") 給Java同仁單點(diǎn)的AI"開(kāi)胃菜"--搭建一個(gè)自己的本地問(wèn)答系統(tǒng)
給Java同仁單點(diǎn)的AI"開(kāi)胃菜"--搭建一個(gè)自己的本地問(wèn)答系統(tǒng)
這是我參與創(chuàng)作者計(jì)劃的第1篇文章
大家好,因?yàn)閷?duì)AI大模型很感興趣,相信很多兄弟們跟我一樣,所以最近花時(shí)間了解了一些,有一些總結(jié) 分享給大家,希望對(duì)各位有所幫助;
本文主要是目標(biāo)是 講解如何在本地 搭建一個(gè)簡(jiǎn)易的AI問(wèn)答系統(tǒng),主要用java來(lái)實(shí)現(xiàn),也有一些簡(jiǎn)單的python知識(shí);網(wǎng)上很多例子都是以 ChatGPT來(lái)講解的,但因?yàn)樗鼘?duì)國(guó)內(nèi)訪問(wèn)有限制,OpeAi連接太麻煩,又要虛擬賬號(hào)注冊(cè)賬號(hào)啥的,第一步就勸退了,所以選擇了 llama和qwen替代,但是原理都是一樣的;
?
相關(guān)概念了解:
(一)大語(yǔ)言模型 LLM
大型語(yǔ)言模型(LLM,Large Language Models),是近年來(lái)自然語(yǔ)言處理(NLP)領(lǐng)域的重要進(jìn)展。這些模型由于其龐大的規(guī)模和復(fù)雜性,在處理和生成自然語(yǔ)言方面展現(xiàn)了前所未有的能力。
?
關(guān)于LLM的一些關(guān)鍵點(diǎn):
1.定義:
?大模型通常指的是擁有大量參數(shù)的深度學(xué)習(xí)模型,這些模型可能包含數(shù)十億至數(shù)萬(wàn)億的參數(shù)。
?LLM是大模型的一個(gè)子類(lèi),專(zhuān)門(mén)設(shè)計(jì)用于處理和理解自然語(yǔ)言,它們能夠模仿人類(lèi)語(yǔ)言的生成和理解過(guò)程。
2.架構(gòu):
?LLM通常基于Transformer架構(gòu),這是一種使用自注意力機(jī)制(self-attention mechanism)的序列模型,它由多個(gè)編碼器和解碼器層組成,每個(gè)層包含多頭自注意力機(jī)制和前饋神經(jīng)網(wǎng)絡(luò)。
3.訓(xùn)練:
?這些模型在大規(guī)模文本數(shù)據(jù)集上進(jìn)行訓(xùn)練,這使得它們能夠?qū)W習(xí)到語(yǔ)言的復(fù)雜結(jié)構(gòu),包括語(yǔ)法、語(yǔ)義、上下文關(guān)系等。
?訓(xùn)練過(guò)程通常涉及大量的計(jì)算資源,包括GPU集群和海量的數(shù)據(jù)存儲(chǔ)。
4.應(yīng)用:
?LLM可以應(yīng)用于各種自然語(yǔ)言處理任務(wù),包括但不限于文本生成、問(wèn)答、翻譯、摘要、對(duì)話系統(tǒng)等。
?它們還展示了在few-shot和zero-shot學(xué)習(xí)場(chǎng)景下的能力,即在少量或沒(méi)有額外訓(xùn)練數(shù)據(jù)的情況下,模型能夠理解和執(zhí)行新任務(wù)。
5.發(fā)展趨勢(shì):
?學(xué)術(shù)研究和工業(yè)界都在探索LLM的邊界,包括如何更有效地訓(xùn)練這些模型,以及如何使它們?cè)诓煌I(lǐng)域和任務(wù)中更具適應(yīng)性。
?開(kāi)源和閉源模型的競(jìng)爭(zhēng)也在加劇,推動(dòng)了模型的持續(xù)創(chuàng)新和改進(jìn)。
6.學(xué)習(xí)路徑:
?對(duì)于那些希望深入了解LLM的人來(lái)說(shuō),可以從學(xué)習(xí)基本的Transformer模型開(kāi)始,然后逐漸深入到更復(fù)雜的模型,如GPT系列、BERT、LLaMA、Alpaca等,國(guó)內(nèi)的有 qwen(通義千問(wèn))、文心一言、訊飛星火、華為盤(pán)古、言犀大模型(ChatJd)等 。
7.社區(qū)資源:
?Hugging Face等平臺(tái)提供了大量的開(kāi)源模型和工具,可以幫助研究人員和開(kāi)發(fā)者快速上手和應(yīng)用LLM。
LLM的出現(xiàn)標(biāo)志著NLP領(lǐng)域的一個(gè)新時(shí)代,它們不僅在學(xué)術(shù)研究中產(chǎn)生了深遠(yuǎn)的影響,也在商業(yè)應(yīng)用中展現(xiàn)出了巨大的潛力。
?
(二)Embedding
在自然語(yǔ)言處理(NLP)和機(jī)器學(xué)習(xí)領(lǐng)域中,"embedding" 是一種將文本數(shù)據(jù)轉(zhuǎn)換成數(shù)值向量的技術(shù)。這種技術(shù)將單詞、短語(yǔ)、句子甚至文檔映射到多維空間中的點(diǎn),使得這些點(diǎn)在數(shù)學(xué)上能夠表示它們?cè)谡Z(yǔ)義上的相似性或差異。
?
Embeddings 可以由預(yù)訓(xùn)練模型生成,也可以在特定任務(wù)中訓(xùn)練得到。常見(jiàn)的 embedding 方法包括:
1. Word2Vec:由 Google 提出,通過(guò)上下文預(yù)測(cè)目標(biāo)詞(CBOW)或通過(guò)目標(biāo)詞預(yù)測(cè)上下文(Skip-gram)來(lái)訓(xùn)練詞向量。
2. GloVe:全球向量(Global Vectors for Word Representation),通過(guò)統(tǒng)計(jì)詞共現(xiàn)矩陣來(lái)優(yōu)化詞向量。
3. FastText:Facebook 研究院提出的一種方法,它基于詞 n-gram 來(lái)構(gòu)建詞向量,適用于稀少詞和未見(jiàn)過(guò)的詞。
4. BERT:基于 Transformer 架構(gòu)的預(yù)訓(xùn)練模型,可以生成上下文相關(guān)的詞嵌入,即“動(dòng)態(tài)”詞嵌入。
5. ELMo:利用雙向 LSTM 語(yǔ)言模型生成的詞嵌入,同樣考慮了上下文信息。
6. Sentence Transformers:這是 BERT 的一種變體,專(zhuān)門(mén)設(shè)計(jì)用于生成句子級(jí)別的嵌入。
?
Embeddings 的主要優(yōu)點(diǎn)在于它們能夠捕捉詞匯之間的復(fù)雜關(guān)系,如同義詞、反義詞以及詞義的細(xì)微差別。此外,它們還能夠處理多義詞問(wèn)題,即一個(gè)詞在不同上下文中可能有不同的含義。
?
在實(shí)際應(yīng)用中,embeddings 被廣泛用于多種 NLP 任務(wù),如文本分類(lèi)、情感分析、命名實(shí)體識(shí)別、機(jī)器翻譯、問(wèn)答系統(tǒng)等。通過(guò)使用 embeddings,機(jī)器學(xué)習(xí)模型能夠理解和處理自然語(yǔ)言數(shù)據(jù),從而做出更加準(zhǔn)確和有意義的預(yù)測(cè)或決策。
?
(三)向量數(shù)據(jù)庫(kù)
向量數(shù)據(jù)庫(kù)是一種專(zhuān)門(mén)設(shè)計(jì)用于存儲(chǔ)和查詢(xún)高維向量數(shù)據(jù)的數(shù)據(jù)庫(kù)系統(tǒng)。這種類(lèi)型的數(shù)據(jù)庫(kù)在處理非結(jié)構(gòu)化數(shù)據(jù),如圖像、文本、音頻和視頻的高效查詢(xún)和相似性搜索方面表現(xiàn)出色。與傳統(tǒng)的數(shù)據(jù)庫(kù)管理系統(tǒng)(DBMS)不同,向量數(shù)據(jù)庫(kù)優(yōu)化了對(duì)高維空間中向量的存儲(chǔ)、索引和檢索操作。
以下是向量數(shù)據(jù)庫(kù)的一些關(guān)鍵特點(diǎn)和功能:
1.高維向量存儲(chǔ): 向量數(shù)據(jù)庫(kù)能夠高效地存儲(chǔ)和管理大量的高維向量數(shù)據(jù),這些向量通常是由深度學(xué)習(xí)模型(如BERT、ResNet等)從原始數(shù)據(jù)中提取的特征。
2.相似性搜索: 它們提供了快速的近似最近鄰(Approximate Nearest Neighbor, ANN)搜索,能夠在高維空間中找到與查詢(xún)向量最相似的向量集合。
3.向量索引: 使用特殊的數(shù)據(jù)結(jié)構(gòu),如樹(shù)形結(jié)構(gòu)(如KD樹(shù))、哈希表、圖結(jié)構(gòu)或量化方法,以加速向量的檢索過(guò)程。
4.混合查詢(xún)能力: 許多向量數(shù)據(jù)庫(kù)還支持結(jié)合向量查詢(xún)和結(jié)構(gòu)化數(shù)據(jù)查詢(xún),這意味著除了向量相似性搜索之外,還可以進(jìn)行SQL風(fēng)格的查詢(xún)來(lái)篩選結(jié)構(gòu)化屬性。
5.擴(kuò)展性和容錯(cuò)性: 高效的數(shù)據(jù)分布和復(fù)制策略,使得向量數(shù)據(jù)庫(kù)可以水平擴(kuò)展,以處理海量數(shù)據(jù),并且具備數(shù)據(jù)冗余和故障恢復(fù)能力。
6.實(shí)時(shí)更新: 允許動(dòng)態(tài)添加和刪除向量數(shù)據(jù),支持實(shí)時(shí)更新,這對(duì)于不斷變化的數(shù)據(jù)集尤其重要。
7.云原生設(shè)計(jì): 許多現(xiàn)代向量數(shù)據(jù)庫(kù)采用云原生架構(gòu),可以輕松部署在云端,利用云服務(wù)的彈性計(jì)算資源。
向量數(shù)據(jù)庫(kù)在多個(gè)領(lǐng)域得到應(yīng)用,包括推薦系統(tǒng)、圖像和視頻檢索、自然語(yǔ)言處理(NLP)以及生物信息學(xué)。一些知名的向量數(shù)據(jù)庫(kù)項(xiàng)目包括FAISS(由Facebook AI Research開(kāi)發(fā))、Pinecone、Weaviate、Qdrant、Milvus等。
?
(四)RAG
文章題目中的 "智能問(wèn)答" 其實(shí)專(zhuān)業(yè)術(shù)語(yǔ) 叫 RAG;
在大模型(尤其是大型語(yǔ)言模型,LLMs)中,RAG 指的是“Retrieval-Augmented Generation”,即檢索增強(qiáng)生成。這是一種結(jié)合了 檢索(Retrieval)和生成(Generation)技術(shù)的人工智能方法, 主要用于增強(qiáng)語(yǔ)言模型在處理需要外部知識(shí)或?qū)崟r(shí)信息的任務(wù)時(shí)的表現(xiàn);
?
RAG 是 "Retrieval-Augmented Generation" 的縮寫(xiě),即檢索增強(qiáng)生成。這是一種結(jié)合了檢索(Retrieval)和生成(Generation)兩種技術(shù)的人工智能模型架構(gòu)。RAG 最初由 Facebook AI 在 2020 年提出,其核心思想是在生成式模型中加入一個(gè)檢索組件,以便在生成過(guò)程中利用外部知識(shí)庫(kù)中的相關(guān)文檔或片段。
在傳統(tǒng)的生成模型中,如基于Transformer的模型,輸出完全依賴(lài)于模型的內(nèi)部知識(shí),這通常是在大規(guī)模語(yǔ)料庫(kù)上進(jìn)行預(yù)訓(xùn)練得到的。然而,這些模型可能無(wú)法包含所有特定領(lǐng)域或最新更新的信息,尤其是在處理專(zhuān)業(yè)性較強(qiáng)或時(shí)效性較高的問(wèn)題時(shí)。
RAG 架構(gòu)通過(guò)從外部知識(shí)源檢索相關(guān)信息來(lái)增強(qiáng)生成過(guò)程。當(dāng)模型需要生成響應(yīng)時(shí),它會(huì)首先查詢(xún)一個(gè)文檔集合或知識(shí)圖譜,找到與輸入相關(guān)的上下文信息,然后將這些信息與原始輸入一起送入生成模型,從而產(chǎn)生更加準(zhǔn)確和豐富的內(nèi)容。
?
1.檢索(Retrieval):
?當(dāng)模型接收到一個(gè)輸入或查詢(xún)時(shí),RAG 首先從外部知識(shí)庫(kù)或數(shù)據(jù)源中檢索相關(guān)信息。 這通常涉及到使用向量數(shù)據(jù)庫(kù)和近似最近鄰搜索算法來(lái)找到與輸入最相關(guān)的文檔片段或知識(shí)條目。
1.生成(Generation):
?一旦檢索到相關(guān)的信息,這些信息會(huì)被整合到生成模型的輸入中,作為上下文或提示(prompt)。 這樣,當(dāng)模型生成輸出時(shí),它就能利用這些額外的信息來(lái)提供更準(zhǔn)確、更詳細(xì)和更相關(guān)的響應(yīng)。
?
基本流程:
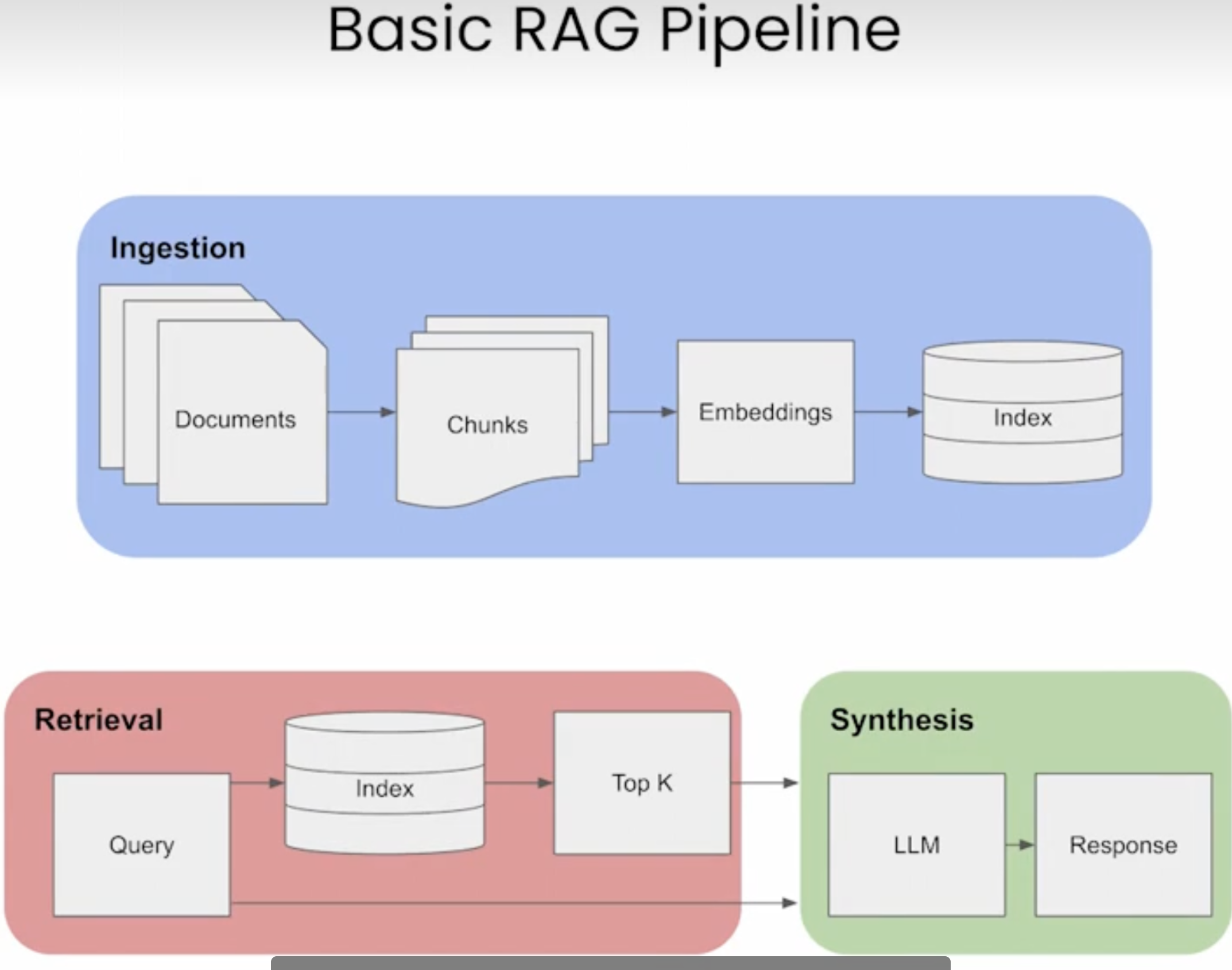
?
RAG的優(yōu)勢(shì):
1.減少知識(shí)局限性:LLMs 通常受限于其訓(xùn)練數(shù)據(jù),而 RAG 可以讓模型訪問(wèn)實(shí)時(shí)或最新的信息,從而克服這一限制。
2.減少幻覺(jué):幻覺(jué)是指模型生成不存在于其訓(xùn)練數(shù)據(jù)中的不真實(shí)信息。RAG 通過(guò)提供事實(shí)依據(jù),可以減少這種現(xiàn)象。
3.提高安全性:RAG 可以通過(guò)控制檢索的范圍和類(lèi)型,避免模型生成潛在的有害或敏感信息。
4.增強(qiáng)領(lǐng)域?qū)I(yè)性:對(duì)于特定領(lǐng)域的查詢(xún),RAG 可以從專(zhuān)業(yè)的知識(shí)庫(kù)中檢索信息,從而使模型的回答更具專(zhuān)業(yè)性
?
RAG 可以應(yīng)用于多種場(chǎng)景,包括但不限于:
?問(wèn)答系統(tǒng):RAG 能夠檢索到與問(wèn)題最相關(guān)的答案片段,然后基于這些片段生成最終的回答。
?對(duì)話系統(tǒng):在對(duì)話中,RAG 可以幫助模型引用歷史對(duì)話或外部知識(shí)來(lái)生成更自然、更有信息量的回復(fù)。
?文檔摘要:RAG 能夠從大量文檔中提取關(guān)鍵信息,生成總結(jié)或概述。
?文本補(bǔ)全:在文本補(bǔ)全任務(wù)中,RAG 可以參考相關(guān)文檔來(lái)提供更準(zhǔn)確的建議。
?
RAG 架構(gòu)的一個(gè)重要組成部分是檢索組件,它通常使用向量相似度搜索技術(shù),如倒排索引或基于神經(jīng)網(wǎng)絡(luò)的嵌入空間搜索。這使得模型能夠在大規(guī)模文檔集合中快速找到最相關(guān)的部分。
?
AI 應(yīng)用開(kāi)發(fā)框架
(一)Langchain
官網(wǎng):https://www.langchain.com/langchain?
LangChain不是一個(gè)大數(shù)據(jù)模型,而是一款可以用于開(kāi)發(fā)類(lèi)似AutoGPT的AI應(yīng)用的開(kāi)發(fā)工具,LangChain簡(jiǎn)化了LLM應(yīng)用程序生命周期的各個(gè)階段,且提供了 開(kāi)發(fā)協(xié)議、開(kāi)發(fā)范式,并 擁有相應(yīng)的平臺(tái)和生態(tài);
?
LangChain 是一個(gè)由 Harrison Chase 創(chuàng)立的框架,專(zhuān)注于幫助開(kāi)發(fā)者使用語(yǔ)言模型構(gòu)建端到端的應(yīng)用程序。它特別設(shè)計(jì)來(lái)簡(jiǎn)化與大型語(yǔ)言模型(LLMs)的集成,使得創(chuàng)建由這些模型支持的應(yīng)用程序變得更加容易。LangChain 提供了一系列工具、組件和接口,可以用于構(gòu)建聊天機(jī)器人、生成式問(wèn)答系統(tǒng)、摘要工具以及其他基于語(yǔ)言的AI應(yīng)用。
LangChain 的核心特性包括:
1.鏈?zhǔn)剿季S(Chains): LangChain 引入了“鏈”(Chain)的概念,這是一系列可組合的操作,可以按順序執(zhí)行,比如從獲取輸入、處理數(shù)據(jù)到生成輸出。鏈條可以嵌套和組合,形成復(fù)雜的邏輯流。
2.代理(Agents): 代理是更高級(jí)別的抽象,它們可以自主地決定如何使用不同的鏈條來(lái)完成任務(wù)。代理可以根據(jù)輸入動(dòng)態(tài)選擇最佳行動(dòng)方案。
3.記憶(Memory): LangChain 支持不同類(lèi)型的內(nèi)存,允許模型保留歷史對(duì)話或操作的上下文,這對(duì)于構(gòu)建有狀態(tài)的對(duì)話系統(tǒng)至關(guān)重要。
4.加載器和拆分器(Loaders and Splitters): 這些工具幫助讀取和處理各種格式的文檔,如PDF、網(wǎng)頁(yè)、文本文件等,為模型提供輸入數(shù)據(jù)。
5.提示工程(Prompt Engineering): LangChain 提供了創(chuàng)建和管理提示模板的工具,幫助引導(dǎo)模型生成特定類(lèi)型的內(nèi)容。
6.Hub: LangChain Hub 是一個(gè)社區(qū)驅(qū)動(dòng)的資源庫(kù),其中包含了許多預(yù)構(gòu)建的鏈條、代理和提示,可以作為構(gòu)建塊來(lái)加速開(kāi)發(fā)過(guò)程。
7.與外部系統(tǒng)的集成: LangChain 支持與外部數(shù)據(jù)源和API的集成,如數(shù)據(jù)庫(kù)查詢(xún)、知識(shí)圖譜、搜索引擎等,以便模型能夠訪問(wèn)更廣泛的信息。
8.監(jiān)控和調(diào)試工具: 為了更好地理解和優(yōu)化應(yīng)用程序,LangChain 提供了日志記錄和分析功能,幫助開(kāi)發(fā)者追蹤模型的行為和性能。
?
(二)LangChain4J
上面說(shuō)的 LangChain 是基于python 開(kāi)發(fā)的,而 LangChain4J 是一個(gè)旨在為 Java 開(kāi)發(fā)者提供構(gòu)建語(yǔ)言模型應(yīng)用的框架。受到 Python 社區(qū)中 LangChain 庫(kù)的啟發(fā),LangChain4J 致力于提供相似的功能,但針對(duì) Java 生態(tài)系統(tǒng)進(jìn)行了優(yōu)化。它允許開(kāi)發(fā)者輕松地構(gòu)建、部署和維護(hù)基于大型語(yǔ)言模型的應(yīng)用程序,如聊天機(jī)器人、文本生成器和其他自然語(yǔ)言處理(NLP)任務(wù)。
主要特點(diǎn):
1.模塊化設(shè)計(jì):LangChain4J 提供了一系列可組合的模塊,包括語(yǔ)言模型、記憶、工具和鏈,使得開(kāi)發(fā)者可以構(gòu)建復(fù)雜的語(yǔ)言處理流水線。
2.支持多種語(yǔ)言模型:LangChain4J 支持與各種語(yǔ)言模型提供商集成,如 Hugging Face、OpenAI、Google PaLM 等,使得開(kāi)發(fā)者可以根據(jù)項(xiàng)目需求選擇最合適的模型。
3.記憶機(jī)制:它提供了記憶組件,允許模型記住先前的對(duì)話歷史,從而支持上下文感知的對(duì)話。
4.工具集成:LangChain4J 支持集成外部工具,如搜索API、數(shù)據(jù)庫(kù)查詢(xún)等,使得模型能夠訪問(wèn)實(shí)時(shí)數(shù)據(jù)或執(zhí)行特定任務(wù)。
5.鏈?zhǔn)綀?zhí)行:通過(guò)鏈?zhǔn)綀?zhí)行,可以將多個(gè)語(yǔ)言處理步驟鏈接在一起,形成復(fù)雜的處理流程,例如先分析用戶(hù)意圖,再查詢(xún)數(shù)據(jù)庫(kù),最后生成回復(fù)。
?
主要功能:
1.LLM 適配器:允許你連接到各種語(yǔ)言模型,如 OpenAI 的 GPT-3 和 GPT-4,Anthropic 的 Claude 等。
2.Chains 構(gòu)建:提供一種機(jī)制來(lái)定義和執(zhí)行一系列操作,這些操作可以包括調(diào)用模型、數(shù)據(jù)檢索、轉(zhuǎn)換等,以完成特定的任務(wù)。
3.Agent 實(shí)現(xiàn):支持創(chuàng)建代理(agents),它們可以自主地執(zhí)行任務(wù),如回答問(wèn)題、完成指令等。
4.Prompt 模板:提供模板化的提示,幫助指導(dǎo)模型生成更具體和有用的回答。
5.工具和記憶:允許模型訪問(wèn)外部數(shù)據(jù)源或存儲(chǔ)之前的交互記錄,以便在會(huì)話中保持上下文。
6.模塊化和可擴(kuò)展性:使開(kāi)發(fā)者能夠擴(kuò)展框架,添加自己的組件和功能。
?
本地問(wèn)答系統(tǒng)搭建環(huán)境準(zhǔn)備
(一)用 Ollama 啟動(dòng)一個(gè)本地大模型
1.下載安裝 Ollma
2.ollama 是一個(gè)命令行工具,用于方便地在本地運(yùn)行 LLaMA 系列模型和其他類(lèi)似的 transformer 基礎(chǔ)的大型語(yǔ)言模型。該工具簡(jiǎn)化了模型的下載、配置和推理過(guò)程,使得個(gè)人用戶(hù)能夠在自己的機(jī)器上直接與這些模型交互,而不需要直接接觸復(fù)雜的模型加載和推理代碼;
3.下載地址:https://ollama.com/,下載完成后,打開(kāi) Ollma,其默認(rèn)端口為11334,瀏覽器訪問(wèn):http://localhost:11434 ,會(huì)返回:Ollama is running,電腦右上角展示圖標(biāo);

1.下載 大模型
2.安裝完成后,通過(guò)命令行下載大模型,命令行格式:ollma pull modelName,如:ollma pull llama3;
3.大模型一般要幾個(gè)G,需要等一會(huì);個(gè)人建議至少下載兩個(gè), llama3、 qwen(通義千問(wèn)),這兩個(gè)都是開(kāi)源免費(fèi)的,英文場(chǎng)景 用 llama3,中文場(chǎng)景用 qwen;
?
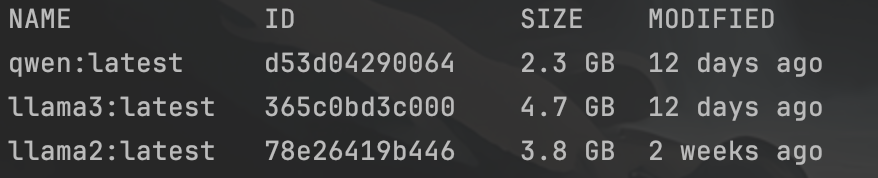
下載完成后,通過(guò) ollma list 可以查看 已下載的大模型;
?
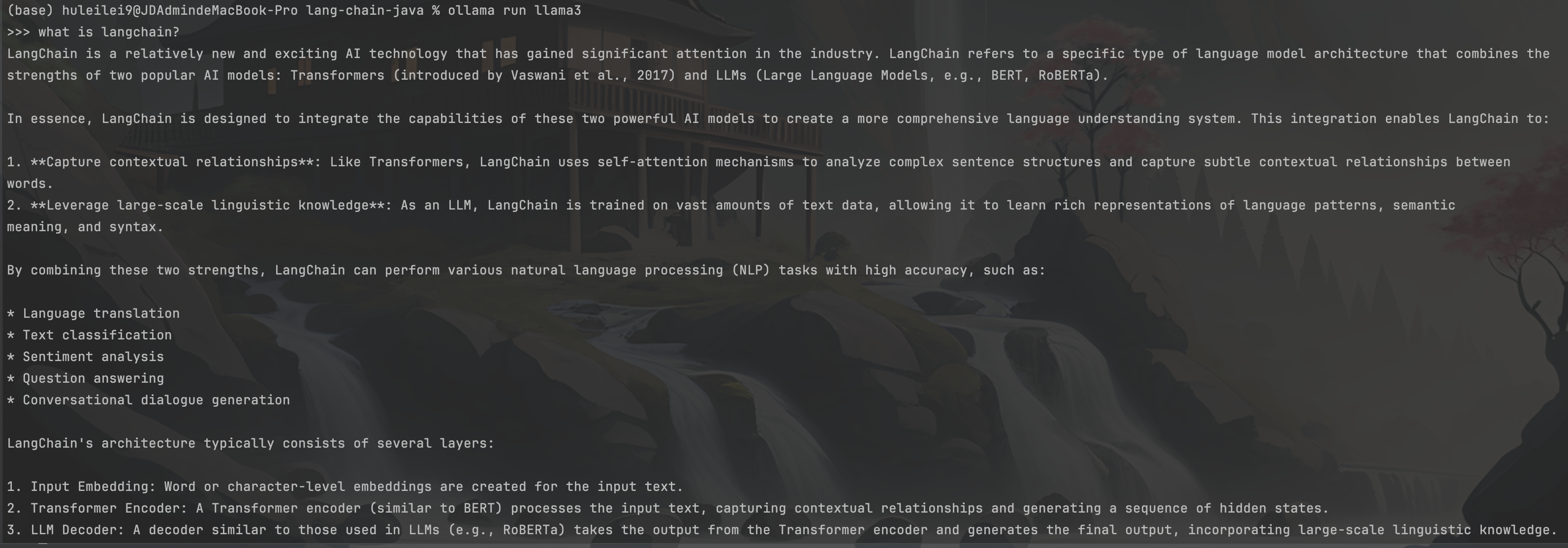
1.啟動(dòng) 大模型
確認(rèn)下載完成后,用命令行 :ollma run 模型名稱(chēng),來(lái)啟動(dòng)大模型;啟動(dòng)后,可以立即輸入內(nèi)容與大模型進(jìn)行對(duì)話,如下:
?
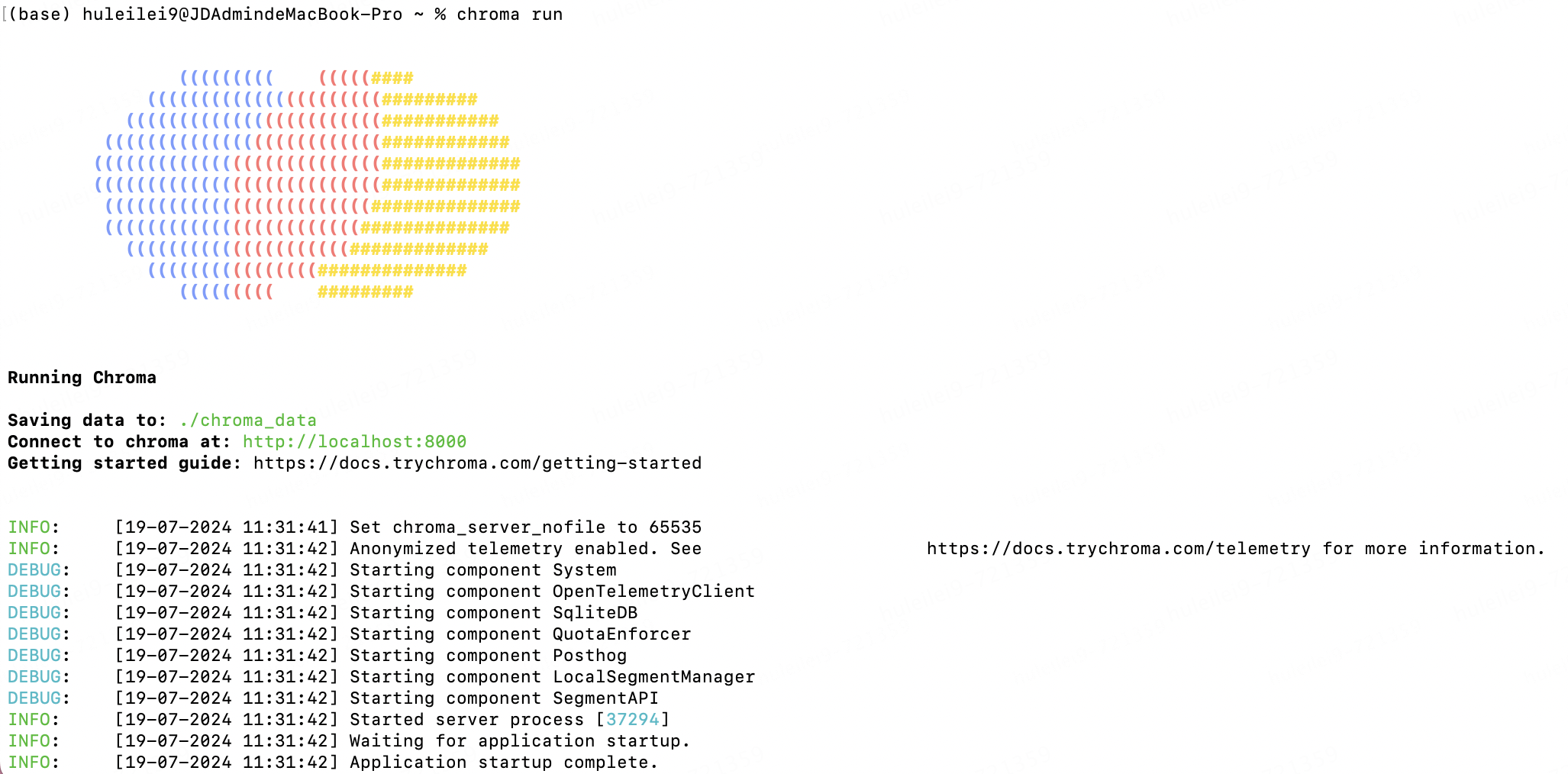
(二)啟動(dòng) 本地向量數(shù)據(jù)庫(kù) chromadb
Chroma 是一款 AI 原生開(kāi)源矢量數(shù)據(jù)庫(kù),它內(nèi)置了入門(mén)所需的一切,可在本地運(yùn)行,是一款很好的入門(mén)級(jí)向量數(shù)據(jù)庫(kù)。
1.安裝:pip install chromadb ;
2.啟動(dòng):chroma run :
?
用java 實(shí)現(xiàn) 本地AI問(wèn)答功能
(一)核心maven依賴(lài):
8
8
UTF-8
0.31.0
dev.langchain4j
langchain4j-core
${langchain4j.version}
dev.langchain4j
langchain4j
${langchain4j.version}
dev.langchain4j
langchain4j-open-ai
${langchain4j.version}
dev.langchain4j
langchain4j-embeddings
${langchain4j.version}
dev.langchain4j
langchain4j-chroma
${langchain4j.version}
dev.langchain4j
langchain4j-ollama
${langchain4j.version}
io.github.amikos-tech
chromadb-java-client
0.1.5
?
(二)代碼編寫(xiě):
1. 加載本地文件作為本地知識(shí)庫(kù):
public static void main(String[] args) throws ApiException { //======================= 加載文件======================= Document document = getDocument("笑話.txt"); } private static Document getDocument(String fileName) { URL docUrl = LangChainMainTest.class.getClassLoader().getResource(fileName); if (docUrl == null) { log.error("未獲取到文件"); } Document document = null; try { Path path = Paths.get(docUrl.toURI()); document = FileSystemDocumentLoader.loadDocument(path); } catch (URISyntaxException e) { log.error("加載文件發(fā)生異常", e); } return document; }
1.拆分文件內(nèi)容:
//======================= 拆分文件內(nèi)容=======================
//參數(shù):分段大小(一個(gè)分段中最大包含多少個(gè)token)、重疊度(段與段之前重疊的token數(shù))、分詞器(將一段文本進(jìn)行分詞,得到token)
DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(200, 0, new OpenAiTokenizer());
List segments = lineSplitter.split(document);
log.info("segment的數(shù)量是: {}", segments.size());
//查看分段后的信息
segments.forEach(segment -> log.info("========================segment: {}", segment.text()));
?
1.文本向量化 并存儲(chǔ)到向量數(shù)據(jù)庫(kù):
//提前定義兩個(gè)靜態(tài)變量
private static final String CHROMA_DB_DEFAULT_COLLECTION_NAME = "java-langChain-database-demo";
private static final String CHROMA_URL = "http://localhost:8000";
//======================= 文本向量化=======================
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
//======================= 向量庫(kù)存儲(chǔ)=======================
Client client = new Client(CHROMA_URL);
//創(chuàng)建向量數(shù)據(jù)庫(kù)
EmbeddingStore embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl(CHROMA_URL)
.collectionName(CHROMA_DB_DEFAULT_COLLECTION_NAME)
.build();
segments.forEach(segment -> {
Embedding e = embeddingModel.embed(segment).content();
embeddingStore.add(e, segment);
});
?
1.向量庫(kù)檢索:
//======================= 向量庫(kù)檢索=======================
String qryText = "北極熊";
Embedding queryEmbedding = embeddingModel.embed(qryText).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding(queryEmbedding).maxResults(1).build();
EmbeddingSearchResult embeddedEmbeddingSearchResult = embeddingStore.search(embeddingSearchRequest);
List> embeddingMatcheList = embeddedEmbeddingSearchResult.matches();
EmbeddingMatch embeddingMatch = embeddingMatcheList.get(0);
TextSegment textSegment = embeddingMatch.embedded();
log.info("查詢(xún)結(jié)果: {}", textSegment.text());
1.與LLM交互
//======================= 與LLM交互=======================
PromptTemplate promptTemplate = PromptTemplate.from("基于如下信息用中文回答:n" +
"{{context}}n" +
"提問(wèn):n" +
"{{question}}");
Map variables = new HashMap();
//以向量庫(kù)檢索到的結(jié)果作為L(zhǎng)LM的信息輸入
variables.put("context", textSegment.text());
variables.put("question", "北極熊干了什么");
Prompt prompt = promptTemplate.apply(variables);
//連接大模型
OllamaChatModel ollamaChatModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
UserMessage userMessage = prompt.toUserMessage();
Response aiMessageResponse = ollamaChatModel.generate(userMessage);
AiMessage response = aiMessageResponse.content();
log.info("大模型回答: {}", response.text());
(三)功能測(cè)試:
1.代碼中用到 "笑話.txt" 是我隨便從網(wǎng)上找的一段內(nèi)容,大家可以隨便輸入點(diǎn)內(nèi)容,為了給大家展示測(cè)試結(jié)果,我貼一下我 文本內(nèi)容:
有一只北極熊和一只企鵝在一起耍, 企鵝把身上的毛一根一根地拔了下來(lái),拔完之后,對(duì)北極熊說(shuō):“好冷哦!” 北極熊聽(tīng)了,也把自己身上的毛一根一根地拔了下來(lái), 轉(zhuǎn)頭對(duì)企鵝說(shuō): ”果然很冷!”
1.當(dāng)我輸入問(wèn)題:“北極熊干了什么”,程序打印如下結(jié)果:
根據(jù)故事,北極熊把自己的身上的毛一根一根地拔了下來(lái)
?
結(jié)語(yǔ)
1.以上便是 完成了一個(gè)超簡(jiǎn)易的AI問(wèn)答 功能,如果想搭一個(gè)問(wèn)答系統(tǒng),可以用Springboot搞一個(gè)Web應(yīng)用,把上面的代碼放到 業(yè)務(wù)邏輯中即可;
2.langchain 還有其他很多很強(qiáng)大的能力,prompt Fomat、output Fomat、工具調(diào)用、memory存儲(chǔ)等;
3.早點(diǎn)認(rèn)識(shí)和學(xué)習(xí)ai,不至于被它取代的時(shí)候,連對(duì)手是誰(shuí)都不知道;
?
參考資料:
1.?langchain 官網(wǎng)?
2.?langchain 入門(mén)教程?
3.?langchain4j github?
4.?langchain4j 視頻介紹?
?審核編輯 黃宇
-
JAVA
+關(guān)注
關(guān)注
19文章
2966瀏覽量
104702 -
AI大模型
+關(guān)注
關(guān)注
0文章
315瀏覽量
305
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
沙特計(jì)劃啟動(dòng)千億美元級(jí)AI項(xiàng)目"超越計(jì)劃"
OCTC發(fā)布"算力工廠"!力促智算中心高效規(guī)劃建設(shè)投運(yùn)

軟通動(dòng)力攜手華為啟動(dòng)&quot;智鏈險(xiǎn)界&quot;計(jì)劃,強(qiáng)化生態(tài)鏈接共啟保險(xiǎn)AI新時(shí)代

AI賦能B2B營(yíng)銷(xiāo),徑碩科技&quot;融合AI?驅(qū)動(dòng)AI&;quot;峰會(huì)成功舉辦

全方位精準(zhǔn)測(cè)量技術(shù)助力:中國(guó)經(jīng)濟(jì)加力發(fā)展向前&amp;quot;進(jìn)&amp;quot;

擷發(fā)科技COMPUTEX 2024展示先進(jìn)&quot;AI設(shè)計(jì)技術(shù)服務(wù)&quot;和&quot;全套IC設(shè)計(jì)解決方案&quot;
晶科能源榮獲EUPD Research授予的六項(xiàng)&quot;頂級(jí)光伏品牌&quot;稱(chēng)號(hào)

九聯(lián)科技推出一款&quot;射手座&quot;UMA502-T7物聯(lián)網(wǎng)模組
浪潮信息&quot;源2.0&quot;大模型YuanChat支持英特爾最新商用AI PC

科沃斯掃地機(jī)器人通過(guò)TüV萊茵&quot;防纏繞&quot;和&quot;高效邊角清潔&quot;認(rèn)證
Quanterix宣布Tau217血液檢測(cè)被美國(guó)FDA授予 &quot;突破性器械 &quot;認(rèn)證
電池&quot;無(wú)&quot;隔膜?SEI新&quot;膜&quot;法!
中創(chuàng)新航榮獲逸動(dòng)科技2023年度&quot;優(yōu)秀戰(zhàn)略合作伙伴獎(jiǎng)&quot;
第二代配網(wǎng)行波故障預(yù)警與定位裝置YT/XJ-001:守護(hù)電力線路的超能&amp;quot;哨兵&amp;quot;

電流互感器帶&quot;S&quot;和不帶S所表示的含義及區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論