builtin)編譯成CSA類型builtin的c++源碼文件。
torque編譯.tq文件生成的c++代碼在torque-generated目錄中:
bytecode_builtins_list_generator執行生成字節碼函數列表在下面目錄中:
mksnapshot則鏈接這些代碼并執行,執行期間會在內置的對應架構模擬器中運行v8,最終生成host平臺的buildin匯編代碼——embedded.S和snapshot(context的序列化對象)——snapshot.cc。它們跟隨其他v8源代碼一起編譯生成最終的v8靜態庫libv8_snapshot.a。目前build目錄中已經編譯出host平臺的完整v8靜態庫及命令行調試工具d8。
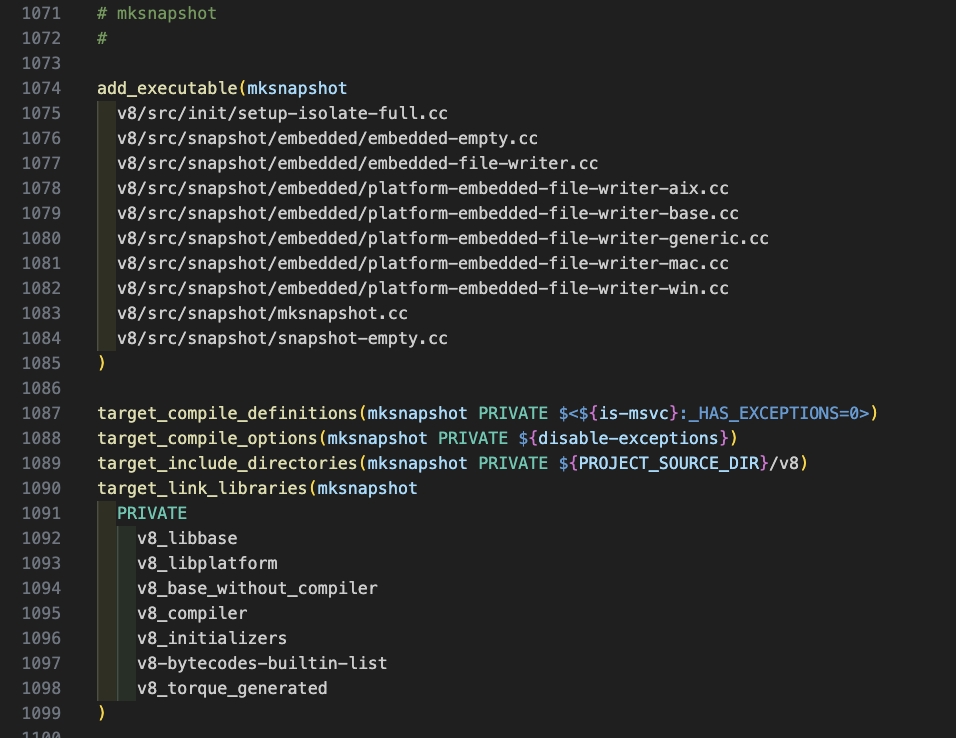
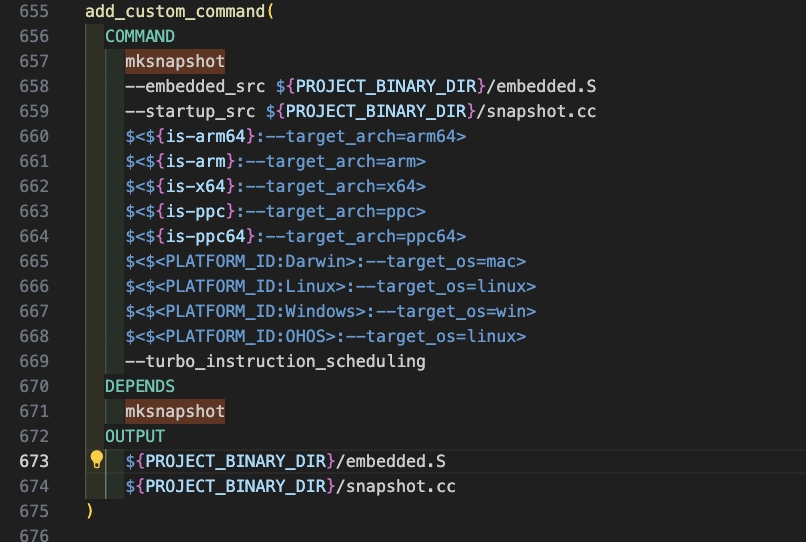
mksnapshot程序自身的編譯生成及執行在CMakeList.txt中的配置代碼如下:
4.使用鴻蒙SDK的編譯工具鏈編譯
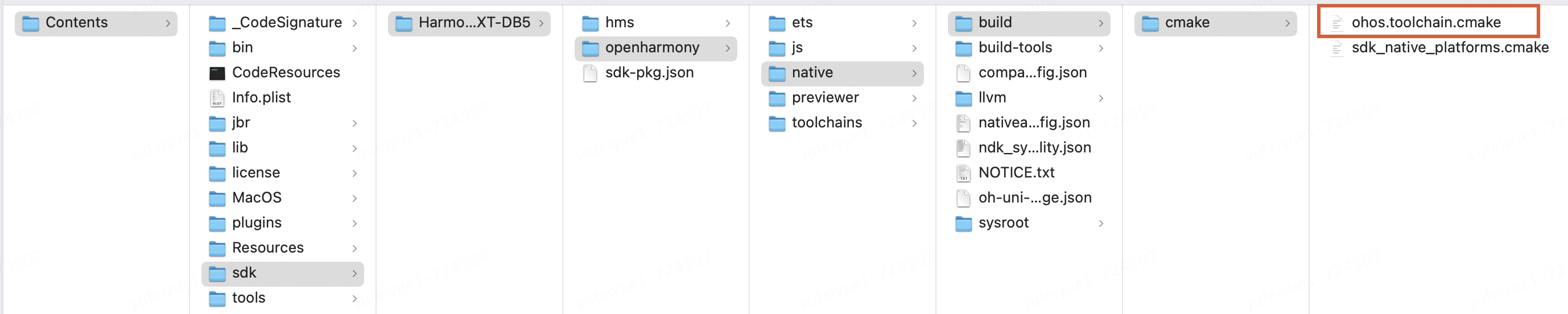
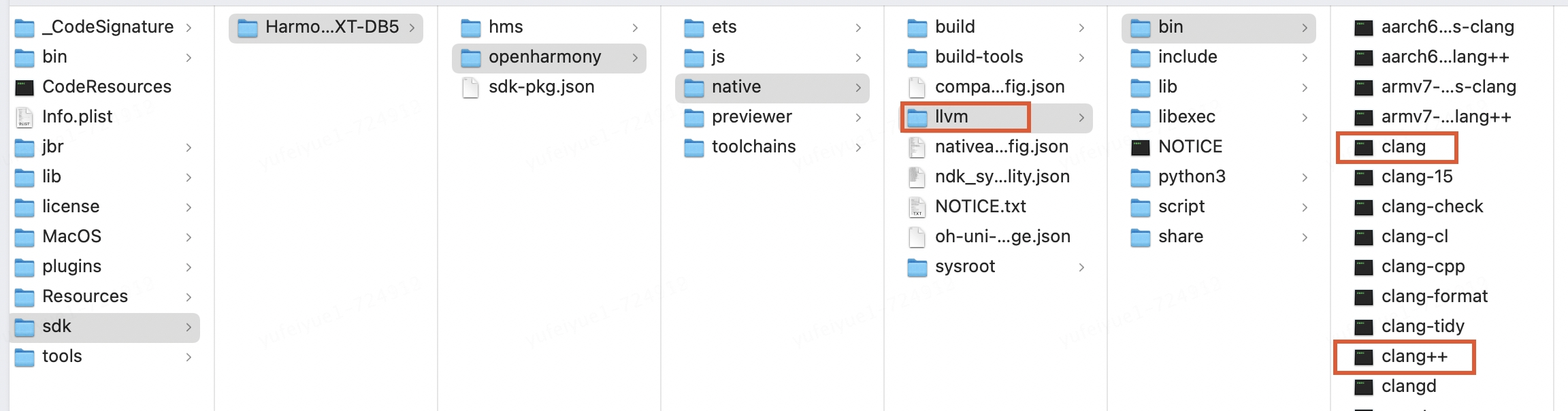
因為在編譯target平臺的v8時中間生成的bytecode_builtins_list_generator,torque,mksnapshot可執行文件是針對target架構的無法在host機器上執行。所以首先需要把上面在host平臺生成的可執行文件拷貝到/usr/local/bin,這樣在編譯target平臺的v8過程中執行這些中間程序時會找到/usr/local/bin下的可執行文件正確的執行生成針對target的builtin和snapshot快照。
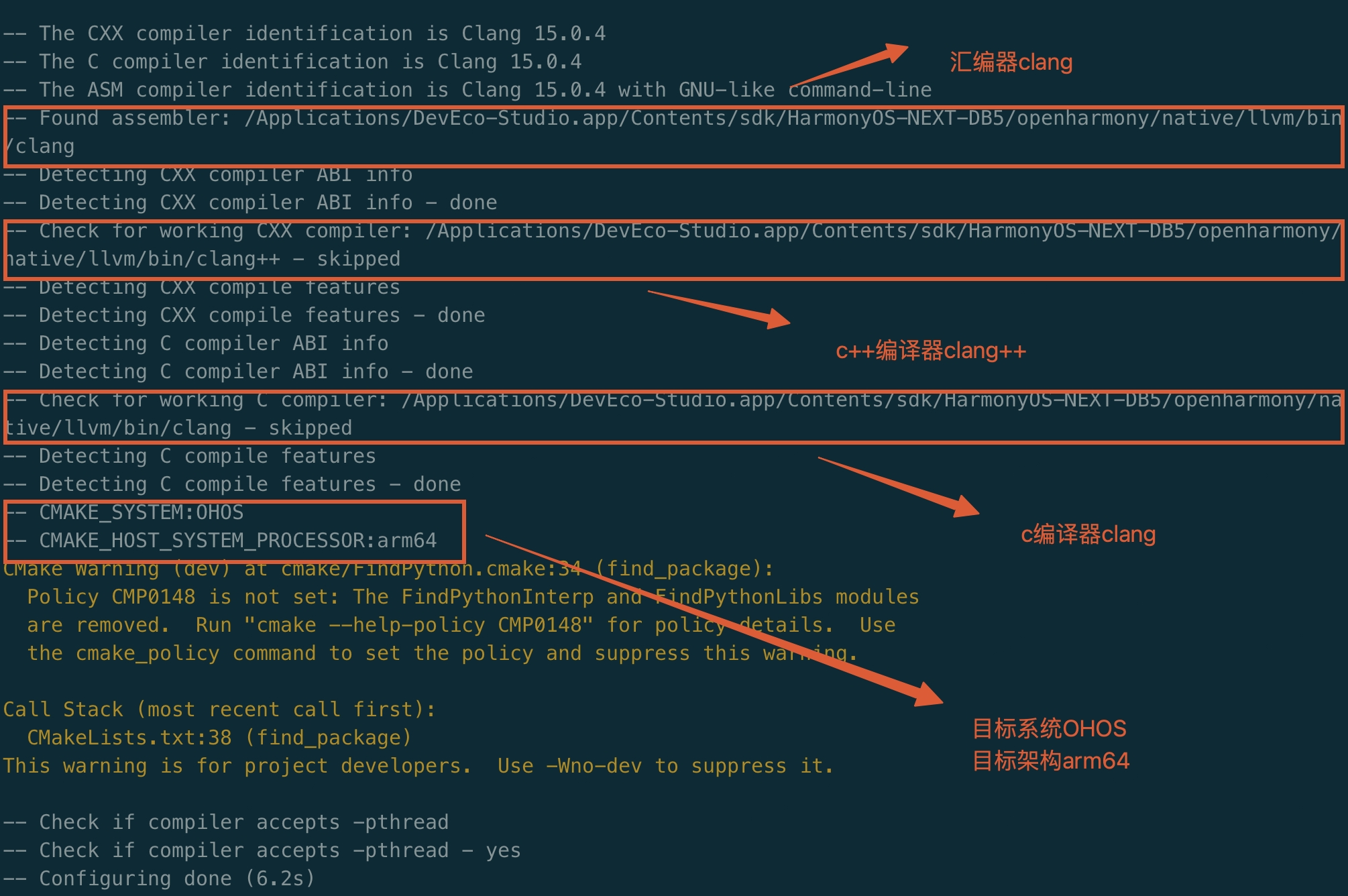
$ cp bytecode_builtins_list_generator torque mksnapshot /usr/local/bin $ mkdir ohosbuild #創建新的鴻蒙v8的編譯目錄 $ cd ohosbuild #使用鴻蒙提供的工具鏈文件 $ cmake -DOHOS_STL=c++_shared -DOHOS_ARCH=arm64-v8a -DOHOS_PLATFORM=OHOS -DCMAKE_TOOLCHAIN_FILE=/Applications/DevEco-Studio.app/Contents/sdk/HarmonyOS-NEXT-DB5/openharmony/native/build/cmake/ohos.toolchain.cmake -G Ninja .. $ ninja 或者 cmake --build .
執行第一步cmake配置后控制臺的信息可以看到,使用了鴻蒙的工具鏈
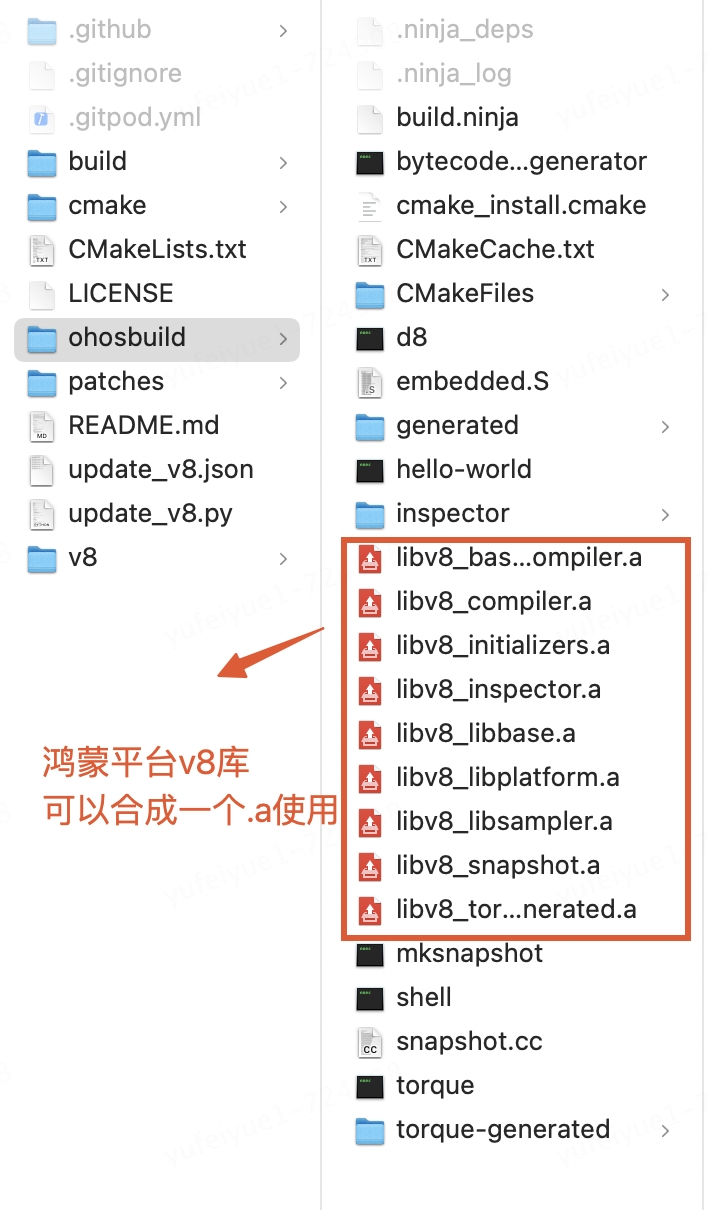
執行完成后ohosbuild文件夾下生成了鴻蒙平臺的v8靜態庫,可以修改CMakeList.txt配置合成一個.a或者生成.so。
七、鴻蒙工程中使用v8庫
1.新建native c++工程
2.導入v8庫
將v8源碼中的include目錄和上面編譯生成的.a文件放入cpp文件夾下
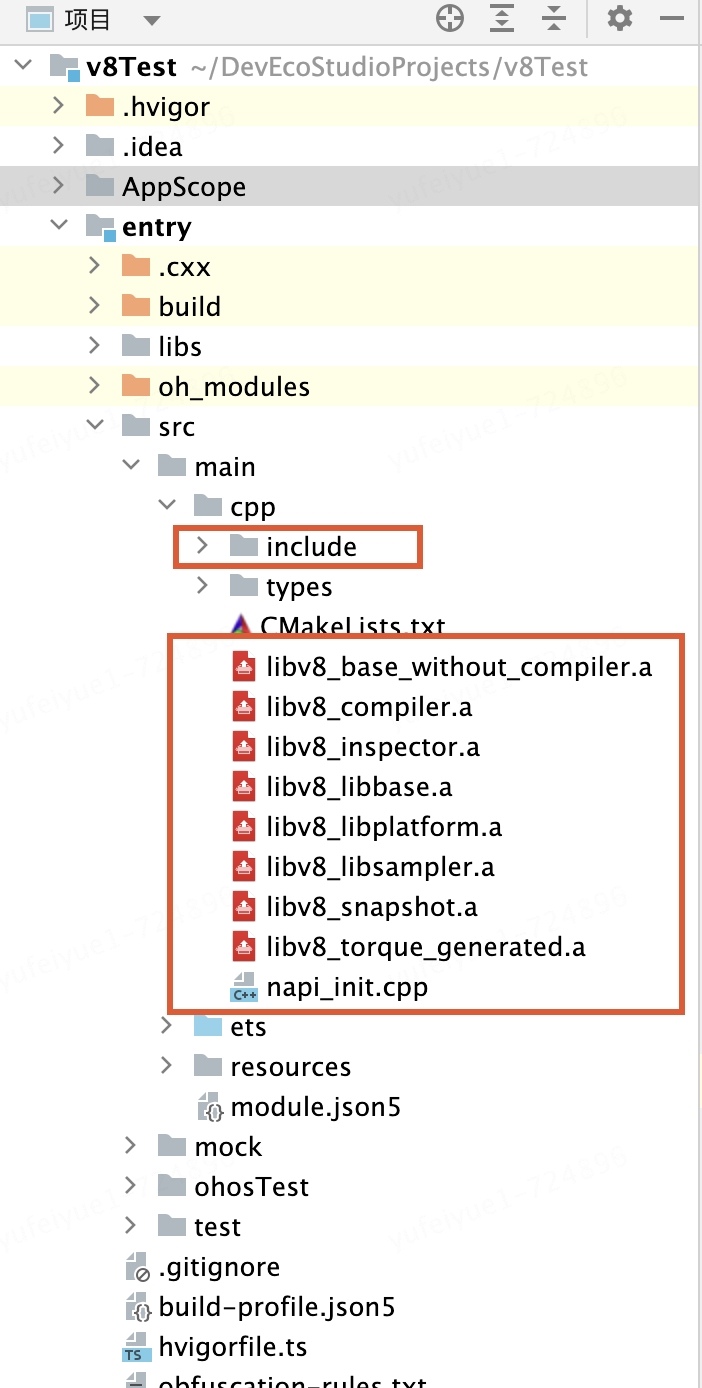
3.修改cpp目錄下CMakeList.txt文件
設置c++標準17,鏈接v8靜態庫
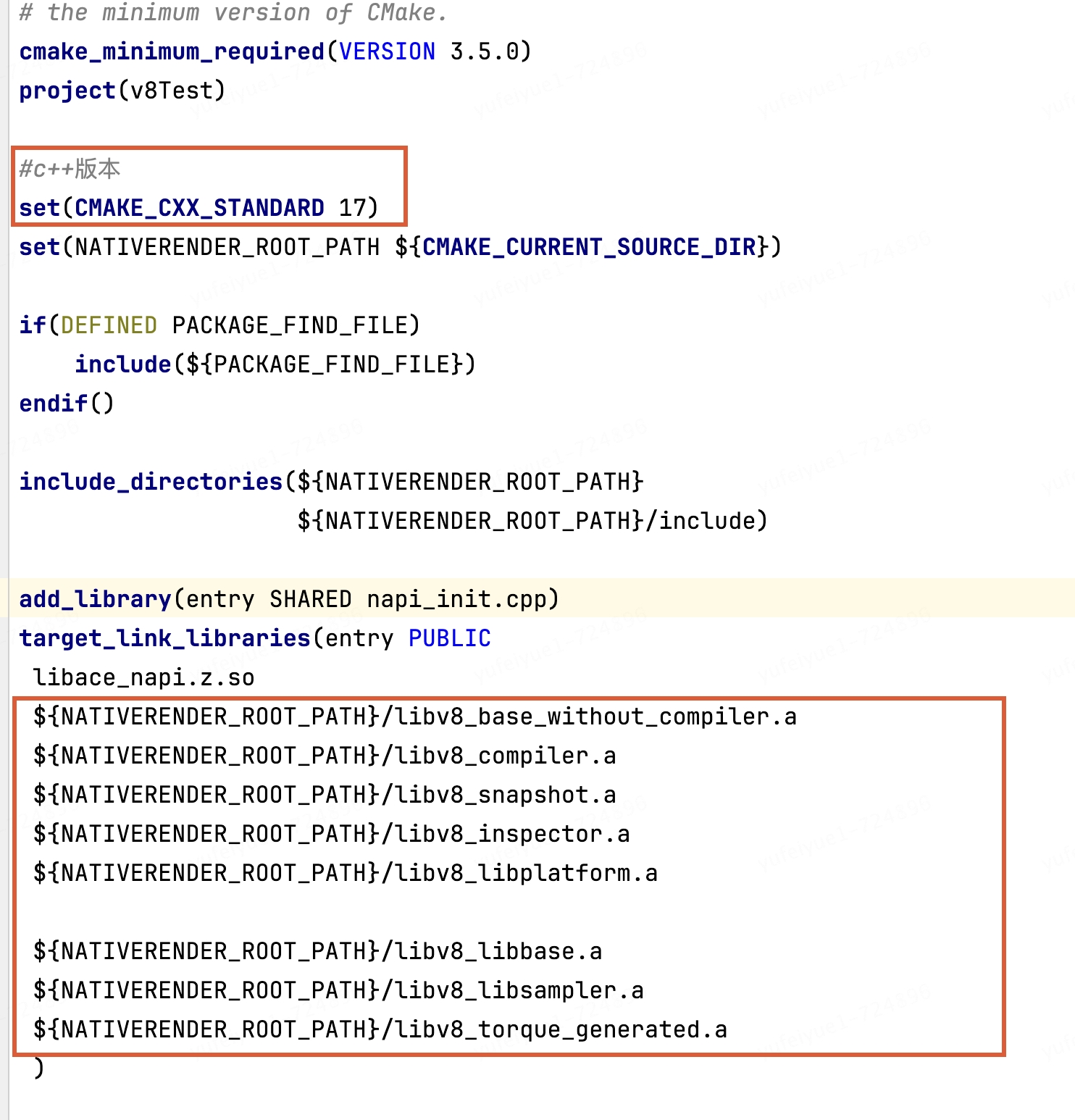
4.添加napi方法測試使用v8
下面是簡單的demo
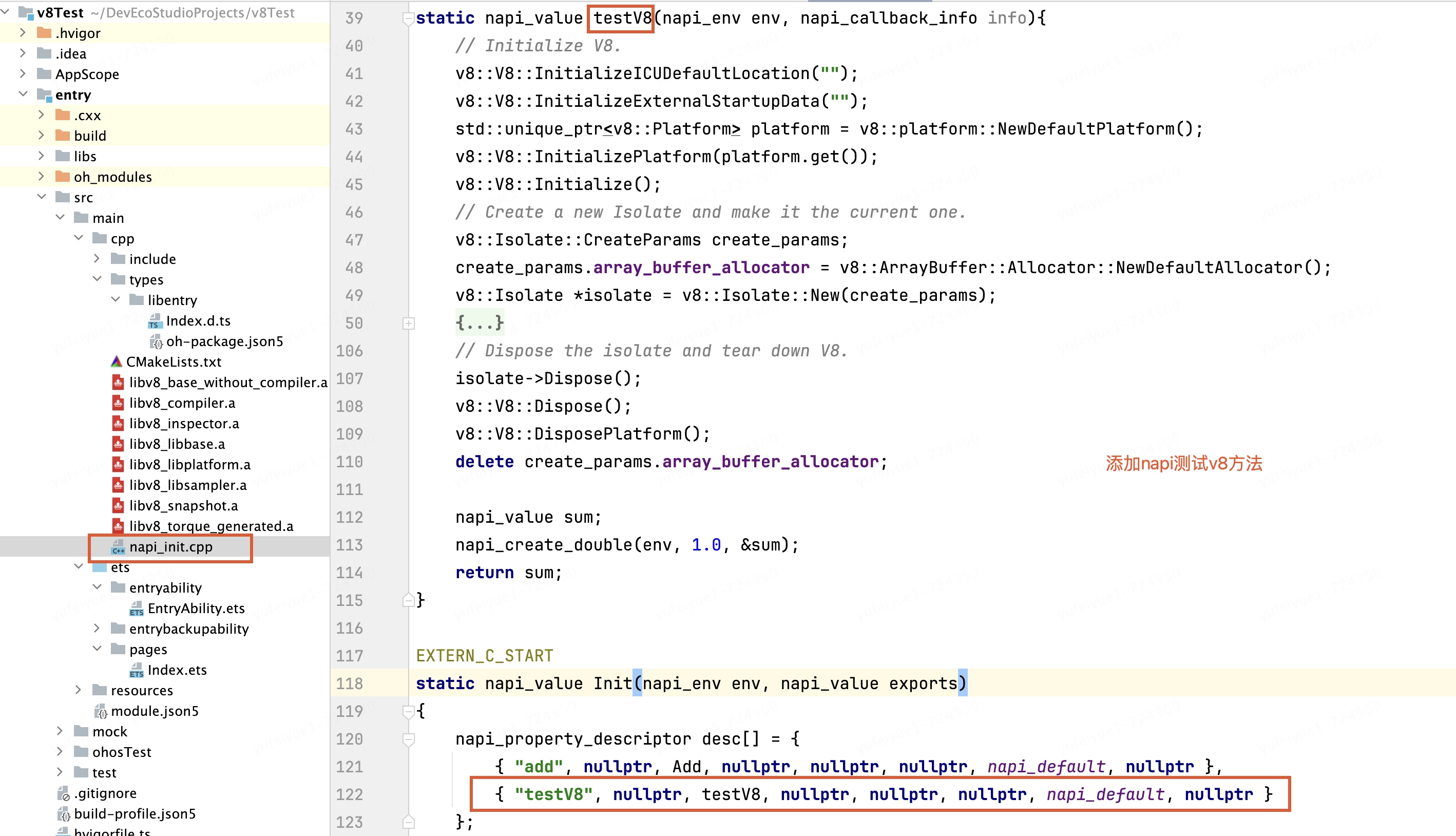
導出c++方法
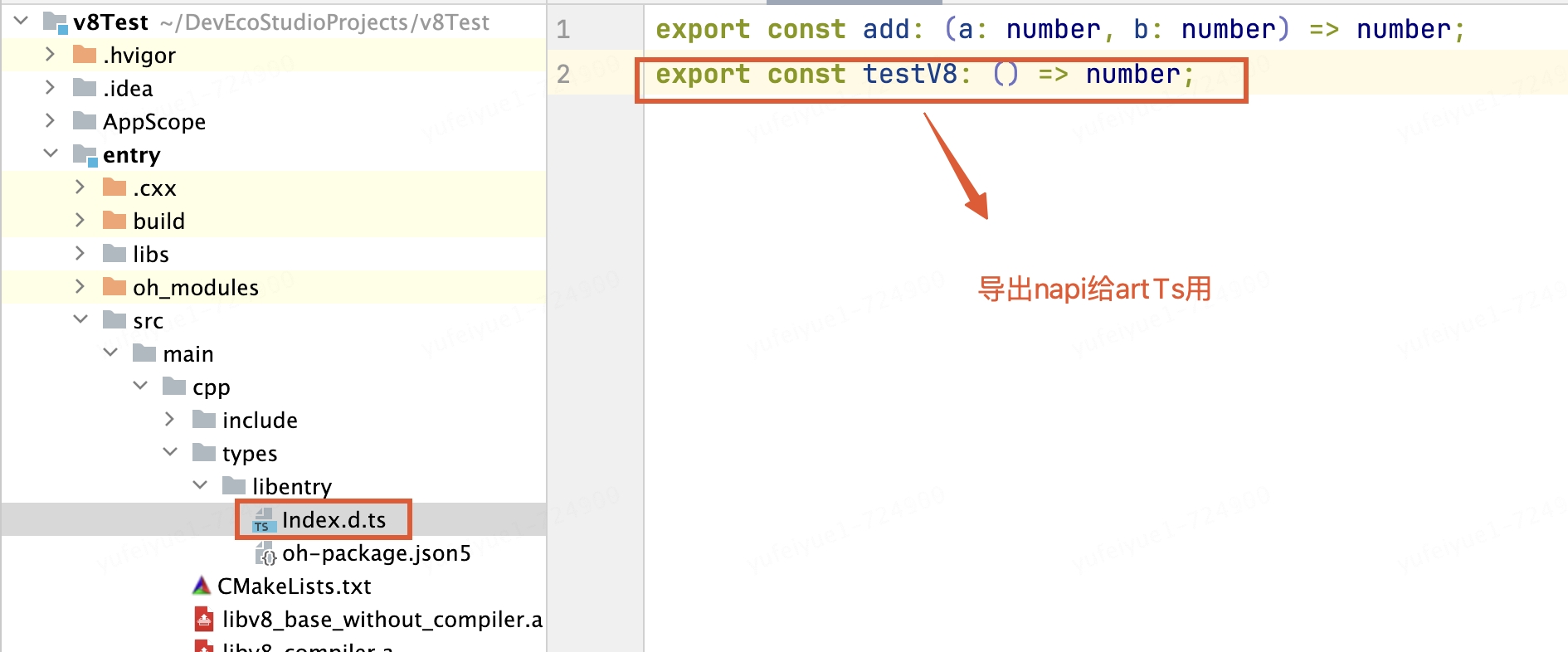
、
arkts側調用c++方法
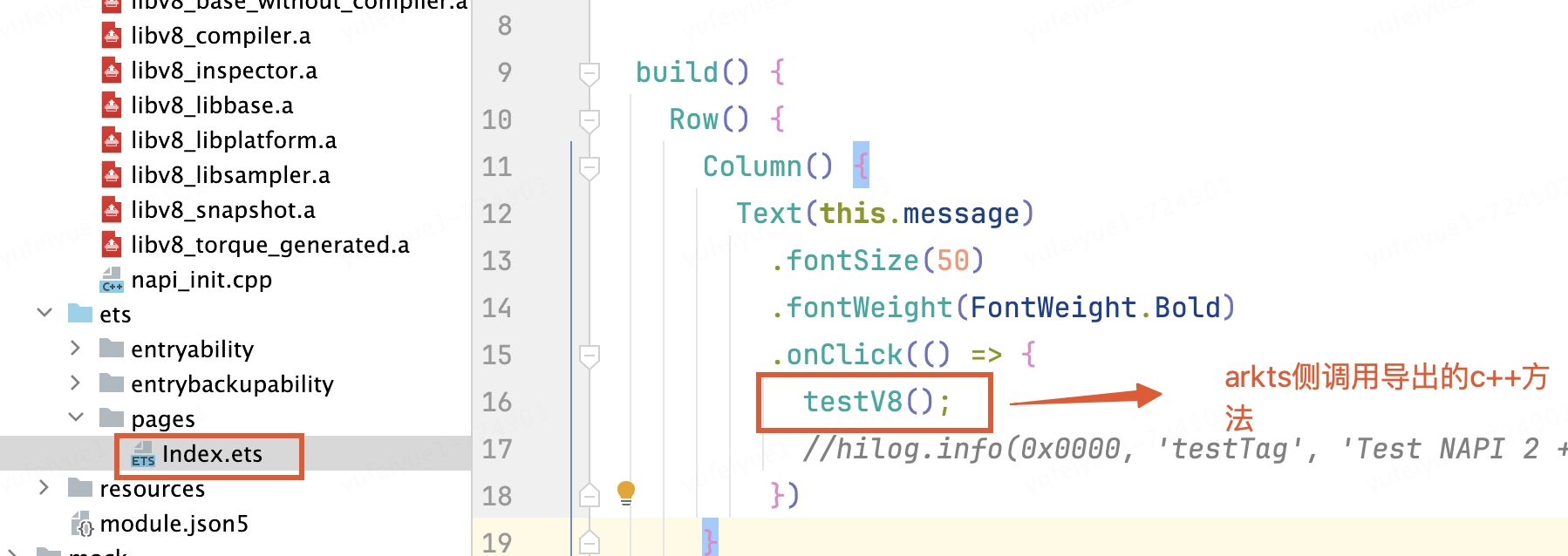
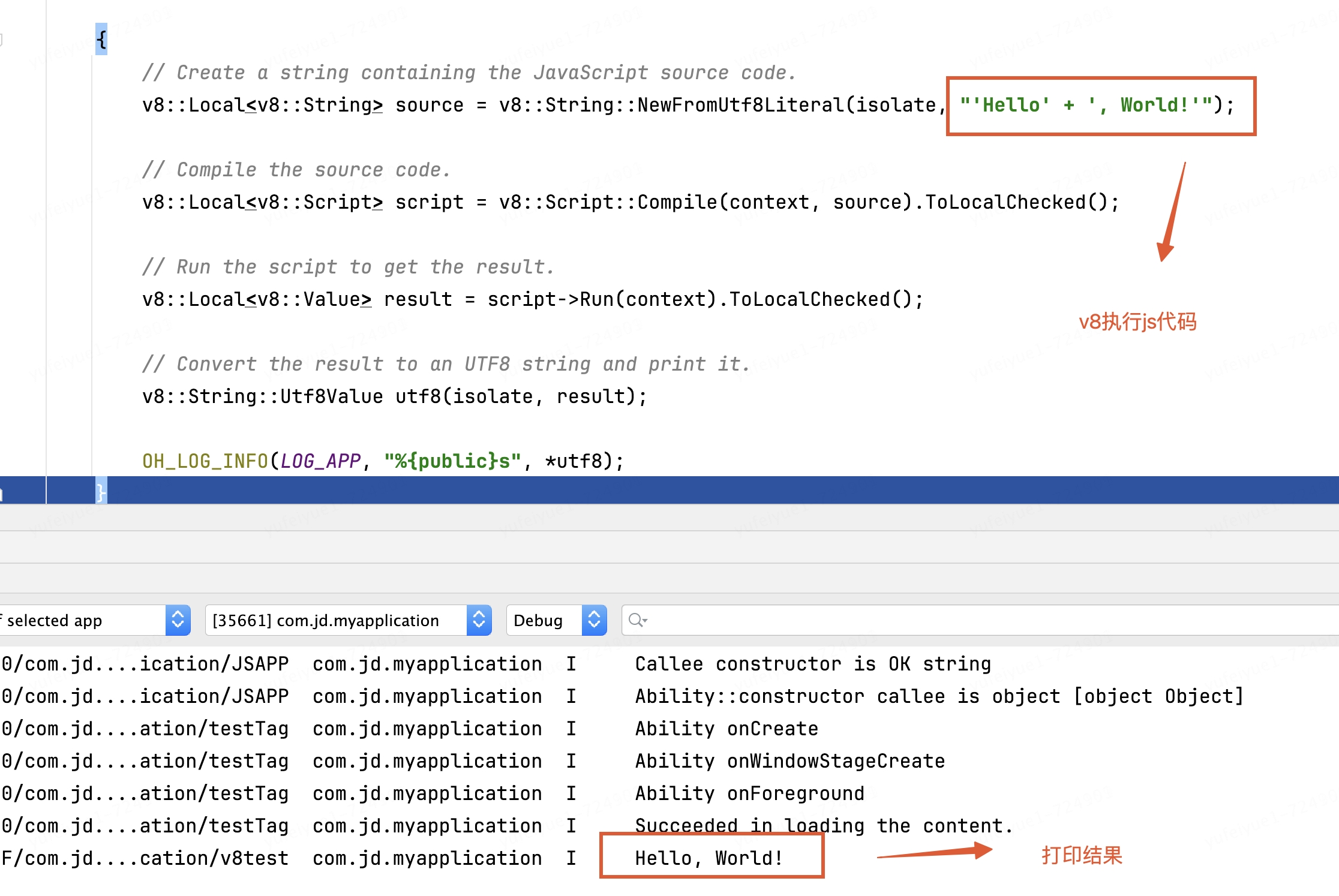
運行查看結果:
八、JS引擎的發展趨勢
隨著物聯網的發展,人們對IOT設備(如智能手表)的使用越來越多。如果希望把JS應用到IOT領域,必然需要從JS引擎角度去進行優化,只是去做上層的框架收效甚微。因為對于IOT硬件來說,CPU、內存、電量都是需要省著點用的,不是每一個智能家電都需要裝一個驍龍855。那怎么可以基于V8引擎進行改造來進一步提升JS的執行性能呢?
?使用TypeScript編程,遵循嚴格的類型化編程規則;
?構建的時候將TypeScript直接編譯為Bytecode,而不是生成JS文件,這樣運行的時候就省去了Parse以及生成Bytecode的過程;
?運行的時候,需要先將Bytecode編譯為對應CPU的匯編代碼;
?由于采用了類型化的編程方式,有利于編譯器優化所生成的匯編代碼,省去了很多額外的操作;
基于V8引擎來實現,技術上應該是可行的:
?將Parser以及Ignition拆分出來,用于構建階段;
?刪掉TurboFan處理JS動態特性的相關代碼;
這樣可以將JS引擎簡化很多,一方面不再需要parse以及生成bytecode,另一方面編譯器不再需要因為JavaScript動態特性做很多額外的工作。因此可以減少CPU、內存以及電量的使用,優化性能,唯一的問題是必須使用嚴格的TS語法進行編程。
Facebook的Hermes差不多就是這么干的,只是它沒有要求用TS編程。
如今鴻蒙原生的ETS引擎Panda也是這么干的,它要求使用ets語法,其實是基于TS只不過做了更加嚴格的類型及語法限制(舍棄了更多的動態特性),進一步提升js的執行性能。
將V8移植到鴻蒙系統是一個巨大的嵌入式范疇工作,涉及交叉編譯、CMake、CLang、Ninja、C++、torque等各種知識,雖然我們經歷了巨大挑戰并掌握了V8移植技術,但出于應用包大小、穩定性、兼容性、維護成本等維度綜合考慮,如果華為系統能內置V8,對Roma框架及業界所有依賴JS虛擬機的跨端框架都是一件意義深遠的事情,通過和華為持續溝通,鴻蒙從API11版本提供了一個內置的JS引擎,它實際上是基于v8的封裝,并提供了一套c-api接口。
如果不想用c-api并且不考慮包大小的問題仍然可以自己編譯一個獨立的v8引擎嵌入APP,直接使用v8面向對象的C++ API。
Roma框架是一個涉及JavaScript、C&C++、Harmony、iOS、Android、Java、Vue、Node、Webpack等眾多領域的綜合解決方案,我們有各個領域優秀的小伙伴共同前行,大家如果想深入了解某個領域的具體實現,可以隨時留言交流~
審核編輯 黃宇
-
javascript
+關注
關注
0文章
516瀏覽量
53850 -
虛擬機
+關注
關注
1文章
914瀏覽量
28158 -
鴻蒙系統
+關注
關注
183文章
2634瀏覽量
66302
發布評論請先 登錄
相關推薦
鴻蒙跨端實踐-JS虛擬機架構實現





 工商網監
工商網監
評論