") 澎峰科技高性能大模型推理引擎PerfXLM解析
澎峰科技高性能大模型推理引擎PerfXLM解析
自ChatGPT問世以來,大模型遍地開花,承載大模型應(yīng)用的高性能推理框架也不斷推出,大有百家爭(zhēng)鳴之勢(shì)。在這種情況下,澎峰科技作為全球領(lǐng)先的智能計(jì)算服務(wù)提供商,在2023年11月25日發(fā)布了針對(duì)大語言模型的高性能推理框架,并受到廣泛關(guān)注。在歷經(jīng)數(shù)月的迭代開發(fā)后,澎峰科技重磅發(fā)布升級(jí)版本,推出全新的高性能大模型推理引擎:PerfXLM。
PerfXLM采用了云端一體架構(gòu),支持云端推理和本地推理兩種模式。在硬件支持上,PerfXLM適配了包含多種國產(chǎn)處理器在內(nèi)的不同硬件,并針對(duì)硬件體系結(jié)構(gòu)特征進(jìn)行了深入性能優(yōu)化,大幅提升了大模型推理性能。
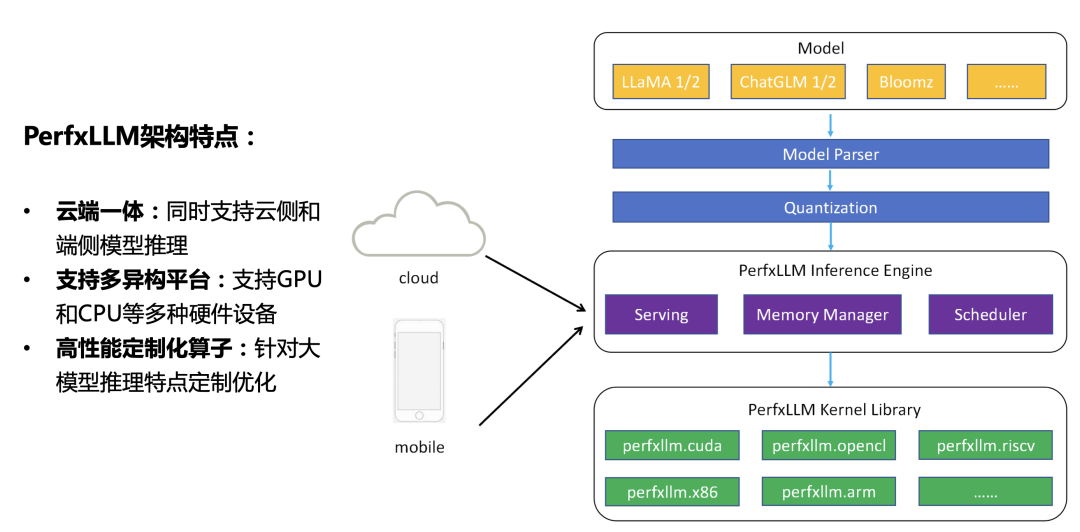
一、PerfXLM整體架構(gòu)

圖1.PerfXLM整體架構(gòu)
如圖1所示,PerfXLM整體架構(gòu)分為三層:
1.模型轉(zhuǎn)換層。將Torch或者Huggingface格式的大模型轉(zhuǎn)化為統(tǒng)一的內(nèi)部模型結(jié)構(gòu),并最終統(tǒng)一表達(dá)為ONNX圖。
2.推理引擎層。實(shí)現(xiàn)了ONNX圖解析、算子調(diào)度、統(tǒng)一內(nèi)存管理等功能,大幅提升硬件資源利用率;同時(shí),也提供了針對(duì)云端推理的專用Serving模塊,以獲得更高的硬件利用率和QPS響應(yīng)。
3.性能層。提供了針對(duì)大模型推理的高性能算子庫,并針對(duì)各種主流硬件進(jìn)行了適配和優(yōu)化。
PerfXLM具有的三大特點(diǎn):
1.云端一體,同時(shí)支持云側(cè)和端側(cè)大模型推理,能夠讓大模型適用于各種應(yīng)用場(chǎng)景之中。
2.支持多異構(gòu)平臺(tái),支持了包括NVIDIA GPU、海光DCU、高通Adreno GPU、Intel iGPU、某國產(chǎn)GPU在內(nèi)的多種硬件設(shè)備
3.高性能定制優(yōu)化算子,實(shí)現(xiàn)了結(jié)合體系結(jié)構(gòu)特征和大模型推理應(yīng)用特征的定制優(yōu)化。
二、大模型推理中的MxN問題
PerfXLM向上對(duì)接各種模型網(wǎng)絡(luò),向下適配各種硬件架構(gòu)。這就存在著一個(gè)組合問題:假設(shè)需要支持M個(gè)模型和N種硬件,那么一共有MxN種組合方式。PerfXLM需要實(shí)現(xiàn)對(duì)主流模型的支持,目前主流模型大概有幾十種,國內(nèi)甚至一度“千模大戰(zhàn)”。同時(shí),PerfXLM也需要實(shí)現(xiàn)對(duì)主流硬件的支持,包括NVIDIA GPU、AMD GPU、海光DCU、沐曦GPU等通用GPU架構(gòu);X86、ARM、RISC-V等通用CPU架構(gòu);高通Adreno GPU、ARM MALI GPU等移動(dòng)GPU架構(gòu);華為昇騰、寒武紀(jì)MLU、燧原等專用處理器架構(gòu)等。考慮到模型和硬件的迅猛發(fā)展,這個(gè)組合數(shù)大概有上千種,這就對(duì)大模型推理框架提出了很高的兼容性要求。
面對(duì)這樣的一個(gè)復(fù)雜問題,PerfXLM提出了一套解決方案:通過統(tǒng)一的模型表達(dá),實(shí)現(xiàn)了對(duì)不同大模型的快速支持;通過統(tǒng)一算子API的定義,實(shí)現(xiàn)了對(duì)大模型圖的快速算子構(gòu)建;通過融合體系結(jié)構(gòu)特征和應(yīng)用特征的算子庫的構(gòu)建,實(shí)現(xiàn)了對(duì)不同硬件的快速適配。
同時(shí),為了便于用戶使用,PerfXLM上層采用了與vllm一致的頂層API接口。用戶只需要在導(dǎo)入python模塊時(shí),簡(jiǎn)單地將vllm修改成perfxlm就能夠?qū)⒃械拇a運(yùn)行起來并且獲得更高的性能表現(xiàn)。具體的使用示例如下圖。
圖2. PerfXLM API接口
通過這樣的一套架構(gòu)體系,PerfXLM可以快速地支持新的模型和新的硬件。以近日Meta開源的LLaMA3為例,假設(shè)算子完備的情況下,只需幾個(gè)小時(shí)的時(shí)間,就能夠?qū)⒃?a href="http://www.1cnz.cn/article/zt/" target="_blank">最新模型運(yùn)行在各種主流硬件設(shè)備上。
三、PerfXLM性能
云側(cè)和端側(cè)的應(yīng)用場(chǎng)景不同:云上側(cè)重于多用戶服務(wù),關(guān)注的是整體吞吐;端側(cè)側(cè)重于單用戶的使用體驗(yàn),關(guān)注的是在低算力硬件上的響應(yīng)速度和延遲。下面講描述PerfXLM在單Batch和多Batch下的性能。
1)PerXLM在NVIDIA GPU上的性能
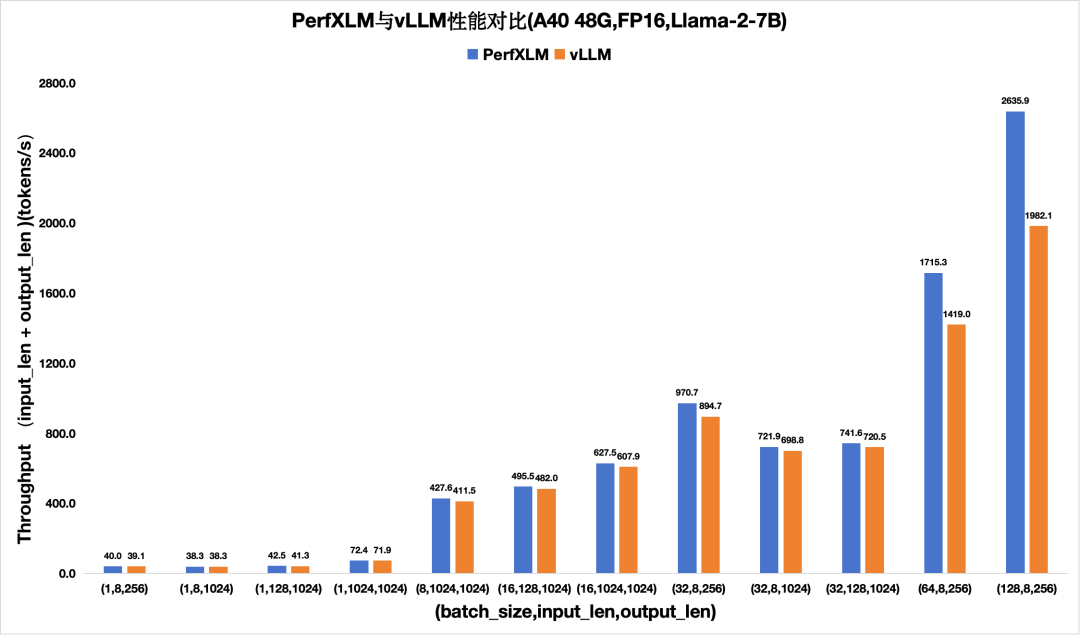
圖3. PerfXLM與vllm在A40上FP16的llama2性能對(duì)比
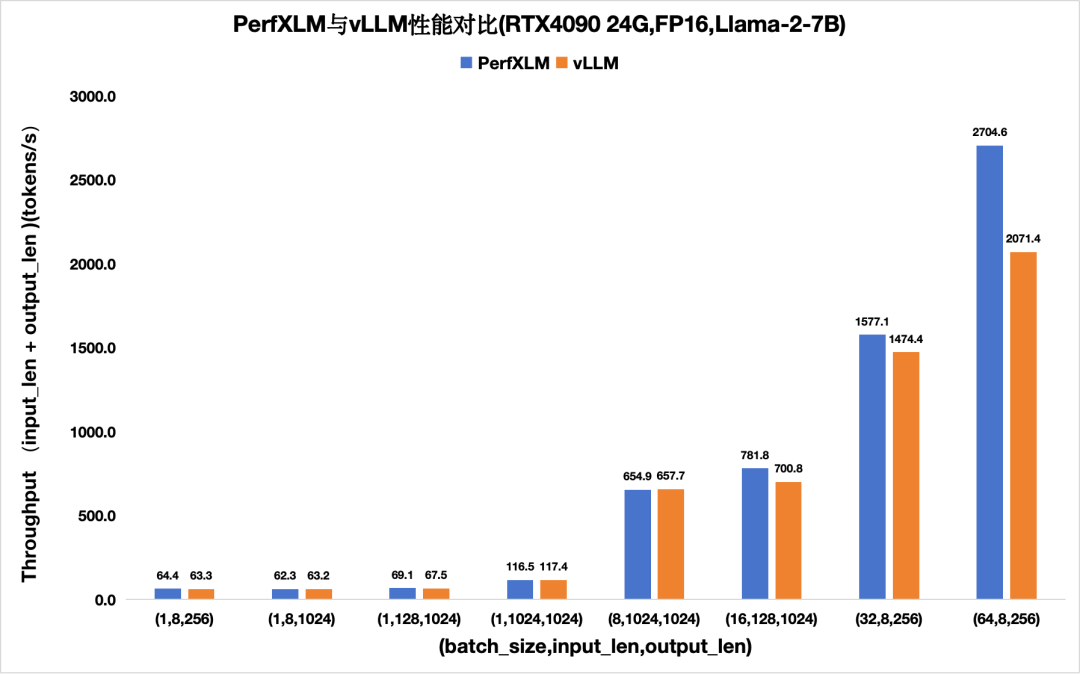
圖4. PerfXLM與vllm在4090上FP16的llama2性能對(duì)比
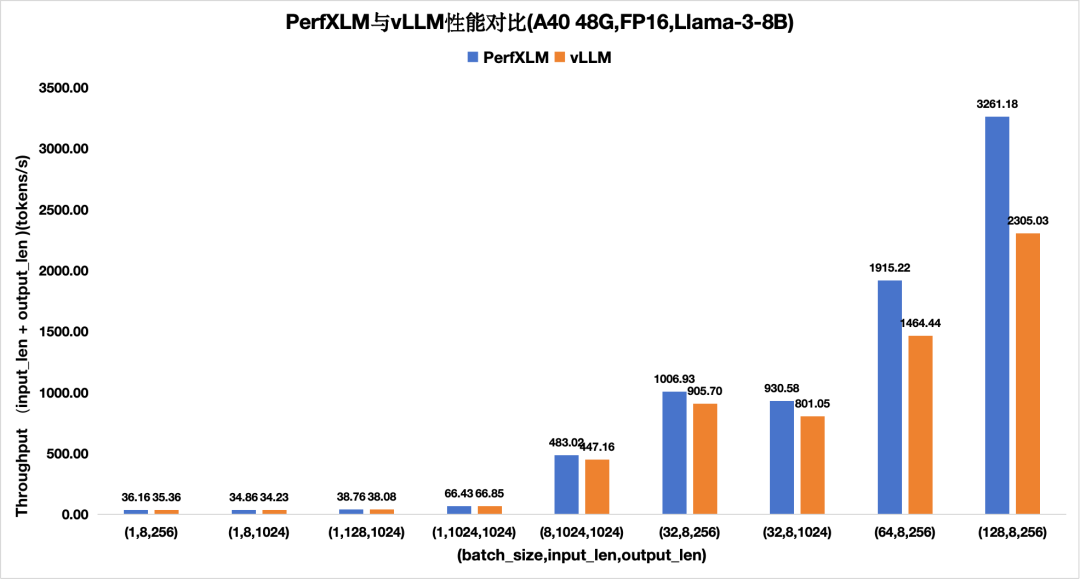
圖5.PerfXLM與vllm在A40上FP16的llama3性能對(duì)比
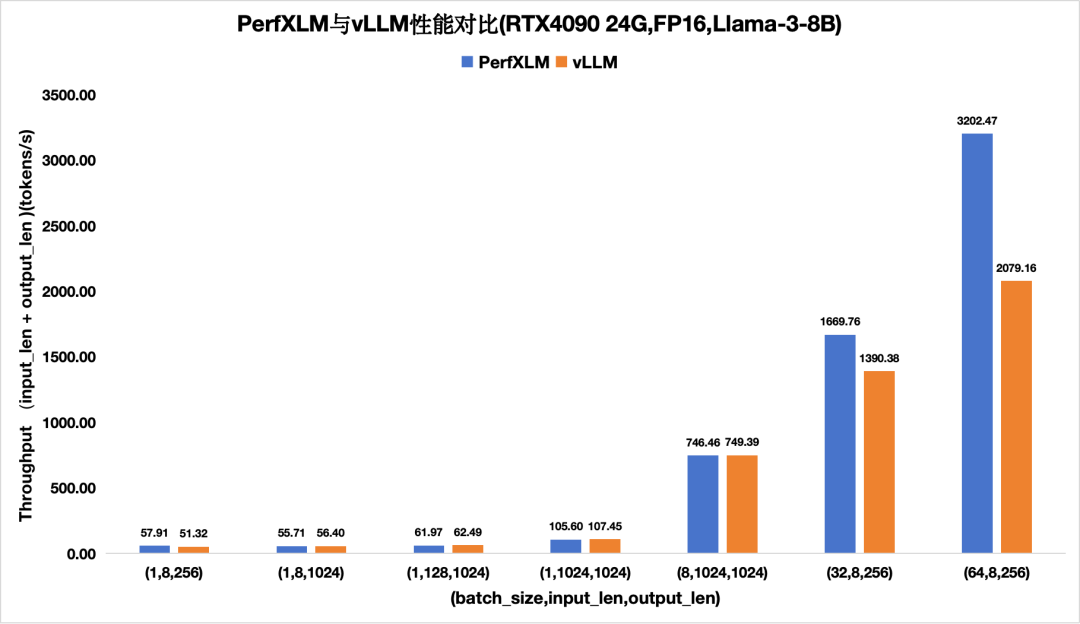
圖6.PerfXLM與vllm在4090上FP16的llama3性能對(duì)比
2)PerfXLM在海光DCU上的性能
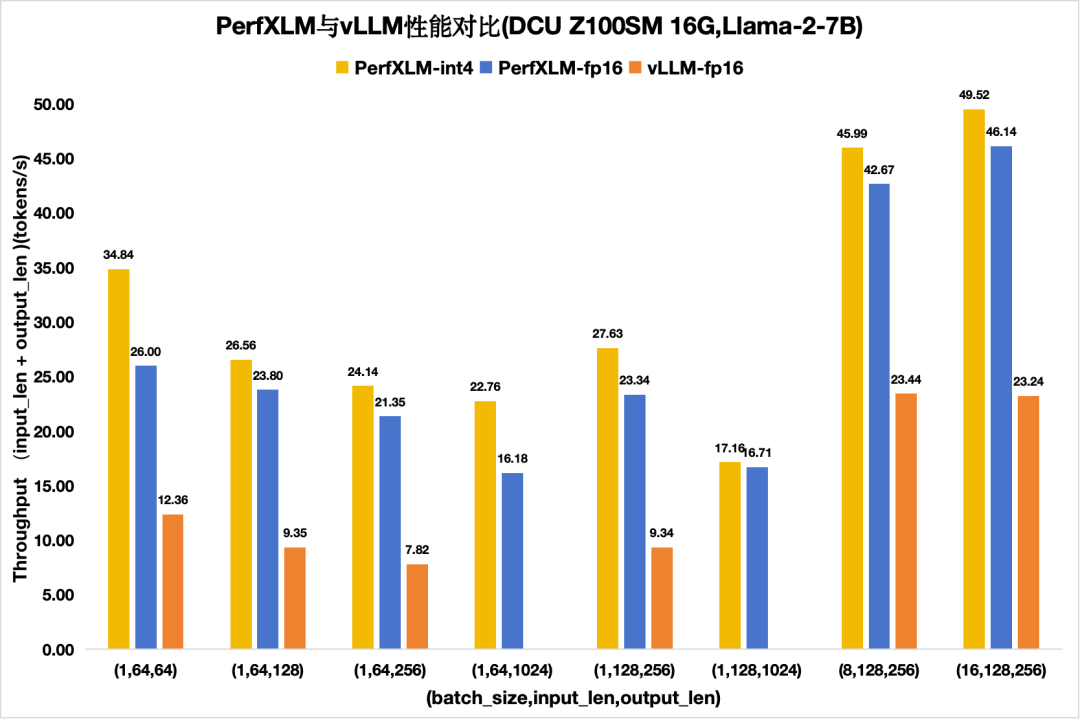
圖7 PerfXLM與vllm在DCU Z100SM上的llama2性能對(duì)比
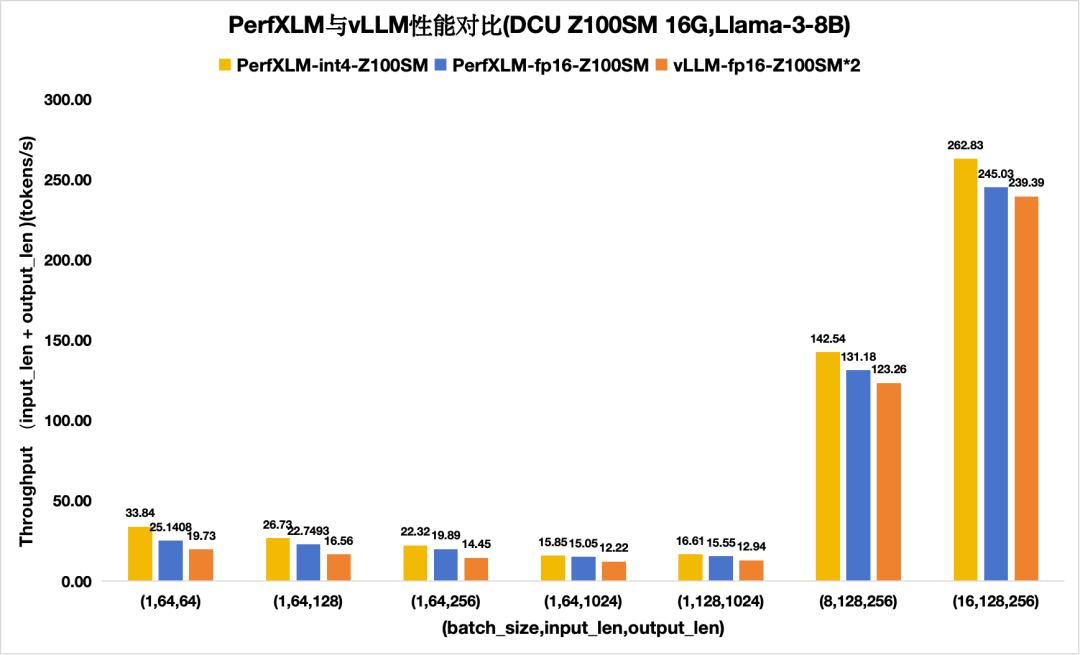
圖8 PerfXLM與vllm在DCU Z100SM上的llama3性能對(duì)比
3)PerfXLM在國產(chǎn)某GPU上的性能
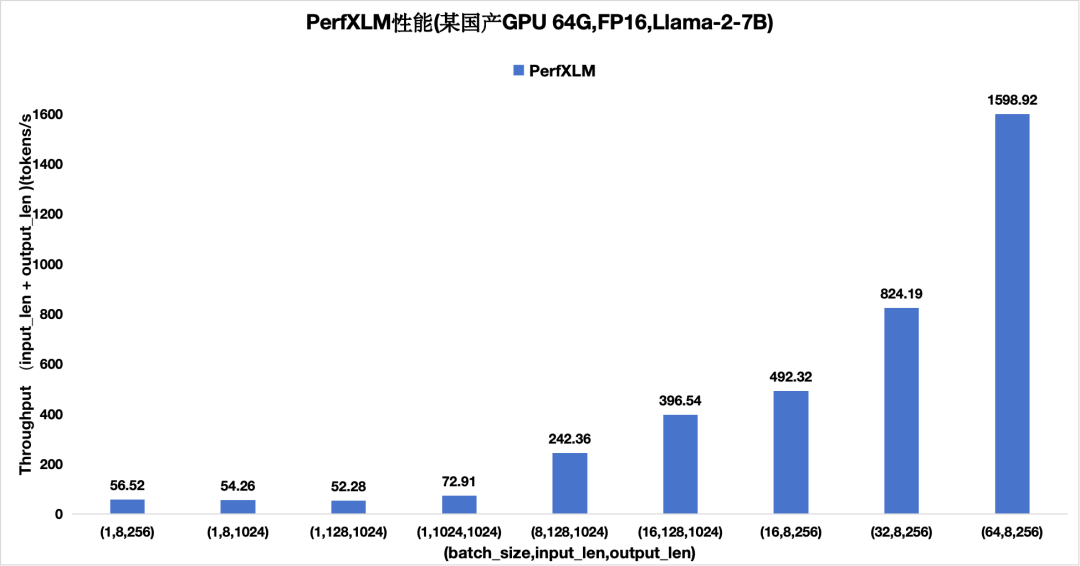
圖9 PerfXLM在某國產(chǎn)GPU上的性能
4)PerfXLM在高通Adreno GPU上的性能
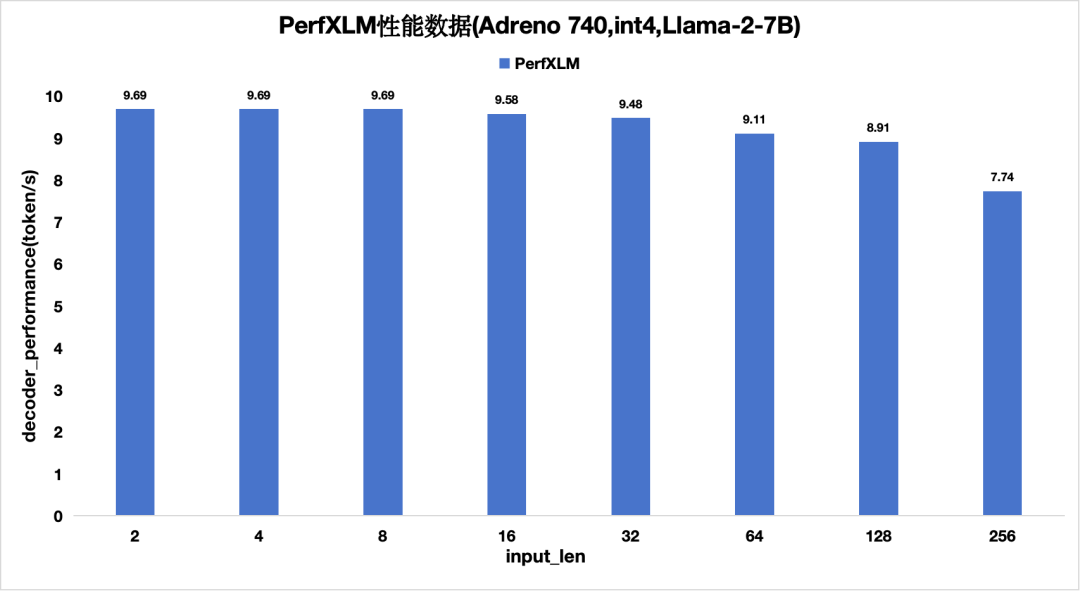
圖10 PerfXLM在高通Adreno的性能(單batch)
5)PerfXLM在Intel iGPU上的性能
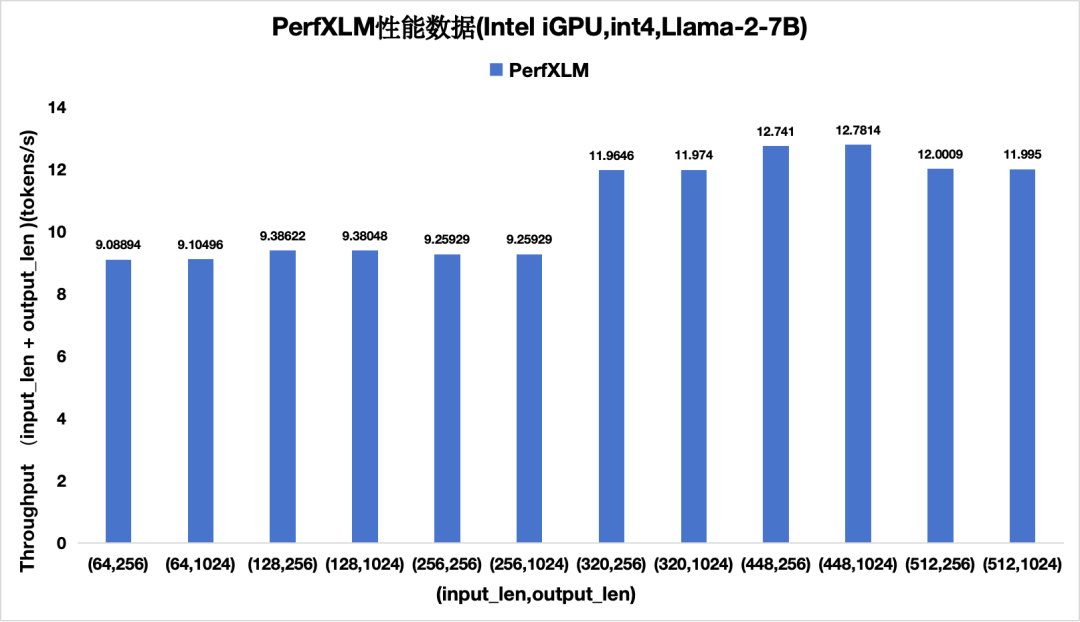
圖11 PerfXLM在Intel iGPU上的性能(單batch)
未來,PerfXLM將繼續(xù)支持"更多的硬件 x更多的模型"。
-
澎峰科技
+關(guān)注
關(guān)注
0文章
55瀏覽量
3168 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
原文標(biāo)題:爆款·大模型推理引擎PerfXLM發(fā)布
文章出處:【微信號(hào):perfxlab,微信公眾號(hào):perfxlab】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
賽昉科技與澎峰科技結(jié)成合作伙伴關(guān)系,共同推動(dòng)RISC-V應(yīng)用生態(tài)發(fā)展
賽昉科技與澎峰科技結(jié)成合作伙伴關(guān)系,共同推動(dòng)RISC-V應(yīng)用生態(tài)發(fā)展
2023RISC-V中國峰會(huì),澎峰科技成果發(fā)布搶先看!
HarmonyOS:使用MindSpore Lite引擎進(jìn)行模型推理
澎峰科技發(fā)布大模型推理引擎PerfXLLM
澎峰科技與并行科技共拓AI大模型技術(shù)創(chuàng)新應(yīng)用服務(wù)

澎峰科技CA100智能計(jì)算一體機(jī)核心優(yōu)勢(shì)解讀
澎峰科技受聘為“主權(quán)級(jí)大模型”創(chuàng)新聯(lián)合體學(xué)術(shù)委員會(huì)委員
澎峰科技受邀參加全球AI芯片峰會(huì),探討大模型推理引擎PerfXLM面向RISC-V的移植和優(yōu)化

澎峰科技“澎峰云”校園行活動(dòng)回顧
“澎峰云”校園行:湖南科技職業(yè)學(xué)院站,共啟校園創(chuàng)新之旅!

第一屆“澎峰云?大模型AI校園應(yīng)用創(chuàng)新賽完美結(jié)束
澎峰科技PerfXCloud平臺(tái)獲海光DCU生態(tài)兼容性認(rèn)證
澎峰科技攜手湖南第一師范,開啟大模型AI學(xué)習(xí)新模式






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論