 奇異摩爾賦能萬卡集群互聯
奇異摩爾賦能萬卡集群互聯
近日,Intel、AMD、博通(Broadcom)、思科(Cisco)、Google、惠普(Hewlett Packard Enterprise,HPE)、Meta和微軟(Microsoft)在內的八家公司宣布他們已經為人工智能數據中心的網絡制定了新的互聯技術UALink(Ultra Accelerator Link),以打破英偉達NVLink技術壟斷的消息受到了廣泛的關注。
“本期奇說芯語Kiwi Talks 將從萬卡集群大模型算力需求的挑戰說起,來解讀這場軍備賽的背后原理…”
智算網絡催生萬卡集群
隨著大模型的持續爆發,其對算力的需求也在迅猛增長,這促使算力集群不斷向萬卡以上的規模演進。這一趨勢不僅代表著計算能力的飛躍,也對網絡提出了前所未有的超高要求。
萬卡集群是指由一萬張及以上的加速卡(包括GPU、TPU及其他專用AI加速芯片)組成的高性能計算系統,主要用于加速人工智能模型的訓練和推理過程。這種集群的構建旨在解決大模型訓練對算力需求的巨大增長問題,尤其是現在模型參數量從百億級、千億級邁向萬億級。大模型的訓練和推理任務需要海量的計算資源和高效的網絡連接。
萬卡級別的算力集群意味著將有數以萬計的高性能計算節點協同工作,它們之間的數據傳輸和同步必須達到毫秒級甚至微秒級的延遲,以確保模型訓練的高效性和準確性。首先,大模型訓練對于GPU之間的互聯通信要求極高,無論是機內GPU的通信還是服務器之間的GPU通信。特別是在模型并行和數據并行等模式下,通信數據量更是達到了百GB級別。因此,網絡必須支持高速互聯協議,并且能夠提供足夠的單端口帶寬和總帶寬。
我們知道PCIe(Peripheral Component Interconnect Express):它是一種計算機總線標準,用于在計算機內部連接各種設備和組件(例如顯卡、存儲設備、擴展卡等)。PCIe接口以串行方式傳輸數據,具有較高的通信帶寬,適用于連接各種設備。然而,由于其基于總線結構,同時連接多個設備時可能會受到帶寬的限制受限于帶寬、延遲、數據傳輸效率,已成為大規模計算集群的互聯瓶頸。
英偉達NVLink的無損網絡護城河
英偉達的NVLink是其開發并推出的一種總線及其通信協議。NVLink采用點對點結構、串列傳輸,用于中央處理器(CPU)與圖形處理器(GPU)之間的連接,也可用于多個圖形處理器之間的相互連接。與PCI Express不同,一個設備可以包含多個NVLink,并且設備之間采用網格網絡而非中心集線器方式進行通信。該協議于2014年3月首次發布,采用專有的高速信號互連技術(NVHS)。目前NVLink已經升級到5.0版本。第五代 NVLink 大幅提高了大型多 GPU 系統的可擴展性。單個 NVIDIA Blackwell Tensor Core GPU 支持多達 18 個 NVLink 100 GB/s 連接,總帶寬可達 1.8 TB/s,比上一代產品提高了兩倍,是 PCIe 5.0 帶寬的 14 倍之多。
NVLink 就是這種“多節點無損網絡”的代表,由一個強大的軟件協議組成,通常通過印在計算機板上的多對導線實現,可以讓處理器以極高的速度收發共享內存池中的數據。NVLink 設計的主要設計目的,就是突破PCIe的屏障,達成GPU-GPU及CPU-GPU的片間高效數據交互。
NVLink雖擁有優秀的性能,但私有協議無法兼容不同來源的產品,這樣的封閉生態已成為行業發展掣肘。受到巨大的需求推動,以及為抵抗這種市場擠壓 ,AMD、谷歌、微軟、英特爾(Intel)、博通(Broadcom)、思科(Cisco)構成聯盟建立一個開放的行業互聯標準即UALink。UALink將使系統OEM、IT專業人員和系統集成商能夠為其人工智能連接數據中心創建一條更易于集成、更具靈活性和可擴展性的途徑。
據官方消息,UALink 1.0規范支持連接多達1024個AI加速器,并允許在一個計算集群(Pod)內,讓接入的GPU等加速器附帶的內存之間實現直接加載和存儲。
奇異摩爾賦能萬卡集群互聯
目前包括各大芯片廠商以及生態內的服務器廠商開始不斷提及甚至對標英偉達NVLink,都想要打破其所造的護城河。整個行業生態包括奇異摩爾在內的企業正在積極探索如何解決滿足集群通信間通訊,片間互聯的高效互聯的解決方案。
目前,奇異摩爾基于自身的互聯技術優勢,較早布局IO Die、Base Die等高性能互聯芯粒,并基于Kiwi-Link統一互聯架構,提供涵蓋集群間、片間、Die間的全鏈路高性能互聯解決方案
GPU片間互聯
奇異摩爾的高性能網絡加速芯粒 – Kiwi NDSA,內建RoCE V2高性能 RDMA (Remote Direct Memory Access) 和數十種卸載/加速引擎,可作為獨立芯粒應用于GPU的傳輸加速器。奇異摩爾自研的全球首創GPU Link Chiplet “NDSA-G2G”,通過RDMA和D2D技術,在芯片間搭建了高速數據交換網絡,可實現近TB/s的超高速數據傳輸,其性能達到全球領先水平,滿足AI芯片對于片間交換不斷增長的需求。
集群間通信
奇異摩爾 Kiwi NDSA SNIC是全球首款支持800G帶寬的RDMA NIC產品,具備極高的集群擴展能力,可以大幅提升集群節點間的交互效率,使得更大規模的集群設計成為可能。除帶寬升級到800G之外,延時也降至納秒級,并支持數十GB的超大規模數據包,性能媲美目前全球標桿ASIC產品。
業界紛紛提出集群通訊互聯的重要性
中國移動研究院網絡與IT技術研究所主任研究員陳佳媛在近期公開演講中提及必須突破GPU卡間互聯技術瓶頸,提高卡間互聯帶寬,提升端口數量以滿足集群算力縱向擴展升級需求;低延遲通信,減少GPU通信跳數,優化數據傳輸路徑。 新華三集團高級副總裁、云與計算存儲產品線總裁徐潤安此前也談到算力互聯。在他看來,過去,大家的目標可能是做更強算力的單顆芯片,現在會從另一個角度努力,怎樣將芯片做成更大集群,同時使得集群的通信效果更高,集群的處理能力更強;
浪潮信息高級副總裁劉軍發表的觀點是,實現更大的算力已經不在芯片,而是在算法層面做創新,比如怎么把算力分布到系統層面上,怎么解決卡間互聯問題,怎么讓更多的GPU高效協同。
寫在最后,數據中心和算力集群是AI的核心,網絡則是它的命脈,它們共同構筑了AI大模型底層網絡基礎設施,實現了數據和智能的無縫傳遞。然而AI芯片性能及軟件生態存在的差距,萬卡集群建設存在芯片間、卡之間、集群間的互聯問題,這些都需要更開放的平臺去持續地解決。
-
英偉達
+關注
關注
22文章
3771瀏覽量
90997 -
算力
+關注
關注
1文章
966瀏覽量
14796 -
奇異摩爾
+關注
關注
0文章
49瀏覽量
3400 -
大模型
+關注
關注
2文章
2427瀏覽量
2648
原文標題:Kiwi Talks | 智算網絡催生萬卡集群,all in通信互聯軍備賽
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
國產千卡GPU集群完成大模型訓練測試,極具高兼容性和穩定性

依托Chiplet&高性能RDMA,奇異摩爾斬獲全國顛覆性技術創新大賽(未來制造領域賽)優勝獎

奇異摩爾分享計算芯片Scale Up片間互聯新途徑

回顧:奇異摩爾@ ISCAS 2024 :聚焦互聯技術與創新實踐

智原科技與奇異摩爾2.5D封裝平臺量產
摩爾線程與羽人科技完成大語言模型訓練測試
從千卡集群卡到萬卡集群,燧原科技打造更好的AI算力底座

奇異摩爾上海總部進駐上海浦東科海大樓

萬卡集群解決大模型訓算力需求,建設面臨哪些挑戰

國產GPU可替代!摩爾線程千卡集群點亮新成就
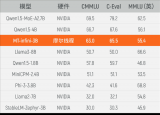
摩爾線程千卡智算集群與滴普企業大模型已完成訓練及推理適配

摩爾線程、無問芯穹合作完成國產全功能GPU千卡集群
摩爾線程與無問芯穹宣布完成基于GPU千卡集群的3B規模大模型實訓
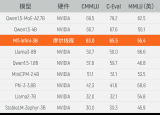
奇異摩爾攜手SEMiBAY Talk 邀您暢談互聯與計算






 工商網監
工商網監
評論