 測試手機芯片帶寬性能及優化測試方法
測試手機芯片帶寬性能及優化測試方法
手機的帶寬吞吐性能是影響手機總體性能的一個重要指標,目前幾乎所有第三方的手機評測軟件都有對這一項指標的單獨測試。但這些測試基本上都存在一些問題,并不能全面真實地反映手機的帶寬吞吐性能。文章從硬件的角度深入分析了CPU、Cache、DDR等模塊的實現方式對帶寬測試軟件的影響,并結合最常用的ARM系列CPU做了對比,最后提出了新的帶寬吞吐性能評價方式。
0引言
隨著智能手機的快速普及,2015年全球的出貨量已達14億臺。這其中大半部分都是Android系統的手機,它們的核心操作系統基本一樣,但硬件平臺就各有不同了。對手機硬件性能的評測成為了業界以及用戶所關注的重點。相應的,第三方的手機測評軟件就應運而生了。這些測評軟件往往將紛繁復雜的各項硬件性能轉化為一個個清晰明了的數字,讓消費者以最直觀的方式了解一部手機的性能水平。由于其使用的簡便性和直觀性,不光是手機的最終消費者經常使用它作為手機選擇的參考,不少方案廠商也利用這些測評軟件作為手機芯片選擇的依據。
現代的手機主控芯片都是多核系統,運算能力越來越強,但內存性能卻提升有限。因此內存性能往往成為系統性能的瓶頸,對內存帶寬吞吐性能的測試也顯得尤為重要。本文將分析目前帶寬性能測試軟件的一些局限性,結合硬件設計探討影響帶寬性能測試的因素,最后提出對帶寬性能測試優化的方向。
1 CPU測試帶寬的局限性
手機的主控芯片是個復雜的SoC(System on Chip),有多個主設備可以訪問DDR(內存),DDR控制器的復雜程度也越來越高,它可以協調均衡各個主設備的訪問。但除了CPU,其他的主設備第三方用戶是不方便直接用軟件來控制的,如視頻編解碼模塊,這些模塊都需要專門的驅動程序來控制,而驅動程序都是由硬件廠商提供,第三方用戶不了解其中的細節。因此一般是利用統計CPU訪問DDR的速度來評估芯片總的帶寬吞吐性能。這就帶來一個問題,可能CPU全速運行測試程序所需要的帶寬也達不到DDR能提供的理論帶寬,這時帶寬吞吐性能受限于CPU發讀寫命令的能力,而不是受限于DDR。
例如,以ARM cortexA9 CPU做仿真實驗,在CPU訪存接口上掛一個理想的32位DDR模型(有訪問請求立即響應,沒有延時),CPU頻率為1 008 MHz時,測得數據拷貝帶寬為2 140 MB/s。而手機上一般會配置540 MHz 32位DDR,能提供的理論帶寬為4 320 MB/s,已經遠超cortex-A9的帶寬吞吐能力了,這種情況下帶寬性能測試得到的只是CPU的訪存性能,而不是DDR的總體帶寬性能。
2 Cache對帶寬吞吐測試的影響
現在的帶寬吞吐性能評測軟件都是利用統計CPU訪問DDR的速度來評估芯片總的帶寬吞吐性能,這就需要考慮CPU Cache的影響。
為了加快訪問數據的速度,現代多核處理器通常包含私有緩存(L1 Cache)和末級共享緩存(L2 Cache)[3]。L1 Cache大小通常有幾十KB,L2 Cache通常有數百KB到幾MB。CPU對數據的訪問都會經過Cache再到DDR。不同的Cache行為實現會導致CPU對DDR訪問量的巨大差異。
目前手機主控芯片幾乎都是采用ARM Cortex系列的CPU,下面就以ARM cortex系列最常用的CPU(A5,A7,A9,A53)來分析不同的Cache配置對CPU訪存性能的影響。
2.1對連續地址的寫操作
CPU對連續地址的寫入速度是反映帶寬性能的重要指標,軟件上對應memset操作,用C語言描述如下:
int *dst;
for(int i=0;i
*dst= value
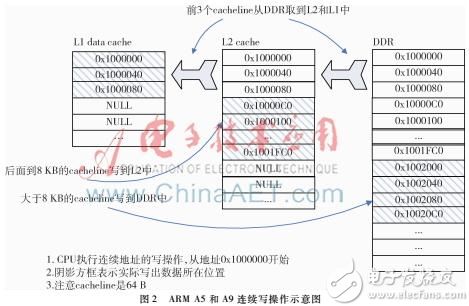
實際上由于Cache的存在,數值并不是直接寫到DDR中。對于ARM cortexA5和cortexA9 CPU,這一過程如圖1所示。
L1 data Cache一般都配置為write back + write allocate。但ARM對所有系列CPU的L1 Cache都做了優化:檢測到連續地址3次Cache line的write操作,即自動切換為write through + write no allocate。所以可以看到在圖中L1 data Cache只有前3個Cache line(0x1000000~0x1000040)的數據從DDR中讀取出來了,后面的數據就直接寫入L2 Cache了。
CortexA5和cortexA9的L2 Cache 依然是write back+write allocate。但沒有類似于L1 Cache那樣的自動切換到write through + write no allocate的機制。所以每次從L1 data Cache有數據寫到L2 Cache,都應該從DDR中讀取相應地址的一個Cache line大小的數據分配到L2 Cache中,再對這個分配好的Cache line做寫操作。但實際上由于L1 data Cache每次對L2 Cache的寫操作都是一個Cache line的大小,即整個Cache line都被重寫了,因此也不用關心DDR中對應這個Cache line地址的數據是什么了。這里L2 Cache就直接分配了一個Cache line來存放L1 data Cache寫過來的數據,沒有再去讀DDR。
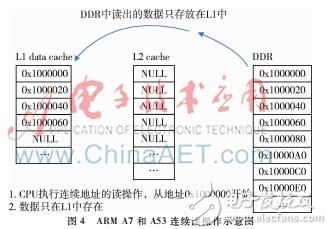
ARM cortexA7和cortexA53的情況又有所不同,如圖2。
CortexA7和cortexA53的L1 data Cache 實現機制與前面一樣,但L2 Cache的實現不同。雖然同樣是write back + write allocate,但其有個自動檢測機制,檢測到連續地址的127次Cache line的write操作可以自動切換到write through+write no allocate。如圖2所示,地址0x1002000之后的數據就直接寫到DDR中了。
根據上面的分析,對于CPU向外寫數據的操作,在小于一定大小的情況下,實際上并不會操作DDR,而是在操作L2 Cache。表1是兩款手機CPU 同頻下的memset性能對比,它們的CPU分別使用了ARM cortexA7和cortexA9。
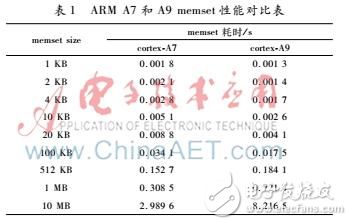
從表中數據可以看出,在size小于10 KB時,cortexA9性能好于cortexA7,此時都是對L2 Cache的訪問,性能決定于CPU的指令發射能力以及流水線的亂序執行能力,這些能力cortexA9都強于cortexA7。在10 KB 100 KB時,cortexA9的性能逐漸被cortexA7反超,因為此時cortexA9也開始有訪問DDR的操作了,size越大訪問DDR占比越大,最后幾乎完全是對DDR的訪問了。這時性能主要由DDR的性能決定。
2.2對連續地址的讀操作
CPU對連續地址的讀取速度也是反映帶寬性能的重要指標,可用C語言描述如下:
int *src;
for(int i=0;i
value = *(src + i);
cortexA5和cortex-A9的L2 Cache是非exclusive模式,即L1不命中時,從DDR讀取回來的Cache line會保存在L2 Cache中。如圖3。
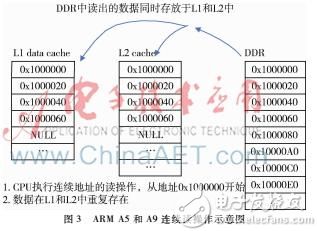
CortexA7和cortexA53的L2 Cache是exclusive模式,即L1不命中時,從DDR讀取回來的Cache line不會保存在L2 Cache中。只有當被改寫過的Cache line從L1 Cache刷出來時才會存到L2 Cache中。如圖4。
以上兩種實現方式各有利弊。做重復讀取性能測試時,如果數據量小于L1 data Cache size,exclusive模式和非exclusive模式性能相當。當數據量大于L1 data Cache size,且小于L2 Cache size時,非exclusive模式性能較好。當數據量大于L2 Cache size時,exclusive模式性能略好,如果除了讀操作還有其他的寫操作,那么exclusive模式性能優勢就更明顯了,因為這種模式下讀操作占用了較少的L2 Cache,可以分配給其他操作使用。
2.3數據拷貝性能
數據拷貝是CPU最常見的訪存行為,也是帶寬性能測試軟件最常用的測試方式。數據拷貝包含了從源地址的讀數據操作和向目標地址的寫數據操作。一般來講數據地址都是連續的。前面兩節討論了連續地址的寫操作和讀操作,這兩項性能也大致決定了數據拷貝的性能。
除此之外,DDR控制器在讀寫交替時的處理也會影響數據拷貝的性能。
DDR的地址線分為bank、row和column。一個bank中同時只能打開一個row,而處于不同bank中的row是可以同時打開的。為了充分利用這一特性來優化DDR訪問效率,bank、row、column地址和物理地址的對應方式會被精心設計,有多種映射方式[4]。圖5是某款手機的地址排列方式。

假設做數據拷貝,源地址是0x100000(對應row2,bank0),目標地址是0x200000(對應row4,bank0),它們對應同一個bank的不同row。從源地址讀一組Cacheline大小的數據,需要打開DDR的bank0_row2,然后CPU將這組數據寫入目標地址,這時就需要先關閉bank0_row2,再打開bank0_row4。在這個讀寫交替的過程中,就有對DDR某一row的關閉和打開操作,需要耗費較多的時間。
同樣還是做這樣的數據拷貝,如果將目標地址換成0x201000(對應bank1_row4),再做寫操作時就不用將bank0_row2關閉,直接打開bank1_row4就可以了。并且由于源和目標地址的row都沒有關閉,后面的讀寫操作都不用再做打開row的操作了,這就大大地提高了數據拷貝的性能。表2是某款手機(采用cortex-A9 CPU)在不同目標地址條件下數據拷貝性能的測試數據。
可以看到,僅僅是改變目標地址就使連續地址的數據拷貝性能出現了很大差異,避免讀寫地址沖突后數據拷貝性能可提高31%。

3帶寬性能測試的優化方向
前面分析了目前手機帶寬性能測試的局限性,并結合硬件設計探討影響帶寬性能測試的因素。根據這些因素,可以從以下幾個方面進一步優化完善帶寬性能測試方式:
(1)多個主設備同時訪問DDR,盡量達到DDR的帶寬極限。手機主控芯片中除了CPU,對帶寬需求最大的就是GPU,而GPU一般都可以通過上層的openGL軟件操作。GPU的測例可以使用多個圖層的疊加操作,這種操作對GPU的運算能力需求較弱,對帶寬要求較高。在測試時,讓CPU密集執行數據拷貝操作,同時讓GPU做圖層疊加,結合兩者的實際完成時間給出帶寬性能評估分數。
(2)用CPU測試數據拷貝性能,數據量要遠大于L2 Cache的大小,避免Cache的影響。除了連續地址的數據拷貝,還要增加非連續地址的數據讀取性能測試,以避免CPU預取功能的影響,更真實地反映DDR的單次延時。如以下C代碼:
int *src;
for(int i=0;i
value = *(src+i);
注意STRIDE的取值要大于兩個Cache line size,以免觸發連續Cache line的預取操作。將連續地址的數據拷貝和非連續地址的數據讀取性能結合評估并打分。
(3)為全面考察不同地址對數據拷貝性能的影響,做多次數據拷貝操作,每次都改變一下目標數據地址的偏移,如以下C代碼:
int *src, *dst;
for(int j=0;j
for(int i=0;i
*(dst+i+j*0x1000) = *(src+i);
4結束語
第三方的帶寬吞吐性能測試軟件不僅為終端消費者提供了手機性能的比較手段,也為手機方案廠商選擇芯片提供了可靠依據,甚至最上游的芯片設計廠商也會利用這些測試軟件來指導芯片架構的設計。本文提出的帶寬吞吐性能測試優化方式可以更全面公正地評估手機芯片的實際性能,加快了芯片設計性能問題的收斂,具有良好效果。
-
ARM
+關注
關注
134文章
9088瀏覽量
367408 -
cpu
+關注
關注
68文章
10855瀏覽量
211606 -
帶寬
+關注
關注
3文章
926瀏覽量
40913 -
soc
+關注
關注
38文章
4163瀏覽量
218172 -
手機芯片
+關注
關注
9文章
367瀏覽量
48916
發布評論請先 登錄
相關推薦
傳AMD再次進軍手機芯片領域,能否打破PC廠商折戟移動市場的“詛咒”

高通新推手機芯片技術,攜手小米等伙伴強化AI應用合作
聯發科發布天璣9400手機芯片
辨別射頻芯片性能好壞的6個高效測試方法

電源紋波測試帶寬設置的應用
想了解芯片推力測試?點擊這里,了解最新測試方法!
芯片的出廠測試與ATE測試的實施方法

阿里云攜手聯發科為手機芯片適配大模型
URAT測試的性能測試方法







 工商網監
工商網監
評論