 服務器數據恢復—EMC存儲RAID5陣列磁盤讀寫不穩定離線的數據恢復案例
服務器數據恢復—EMC存儲RAID5陣列磁盤讀寫不穩定離線的數據恢復案例
服務器數據恢復環境:
一臺EMC某型號存儲設備,該存儲中有一組由12塊(包括2塊熱備盤)STAT硬盤組建的raid5陣列。
服務器故障:
該存儲在運行過程中突然崩潰,raid癱瘓。數據恢復工程師到達現場對故障存儲設備進行初檢,發現raid中有兩塊硬盤掉線但只有一塊熱備盤成功激活,所以導致陣列癱瘓,上層lun無法使用。
服務器數據恢復過程:
1、將故障存儲中所有磁盤標記后取出。由硬件工程師檢測后沒有發現有磁盤存在物理故障,使用壞道檢測工具檢測也沒有發現有磁盤存在壞道。將所有磁盤以只讀方式進行扇區級全盤鏡像,由于源磁盤的扇區大小是520字節,做完鏡像后將520字節轉換成512字節。
2、由于故障存儲中所有硬盤經過檢測沒有發現存在物理故障和壞道,基本上可以推斷硬盤掉線是磁盤讀寫性能不穩定造成的。EMC控制器的磁盤檢測策略十分嚴格,讀寫性能不穩定的磁盤一般會被控制器判定為壞盤并踢出raid。當raid中掉線盤超過該raid級別的允許掉盤數量的極限,raid就會崩潰,基于raid的lun不可用。本案例中只有一個lun分配給sun小機,上層文件系統是ZFS。
3、EMC存儲的LUN都是基于RAID。通過分析發現有2塊盤完全沒有數據,EMC存儲的管理界面上顯示這2塊沒有數據的盤都是熱備盤,其中一塊熱備盤替換了一塊離線盤。雖然這塊熱備盤成功激活,RAID中還有一塊硬盤離線,所以數據沒有同步到這塊熱備盤中。繼續分析其他10塊盤,分析數據在硬盤中的分布規律、RAID條帶大小以及盤序等重組RAID所需要的信息。
4、由于RAID中有兩塊盤掉線,需要搞清楚這兩塊盤的掉線順序。分析每一塊盤中的數據,發現有一塊硬盤在同一個條帶上的數據和其他硬盤明顯不一樣,因此初步判斷此硬盤可能是最先掉線的。通過北亞企安自主開發的RAID校驗程序對這個條帶做校驗,最終確定這塊硬盤就是最先掉線的。
5、根據上面步驟獲取到的信息將RAID重組出來。EMC存儲的LUN是基于RAID的。分析LUN在RAID中的分配信息,以及LUN分配的數據塊MAP。根據上述信息,用北亞企安自主開發的程序解釋LUN的數據MAP并導出LUN的所有數據。
6、用北亞企安自主開發的ZFS文件系統解釋程序對生成的LUN做文件系統解釋,但是在解釋某些文件系統元文件的時候報錯。開發工程師對程序做debug調試并分析程序報錯原因,文件系統工程師分析ZFS文件系統是否因為版本原因而導致程序不支持。經過長達數小時的分析與調試,發現ZFS文件系統因存儲癱瘓導致某些元文件損壞,從而導致文件系統解釋報錯。
7、北亞企安數據恢復工程師手工修復這些損壞的元文件,直到ZFS文件系統能夠正常解析。
8、解析ZFS文件系統,解析所有文件節點及目錄結構。用戶方工程師對恢復出來的數據進行隨機驗證,經過仔細驗證沒有發現問題。
審核編輯 黃宇
-
服務器
+關注
關注
12文章
9272瀏覽量
85813 -
數據恢復
+關注
關注
10文章
585瀏覽量
17565 -
emc
+關注
關注
170文章
3945瀏覽量
183515
發布評論請先 登錄
相關推薦
服務器數據恢復—華為OceanStor存儲中RAID5陣列數據恢復案例

服務器數據恢復—RAID5陣列硬盤離線但熱備盤未激活的數據恢復案例

服務器數據恢復—不當操作導致raid5陣列數據無法恢復的案例
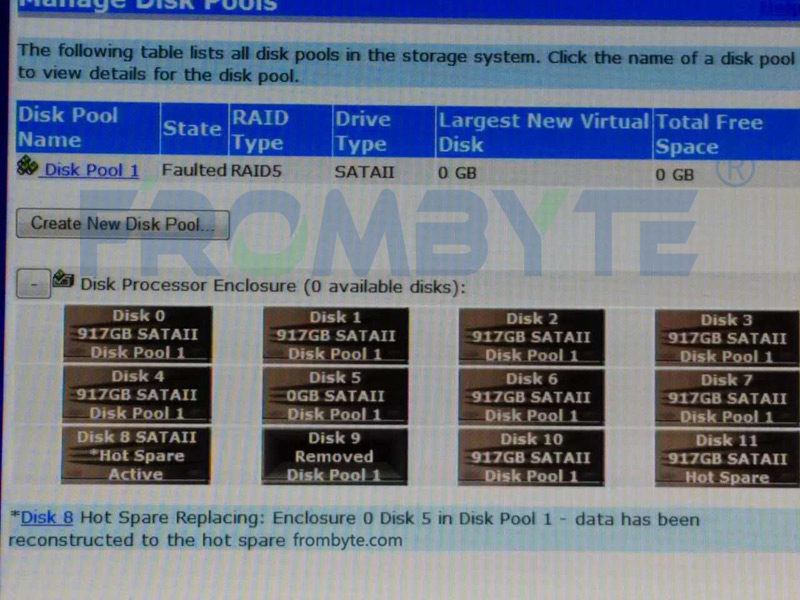
服務器數據恢復—raid5陣列熱備盤未完全激活導致陣列崩潰的數據恢復案例
服務器數據恢復—raid5陣列硬盤壞道導致raid崩潰的數據恢復案例
服務器數據恢復—磁盤不穩定被踢導致raid5陣列崩潰的數據恢復案例





 工商網監
工商網監
評論