") NASA專家細品iMac Pro,細節(jié)驚艷全場,堪稱性能怪獸!
NASA專家細品iMac Pro,細節(jié)驚艷全場,堪稱性能怪獸!
俗話說得好,錢多燒包。每隔一段時間,總會有那么一樣產(chǎn)品會對我產(chǎn)生相似的效果 —— 這種產(chǎn)品是那么吸引人,那么讓人興奮,看起來是那么美,它能讓我的錢包升溫,甚至燒起來。最新的 iMac Pro 就是這樣一種產(chǎn)品。
承蒙蘋果的美意,他們給我發(fā)了一臺 128GB,十核版本的 iMac Pro以便測試和評估。我花了不到一周的時間使用這臺機器,在航空航天工程和軟件開發(fā)領(lǐng)域進行我日常的工作流程,另外也運行了一些跑分和測試。iMac Pro 在性能和生產(chǎn)力上給我留下了強烈的印象。我會在下文中給出其中一些結(jié)果,但我還需要說的是 iMac Pro 在視覺上也給了我很深的印象。盡管它在造型和尺寸上看起來很像近些年來的 27 英寸 iMac,但 iMac Pro 是第一款采用深空灰配色的(還有對應(yīng)配色的鍵盤、鼠標和觸控板),這讓它看上去很棒,很有商務(wù)的感覺。和我那臺銀色的 iMac 放在一起,iMac Pro 盤踞在一旁就好像沉默的達斯·維德,正準備要砍翻幾個人。
iMac Pro 的機身下也同樣非常可觀,它擁有的是十核的英特爾至強 W-2155 處理器,主頻 3.0GHz(通過睿頻可加速到 4.5GHz)。這是英特爾最新發(fā)布的一款工作站級別的至強處理器,用以填補其消費級 Core i9 和服務(wù)器級至強 Scalable 之間的空白。如果你希望擁有 Core i9 的性能但內(nèi)存容量更大,核心數(shù)更多,卻又不需要至強 Scalable 那么全面的能力,至強 W 系列就是對像 iMac Pro 這樣的機器最理想的選擇(它提供八核、十核、十四核和十八核四種版本)。至強 W 還是在 Mac 中第一款支持英特爾 AVX-512 向量處理的處理器,這將其向量寄存器的向量長度提高到了 512 bit(提升自 AVX2 的 256 bit),并將向量寄存器的數(shù)量倍增到每核心 32 個(提升自 AVX2 的 16 個)。我會在下文中更多地討論此事。
我的測試機中的十核處理器擁有每核心單個 13.8MB 的 L3 緩存以及 1MB 的 L2 緩存,該機型搭載的是 128GB 的 2666MHz DDR4 ECC 內(nèi)存,一塊 2TB SSD 硬盤(擁有硬件級別的線路速率加密),以及顯存為 16GB 的 AMD Radeon Pro Vega 64 圖形芯片集。與此搭配的是沖擊力極強的 5120×2880 視網(wǎng)膜“5K”顯示器,iMac Pro 可說是一個圖形動力室 —— 我不斷為一切被渲染得如此清晰干凈,卻又對性能沒有明顯的過度占用或影響感到驚奇。曾經(jīng)我在將復(fù)雜的 3D 數(shù)據(jù)集進行視覺化時,不得不在性能或細節(jié)中二選一,而 iMac Pro 兩邊都能滿足。即使僅僅是使用 Xcode 或終端來工作的時候,屏幕的清晰和高亮度都能讓眼睛感到很舒適。
那么現(xiàn)在就來做一些測試吧,這些測試基于對空氣動力學(xué)設(shè)計和開發(fā)所需的計算流體動力學(xué)(CFD)的使用。在這類工作中,我使用的是 NASA 提供的名為 TetrUSS 的 CFD 工具,還有被普遍使用的 NACA 0012 airfoil 來打造運輸類飛機的通用研究模型(CRM)的幾何結(jié)構(gòu)。
CFD 的一種典型用法是評估航空航天飛行器,諸如火箭或飛機的空氣動力表現(xiàn)。該流程的第一步是從 CAD 定義中創(chuàng)建飛行器的幾何網(wǎng)格模型。這本質(zhì)上能讓我們將問題分解為成百萬個小單元,以便通過數(shù)值來模擬氣流的物理表現(xiàn)。類似的流程被用在工程分析的其他領(lǐng)域還包括結(jié)構(gòu)和熱傳導(dǎo)。另外雖然和模擬無關(guān),OpenGL 游戲程序員也很了解用三角形或四邊形為 3D 物體創(chuàng)建網(wǎng)格模型的流程,因為這能夠打造一個能夠反映光影、著色和其他視覺效果的實體模型。
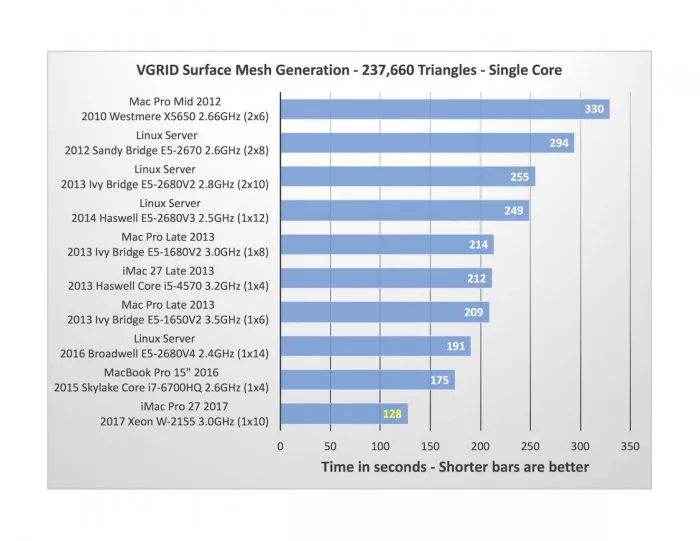
為了進行單核測試,我們首先從生成一個由 237660 個三角形組成的 CRM 翼-體-尾外形的表面網(wǎng)格模型開始。
iMac Pro 在這項測試中的耗時結(jié)果看上去非常好(下方圖標中的最后一欄),在我過去五年里測試過的十個系統(tǒng)中它是最快的,而且差距明顯。
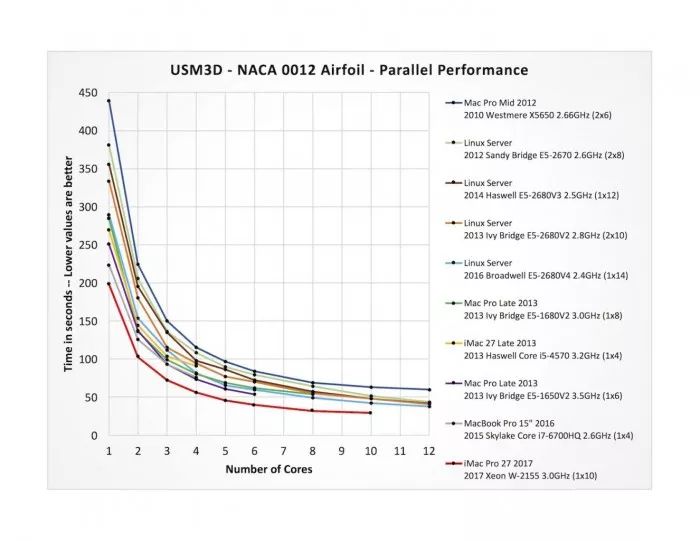
CFD 流程的另一個關(guān)鍵部分是實際的數(shù)值模擬,我們要對網(wǎng)格模型上通過的氣流進行運算。通常來說,這些模擬是要在超級計算機集群上運行的,使用 500 至 2000 個核心或更多,整個過程有時要耗費數(shù)天或數(shù)周。較小的實例可以運行在諸如 iMac Pro 這樣的多核心臺式電腦上,特別適合那些小型企業(yè)用戶以及學(xué)術(shù)界人士(通常實例的規(guī)模會受到內(nèi)存的限制,但這對 iMac Pro 的 128GB 來說不是問題 —— 它可以應(yīng)對大多數(shù)有實際意義的實例)。
和網(wǎng)格模型生成不同,氣流模擬很考驗并行處理,使得它成為理想的多核心測試指標。在這里,我們通過 NACA 0012 airfoil 計算氣流。結(jié)果通過示意圖來展示運算時間(以秒計),并和所使用的核心數(shù)量進行對比。在一部分機器中,最大可用的核心數(shù)量為十二核。在同一組系統(tǒng)中,iMac Pro(底部的紅線)再一次取得了最好的成績,在最多到十個核心的對比中,它的耗時很明顯是最短的。
我還關(guān)注了一下擴展表現(xiàn),這部分很有趣,因為它能夠顯示出許多和計算機架構(gòu)有關(guān)的東西。和很多人預(yù)期的不同,將更多的核心投入到一個問題中并不總是最完美的答案 —— 從某一點開始各個核心之間會開始爭奪各種系統(tǒng)資源,比如內(nèi)存和硬盤,你也能夠從上面的圖表中看到曲線是會漸漸平緩的。下面的圖表通過計算每一臺接受測試的電腦采用多核時,對比單核的速度增幅(單核耗時除以多核耗時),更清楚地體現(xiàn)了這一點。作為參考,理想的曲線以虛線顯示。在這個對比中,iMac Pro(紅色曲線)的表現(xiàn)和競爭對手們基本相似,使用全部十個核心時有 6.7 倍的速度提升。如果能讓十八核版本的 iMac Pro 運行同樣的測試肯定會很有趣,但可惜的是,它們直到明年一月才出貨。
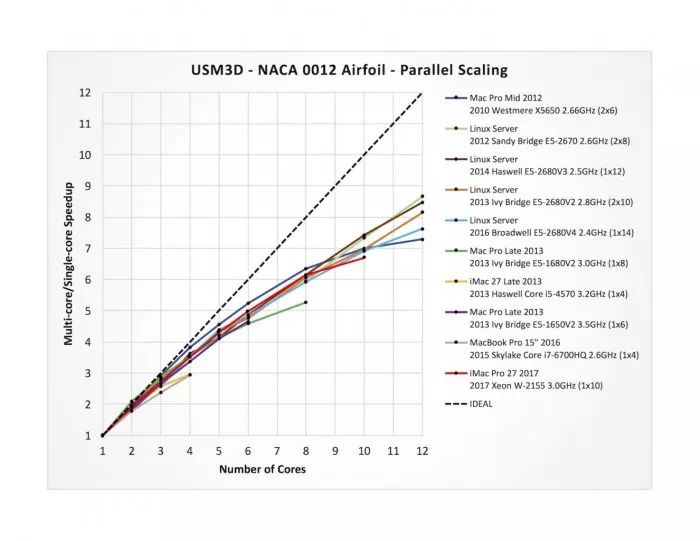
X 軸是所用核心數(shù),Y 軸是多核與單核的速度比值
另一個對我來說很重要,但同時又難以量化的測試項目是軟件開發(fā)。我傾向于使用 C 和 Fortan 編譯器在終端上做我大多數(shù)工程和 CFD 相關(guān)的軟件開發(fā)工作,但在 iOS 和 Mac 應(yīng)用的開發(fā)上我最常用的卻是 Xcode。幾個星期以前,我忙于調(diào)試一個異常棘手的 MapKit 分塊渲染 Bug,與此同時還要為iPhoneX 準備好我的 AR 應(yīng)用 Theodolite,我很確信在那幾天之內(nèi)我按了 Xcode 的 Build/Run 好幾千次(至少感覺上是這樣)。當你進入一個涉及到大量編譯工作的高強度開發(fā)或調(diào)試階段時,這兒省幾秒那兒省幾秒,加起來一天就能多出幾個小時了。十核 iMac Pro 在這個方面大放光彩,特別是當它結(jié)合 Xcode 能夠自動利用多核心去同時編譯多個源文件的能力時更是如此。
絕大多數(shù)我的應(yīng)用有 20000 至 30000 行代碼,分布在 80 至 120 個源文件中(大部分是 Obj-C 和 C,混合極少量 Swift)。有太多變量會影響編譯表現(xiàn),所以很難提出一種普遍適用的測試標準,因此我就簡單地描述一下,當我將 iMac Pro 和我的 2016 版MacBookPro 和 2013 版 iMac 對比時,我注意到編譯耗時有了 30% 至 60% 的減少。如果你開發(fā) iOS 應(yīng)用,仍會注意到在模擬器或在設(shè)備上安裝或啟動應(yīng)用存在瓶頸,但在開發(fā) Mac 應(yīng)用時,反復(fù)的代碼-編譯-調(diào)試循環(huán)會有相當明顯的提升。
我長年以來醉心于向量化,從上世紀 90 年代的 Cray 超級計算機開始,到進入 2000 年后 PowerMac G4 和 G5 中的 AltiVec。所以我很高興能夠聽到 iMac Pro 在向量處理上了有了很大飛躍。
向量化是一種單指令多數(shù)據(jù)(SIMD)處理的形式,處理器能夠同步地在一個“向量”內(nèi)執(zhí)行多個數(shù)據(jù)元素的運算。與此相對的,常見的“標量”代碼一次只能執(zhí)行單個數(shù)據(jù)元素。標量代碼的經(jīng)典例子是如下所示的循環(huán),我們將數(shù)組“a”的元素加上數(shù)組“b”的元素,并將結(jié)果儲存在數(shù)組“c”:
for (i=0;i
c=a+b;
}
當我們這樣循環(huán)的時候,我們一次只處理一個數(shù)據(jù)元素。如果你也了解這方面,就會知道每一次循環(huán)都需要兩次負載,加法和存儲 —— 四次運算 —— 因此我們在這個標量循環(huán)中就有總共 4*N 次運算。現(xiàn)在,因為 iMac Pro 的處理器每個核心都有了 AVX-512 向量處理器,我們就可以形成支持 16 字節(jié)單精度(32 位)浮點數(shù)或 8 字節(jié)雙精度(64 位)浮點數(shù)(或當使用整數(shù)時的等量)。如果我們假設(shè)范例中的數(shù)組是雙精度,那么使用 AVX-512 向量指令的等量向量循環(huán)就會是這個樣子:
for (i=0;i
__m512d a_vec = _mm512_load_pd(&a);
__m512d b_vec = _mm512_load_pd(&b);
__m512d c_vec = _mm512_add_pd(a_vec,b_vec);
_mm512_store_pd(&c,c_vec);
}
我們還是需要兩次負載,通過每次循環(huán)就有一次加法一次存儲,但因為我們是通過每個支持 8 字節(jié)雙精度的向量運算的,我們每一次就能增加 8 個循環(huán),所需的總運算量就是 4*N/8 —— 之前的八分之一!
你可能會馬上期待一個八倍的性能提升,但實際上這個漲幅太理論化了,現(xiàn)實中不會有那么多。誤差的多少取決于很多因素,比如數(shù)據(jù)大小,它是否能適合不同的緩存或分配入 RAM 中,等等。但在這個例子中,我們?nèi)?N 為 512,結(jié)果也很棒了。AVX-512 帶來的速度提升是 5.2 倍。作為對比,我也總結(jié)了 AVX2 的測試結(jié)果,它使用 256 bit 寬向量,一次可支持 4 次雙精度運算。這最終帶來了 3 倍的速度提升。雖然我不會給出具體的代碼細節(jié),但如果是使用單精度浮點數(shù)進行同樣的測試,AVX-512 的速度提升是 10.1 倍,而 AVX2 則為 6.3 倍。
一個需要注意的重要細節(jié)是,在上文的代碼范例中為了方便說明(也為了在測試時能有明確的控制),我使用了原有的 AVX-512 向量指令。實際上,現(xiàn)在的編譯器很擅于對合適的標量循環(huán)進行自動向量化,且在大多數(shù)情況下,你除了選擇更高層的優(yōu)化(通常是 -O2 或 -O3)以及指定正確的架構(gòu)和/或指令集標記外不需要做任何事。另一個可選項是鏈接到向量優(yōu)化庫。英特爾的 Math Kernel Library(MKL)對 AVX-512 進行了高度優(yōu)化,我被告知蘋果的 Accelerate 框架也已經(jīng)針對 AVX-512 進行了優(yōu)化(更多的改進未來還會有)。
最顯而易見的問題,其實我以上的測試并沒有直接給出答案,即 iMac Pro 和往年的標準版 iMac 相比,性能究竟如何。這里最相近的直接對比是我的 2013 版 iMac,但和它相比已經(jīng)落后幾代了。即便如此,我還是拿到了一些關(guān)于 2017 版 iMac 的 4.2GHz 四核 Core i7 處理器的有限資料。盡管 2017 版 iMac 在單核表現(xiàn)上比 iMac Pro 稍快一些,但隨著更多核心的參與,性能表現(xiàn)漸漸持平,到四核的時候 iMac 的優(yōu)勢不再。從四核到十核,iMac Pro 一路絕塵而去。如果你要利用 AVX-512(標準版 iMac 不支持),iMac Pro 更是直接超越。這樣的強化是 iMac Pro 的其中一個主要優(yōu)勢 —— 工作站級別的處理器相比標準版 iMac 所能提供的,可以利用更多的核心,更先進的處理功能,以及更大、擴展性更強的性能極限。另一個關(guān)鍵優(yōu)勢是內(nèi)存容量和圖形能力。如果你的工作能受益于其中任何一樣,那么 iMac Pro 就是自然而然的選擇。
我寫稿時,蘋果仍然沒有公開 iMac Pro 產(chǎn)品線的完整價位,只提到搭載八核處理器、32GB 內(nèi)存、1TB SSD 和 Vega Pro 56 圖形芯片集的基本款起售價是 4999 美元。價位上最相近的對比是 27 英寸 iMac,售價 3699 美元,但處理器和圖形芯片集差了太多。
少了四個核心,整體上還有其他劣勢。因此結(jié)合上文來看,多花 1300 美元入手 iMac Pro 是根本不需要考慮的。有趣的是高端機型究竟會是怎樣的價格,尤其是十八核版本,但如果按照入門級的價位這么延伸下去,那對那些想要購買工作站級 Mac 的人們來說可是一大筆錢。只要注意,錢包可別燒起來就行了。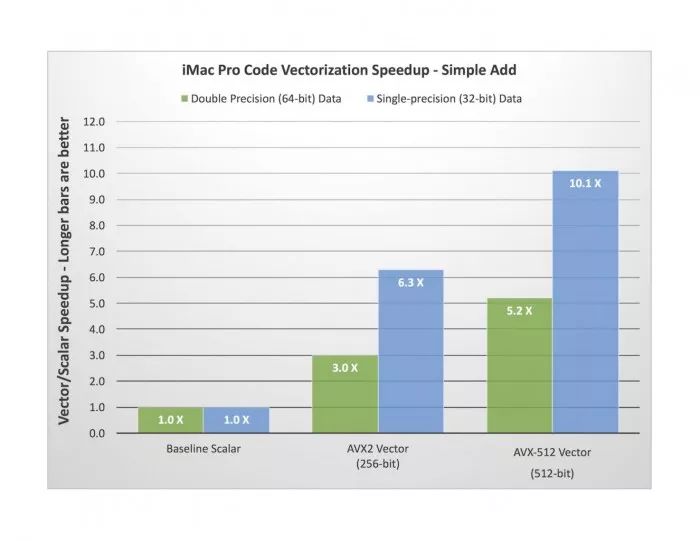
-
imacpro
+關(guān)注
關(guān)注
0文章
27瀏覽量
9445
原文標題:性能怪獸!NASA專家細品iMac Pro,細節(jié)驚艷全場!
文章出處:【微信號:iphone-apple-ipad,微信公眾號:iPhone頻道】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
蘋果將于今晚發(fā)布MacBook Pro系列新品
蘋果發(fā)布搭載M4芯片的iMac
北京安防博覽會圓滿閉幕!華電子智慧路燈全網(wǎng)運維管理驚艷全場!







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論