

機(jī)器學(xué)習(xí)已經(jīng)在各個(gè)行業(yè)得到了大規(guī)模的廣泛應(yīng)用,并為提升業(yè)務(wù)流程的效率、提高生產(chǎn)率做出了極大的貢獻(xiàn)。這篇文章主要介紹了機(jī)器學(xué)習(xí)中最先進(jìn)的算法之一——神經(jīng)網(wǎng)絡(luò)的八種不同架構(gòu),并從原理和適用范圍進(jìn)行了解讀。機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)如此優(yōu)秀,我們先來(lái)探討兩個(gè)問(wèn)題——為什么需要機(jī)器學(xué)習(xí)?為何要使用神經(jīng)網(wǎng)絡(luò)?之后在來(lái)詳細(xì)了解八種不同的網(wǎng)絡(luò)架構(gòu)。
一、為何需要機(jī)器學(xué)習(xí)?
通常來(lái)講,對(duì)于人類十分復(fù)雜的任務(wù)就是機(jī)器學(xué)習(xí)大顯身手的地方,那些問(wèn)題都過(guò)于復(fù)雜,讓人類解決是不現(xiàn)實(shí)或者是不可能的。所以人們想出了一個(gè)辦法,為機(jī)器學(xué)習(xí)算法提供大量的數(shù)據(jù),并讓算法去探索這些數(shù)據(jù),搜索出一個(gè)可以描述這些數(shù)據(jù)的模型來(lái)實(shí)現(xiàn)解決問(wèn)題的目標(biāo)。
讓我們來(lái)看兩個(gè)小例子:
要寫(xiě)出一個(gè)能在不同光照條件下、新的視角下、雜亂的環(huán)境中識(shí)別一個(gè)新的物體的程序是極度困難的。我們不知道如何去寫(xiě)這個(gè)程序,如何建模,因?yàn)槲覀兏揪筒恢牢覀兊拇竽X是如何處理這樣的情況的。即使我們能想到一個(gè)辦法,那么程序?qū)?huì)復(fù)雜到難以置信的程度!
編寫(xiě)一個(gè)檢測(cè)信用卡欺詐的程序也十分困難,幾乎不存在又簡(jiǎn)單又可靠的規(guī)則,我們需要結(jié)合一系列弱規(guī)則來(lái)實(shí)現(xiàn)。當(dāng)欺詐目標(biāo)變化時(shí),程序也需要隨機(jī)應(yīng)變的改變以適應(yīng)。
還有大量的例子使我們束手無(wú)策,于是機(jī)器學(xué)習(xí)就成為了一種有效的方法。我們不在去編寫(xiě)程序解決某個(gè)特定的任務(wù),而是對(duì)于需要解決的問(wèn)題收集大量的輸入——輸出數(shù)據(jù)。機(jī)器學(xué)習(xí)算法可以通過(guò)這些數(shù)據(jù)產(chǎn)生可以解決問(wèn)題的程序。這些程序與傳統(tǒng)的code不同,是由成千上萬(wàn)個(gè)參數(shù)構(gòu)成。如果我們建模有效,那么程序?qū)?huì)在新的數(shù)據(jù)上獲得和訓(xùn)練數(shù)據(jù)一樣好的表現(xiàn),并且可以輸入新的訓(xùn)練數(shù)據(jù)來(lái)使得程序適應(yīng)新的變化。需要注意的是,現(xiàn)在大規(guī)模計(jì)算的成本已經(jīng)比請(qǐng)經(jīng)驗(yàn)豐富的程序員便宜了,這也是經(jīng)濟(jì)上機(jī)器學(xué)習(xí)得以發(fā)展的原因所在。
目前機(jī)器學(xué)習(xí)主要在以下方面應(yīng)用:
模式識(shí)別:實(shí)際場(chǎng)景中的目標(biāo)、包括人臉、表情、語(yǔ)音識(shí)別等等;
異常檢測(cè):例如信用卡交易的異常檢測(cè)、傳感器異常數(shù)據(jù)模式檢測(cè)和異常行為檢測(cè)等;
預(yù)測(cè):預(yù)測(cè)股票或者匯率、或者預(yù)測(cè)消費(fèi)者喜歡的電影、音樂(lè)等。
二、什么是神經(jīng)網(wǎng)絡(luò)?
神經(jīng)網(wǎng)絡(luò)是一類機(jī)器學(xué)習(xí)算法和模型的統(tǒng)稱,也是目前機(jī)器學(xué)習(xí)發(fā)展最快的一個(gè)領(lǐng)域。它在生物大腦結(jié)構(gòu)的啟發(fā)下誕生,并衍生為現(xiàn)在最為前沿的深度神經(jīng)網(wǎng)絡(luò),可以處理輸入和輸出間極為復(fù)雜的映射過(guò)程。神經(jīng)網(wǎng)絡(luò)具有如下三個(gè)特征使它成為了機(jī)器學(xué)習(xí)中的重要組成部分:
有助于理解大腦實(shí)際工作的流程,
有助于理解神經(jīng)元和期間的自適應(yīng)鏈接以及并行計(jì)算的概念,與順序處理的序列模型大不相同;
在大腦的啟發(fā)下利用新的算法解決實(shí)際問(wèn)題。
要想系統(tǒng)地學(xué)習(xí)機(jī)器學(xué)習(xí),吳恩達(dá)的課程對(duì)于機(jī)器學(xué)習(xí)入門(mén)很有幫助,進(jìn)一步的可以學(xué)習(xí)被稱為"深度學(xué)習(xí)教父"Hinton的神經(jīng)網(wǎng)絡(luò)課程來(lái)進(jìn)一步理解神經(jīng)網(wǎng)絡(luò)。
接下來(lái)的內(nèi)容我們會(huì)具體闡述八種常見(jiàn)的神經(jīng)網(wǎng)絡(luò)架構(gòu),這應(yīng)該是每個(gè)機(jī)器學(xué)習(xí)從業(yè)者和研究者都應(yīng)該熟悉并掌握的工具。
神經(jīng)網(wǎng)絡(luò)的架構(gòu)主要分為三大類——前饋、循環(huán)和對(duì)稱鏈接網(wǎng)絡(luò)。
前饋網(wǎng)絡(luò)是最常見(jiàn)的架構(gòu),第一次負(fù)責(zé)輸入、最后一層負(fù)責(zé)輸出,中間的稱為隱藏層。如果有一層以上的隱藏層則稱為深度結(jié)構(gòu)。可以將每一層看做是一次變換,并在變換后利用非線性激活函數(shù)進(jìn)行激活。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNNs):在連接圖中表現(xiàn)的是一個(gè)循環(huán),它們的動(dòng)力學(xué)特性十分復(fù)雜并難以訓(xùn)練,但更真實(shí)地反映了生物真實(shí)的情況。有很多工作在尋找更高效的方法來(lái)訓(xùn)練網(wǎng)絡(luò)。這種網(wǎng)絡(luò)對(duì)于處理序列數(shù)據(jù)十分有效,其中每一個(gè)單元與深度網(wǎng)絡(luò)中的神經(jīng)元類似,但其在每一個(gè)時(shí)隙內(nèi)采用相同的權(quán)重,并在每一個(gè)時(shí)隙內(nèi)都接收輸入。他們同時(shí)還具有利用隱藏狀態(tài)記憶信息的能力。
對(duì)稱連接網(wǎng)絡(luò)與循環(huán)網(wǎng)絡(luò)類似,但單元間的鏈接對(duì)稱。他們遵循能量函數(shù)更容易分析。沒(méi)有隱藏層的對(duì)稱連接網(wǎng)絡(luò)成為Hopfield網(wǎng)絡(luò),有隱藏層的則稱為玻爾茲曼機(jī)(具體參見(jiàn)Hinton課程內(nèi)容)
三、八種核心神經(jīng)網(wǎng)絡(luò)架構(gòu)

1.感知機(jī)(Perceptrons)
感知機(jī)可以稱為第一代的神經(jīng)網(wǎng)絡(luò),主要包括輸入的多個(gè)特征單元(人工定義或程序?qū)ふ遥虚g由學(xué)習(xí)權(quán)重連接,最后由決策單元輸出。典型的感知機(jī)單元遵循前饋模型,輸入通過(guò)權(quán)重處理后直接連接到輸出單元上。
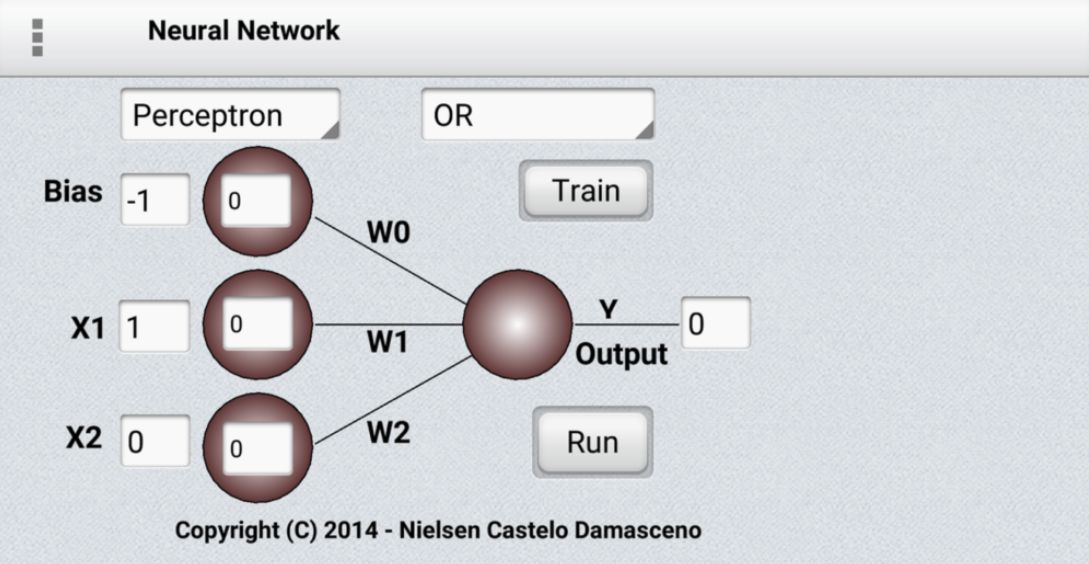
如果人們手動(dòng)選取足夠的有效特征,感知機(jī)幾乎可以做任何事。但一旦人工特征固定下來(lái)將會(huì)極大的限制感知機(jī)的學(xué)習(xí)能力。同時(shí)如何選擇一個(gè)好的、有效的特征也是困擾人們的難點(diǎn)。這對(duì)于感知機(jī)來(lái)說(shuō)是毀滅性的,由于感知機(jī)將所有的注意力放在了模式識(shí)別上而忽視了變換過(guò)程。Minsky和Papert的"群體不變性理論"指出無(wú)法通過(guò)學(xué)習(xí)來(lái)識(shí)別出一組變化中的變換過(guò)程。為了處理這樣的變換,感知機(jī)需要利用多特征單元來(lái)識(shí)別出變換。而這模式識(shí)別中最為復(fù)雜的一步則需要手工來(lái)完成特征提取,而不是學(xué)習(xí)。
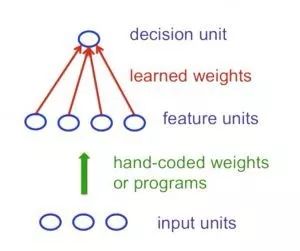
沒(méi)有隱藏層的神經(jīng)網(wǎng)絡(luò)在為輸入輸出映射建模的過(guò)程中具有很大的局限性。而更多層的線性單元似乎也沒(méi)有幫助,因?yàn)榫€性的疊加依舊是線性的。固定的非線性輸出也不足以建立復(fù)雜的映射關(guān)系。所以在感知機(jī)的基礎(chǔ)上我們需要建立多層具有適應(yīng)性非線性的隱藏單元網(wǎng)絡(luò)。但我們?cè)撊绾斡?xùn)練這樣的網(wǎng)絡(luò)呢?我們需要有效的方法來(lái)調(diào)整所有層而不僅僅是最后一層的權(quán)重。這十分困難,因?yàn)閷W(xué)習(xí)隱藏層的權(quán)重就等同于學(xué)習(xí)特征,但沒(méi)人會(huì)告訴你每個(gè)隱藏單元應(yīng)該做什么。這就需要更先進(jìn)的結(jié)構(gòu)來(lái)處理了!
2.卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks)
機(jī)器學(xué)習(xí)領(lǐng)域?qū)τ谀繕?biāo)識(shí)別和檢測(cè)進(jìn)行了多年的探索,問(wèn)題始終懸而未決的原因在于以下問(wèn)題始終困擾著物體的視覺(jué)識(shí)別:
分割、遮擋問(wèn)題
光照變化問(wèn)題
扭曲和形變問(wèn)題
同一類物體在功能性區(qū)別下的外形變化
視角不同帶來(lái)的困難
維度尺度帶來(lái)的問(wèn)題
這些問(wèn)題一直困擾著傳統(tǒng)的模式識(shí)別。人們闡釋手工創(chuàng)造各種各樣的特征來(lái)描述物體的特征,但結(jié)果總不盡如人意。熱別是在物體識(shí)別領(lǐng)域,輕微的變化就會(huì)造成結(jié)果的巨大差別。
圖 卷積網(wǎng)絡(luò)的可視化圖形
在感知機(jī)和多層感知機(jī)的基礎(chǔ)上,人們提出了一種新的網(wǎng)絡(luò)結(jié)構(gòu)——卷積神經(jīng)網(wǎng)絡(luò)。利用卷積神經(jīng)網(wǎng)絡(luò)可以對(duì)一些特征的檢測(cè)進(jìn)行共享,并在尺度和位置和方向上具有一定的不變性。較早的著名例子就是1998年Yann LeCun提出的一個(gè)稱為L(zhǎng)eNet的網(wǎng)絡(luò)進(jìn)行手寫(xiě)字符識(shí)別獲得了巨大的成功。下圖是LeNet的主要結(jié)構(gòu):一個(gè)包括卷積、池化和全連接的六層網(wǎng)絡(luò)結(jié)構(gòu)。
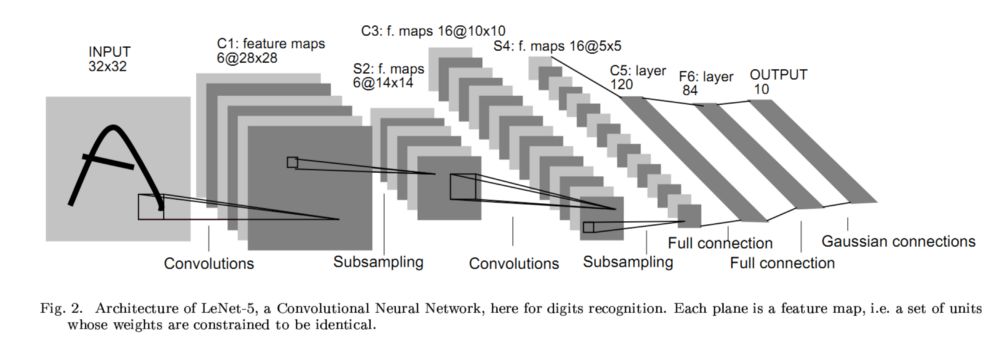
它利用反向傳播算法來(lái)對(duì)隱藏層的單元權(quán)重進(jìn)行訓(xùn)練,并在每個(gè)卷積層中實(shí)現(xiàn)了卷積操作的(卷積核)權(quán)值共享,并引入池化層實(shí)現(xiàn)了特征的縮聚(后面的網(wǎng)絡(luò)層具有較大的感受野),最后通過(guò)全連接層來(lái)實(shí)現(xiàn)輸出。
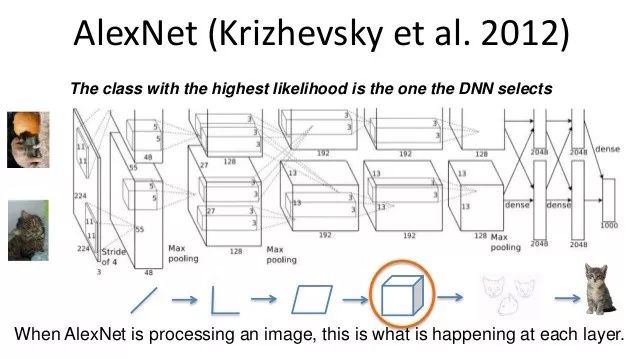
而后時(shí)間來(lái)到了ILSVRC2012年的比賽,由ImageNet提供了120萬(wàn)張的高清訓(xùn)練數(shù)據(jù),目的是訓(xùn)練一個(gè)可以分類出圖像屬于一千類中每一類的概率的模型,并以此來(lái)進(jìn)行圖像的識(shí)別。Hinton的學(xué)生Alex Krizhevsky最后奪魁。在LeNet的基礎(chǔ)上改進(jìn)了神經(jīng)網(wǎng)絡(luò),訓(xùn)練出了一個(gè)具有7個(gè)隱藏層深度網(wǎng)絡(luò),更深更強(qiáng)大的AlexNet,并引入了GPU進(jìn)行并行訓(xùn)練,極大的提高了深度學(xué)習(xí)模型的訓(xùn)練效率。自此GPU開(kāi)始進(jìn)入了廣大機(jī)器學(xué)習(xí)研究者的視野中。遠(yuǎn)超過(guò)第二名的成績(jī)展示了深度學(xué)習(xí)的強(qiáng)大魅力,也使得深度學(xué)習(xí)開(kāi)始走入了高速發(fā)展的快車道中。
3.循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network)
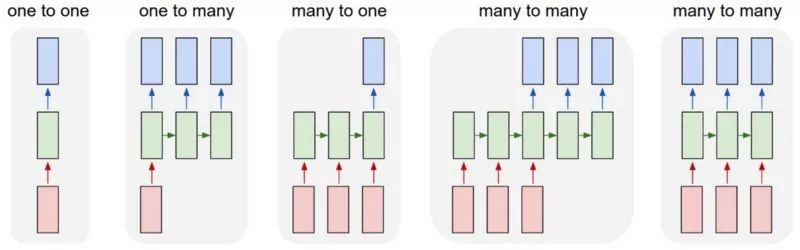
循環(huán)神經(jīng)網(wǎng)絡(luò)主要用于處理序列數(shù)據(jù)。在機(jī)器學(xué)習(xí)領(lǐng)域,序列模型一般利用序列數(shù)據(jù)作為輸入,來(lái)訓(xùn)練序列模型用于預(yù)測(cè)序列數(shù)據(jù)的下一項(xiàng)。在循環(huán)神經(jīng)網(wǎng)絡(luò)之前主要使用無(wú)記憶模型處理這類任務(wù)。
循環(huán)神經(jīng)網(wǎng)絡(luò)是一種十分有力的武器,它包含了兩個(gè)重要的特點(diǎn)。首先擁有一系列隱含狀態(tài)的分布可以高效的存儲(chǔ)過(guò)去的信息;其次它具有非線性動(dòng)力學(xué)可以允許它以復(fù)雜的方式更新隱藏狀態(tài)。在足夠的時(shí)間和神經(jīng)元數(shù)量下,RNN甚至可以計(jì)算出計(jì)算機(jī)能計(jì)算的任何東西。它們甚至?xí)憩F(xiàn)出振動(dòng)、牽引和混沌的行為。
然而循環(huán)神經(jīng)網(wǎng)絡(luò)的訓(xùn)練復(fù)雜,需要面對(duì)梯度消失或者爆炸的問(wèn)題。由于訓(xùn)練的RNN是一個(gè)很長(zhǎng)的序列模型,訓(xùn)練過(guò)程中的梯度十分容易出現(xiàn)問(wèn)題。即使在很好的初值下,它也很難檢測(cè)到目前的目標(biāo)和先前很多步前輸入間的聯(lián)系,所以循環(huán)神經(jīng)網(wǎng)絡(luò)處理長(zhǎng)程依賴性還十分困難。
目前主要有四種有效的方式實(shí)現(xiàn)循環(huán)神經(jīng)網(wǎng)絡(luò),主要包括長(zhǎng)短時(shí)記憶(Long Short Term Memory),海森自由優(yōu)化方法(Hessian Free Optimization),回聲狀態(tài)網(wǎng)絡(luò)(Echo State Networks)以及利用動(dòng)量的初始化(Good initialization with momentum)
4?.長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(Long/Short Term Memory Network)
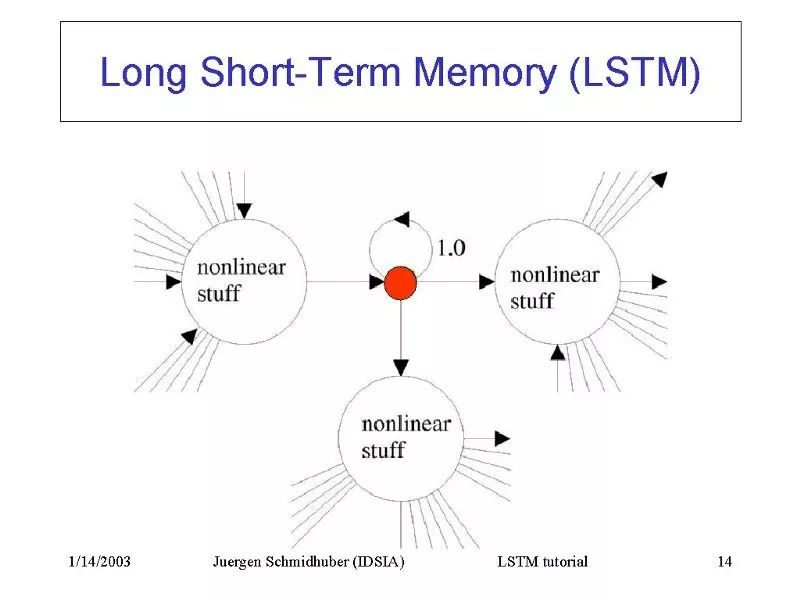
Hochreiter和Schmidhuber(1997)通過(guò)構(gòu)建長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM:Long Short Term Memory),解決了RNN長(zhǎng)時(shí)間記憶(如數(shù)百個(gè)時(shí)間步)的問(wèn)題。 他們使用相互作用的邏輯單元和線性單元來(lái)設(shè)計(jì)專門(mén)的存儲(chǔ)細(xì)胞(Memory Cell)。 當(dāng)“寫(xiě)入”門(mén)打開(kāi)時(shí),信息就可以進(jìn)入存儲(chǔ)細(xì)胞。 只要“保持”門(mén)處于開(kāi)啟狀態(tài),信息就會(huì)一直保留在存儲(chǔ)細(xì)胞中。開(kāi)啟“讀取”門(mén)就可以從細(xì)胞中讀取信息:RNN特別適合用于手寫(xiě)草書(shū)識(shí)別這樣的任務(wù)。通常會(huì)以筆尖坐標(biāo)x,y以及表示筆是向上還是向下的參數(shù)p作為輸入,輸出則是一段字符序列。Graves和Schmidhuber(2009)將LSTM結(jié)合到RNN中,得到了當(dāng)前草書(shū)識(shí)別的最佳結(jié)果。 不過(guò),他們使用小圖像序列而非筆尖坐標(biāo)序列作為輸入。
5. Hopfield網(wǎng)絡(luò)
帶有非線性單元的循環(huán)網(wǎng)絡(luò)通常是很難分析的,它們會(huì)以許多不同的方式表現(xiàn)出來(lái):穩(wěn)定狀態(tài),振蕩,或遵循不可預(yù)測(cè)的混沌軌跡。 Hopfield網(wǎng)絡(luò)由二進(jìn)制閾值單元反復(fù)連接組成。1982年,約翰·霍普菲爾德認(rèn)識(shí)到如果這種連接是對(duì)稱的,那就存在一個(gè)全局的能量函數(shù)。整個(gè)網(wǎng)絡(luò)每個(gè)二進(jìn)制單元的“配置”都對(duì)應(yīng)了能量的多與少,二進(jìn)制單元的閾值決策規(guī)則會(huì)讓網(wǎng)絡(luò)的配置朝著能量函數(shù)最小化的方向進(jìn)行。 使用這種類型的計(jì)算的一種簡(jiǎn)潔方法是使用存儲(chǔ)器作為神經(jīng)網(wǎng)絡(luò)的能量最小值,使用能量極小值的記憶提供了一個(gè)內(nèi)存關(guān)聯(lián)存儲(chǔ)器(CAM) 。項(xiàng)目只用知道其內(nèi)容的一部分便可實(shí)現(xiàn)訪問(wèn),可以有效應(yīng)對(duì)硬件損壞的情況。
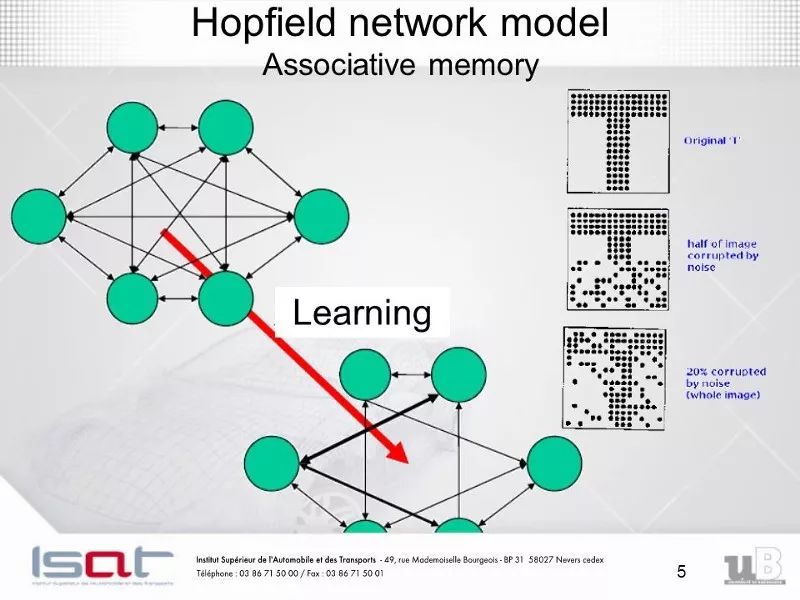
每當(dāng)我們記憶一次配置,我們希望得到一個(gè)新的能量最小值。 但是,一旦同時(shí)存在兩個(gè)最小值,怎么辦? 這就限制了Hopfield網(wǎng)絡(luò)的能力。 那么我們?nèi)绾卧黾親opfield網(wǎng)絡(luò)的能力呢? 物理學(xué)家們喜歡用已有的數(shù)學(xué)知識(shí)去解釋大腦的工作原理。 許多關(guān)于Hopfield網(wǎng)絡(luò)及其存儲(chǔ)能力的論文在物理學(xué)期刊上發(fā)表。最終,伊麗莎白·加德納(Elizabeth Gardner)發(fā)現(xiàn)了一個(gè)更好的存儲(chǔ)規(guī)則,它使用權(quán)重的全部容量。 她并不一次存儲(chǔ)所有向量,而是多次循環(huán)訓(xùn)練集,并利用感知器收斂過(guò)程來(lái)訓(xùn)練每個(gè)單元,使其具有正確的狀態(tài),給定該向量中所有其他單元的狀態(tài)。 統(tǒng)計(jì)學(xué)家稱這種技術(shù)為“擬似然估計(jì)”。
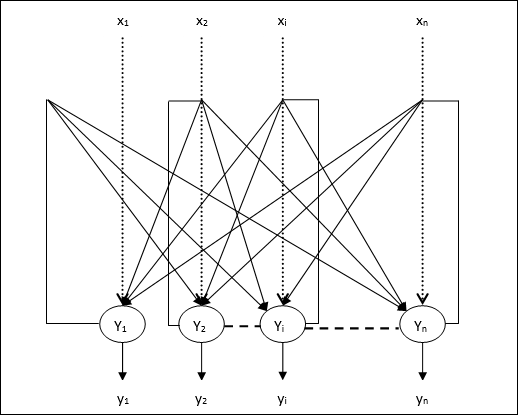
Hopfield網(wǎng)絡(luò)還有另一種計(jì)算角色。 我們并不用網(wǎng)絡(luò)來(lái)存儲(chǔ)記憶,而是用它來(lái)構(gòu)建感官輸入的演繹,用可見(jiàn)單元表示輸入,用隱層節(jié)點(diǎn)的狀態(tài)表示演繹,用能量表示演繹的好壞。
6?.玻爾茲曼機(jī)(Boltzmann Machine Network)
玻爾茲曼機(jī)是一種隨機(jī)遞歸神經(jīng)網(wǎng)絡(luò), 它可以被看作是Hopfield網(wǎng)絡(luò)隨機(jī)生成的, 它也是第一批能夠?qū)W習(xí)內(nèi)部表示、能夠表示和解決困難的組合學(xué)問(wèn)題的神經(jīng)網(wǎng)絡(luò)之一。
玻爾茲曼機(jī)學(xué)習(xí)算法的學(xué)習(xí)目標(biāo)是最大化玻爾茲曼機(jī)分配給訓(xùn)練集中的二進(jìn)制向量的概率乘積。這相當(dāng)于最大化了玻爾茲曼機(jī)分配給訓(xùn)練向量的對(duì)數(shù)概率之和。如果我們1)讓網(wǎng)絡(luò)在沒(méi)有外部輸入的情況下穩(wěn)定到N不同時(shí)間平穩(wěn)分布; 2)每次采樣一次可見(jiàn)向量,那也可以理解為最大化我們得到N個(gè)樣本的概率。
2012年,Salakhutdinov和Hinton提出了玻爾茲曼機(jī)的高效小批量學(xué)習(xí)程序。 對(duì)于正向,首先將隱藏概率初始化為0.5,然后將可見(jiàn)單元上的數(shù)據(jù)向量進(jìn)行固定,然后并行更新所有隱藏單元,直到使用平均場(chǎng)更新進(jìn)行收斂。 在網(wǎng)絡(luò)收斂之后,為每個(gè)連接的單元對(duì)記錄PiPj,并在最小批量中對(duì)所有數(shù)據(jù)進(jìn)行平均。 對(duì)于反向:首先保留一組“幻想粒子”,每個(gè)粒子的值都是全局配置。 然后依次更新每個(gè)幻想粒子中的所有單元幾次。 對(duì)于每個(gè)連接的單元對(duì),在所有的幻想粒子上平均SiSj。
在普通玻爾茲曼機(jī)中,單元的隨機(jī)更新是有序的。 有一個(gè)特殊的體系結(jié)構(gòu)允許更有效的交替并行更新(層內(nèi)無(wú)連接,無(wú)跨層連接)。 這個(gè)小批量程序使得玻爾茲曼機(jī)的更新更加并行化。 這就是所謂的深玻爾茲曼機(jī)器(DBM),一個(gè)帶有很多缺失連接的普通玻爾茲曼機(jī)。
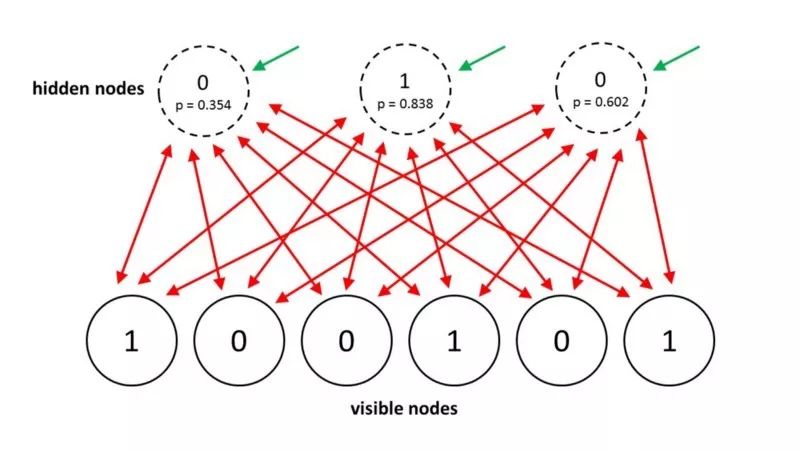
2014年,Salakhutdinov和Hinton為他們的模型提出了更新,稱之為受限玻爾茲曼機(jī)(Restricted Boltzmann Machines)。 他們限制連通性使得推理和學(xué)習(xí)變得更簡(jiǎn)單,隱藏單元只有一層,隱藏單元之間沒(méi)有連接。 在受限玻爾茲曼機(jī)中,當(dāng)可見(jiàn)單元被固定時(shí),只需要一步就能達(dá)到熱平衡。 另一個(gè)有效的小批量RBM學(xué)習(xí)程序是這樣的: 對(duì)于正向,首先將可見(jiàn)單元的數(shù)據(jù)向量固定。 然后計(jì)算所有可見(jiàn)和隱藏單元對(duì)的
7. 深度信念網(wǎng)絡(luò)(Deep Belief Network)
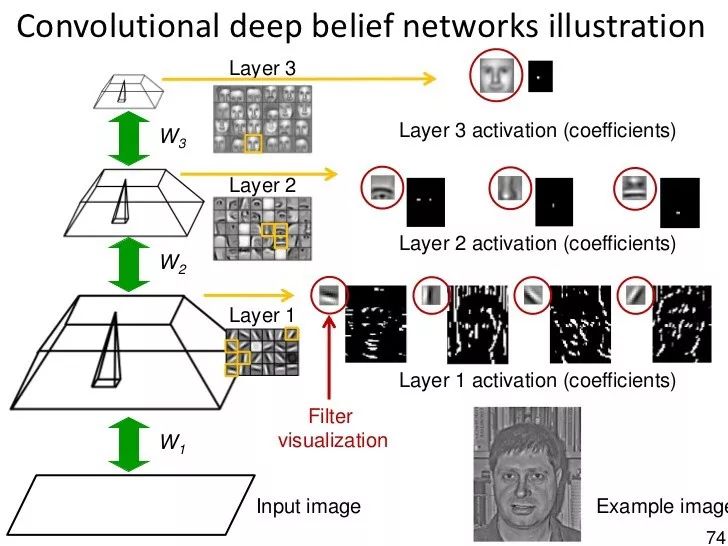
反向傳播被認(rèn)為是人工神經(jīng)網(wǎng)絡(luò)的標(biāo)準(zhǔn)方法,在處理數(shù)據(jù)后,計(jì)算每個(gè)神經(jīng)元的誤差貢獻(xiàn)。但是,使用反向傳播也存在一些很明顯的問(wèn)題。首先,它需要的數(shù)據(jù)是要標(biāo)注訓(xùn)練好的,但實(shí)際生活中幾乎所有的數(shù)據(jù)都是沒(méi)有標(biāo)注過(guò)的。其次,其學(xué)習(xí)的延展性不好,這意味著在具有多個(gè)隱藏層的網(wǎng)絡(luò)中,它的學(xué)習(xí)時(shí)間是非常慢的。第三,它很可能會(huì)被陷在一個(gè)局部最優(yōu)的位置,這對(duì)于深度網(wǎng)絡(luò)來(lái)說(shuō),遠(yuǎn)不是最優(yōu)解。
為了克服反向傳播的上述局限性,研究人員已經(jīng)考慮使用無(wú)監(jiān)督學(xué)習(xí)方法。這有助于保持使用梯度法調(diào)整權(quán)重的效率和簡(jiǎn)單性,同時(shí)也可以用于對(duì)感覺(jué)輸入的結(jié)構(gòu)進(jìn)行建模。尤其是可以通過(guò)調(diào)整權(quán)重來(lái)使得生成模型的輸入概率最大化。那么問(wèn)題就來(lái)了,我們應(yīng)該學(xué)習(xí)什么樣的生成模型?它能像Boltzmann機(jī)器那樣以能量為基礎(chǔ)嗎?它是一個(gè)非常理想的由神經(jīng)元組成的因果模型,還是兩者的混合?
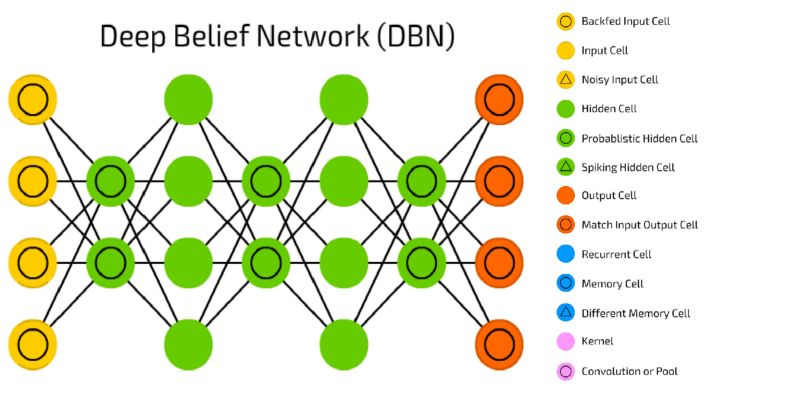
信念網(wǎng)絡(luò)(belief net)是由隨機(jī)變量構(gòu)成的有向無(wú)環(huán)圖。用信念網(wǎng)絡(luò),我們要觀察的一些變量和想要解決二個(gè)問(wèn)題是:推理的問(wèn)題——推斷未觀測(cè)的狀態(tài)變量,以及學(xué)習(xí)的問(wèn)題——調(diào)整變量之間的相互作用,使網(wǎng)絡(luò)更容易生成訓(xùn)練數(shù)據(jù)。
早期的圖形模型使用專家來(lái)定義圖形結(jié)構(gòu)和條件概率。當(dāng)時(shí)這些圖形是稀疏連接的;因此,研究人員最初專注于做正確的推斷,而不是學(xué)習(xí)。神經(jīng)網(wǎng)絡(luò)是以學(xué)習(xí)為中心的,自己死記硬背的知識(shí)并不酷,因?yàn)橹R(shí)來(lái)自于學(xué)習(xí)訓(xùn)練數(shù)據(jù)。神經(jīng)網(wǎng)絡(luò)的目的不是為了便于解釋,也不是為了讓推理變得簡(jiǎn)單。但即便如此,還是有神經(jīng)網(wǎng)絡(luò)版本的信念網(wǎng)絡(luò)。
由隨機(jī)二元神經(jīng)元組成的生成神經(jīng)網(wǎng)絡(luò)有兩種。一個(gè)是基于能量的,在此基礎(chǔ)上,我們利用對(duì)稱連接將二元隨機(jī)神經(jīng)元連接到一個(gè)波耳茲曼機(jī)器上。另一個(gè)是基于因果關(guān)系,我們?cè)谝粋€(gè)有向無(wú)環(huán)圖中連接二元隨機(jī)神經(jīng)元,得到一個(gè)s型信念網(wǎng)絡(luò)。這兩種類型的具體描述不再贅述。
8.深度自動(dòng)編碼器(DeepAuto-encoders)
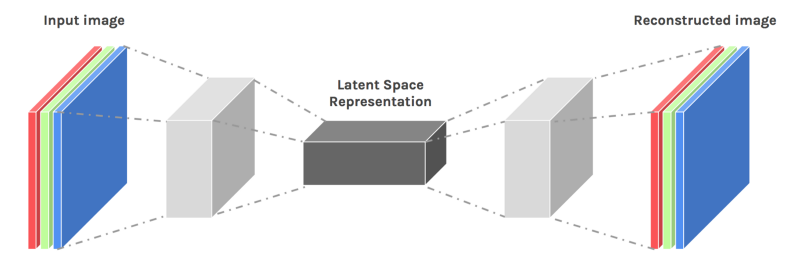
最后,讓我們討論一下deep auto-encoders。由于一些原因,它們看起來(lái)總是很好地進(jìn)行非線性降維,因?yàn)樗鼈兲峁┝藘煞N方式的靈活映射。在訓(xùn)練目標(biāo)的數(shù)量上,學(xué)習(xí)時(shí)間是線性的(或更好的)。最終的編碼模型是相當(dāng)緊湊快速的。然而,利用反向傳播來(lái)優(yōu)化深度自動(dòng)編碼器是非常困難的。初始權(quán)值小,后傳播梯度消失。我們現(xiàn)在有了更好的方法來(lái)優(yōu)化它們:要么使用無(wú)監(jiān)督的分層預(yù)訓(xùn)練,要么就像在回聲狀態(tài)網(wǎng)絡(luò)中一樣小心地初始化權(quán)重。
對(duì)于預(yù)訓(xùn)練任務(wù),主要有三種不同類型的shallow auto-encoders:
RBM
去噪自動(dòng)編碼器
壓縮自動(dòng)編碼器
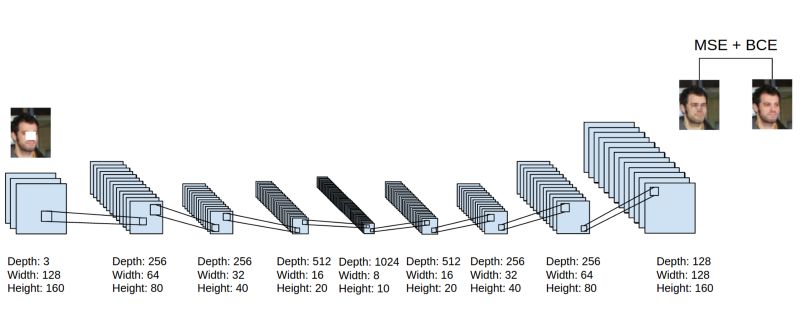
簡(jiǎn)單地說(shuō),現(xiàn)在有許多不同的方法來(lái)對(duì)特性進(jìn)行逐層預(yù)訓(xùn)練。對(duì)于沒(méi)有大量標(biāo)記案例的數(shù)據(jù)集,預(yù)訓(xùn)練有助于后續(xù)的鑒別學(xué)習(xí)。對(duì)于非常大的、已標(biāo)記的數(shù)據(jù)集,初始化在監(jiān)督學(xué)習(xí)中使用無(wú)監(jiān)督預(yù)訓(xùn)練的權(quán)值是不必要的,即使對(duì)于深網(wǎng)也是如此。所以預(yù)訓(xùn)練是初始化深網(wǎng)權(quán)重的最優(yōu)先方法,當(dāng)然現(xiàn)在還有其他方法。但是如果我們讓網(wǎng)絡(luò)變得更大,我們還將需要再次訓(xùn)練!
說(shuō)了這么多...
神經(jīng)網(wǎng)絡(luò)是有史以來(lái)最美麗的編程范例之一。在傳統(tǒng)的編程方法中,我們告訴計(jì)算機(jī)要做什么,將大問(wèn)題分解成許多小的、精確定義的任務(wù),計(jì)算機(jī)就可以輕松地執(zhí)行這些任務(wù)。相比之下,在神經(jīng)網(wǎng)絡(luò)中,我們不會(huì)告訴計(jì)算機(jī)如何解決我們的問(wèn)題。相反,它從觀察數(shù)據(jù)中學(xué)習(xí),找出自己解決問(wèn)題的方法。
今天,深度神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)、語(yǔ)音識(shí)別、自然語(yǔ)言處理等許多重要問(wèn)題上都取得了令人矚目的成績(jī)。它們廣泛應(yīng)用在了Google、微軟和Facebook等公司的部署中。
希望這篇文章對(duì)你學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)的核心概念能有所幫助!
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
104139 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8510瀏覽量
134921
原文標(biāo)題:作為機(jī)器學(xué)習(xí)研究者,你需要了解的八種神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門(mén)創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論