 AMD發布首款小語言AI模型Llama-135m
AMD發布首款小語言AI模型Llama-135m
近日,AMD在Huggingface平臺上正式推出了自家首款“小語言模型”——AMD-Llama-135m。這款模型以其獨特的推測解碼功能,吸引了業界的廣泛關注。
AMD-Llama-135m模型擁有6700億個token,并采用了Apache 2.0開源許可,為用戶提供了更多的靈活性和自由度。據AMD介紹,該模型主打“推測解碼”能力,這一功能的基本原理是通過使用一個小型草稿模型來生成一組候選token,然后由更大的目標模型對這些候選token進行驗證。這種方法不僅能夠確保生成的token的準確性和可靠性,而且允許每次前向傳遞生成多個token,從而顯著提高了效率。
與傳統的AI模型相比,AMD-Llama-135m在RAM占用方面也有了顯著的優化。由于采用了推測解碼技術,該模型能夠在不影響性能的前提下,減少RAM的占用,實現了更加高效的計算和存儲資源利用。
AMD-Llama-135m的發布,標志著AMD在AI領域邁出了重要的一步。未來,AMD將繼續致力于AI技術的研發和創新,為全球用戶提供更加智能、高效和可靠的解決方案。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
amd
+關注
關注
25文章
5466瀏覽量
134097 -
AI
+關注
關注
87文章
30732瀏覽量
268893 -
模型
+關注
關注
1文章
3226瀏覽量
48809
發布評論請先 登錄
相關推薦
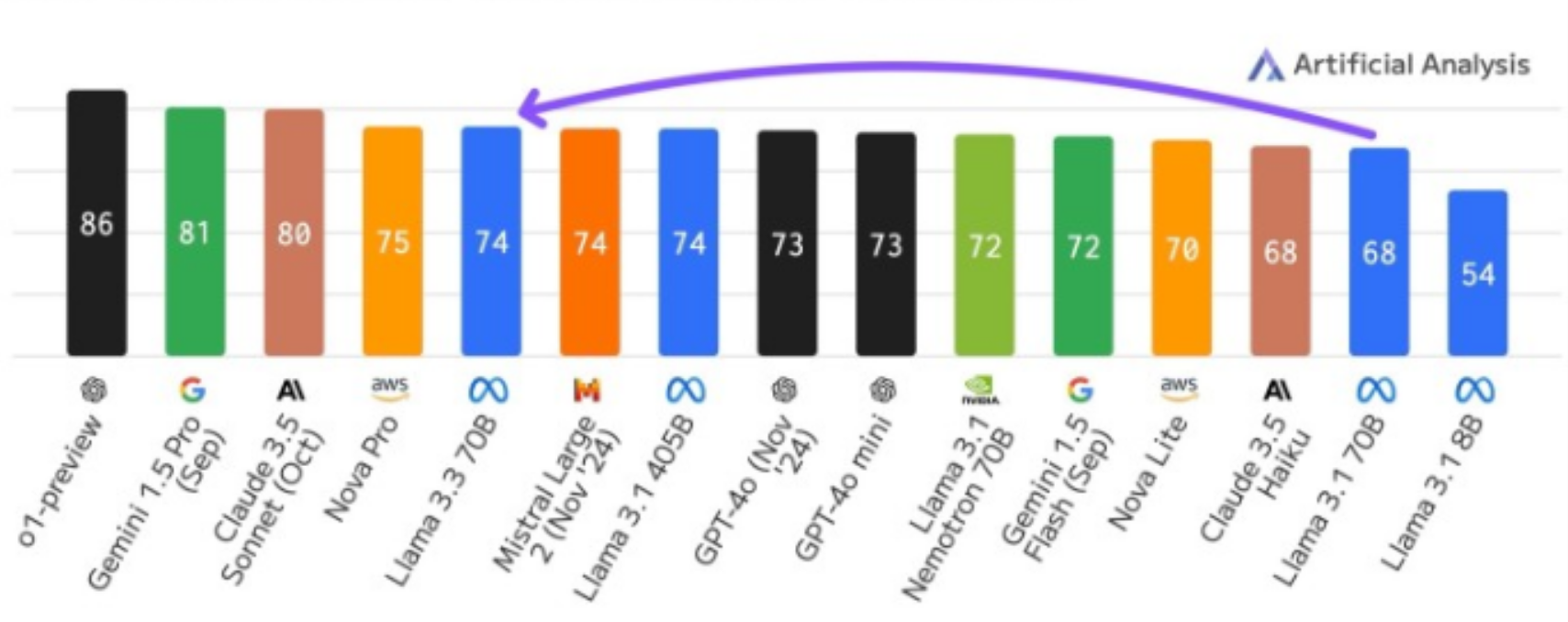
Meta重磅發布Llama 3.3 70B:開源AI模型的新里程碑
新的高度。 一,技術突破:開源智能的新高度 Llama 3.3 70B 模型的發布,標志著開源AI模型在智能水平上的一大飛躍。它不僅達到了之
使用NVIDIA TensorRT提升Llama 3.2性能
Llama 3.2 模型集擴展了 Meta Llama 開源模型集的模型陣容,包含視覺語言
Llama 3 與開源AI模型的關系
在人工智能(AI)的快速發展中,開源AI模型扮演著越來越重要的角色。它們不僅推動了技術的創新,還促進了全球開發者社區的合作。Llama 3,作為一個新興的
Llama 3 模型與其他AI工具對比
Llama 3模型與其他AI工具的對比可以從多個維度進行,包括但不限于技術架構、性能表現、應用場景、定制化能力、開源與成本等方面。以下是對Llama 3
Llama 3 語言模型應用
在人工智能領域,語言模型的發展一直是研究的熱點。隨著技術的不斷進步,我們見證了從簡單的關鍵詞匹配到復雜的上下文理解的轉變。 一、Llama 3 語言
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
前面我們分享了《三步完成Llama3在算力魔方的本地量化和部署》。2024年9月25日,Meta又發布了Llama3.2:一個多語言大型語言
亞馬遜云科技上線Meta Llama 3.2模型
亞馬遜云科技近日宣布,Meta公司的新一代模型Llama 3.2已在其平臺上正式上線。該模型包括Meta首款多模態
亞馬遜云科技正式上線Meta Llama 3.2模型
亞馬遜云科技宣布,Meta的新一代模型Llama 3.2,包括其首款多模態模型,現已在Amazon Bedrock和Amazon SageM
英偉達發布AI模型 Llama-3.1-Nemotron-51B AI模型
英偉達公司宣布推出 Llama-3.1-Nemotron-51B AI 模型,這個AI大模型是源自 Meta 公司的
Meta發布全新開源大模型Llama 3.1
科技巨頭Meta近期震撼發布了其最新的開源人工智能(AI)模型——Llama 3.1,這一舉措標志著Meta在AI領域的又一重大突破。Met
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型
借助 NVIDIA AI Foundry,企業和各國現在能夠使用自有數據與 Llama 3.1 405B 和 NVIDIA Nemotron 模型配對,來構建“超級模型” NVIDIA
發表于 07-24 09:39
?706次閱讀

中控流程工業首款AI時序大模型TPT發布
點燃AI引擎,打造工業應用新范式? 杭州2024年6月7日?/美通社/ --?6月5日,由中控技術傾力打造的流程工業首款AI時序大模型TPT

Meta Llama 3基礎模型現已在亞馬遜云科技正式可用
亞馬遜云科技近日宣布,Meta公司最新發布的兩款Llama 3基礎模型——Llama 3 8B和Llam
英特爾AI產品助力其運行Meta新一代大語言模型Meta Llama 3
英特爾豐富的AI產品——面向數據中心的至強處理器,邊緣處理器及AI PC等產品為開發者提供最新的優化,助力其運行Meta新一代大語言模型Meta L
LLaMA 2是什么?LLaMA 2背后的研究工作
Meta 發布的 LLaMA 2,是新的 sota 開源大型語言模型 (LLM)。LLaMA 2 代表著





 工商網監
工商網監
評論