 谷歌工程師機器學習干貨:從表現力、可訓練性和泛化三方面詳解
谷歌工程師機器學習干貨:從表現力、可訓練性和泛化三方面詳解
本文是谷歌大腦工程師Eric Jiang的博文,結合當前監督、無監督和強化學習進展,談了他衡量機器學習研究工作的框架:①表現力(Expressivity)、②可訓練性(Trainability)和/或③泛化能力(Generalization)。這篇文章可能是本年度最佳機器學習技術及研究總結之一,值得學習和參考。
當我閱讀機器學習論文時,我會問自己,這篇論文的貢獻是否屬于:1)表現力(Expressivity)、2)可訓練性(Trainability),和/或3)泛化能力(Generalization)。我從Google Brain的同事Jascha Sohl-Dickstein那里學到了這個分類,并且在這篇文章中介紹了這個術語。我發現這種分類有效地考慮了個別研究論文(特別是在理論方面)是如何將AI研究的子領域(例如機器人、生成模型、NLP)聯系在一起,成為一個大的圖景的。
在這篇博文中,我將討論這些概念如何與當前(截止2017年11月)的監督學習、無監督學習和強化學習的機器學習研究相結合。我認為泛化由“弱泛化”和“強泛化”兩大類構成,我將分別討論它們。這個表格總結了我對事情的看法:
我非常感謝Jascha Sohl-Dickstein和Ben Poole為這篇文章提供的反饋和編輯,還感謝Marcin Moczulski對RNN可訓練性給出的有益討論。
這篇文章涵蓋了廣泛的研究,在很大程度上以我比較個人的觀點在評判。因此,需要強調,文中任何事實錯誤都是我自己的,并不反映我的同事和校對者的意見。如果你有想討論的問題和建議,請隨時在評論中提供反饋意見或發送電子郵件——我寫這篇文章也是為了學習。
表現力:這個模型可以進行什么計算?表現力(Expressivity)體現了一個可以被參數函數(例如神經網絡)計算的函數的復雜性。深度神經網絡隨著深度的增加,表現力呈指數級增長,這意味著今天大家正在研究的大多數監督、無監督和強化學習問題,用中等規模的神經網絡就可以充分表現[2]。其中一個證據就是深度神經網絡能夠記憶非常大的數據集。
神經網絡可以表現各種各樣的東西:連續的、復雜的、離散的,甚至是隨機的變量。隨著過去幾年對生成建模和貝葉斯深度學習的研究,深度神經網絡已經被用來構造概率神經網絡,并且產生了令人難以置信的生成建模結果。
生成建模的最新突破表明了神經網絡強大的表現力:神經網絡可以輸出與真實數據幾乎無法區分的極其復雜的數據流形(音頻、圖像)。以下是NVIDIA研究人員提出的最近GAN架構的輸出:
這個結果還不算完美(注意扭曲的背景),但是距離最終目標也不遠了。類似地,在音頻合成任務中,最新的WaveNet模型生成的音頻樣本,聽起來與真實的人說話無異。
無監督學習不限于生成式建模。有些研究人員,比如Yann LeCun,將無監督學習更名為“預測學習”,模型可以推斷過去、估算現在或預測未來。然而,由于許多無監督學習集中在預測極其復雜的聯合分布(過去或未來的圖像、音頻),我認為生成建模是衡量無監督領域表現力一個相當好的基準。
神經網絡似乎也是足以表現強化學習的。很小的網絡(2個卷積層和2個全連接層)就足夠強大,能夠解決Atari和Mujoco控制任務(雖然其可訓練性還有許多不足之處,這個我們稍后會說到)。
單獨看,表現力(expressivity)本身并不是一個很有趣的問題,我們可以通過在網絡中增加更多的層、更多的連通性和其他一些方法來增強表現力。我們現在面臨的挑戰是,在控制訓練難度不會太高的前提下,使神經網絡充分表現出足夠多的訓練和測試數據集。例如,就算深度全連接網絡有足夠的能力來記憶訓練集,但似乎還是需要二維卷積來使圖像分類模型能夠泛化。
表現力是最容易處理的問題(增加更多層就好!),但同時也是最神秘的:我們沒有很好的方法來衡量一個給定的任務需要多少(和什么樣的)表現力。什么樣的問題需要比我們今天使用的神經網絡更大數量級的神經網絡?為什么這些問題需要這么大量的計算?目前的神經網絡是否有足夠的表現力來實現類似于人類的智能?解決泛化問題是否需要表現力超級強大的模型?
大腦的神經元數量(1e11)比大型神經網絡(Inception-ResNet-V2具有大約25e6的ReLU單元)的要多很多個數量級。而且,ReLU單元根本無法比擬人類神經元的復雜度。一個單一的生物神經元及其樹突、軸突和各種神經遞質,具有令人難以置信的表現力。蝗蟲在一個神經元中實現了碰撞檢測系統,比我們建造的任何無人機系統都飛得更好。這種表現力來自哪里?要實現人類智能,神經網絡需要多強的表現力?
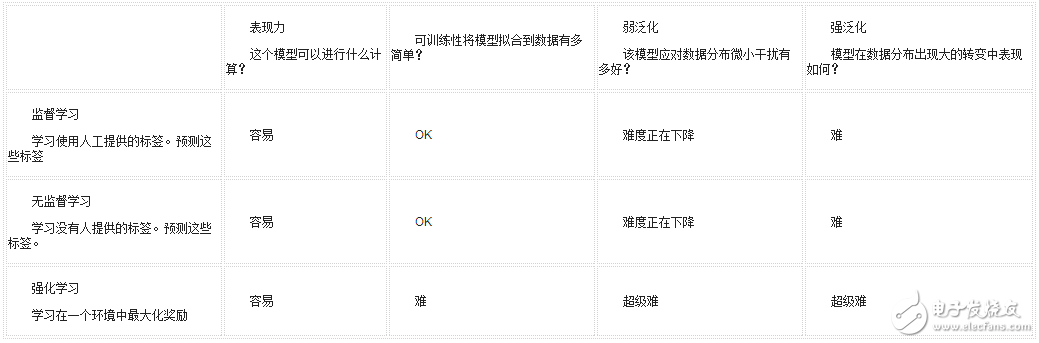
可訓練性:給定一個充分表達的模型空間,我們能找到一個好的模型嗎?機器學習模型是任何能夠從數據中學習到函數的計算機程序。在“學習”期間,我們從一個可能非常巨大的模型空間中,尋找一個比較好的,能夠利用數據中的知識做出決策的模型。這個搜索過程通常被定義為解決模型空間的優化問題。
優化的幾種類型
一種常見的方法,特別是在深度學習中,是定義一些標量度量來評估模型的“優點”。然后使用數值優化技術,將這些“優點”最大化(或“最小化不良”)。
一個具體的例子:最小化平均交叉熵誤差是訓練神經網絡分類圖像的標準方法。這樣做的目的是,當模型x數據集在交叉熵損失最小的時候,它做的就是我們真正想要的,比如以一定的精度正確地分類圖像,并在測試圖像上進行召回。通常,評估指標是不能直接優化的(最顯而易見的原因是我們無法訪問測試數據集),而像訓練集上的交叉熵這樣的替代函數可以。
尋找好的模型(也即訓練)最終等同于優化——事實就是如此!但是……優化的目標有時難以確定。監督學習中,一個典型場景是圖像下采樣(down-sampling),在這種情況下,很難定義一個標量的量,讓這個量與人類從特定的下采樣算法中感知“perceptual loss”的方式完全一致。類似的,超分辨率和圖像合成也很困難,因為我們很難將“優點/好”作為最大化的目標。想象一下,寫一個函數,判斷一張圖像“逼真(photoreal)”的程度!實際上,關于如何衡量生成模型(用于圖像,音頻)的質量,爭論一直在激化。
近年來,解決這個問題最流行的技術是一種協同適應方法(co-adaptation approach),這種方法將最優化問題轉換為求解兩個非平穩分布之間的平衡點,而這些非平穩分布是協同演化的(in tandem)[3]。用一個直觀的比喻來解釋為什么這樣做是“自然的”,可以想一想掠食者物種和被捕獵的物種之間的生態進化過程。起初,掠食者變聰明了,所以可以有效地捕獲獵物。然后,獵物也變得更聰明,從而逃避捕獵者。這樣,物種協同進化,最終的結果是兩個物種都變得更加聰明。
生成對抗網絡也按照類似的原理工作,通過這種方法,避開了明確定義感知損失目標(perceptual loss objectives)。同樣,強化學習中的自我對弈(competitive self-play)也運用這個原則來學習大量豐富的行為動作。雖然優化目標現在已經被隱含地指定,但它仍然是一個優化問題,機器學習從業者可以重新使用熟悉的工具,如深度神經網絡和SGD。
演化策略通常將優化視為一個模擬的過程(optimization-as-a-simulation)。用戶在模型總體(a population of models)上指定一個動態系統,并且在模擬的每個時間步長,根據動態系統的規則更新這個總體。模型可能會也可能不會相互影響。模擬進行下去,希望系統的動力學最終能夠誘導這個總體匯聚成“好的模型”。
要了解強化學習背景下的演化策略(ES),你可以參閱David Ha的“A Visual Guide to Evolution Strategies),“參考文獻和進一步閱讀”部分非常棒!
當前研究及工作總結
前饋網絡和監督學習中遇到的“直接”目標,其可訓練性(Trainability)基本上已經解決了(我從經驗上得出這個結論,不是理論上的總結)。2015年發布的一些突破性工作(Batch Norm、ResNets、Good Init),今天已經被廣泛用于前饋網絡的訓練。實際上,具有數百層的深度網絡現在可以將大規模分類數據集的訓練誤差最小化為零。
另一方面,RNN仍然非常棘手,但研究界正在取得很大的進展,將LSTM放入一個復雜的機器人策略中并期望它“正常工作”已經不再是一件瘋狂的事情。想一想也挺不可思議,就在2014年,還沒有多少人對RNN的可訓練性抱有信心,在過去的十年中,有很多工作表明RNN十分難以訓練。有證據表明,大量不同的RNN架構,其表現力是同等的,任何性能上的差異都是由于某些架構比其他架構更容易優化導致的[4]。
在無監督學習中,模型的輸出通常(但不總是)更大——例如,1024 x 1024像素,巨大的語音和文本序列。因此很不幸,無監督模型也更難以訓練訓練。
2017年的一個重大突破,就是GAN現在更容易訓練了。最常見的改進方法,是對原來Jensen-Shannon散度目標的簡單修改:最小二乘法,absolute deviation with margin,還有Wasserstein距離。NVIDIA最近的工作擴展了基于Wasserstein的GAN,使得模型對BatchNorm參數、架構選擇等各種超參數的敏感度降低。穩定性對于實際和工業應用來說是非常重要的——正因為有了穩定性,才能使人相信這種方法將與未來的研究思路或應用兼容。總之,這些結果令人興奮,因為它們表明生成器神經網絡具有足夠的表現力生成正確的圖像,阻止它們的瓶頸只是可訓練性的問題。可訓練性可能仍然是一個瓶頸——不幸的是,對于神經網絡而言,我們很難判斷究竟是模型的表現力不夠,還是我們沒有把它訓練好。
由于高方差的蒙特卡洛梯度估計量,神經網絡中,潛在離散變量推理(latent discrete variable inference)也很難訓練。然而近年來,從GAN到語言建模,到記憶增強神經網絡,再到強化學習,各種架構都開始重新得到關注。從表現力的角度看,離散表示非常有用,而且我們現在也能夠相當可靠地進行訓練,這是非常好的。
不幸的是,深度強化學習在純粹的可訓練性方面仍然相當落后,更不用說泛化方面的能力了。對于那些時間步長超過1的環境,我們正在尋找一個模型,在推理時進行優化。有一個內部優化的過程,其中模型推理得出最優的控制,而外部的一個優化循環則只使用智能體看到的數據庫,學習這個最佳模型。
最近,我為連續機器人控制任務增加了一個額外的維度,讓我的強化學習算法性能從>80%下降到了10%。強化學習不僅訓練很難,而且也不穩定!因為優化隨機性太強,我們甚至不能用不同的隨機種子獲得相同的結果,因此我們的策略是報告多次試驗中的獎勵曲線分布,使用不同的隨機種子。相同的算法,由于部署不同,在不同的環境中表現也不同,因此文獻中報道的RL分數時要用批判性的眼光去審視。
強化學習中的可訓練性問題仍然沒有得到解決,我們仍然不能稍微擴展問題一點點,然后期望相同的學習過程10次都做同樣的事情。
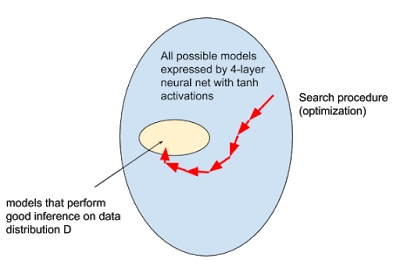
如果我們把RL看作一個純粹的優化問題(之后再去擔心泛化和復雜的任務),情況仍然十分棘手。假設有一個環境,只有在episode結束的時候才能得到一個稀疏的獎勵(例如,照看孩子,在父母回家之后得到報酬)。動作的數量(和環境的相應結果)隨著事件的持續時間呈指數增長,但是這些動作序列中只有少數與成功對應。
因此,在模型優化范圍中的任何點估計策略梯度,需要在獲得有用的學習信號之前,在動作空間中大量的樣本。這就好比要計算概率分布的蒙特卡洛expectation,但(在所有動作序列上)質量卻集中在delta分布上。當proposal分布與獎勵分布之間沒有重疊時,無論收集多少樣本,有限樣本蒙特卡洛策略梯度估計根本無法工作。
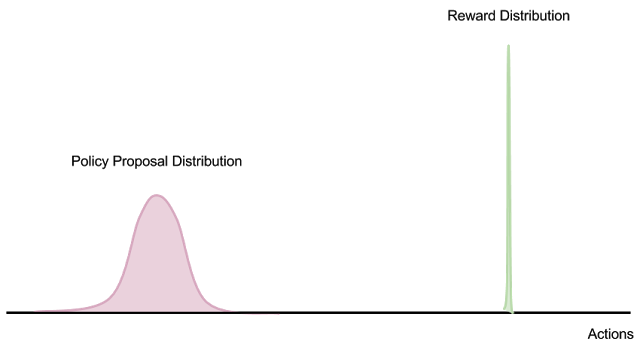
此外,如果數據分布是非平穩的(如帶有replay buffer的off-policy學習算法的情況),那么收集“不良數據”會在外部優化過程中引入不穩定的反饋環路。
從優化的角度而不是蒙特卡洛估計的角度看,也是相同的:在狀態空間中沒有任何先驗(例如對世界的理解或向智能體提供的明確指示),整個優化看起來就像“瑞士奶酪”——一個個convex optima“小孔”周圍是大量的參數空間平臺(plateaus),在這里策略梯度毫無用處。這意味著整個模型空間基本上沒有信息(因為學習信號在整個模型空間中是非常均勻的,非零區域非常小)。
如果不開發出可以學習的良好表征(representation),我們還不如就用隨機種子和隨機策略循環,直到發現一個剛剛好落在這些奶酪洞里的好模型。事實上,強化學習基線表明,我們的優化格局可能看起來就是這樣。
我相信,從純粹的優化角度來看,像Atari和Mujoco這樣的RL基準測試并沒有真正推動機器學習的極限,只是為了解決單一的單策略(monolithic policy)問題,可以說是在相當無菌的環境下優化性能。這種情況下,模型“泛化”的選擇壓力很小,使得問題成為一個純粹的優化問題,而不是真正的困難ML問題。
并不是說我喜歡用泛化能力來將強化學習的可訓練性問題復雜化(肯定不容易調試!),但是我認為學習理解環境和理解任務是強化學習處理現實世界機器人問題的唯一途徑。
將這個與監督學習和無監督學習相比,無論我們處于模型搜索空間的哪個位置,我們都可以方便地獲得學習信號。Minibatch梯度的proposal分布與梯度分布非零重疊。如果我們使用小批量大小為1的SGD,那么用有用的學習信號對轉換進行采樣的概率最差為1/N,其中N是數據集的大小。我們可以通過簡單地拋出大量計算和數據來解決問題,從而使我們的方法成為一個好的解決方案。此外,提升較低層的感知泛化,通過在低級特征上的“bootstrapping”,可能實際上具有減少方差的效果。
為了解決高維和復雜的RL問題,在處理數值優化問題之前,必須考慮泛化和一般的感知理解。我們需要達到每個數據點為RL算法提供非零比特數的點,并且在任務非常復雜時(沒有收集指數級的更多數據),可以輕松實現重要性采樣梯度。只有這樣,才能合理地假設我們能夠成功地通過暴力計算解決問題。
從示范學習(demonstration),模仿學習(imitation learning),逆向強化學習(inverse reinforcement learning)以及與自然語言指令的交互中學習,可能會提供一些方法來快速將起始策略(starting policy)引入到獲取某些學習信號的點上,或者以這樣一種方式來塑造搜索空間。例如,環境提供0的獎勵,但是觀察產生一些有助于模型的規劃模塊得出歸納偏向(inductive biases)的信息。
總而言之,在可訓練性這個問題上:監督學習已經很容易了;無監督學習還很難,但我們正在努力;強化學習則是非常糟糕。
泛化:機器學習本身的核心泛化是三個問題中最深刻的問題,也是機器學習本身的核心。簡單說,泛化就是在訓練數據集上訓練好的模型,在測試數據集上表現如何。
在討論泛化時有兩種不同的場景:1)訓練和測試數據是從相同的分布中抽取的(我們只需要從訓練數據中學習這個分布),或者2)訓練和測試數據來自不同的分布(我們需要從訓練集推廣到測試分布)。這兩種情況分別對應于我下文所說的(1)“弱泛化”和(2)“強泛化”。這種對泛化進行分類的方式也可以被稱為“內插與外推”(interpolation vs. extrapolation),或者“模型的健壯性vs對數據的理解”(robustness vs. understanding)。
弱泛化:兩種情況,模型對數據分布的小擾動表現有多好?
在“弱泛化”中,我們通常假設訓練和測試數據樣本是從相同的分布中抽取的。然而在現實世界中,即使在大樣本范圍內,訓練和測試分布之間幾乎總是有一些差異。
這些差異可能來自傳感器噪聲,環境光線條件的變化,物體的逐漸磨損和撕裂,照明條件的變化。另一種情況是,對抗樣本可能會產生差異(differences can be generated by an adversary)。因為對抗干擾以人類視覺幾乎不能察覺,所以我們可以將對抗樣本歸入“從相同分布中抽取”。
因此,在實踐中將“弱泛化”作為評估訓練分布的“擾動”是有用的:
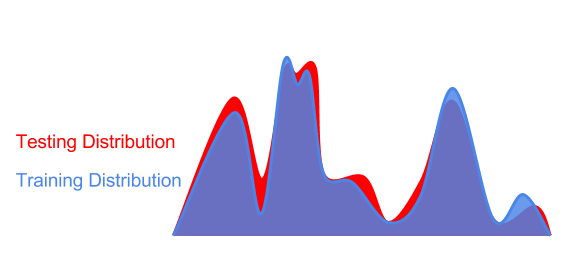
測試數據分布的干擾也可能會導致優化的干擾(最低點是最好的)。
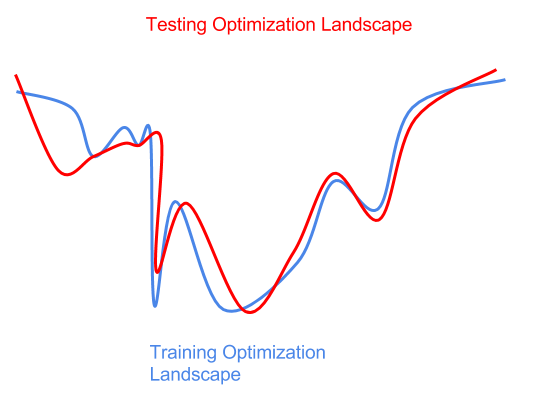
事實上,我們預先不知道測試分布干擾為優化帶來了一些困難。如果我們在優化訓練環境(藍色曲線左側的sharp全局最小值)方面過于激進,那么我們就會得到一個對于測試數據(紅色曲線上的sharp局部最小值)次優的模型。在這里,我們對訓練分布或訓練數據樣本進行了過擬合,并沒有泛化到干擾的測試分布。
“正則化”是我們用來防止過擬合的技術。由于我們沒有任何關于測試擾動的先驗信息,所以通常我們所能做的最好的事情就是嘗試訓練訓練分布的隨機擾動,希望這些擾動覆蓋測試分布。隨機梯度下降,dropout,權重噪音,激活噪音,數據增強,這些都是深度學習中常用的正則化算子。在強化學習中,隨機化模擬參數使得訓練更加健壯。張馳原在他ICLR 2017演講中指出,正規化是“任何使訓練變得更加困難的事情”(相對于“限制模型容量”的傳統觀點)。基本上,讓事情更難優化,就能提高泛化性能。
這真是令人不安——我們的“泛化”方法相當粗糙,相當于“optimizer lobotomy”。我們做的基本上就是調整一下優化器,然后希望它對訓練過程的干擾剛剛好防止過擬合。而且,提高模型的可訓練性讓你以犧牲可泛化性為代價!用這種方式看待(弱)泛化問題,確實讓開展可訓練性研究變得復雜。
但是,如果更好的優化器容易造成過擬合,那么我們如何解釋為什么一些優化器似乎減少了訓練和測試的誤差?現實情況是,任何優化方法和優化器的組合,都在:1)找到一個更好的模型區域和2)過擬合到一個特定的解決方案之間達到平衡,而我們沒有很好的方法來控制這種平衡。
弱泛化最具挑戰性的測試可能是對抗性攻擊,在對抗性攻擊中,擾動來自一個對手“adversary”,它會對數據點進行最糟糕的干擾,使你的模型以較高的概率表現不佳。我們仍然沒有能夠很好應對對抗性攻擊的深度學習方法,但我的直覺是對抗性攻擊最終是可以被解決的[5]。
在理論工作方面,有一些研究者在利用信息理論探究神經網絡在訓練過程中,模型從“記憶”數據到“壓縮”數據。這個理論正在興起,雖然是否有效還存在學術爭論。從“記憶”和“壓縮”在直覺上很令人信服,因此這方面值得我們保持關注。
強泛化:自然流形(Natural Manifold)
在“強泛化”的測試中,模型在測試中使用的數據來自與訓練數據完全不同的分布,但是,這些數據的底層manifold(或生成過程)是相同的。
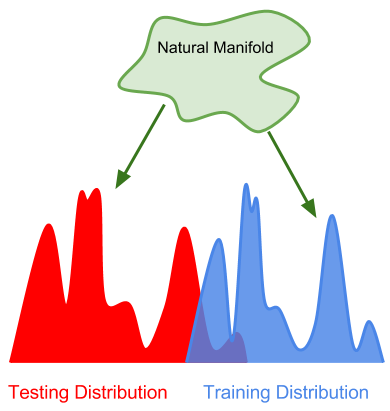
世界上可觀測數據的空間可以被描述為一個非常高維的,不斷變化的“自然流形”(natural manifold)。雖然流行非常巨大,但它也是高度結構化的。例如,我們所觀察到的所有數據都遵循萬有引力這樣的物理規律,物體不會出現在物體中,等等。
強泛化可以被認為是這種“超級流形”在多大程度上被一個特定的模型所捕獲,這個模型只在流形的數據點的十進制采樣上被訓練。需要注意的是,圖像分類器并不需要發現麥克斯韋方程組,它只需要了解與流形數據相一致的現實即可。
在ImageNet上訓練的現代分類模型在強泛化方面可以說是OK的——在ImageNet上訓練的模型確實可以理解像邊緣、輪廓和物體這樣的原理,這也是ImageNet預訓練模型受歡迎的原因。然而,這類模型仍然有大量的改善空間:在ImageNet上訓練的分類器還不是普遍適用的,少數據學習問題仍然沒有得到解決,并且仍然容易受到對抗樣本攻擊。很明顯,我們的模型現在還不能理解它們正在看什么,但這是一個開始 。
類似于弱泛化,測試分布可以以對抗訓練和測試分布之間最大差異的方式進行對抗采樣。AlphaGo Zero是我最喜歡的例子:在測試的時候,它觀察來自人類玩家的數據,與其訓練分布完全不同(它以前從未“看見”過人類)。而且,人類正在利用自己所有的智慧,主動把AlphaGo帶到訓練數據中未被發現的領域。盡管AlphaGo并沒有明確地理解抽象數學、對手心理學或“綠色”意味著什么,但它清楚地理解了如何這個世界一個狹窄的領域中勝過人類玩家。如果一個人工智能系統對一個熟練的人類對手具有健壯性(robust against a skilled human adversary),那么我認為它具有足夠強的泛化能力。
可惜的是,強化學習研究在很大程度上忽視了強泛化的問題。大多數基準都是靜態環境,很少有感知豐富性(例如,類人機器人不了解它周圍的世界或它自己的身體看起來像什么,除了一些與獎勵機制有關的關節位置)。
我真的相信解決泛化是解決強化學習可訓練性的關鍵。我們的學習系統對世界“了解”越多,獲得學習信號的能力就越強,也許這樣需要的樣本數量也就越少。這就是為什么少數據學習(few-shot learning),模仿學習,學會學習(learning-to-learn)很重要:它使我們擺脫了差異性大、信息量低的暴力解決方案。
我認為,要實現更強有力的泛化,需要做到兩件事情:
首先,我們需要從觀察和實驗中積極推導世界基本規律的模型。符號推理和因果推理似乎是成熟的研究主題,但任何一種無監督的學習都可能有所幫助。這讓我想起人類通過使用邏輯推理系統(數學),推導宇宙物理定律來理解天體運動的事情。有趣的是,在哥白尼革命之前,人類最初可能依賴于貝葉斯啟發式方法(“迷信”),在我們發現經典力學后,這些“貝葉斯”模型就被拋棄了。
我們基于模型的機器學習方法(試圖“預測”環境方面的模型)現在還處于“前哥白尼時期”,即它們只是基于非常淺的統計迷信進行內插(Interpolation),而不是提出深刻的、一般的原理來解釋和推斷可能在數百萬光年遠的地方或未來許多時間步的數據。請注意,人類確實不需要對概率理論有一個牢固的把握來推導出確定性的天體力學,而這就引出了一個問題——如果沒有明確的統計框架,是否有辦法進行機器學習和因果推斷。
大幅降低復雜性的一種方法是使我們的學習系統更具適應性。我們需要超越僅僅優化以靜態方式預測或行動的模型,我們需要優化那些可以實時思考、記憶和學習的模型。
其次,我們需要在這個問題上投入足夠多樣化的數據,促使模型去開發抽象的表征。只有環境足夠豐富,正確的表征才能被開發出來(雖然AlphaGo Zero提出了一個問題,就是智能體真正需要體驗的自然流形有多少)。如果沒有這些限制,這個問題就沒有明確規定,我們偶然發現正確的解決方案的機會是零。
我不知道三體文明(參見《三體》一書)演變到如此高的技術水平,是不是因為他們的生存依賴于他們對復雜的天體力學的物理理解。也許我們也需要在我們的Mujoco&Bullet環境中引入一些天體運動:)
注釋[1] 有些研究領域不適合表現力(Expressivity)、可訓練性和泛化能力這一框架。例如,試圖理解為什么一個模型提供了一個特定答案的解釋性研究(interpretability research)。在一些高風險領域(比如醫學、執法)工作的ML客戶和政策制定者需要了解這一點,這也可以闡明泛化問題:如果我們發現模型提供的診斷方式與與人類醫學專業人士會得出這些結論有很大的不同,這可能意味著模型在推導過程中存在邊緣情況(edge case),不能泛化。確定模型是否學到了正確的東西,比減少測試錯誤更加重要!差分隱私(Differential privacy)是對ML模型的另一個約束。但鑒于超出本文范疇,這里就不多講了。
[2] 簡單解釋一下:一個大小為N的全連接層,后跟一個ReLU非線性,可以將一個向量空間切割成N個分段線性塊。添加第二個ReLU層,進一步將空間細分為N個以上的塊,在輸入空間中產生N^2個分段線性區域,3個層就是N^3。詳細分析請參閱Raghu et al. 2017。
[3] 這有時被稱為多級優化問題。然而,這意味著一個“外部”和“內部”優化循環,而適應可能在同一時間發生。例如,異步通信的單個機器上的并行進程,或者在生態系統中不斷協同進化的物種。在這些情況下,沒有明確的“外部”和“內部”優化循環。
[4] seq2seq with attention實現了SOTA,但是我懷疑它的優點是可訓練性,而不是表現力或泛化性。也許seq2seq without attention在正確初始化的情況下,也可以做得一樣好。
[5] 這里提供一個對抗對抗性攻擊的方法,雖然并沒有解決強泛化問題,那就是使計算對抗干擾極其昂貴。模型和數據部分是黑箱。在推理期間每次調用模型時,從訓練好的模型中隨機挑選一個模型,并將該模型提供給對手,而不告訴他們他們得到了哪個模型。模型彼此獨立訓練,甚至可以采用不同的架構。這使得計算有限差分梯度很難,因為f(x + dx) - f(x)可以具有任意高的方差。此外,連續梯度計算之間的梯度仍將具有較高的方差,因為可以對不同的模型對進行采樣。另一種改進方法是使用多模太數據(視頻、多視圖multi-view,圖像+聲音),導致在保持輸入的一致性的同時,很難干擾輸入。
-
谷歌
+關注
關注
27文章
6228瀏覽量
107755 -
機器學習
+關注
關注
66文章
8497瀏覽量
134246
原文標題:【谷歌工程師機器學習干貨總結】從表現力、可訓練性和泛化三方面看2017年進展
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【分享】arm技術總結為三方面能力
硬件工程師需要知道的DFM可制造性設計
從分層、布局及布線三方面,詳解EMC的PCB設計技術
什么是機器學習? 機器學習基礎入門
從三方面考慮AI安全
從三方面解讀電子工程師是如何維修電子電路板的?
工信部將從三方面著手加大新能源汽車的監管力度
教育機器人公司獲百萬元天使輪融資 將主要用于以下三方面
小尋兒童手表完成適配及相關測試,三方面能力有顯著改善
watchOS 9將在三方面帶來新功能






 工商網監
工商網監
評論