 支持向量機(SVM)的定義、分類及工作流程圖詳解
支持向量機(SVM)的定義、分類及工作流程圖詳解
關于SVM
可以做線性分類、非線性分類、線性回歸等,相比邏輯回歸、線性回歸、決策樹等模型(非神經網絡)功效最好
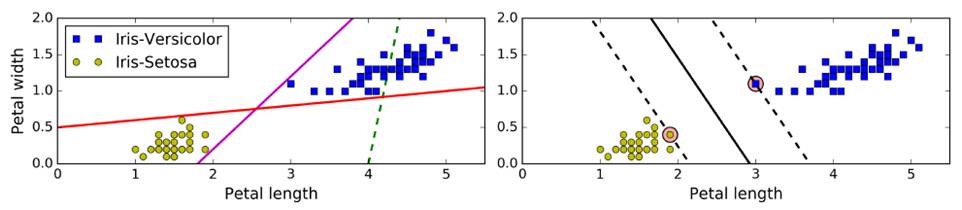
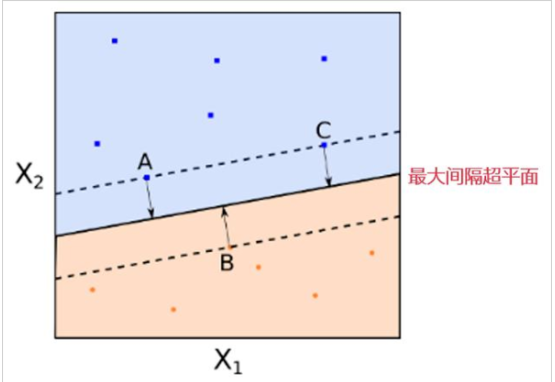
傳統線性分類:選出兩堆數據的質心,并做中垂線(準確性低)——上圖左
SVM:擬合的不是一條線,而是兩條平行線,且這兩條平行線寬度盡量大,主要關注距離車道近的邊緣數據點(支撐向量support vector),即large margin classification——上圖右
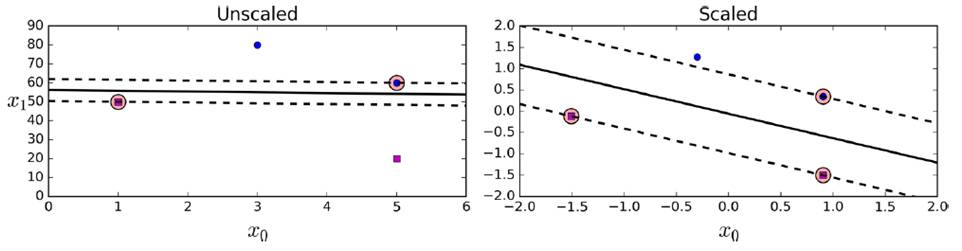
使用前,需要對數據集做一個scaling,以做出更好的決策邊界(decision boundary)
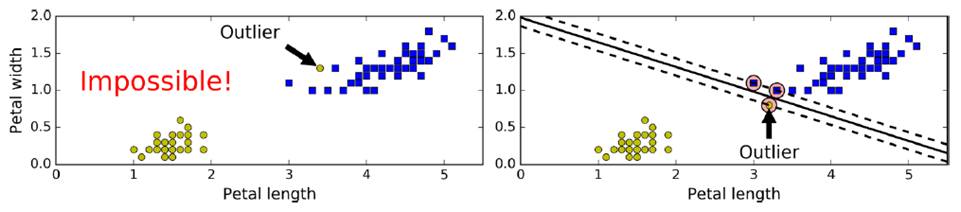
但需要容忍一些點跨越分割界限,提高泛化性,即softmax classification
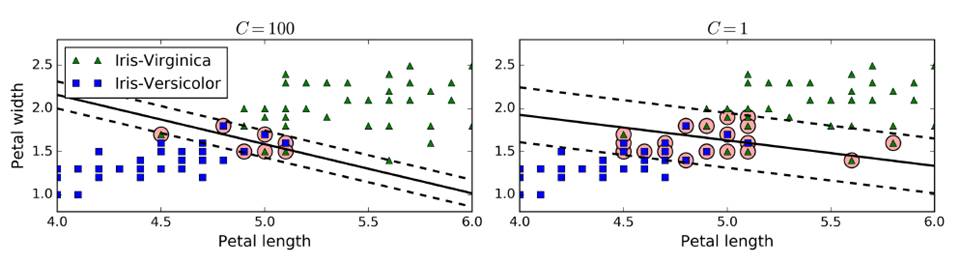
在sklearn中,有一個超參數c,控制模型復雜度,c越大,容忍度越小,c越小,容忍度越高。c添加一個新的正則量,可以控制SVM泛化能力,防止過擬合。(一般使用gradsearch)
SVM特有損失函數Hinge Loss
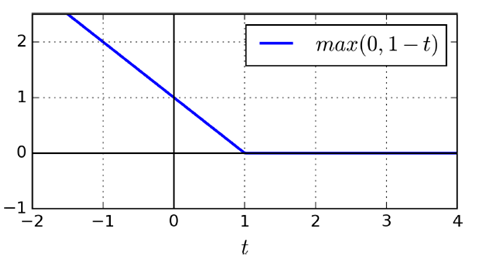
(liblinear庫,不支持kernel函數,但是相對簡單,復雜度O(m*n))
同SVM特點吻合,僅考慮落在分類面附近和越過分類面到對方領域的向量,給于一個線性懲罰(l1),或者平方項(l2)
importnumpyasnpfromsklearnimportdatasetsfromsklearn.pipelineimportPipelinefromsklearn.preprocessingimportStandardScalerfromsklearn.svmimportLinearSVCiris = datasets.load_iris()X = iris["data"][:,(2,3)]y = (iris["target"]==2).astype(np.float64)svm_clf = Pipeline(( ("scaler",StandardScaler()), ("Linear_svc",LinearSVC(C=1,loss="hinge")), ))svm_clf.fit(X,y)print(svm_clf.predit([[5.5,1.7]]))
對于nonlinear數據的分類
有兩種方法,構造高維特征,構造相似度特征
使用高維空間特征(即kernel的思想),將數據平方、三次方。。映射到高維空間上
fromsklearn.preprocessingimportPolynomialFeaturespolynomial_svm_clf = Pipeline(( ("poly_features", PolynomialFeatures(degree=3)), ("scaler", StandardScaler()), ("svm_clf", LinearSVC(C=10, loss="hinge")) ))polynomial_svm_clf.fit(X, y)
這種kernel trick可以極大地簡化模型,不需要顯示的處理高維特征,可以計算出比較復雜的情況
但模型復雜度越強,過擬合風險越大
SVC(基于libsvm庫,支持kernel函數,但是相對復雜,不能用太大規模數據,復雜度O(m^2 *n)-O(m^3 *n))
可以直接使用SVC(coef0:高次與低次權重)
fromsklearn.svmimportSVCpoly_kernel_svm_clf = Pipeline(( ("scaler", StandardScaler()), ("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5)) ))poly_kernel_svm_clf.fit(X, y)

添加相似度特征(similarity features)
例如,下圖分別創造x1,x2兩點的高斯分布,再創建新的坐標系統,計算高斯距離(Gaussian RBF Kernel徑向基函數)

gamma(γ)控制高斯曲線形狀胖瘦,數據點之間的距離發揮更強作用
rbf_kernel_svm_clf= Pipeline(( ("scaler", StandardScaler()), ("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001)) ))rbf_kernel_svm_clf.fit(X, y)

如下是不同gamma和C的取值影響
SGDClassifier(支持海量數據,時間復雜度O(m*n))
SVM Regression(SVM回歸)
盡量讓所用instance都fit到車道上,車道寬度使用超參數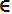 控制,越大越寬
控制,越大越寬
使用LinearSVR
fromsklearn.svmimportLinearSVRsvm_reg = LinearSVR(epsilon=1.5)svm_reg.fit(X, y)
使用SVR
fromsklearn.svmimportSVRsvm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)svm_poly_reg.fit(X, y)
數學原理

w通過控制h傾斜的角度,控制車道的寬度,越小越寬,并且使得違反分類的數據點更少
hard margin linear SVM
優化目標: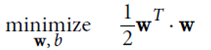 ,并且保證
,并且保證
soft margin linear SVM
增加一個新的松弛變量(slack variable) ,起正則化作用
,起正則化作用
優化目標: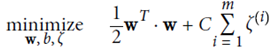 ,并且保證
,并且保證
放寬條件,即使有個別實例違反條件,也懲罰不大
使用拉格朗日乘子法進行計算,α是松弛項后的結果
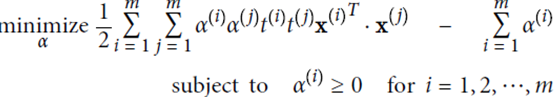
計算結果: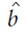 取平均值
取平均值
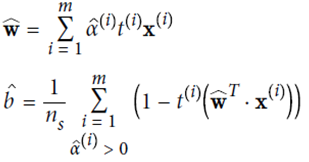
KernelizedSVM
由于
故可先在低位空間里做點積計算,再映射到高維空間中。
下列公式表示,在高維空間計算可用kernel trick方式,直接在低維上面計算
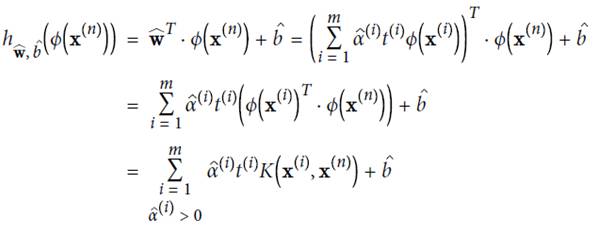
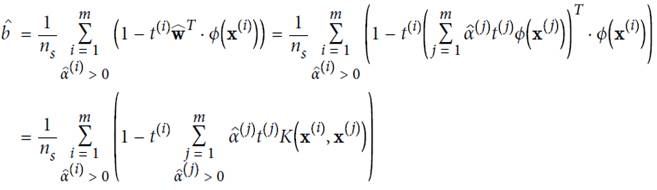

幾個常見的kernal及其function

-
SVM
+關注
關注
0文章
154瀏覽量
32437 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567
原文標題:【機器學習】支持向量機(SVM)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
軟件測試工作流程圖
基于支持向量機SVM引入雷達故障預診斷
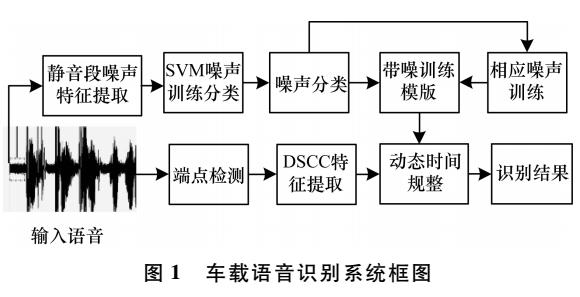
基于支持向量機的噪聲分類與補償
人工智能之機器學習Analogizer算法-支持向量機(SVM)
什么是支持向量機 什么是支持向量





 工商網監
工商網監
評論