 在深度學習中為什么要正則化輸入?
在深度學習中為什么要正則化輸入?
本文作者原創,轉載請注明出處。
今天我們來講解一下為什么要正則化輸入(也叫標準化輸入)呢?
正則化輸入其實就是論文中說的局部相應歸一化,它最早由Krizhevsky和Hinton在關于ImageNet的論文里面使用的一種數據標準化方法。
在實際應用中,我們可能會遇到各維度數據或者各特征在空間中的分布差別很大。就如同下圖

這給訓練增加了難度,我們可以看一下如果是這樣的數據我們會得到一個什么樣的梯度下降圖。
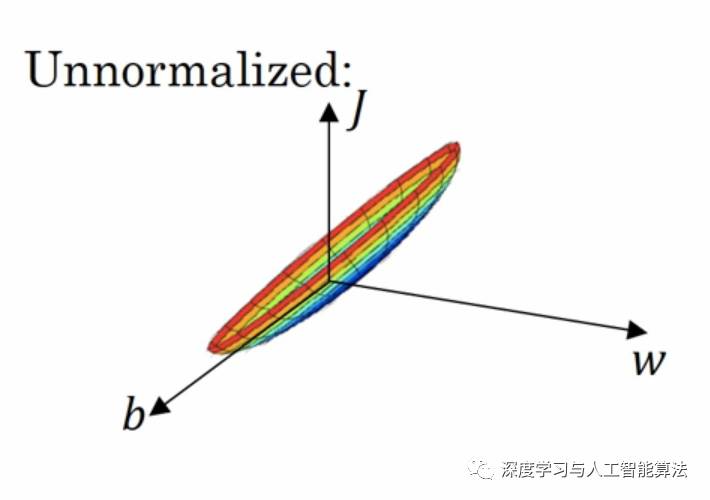
很明顯,這是一個狹長的立體圖形,在進行反向傳播的過程中,如果在兩端開始梯度下降的話,整個過程就變得很漫長。所以為了解決這種情況,我們使用了正則化輸入去解決。下面就是正則化輸入的計算公式:
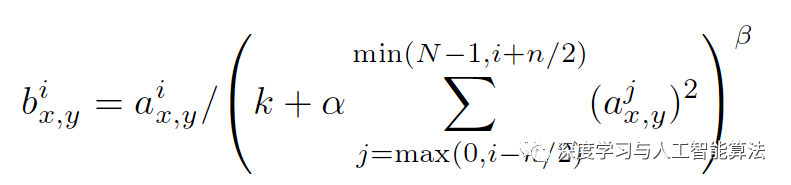
按照這個公式來計算的話,我們的梯度下降就變成這樣了。
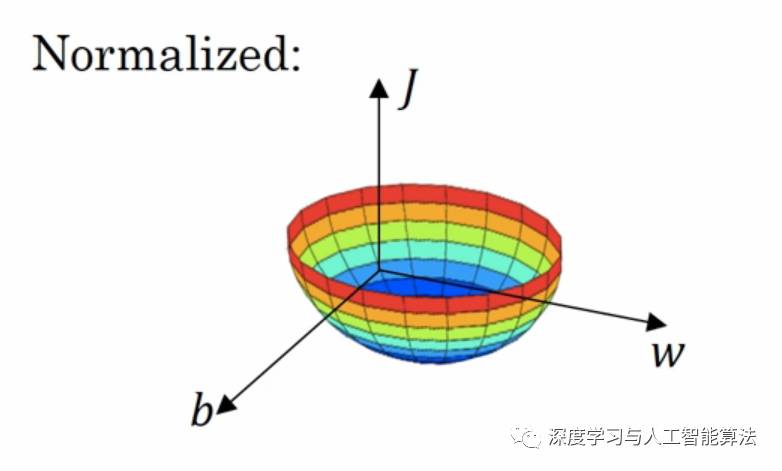
這樣的話我們無論是從哪一個點開始梯度下降,得到的效果是一樣的。
那我們再來看一下在Tensorflow中是怎么實現的。Tensorflow中的API是tf.nn.lrn,別名也叫tf.nn.local_response_normalization,這兩個是一個東西。再來看一下函數是怎么定義的:
local_response_normalization( input, depth_radius=5, bias=1, alpha=1, beta=0.5, name=None)
里面那么多參數,那分別又是代表什么呢?首先,input是我們要輸入的張量,depth_radius就是上面公式中的n/2,其實這個變量名為什么叫depth_radius呢?radius不是半徑嗎?與半徑又有什么關系呢,我等下再來講解為什么。接著,bias是偏移量,alpha就是公式中的α,beat就是公式中的β。
其實啊,LRN也可以看作是“每個像素”在零值化后除以“半徑以內的其他對應像素的平方和”,這個半徑就是給定的變量depth_radius的值。
那我們用代碼來看一下效果怎么樣:
import numpy as npimport tensorflow as tfa = 2 * np.ones([2, 2, 2, 3])print(a)b = tf.nn.local_response_normalization(a, 1, 0, 1, 1)with tf.Session() as sess: print(sess.run(b))
輸出的結果a是:

輸出的結果b是:

-
深度學習
+關注
關注
73文章
5504瀏覽量
121220 -
正則化輸入
+關注
關注
0文章
1瀏覽量
849
原文標題:技術詳解 | 為什么要正則化輸入?
文章出處:【微信號:gh_a204797f977b,微信公眾號:深度學習實戰】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
改善深層神經網絡--超參數優化、batch正則化和程序框架 學習總結
一種基于機器學習的建筑物分割掩模自動正則化和多邊形化方法
基于快速自編碼的正則化極限學習機





 工商網監
工商網監
評論