 深度學習或將引領半導體行業變革
深度學習或將引領半導體行業變革
機器學習就是在巨量數據上執行某類復雜運算,并且效率越來越來高,成功的案例也越來越多。現在,機器學習已經從一個相對晦澀的計算機科學概念快速發展成了一種可靠的方法,并且已經被應用在了從人臉識別技術到自動駕駛汽車等各種應用中。
機器學習可以應用于每一種企業職能,并且會影響到經濟體中每個部分的公司。所以無怪乎資金正在大量涌入這一行業。麥肯錫公司的一項調查表明:在 2013 年到 2016 年之間,對人工智能(AI)開發的總投資額增長了 2 倍,達到了 200 億到 300 億美元。其中大多數都來自科技巨頭。這些公司預計機器學習及其衍生的其它 AI 模型將成為它們未來客戶發展的關鍵,就像現在的移動性和網絡化一樣。
機器學習技術為何如此吸引人?因為機器學習和其它形式的 AI 技術可以在很多領域得到廣泛的應用,同時仍然還能產出顯著的利益。Gartner 預計到 2020 年,AI 技術將會在新的業務軟件中實現普及,并且將成為 30% 的 CIO 的前五大投資優先選擇之一。
事實上,這一市場的主要發展推動力來自那些已經站穩腳跟的公司,它們可以將它們的進展應用到其它領域,比如:
-
英偉達已經成為了 GPU 領域的主導者,而 GPU 正是機器學習訓練階段的最主要平臺。到目前為止,大多數已經實現的機器學習開發成果都基于 GPU。
-
英特爾已經推出的 Nervana 神經處理器(Neural Processor),這是一種低延遲、高內存帶寬的芯片,據說是專為深度學習設計打造的。(英特爾在 2016 年收購了 Nervana。)
-
谷歌的張量處理單元(TPU/Tensor Processing Unit)已經占據了機器學習加速器的部分市場。其第二個版本是 Cloud TPU,這是一種更加高性能的 TPU 集群。Cloud TPU 是為機器學習的訓練階段設計的,可與英偉達的 GPU 平臺競爭;而谷歌第一個版本的 TPU 則是該公司為了在自己的服務器上加速語音轉文本應用的推理而開發的一款 ASIC。
機器學習分為兩個階段:訓練階段和推理階段。其中大部分開發工作都集中在第一個階段:訓練階段。這篇文章主要限于數據中心和云計算方面,而且這本身就是一個巨大的市場。Linley Group 的首席分析師 Linley Gwennap 預計數據中心方向的 AI 加速器市場將在 2022 年達到 120 億美元。
Gwennap 說:“在接下來的一兩年時間里,我們將開始看到將會出現遠遠更多針對數據中心和其它設備的選擇。所以世界各地的谷歌和 Facebook 這樣的公司所面臨的問題是:‘我應該繼續設計自己的芯片嗎?或者,如果我能從公開市場獲得同樣好的芯片,我還應該自己設計嗎?’”
推理的發展機會機器學習的第二個階段是推理,基本上就是將學習階段應用于特定應用和細分市場。也就是算法被投入實際應用的階段,而人們預計這方面的發展機會甚至還更大。因此,VC 支持的創業公司正在大量涌現,但其中只有很少一些已經推出了或演示過任何產品;當然,已有的公司也在這一領域大力推進。
ARM 的研究員 Jem Davies 說:“推理和訓練是相當不同的。推理是做各種古怪的事情(比如分揀黃瓜)或有用的事情的階段。這個階段離用戶更近,所以你能看到各種‘有趣的’用例。但也有在手機中執行文本預測(這始于 25 年前)以及人臉檢測和識別的應用。”
推理也是輔助駕駛和自動駕駛的重要組成部分,其中傳感器收集到的數據需要基于機器學習進行預處理。
Cadence 的 Tensilica DSP 組的產品營銷總監 Pulin Desai 說:“推理需要在邊緣進行。在汽車中,你可能會有 20 個圖像傳感器,另外還有雷達和激光雷達(LiDAR),以便提供 360 度的視野。但如果你將一個圖像傳感器放在汽車上,它可能就有 180 度的視野了。那就會需要畸變校正,這是一種圖像處理。”
訓練和推理之間的一個關鍵差異是訓練是以浮點形式完成的,而推理則使用定點形式。DSP 和 FPGA 都是定點形式。
Flex Logix 的 CEO Geoffrey Tate 說:“我們不再只使用 x86 處理器解算所有任務或為特定的負載對硬件進行優化。大多數計算都要在數據中心外完成,所以 FPGA 等器件的作用將不得不改變——盡管隨著音頻和視頻的支持需求擴大,你可能仍將看到傳統架構與新架構的混合使用。我將這全部都看作是加速器。”
在機器學習領域,FPGA 和 eFPGA 玩家正爭先恐后要在推理市場分一杯羹。Linley 估計,在 2022 年總共將會有 17 億臺機器學習客戶端設備。
Achronix 總裁兼 CEO Robert Blake 說:“GPU 在機器學習的學習階段已經得到了很大的重視。但推理方面的市場會更大,而這些產品的關鍵因素將會是成本和功耗。因此,嵌入式解決方案將會成為這些領域的矚目焦點。”
ARM 的 Davies 同意這個觀點。他說功率預算保持在 2W 到 3W的范圍內,而電池技術的發展一直以來都相對平穩。鋰電池的改進幅度一直都在每年 4% 到 6% 的范圍內。考慮到所有這些情況,計算性能將會需要幾個數量級的增長。
那將需要不同的架構,還要理解應該在哪里完成哪些處理。
Rambus 的杰出發明家 Steven Woo 說:“我們看到有各種各樣的 AI、神經網絡芯片和內核。在更高層面上看,它們是將信息融合在一起。這方面有很多探索正在進行。你可以看到,現在有很多公司在尋找主要市場,以便圍繞其構建基礎設施。你可以看到手機的數量達到了數十億。這些都在驅動新的封裝基礎設施發展。你可以看到汽車領域背后有很多資金支持。物聯網(IoT)的潛力也很明顯,但難在尋找共同點。而在神經網絡和機器學習方面,似乎每周都有新算法出現,這使得我們難以開發出單個一個架構。這就是人們對 FPGA 和 DSP 的興趣如此之大的原因。”
定義機器學習公司交替地使用機器學習、深度學習、人工智能和神經網絡這些術語并沒有什么幫助。盡管這些術語的差別很微妙,但共有的思想是:使用足夠多的實時數據,計算機可以給多種不同的場景加權,并根據這些預定義的權重響應給出最好的選擇。這個加權過程是訓練和推理過程的一部分,對機器學習而言至關重要。
深度學習是機器學習的一種——具有更多的層,這些層執行著不同類型的分析,并最終能得到更加完整的解決方案,但完成深度學習訓練也需要更多計算資源。這兩者往往都涉及到神經網絡,即圍繞信息節點創建網狀的連接,這種連接有一點類似于人腦中細胞之間的網狀連接。人工智能則是一個涵蓋性術語,很多人對此都有不同的看法:從 IBM 的 Watson 到電影《2001 太空漫游》中的 HAL。但主要是指無需明確編程就能自己學習不同行為的設備或程序。
誰在使用機器學習在以客戶為中心的應用中,機器學習已經非常常見,其中包括預測銷量、尋找客戶流失的跡象、通過交互式語音響應或聊天機器人提供客戶服務、谷歌翻譯那樣的消費者應用等等。
Facebook 使用了三種深度學習應用來過濾上傳的內容,比如:一種用于識別上傳的圖片中的人臉并進行標注,一種用于檢查帖子中的仇恨言論或其它客觀內容,一種用于定向廣告。
英偉達首席科學家兼研究部門高級副總裁 Bill Dally 說:“讓我驚訝的是深度學習革命的速度是如此之快。在過去三年中,各種應用幾乎在一夜之間就完成了從傳統方法向深度學習方法的轉變。這不需要在軟件上進行大量投入;你找到應用,再訓練網絡,然后就完成了。這在一些領域里已經得到了普及,但對于每一個已經轉向神經網絡的應用,還可能還會有多次轉變。”
據麥肯錫的研究:盡管科技行業內已經采用 AI 實現或改進了其它服務或增加了新服務給客戶,但在科技行業之外,對 AI 技術的采用還大都是實驗性的。在受調查的 3000 家公司中,僅有 20% 表示它們在業務中的重要部分使用了與 AI 相關的技術。麥肯錫調查了 160 種 AI 用例,發現其中僅有 12% 實現了 AI 的商業部署。
換個角度看,也就是說有 88% 的公司仍然還沒有實現 AI 的商業部署,所以其中還有巨大的機會。谷歌和百度等科技巨頭則相反,它們在 2016 年中投入了 200 億到 300 億美元,其中 90% 投入了研發,10% 用于收購。
深度學習是下一個大事件據西門子旗下 Mentor 的傳感器融合部門首席工程師 Nizar Sallem 說,深度學習可能不僅在客戶服務和分析上表現優良,而且也是用于自動駕駛汽車所需的即時感知、決策和控制的主要候選系統。
Sallem 說:“機器學習最重要的應用是基于交通規則和汽車當時所在位置的預期理解汽車周圍的環境、道路上不同的行為者和背景。它必須確定你的行為應該會怎樣,還要確定什么時候允許你打破規則以避開危險或保護汽車中的人類。”
市場預測不管 AI 技術可能將會有多么能干,它目前仍還處于起步發展階段。據 Tractica 的一份報告,主要的服務提供商還仍然是已有的科技公司,最賺錢的還仍然是面向消費者的服務。其中包括谷歌的語音轉文本和翻譯服務以及來自亞馬遜、Facebook、百度等公司的消費者交互/客戶服務應用。這份報告估計 2016 年 AI 驅動的消費者服務價值 19 億美元,并將在 2017 年年底增長至 27 億美元。
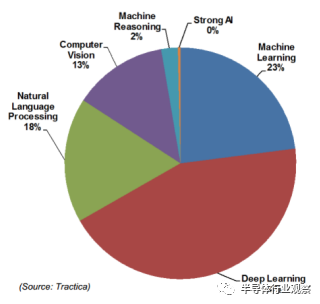
圖 1:不同 AI 技術的收入情況,來自 Tractica
Tractica 估計 AI 的整個市場(包括硬件、軟件和服務)將會在 2025 年增長至 421 億美元。
圖 2:AI 在不同方面(軟件、服務、硬件)的收入情況,來自 Tractica
機器學習即服務(MLaaS)是一個不同的類別——亞馬遜、IBM 和微軟占據了其中 73%。據 Transparency Market Research(TMR)在今年 4 月份的一份報告稱,這個市場將從 2016 年的 10.7 億美元增長至 2025 年的 199 億美元。
據 Tractica 稱,目前大多數使用了機器學習的服務都是面向消費者的——這個類別中包括谷歌的翻譯和語音轉文本應用,這些應用為其客戶級 TPU 提供了概念證明。
客戶變成競爭對手深度學習的出現也凸顯出了半導體行業與其最大的客戶之間的日益復雜的關系——尤其是谷歌等超大規模數據中心的所有者,這些公司的規模非常大,足以開發設計它們自己的服務器和芯片。
多年以來,芯片公司一直都在開發或定制滿足特定的云客戶的需求的芯片。以英特爾為例,它為微軟開發了 FPGA 深度學習加速器,還為阿里巴巴的云客戶開發了基于 FPGA 的應用加速器。英特爾還邀請了 Facebook 來幫助設計英特爾推出的 Nervana 神經處理器的封裝以及即將到來的用于深度學習的 “Lake Crest” ASIC。
谷歌已經宣布了其它芯片,比如新聞報道的該公司為其 Pixel 2 手機開發了一款機器學習協處理器,這也是其第一款移動芯片。谷歌也已經開發出了 Titan,這是一款連接到服務器的微控制器,可以確保服務器在板上出現故障、損壞或感染了惡意軟件時不會啟動。
谷歌在解釋其對第一款 TPU 的投資時說 TPU 可以“為機器學習在單位功耗下的性能帶來一個數量級的優化”并能將谷歌的機器學習應用向前推進大概七年時間。第一款 TPU 的設計目的只是加速運行機器學習模型的推理的普通服務器,而不是為了一開始的模型訓練。因此,它們不會與英偉達或英特爾的機器學習訓練產品直接競爭。
當谷歌在 5 月份宣布了 Cloud TPU 時,聽起來似乎就將與英特爾和英偉達的產品進行更加直接的競爭了。
谷歌描述說,每個 Cloud TPU 都有 180 teraflops 的浮點運算性能,將 4 個 TPU 封裝成一個 TPU Pod 可以實現總共 11.5 petaflops 的性能。這種配置似乎是為了與英偉達備受關注的 DGX-1 “超級計算機”競爭而設計的。DGX-1 包含 8 個頂級的 Tesla V100 芯片,并聲稱總體最高吞吐量達 1 petaFLOP。
云上的競爭Dally 說:“谷歌和其它一些公司沒使用加速或只使用 TPU 取得了一些早期的成功,但有些網絡是很容易訓練的;標準的圖像搜索就很簡單。但對于需要處理越來越多信號的訓練(處理圖像和視頻流)以及對于每周都要重新訓練網絡的人或重點關注訓練過程的人,GPU 要高效得多。”
據 Cadence 的 IP 組的前 CTO Chris Rowen 說,問題是來自谷歌的一款新處理器是否足以奪走其它公司的客戶,答案可能是“不能”。任何云提供商都必須支持不止一種架構,所以使用了深度學習的數據中心將會是 CPU、GPU、ASIC、FPGA 和各種技術的 IP 的混合。Rowen 現已創立了 Cognite Ventures 公司,為神經網絡、物聯網和自主式嵌入式系統領域的創業公司提供資金和建議。
Rowen 說,某些訓練負載也可以轉移,從而讓客戶端設備也能具備數十億個推理引擎。在這一領域,很多公司肯定都有機會;但是對于在數據中心服務器上進行的機器學習訓練,新進入的公司很難取代已經站穩腳跟的玩家。
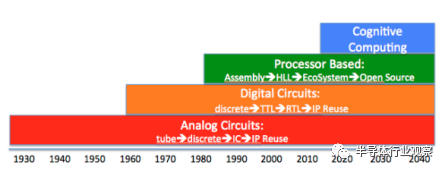
圖 3:認知計算的演進,來自 Cognite Ventures
Rowen 說:“我們希望有所選擇,理由很充分,但選擇也非常多,而且英特爾、高通和其它公司也都在關注。不能因為你有一個用于智能手機的神經網絡,就假設你的生產制造能超越三星,這種假設可不好。”
-
人臉識別
+關注
關注
76文章
4011瀏覽量
81867 -
英偉達
+關注
關注
22文章
3771瀏覽量
91001 -
自動駕駛
+關注
關注
784文章
13787瀏覽量
166407
原文標題:機器學習將引領半導體產業進入新階段
文章出處:【微信號:icbank,微信公眾號:icbank】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
意法半導體如何引領汽車電子重塑未來
可驗證AI開啟EDA新時代,引領半導體產業變革

變革性的半導體IP,如何驅動未來?

如何減少半導體行業溫室氣體排放
意法半導體加速AI時代業務重組,重塑半導體制造未來
紐約與荷蘭建立半導體聯盟
日本半導體設備出口激增:中國需求引領行業復蘇
深迪半導體榮獲“2023-2024半導體行業/MEMS芯片創新引領企業”獎

半導體發展的四個時代
FPGA在深度學習應用中或將取代GPU
半導體發展的四個時代
納微十載征程,引領功率半導體行業發展
鈮酸鋰芯片與精密劃片機:科技突破引領半導體制造新潮流






 工商網監
工商網監
評論