 Yann LeCun力挺觀點: AI 系統的輸入改進對 AI 性能改善的作用不大
Yann LeCun力挺觀點: AI 系統的輸入改進對 AI 性能改善的作用不大
什么是奇點(Singularity)?奇點是指在未來某個假想的時間點,因為技術發展太過迅速,以致于達到我們無法理解的地步。奇點被看成是人類無法達到的文明程度……一些我們不用指望能夠預測到的東西。
最近計算機科學教授 Edward W. Felten 在自己博客上發表了一篇文章,認為奇點還遠未到來,這一言論得到了 Yann LeCun 的強烈支持,我們將教授的原文做了翻譯。

為什么說奇點不是奇點?
英國數據家 I.J. Good 在 1965 年的一篇論文中對奇點理論進行了概括:
我們假設超智能機器是一種可以超越人類智慧的機器。既然這樣的一種機器是通過人類的智慧設計出來的,那么超智能機器也就能夠設計出更好的機器。這樣無疑會出現“智能大爆炸”,人類的智慧會遠遠落在后面。因此,如果超智能機器能夠告訴我們如何控制它,那么第一臺超智能機器也就是需要由人類發明的最后一臺機器。
Vernor Vinge 是第一個將這種理論描述為“奇點”的人,“奇點”的概念來自于數學,用于表示數量的增長達到了無限的速度。后來,Ray Kurzweil 將“奇點”一詞用在他的“奇點臨近(The Singularity is Near)”一書中,才為人們所熟知。
指數增長
奇點理論主要與未來機器智能的增長速度有關。不過,在深入探討這個理論之前,先讓我們來澄清一些與增長速度有關的概念。
指數增長是最為關鍵的一個概念,也就是說,事物的增長與其現有的規模呈比例關系。例如,如果我的銀行存款每年增長 1%,那么銀行每年要把當前余額的 1% 累加到賬戶中。這就是所謂的指數增長。
指數增長的速度各異,我們可以使用兩種方式來表示指數增長速度。第一種是增長速率,通常表示為單位時間內的百分比。例如,銀行存款的增長速率為每年 1%。第二種是倍增時間,也就是數量翻番需要多少時間。例如,我的銀行存款要翻番需要大概 70 年時間。
要想知道一個數量是否呈指數級增長,最好的辦法是使用上述的兩種方式來衡量它。如果它符合上述中的任何一種模式,那么它就是呈指數級增長。例如,大部分國家都通過 GDP 來衡量經濟增長,當然,GDP 在短期內可能會有起伏,但從長期來看,它是呈指數級增長的。如果一個國家的 GDP 每年增長 3%,那么大概 23 年就可以翻一番。
指數增長在人類社會和自然界中都是很常見的。所以,一個呈指數級增長的數量并不會讓自己變得有任何特別之處,也不會出現任何違反直覺的變化。
計算機的速度和容量也是呈指數級增長的,這也沒有什么新奇的。新奇的是計算機容量的增長速率。“摩爾定律”告訴我們,計算機的速度和容量每 18 個月就會翻一番,相當于每年 60% 的增長速率。摩爾定律在過去 50 年被證明是正確的,計算機容量整整翻了 33 番,也就是差不多百億倍。
奇點并非實際意義上的奇點
在討論奇點假設的真實性之前,先讓我們來看看實際意義上的奇點——在未來某個時間點,機器智能的改進速率趨向于無窮。這就要求機器智能的增長速度超過指數級,翻番的時間就會縮短,最后趨向于零。
實際意義上的奇點可能并沒有任何理論依據。在人類社會和自然世界根本不存在超指數增長的東西,而即使有,也不可能達到真實意義上的奇點。簡單地說,人工智能的“奇點”不可能變成現實。
如果說奇點不是真正意義上的奇點,那它會是什么?
為何自我改進還不夠?
我們在上面討論了為何不可能存在單一的奇點——換言之,為何 AI 不可能擁有無限的增長率。那么如果奇點并不單一,那又會呈現出怎樣的形式?
首先來回顧奇點理論,其基本上屬于一項關于機器智能增長率的主張。在排除了指數級以上增長的可能性之后,其主要假設在于認為 AI 技術將以指數形式增長。
指數級增長并不代表著發生“爆炸式”發展。舉例來說,盡管我的儲蓄帳戶擁有 1% 的利率并實現持續增長,但我本人并不會因此迎來“財富爆炸”,即突然之間獲得超出想象的資金數額。但是如果指數級增長率非常高,是否會帶來爆炸式增長?
在這方面,我認為摩爾定律是最理想的類比對象。在過去幾十年當中,計算能力一直以 60% 的年增長率保持著穩定發展,換言之即第 18 個月翻一番。這意味著 這數十年周期內的計算能力提升了約 100 億倍。這雖然是一項了不起的成就,但卻仍 無法從根本上改變人類的生存法則。事實上,這種增長對社會與經濟的影響屬于漸進式推動。
計算能力增長一百億倍,仍無法令我們獲得百倍于以往的幸福感,其中的原因可謂顯而易見——計算能力并不是我們的核心。為了讓計算能力轉化為我們的幸福感,人類必須想辦法利用計算資源改進我們最關心的方方面面——這顯然非常困難。
更重要的是,將計算能力轉化為幸福感的努力似乎總是面臨著回報快速衰減的難題。舉例來說,計算能力每增加一倍,我們都能夠通過發現新型藥物來更好地評估醫學診療效果或者更高效地改善人類健康水平。然而其最終結果是,健康改善更像是關于我們身體的一種儲蓄帳戶,而非摩爾定律。
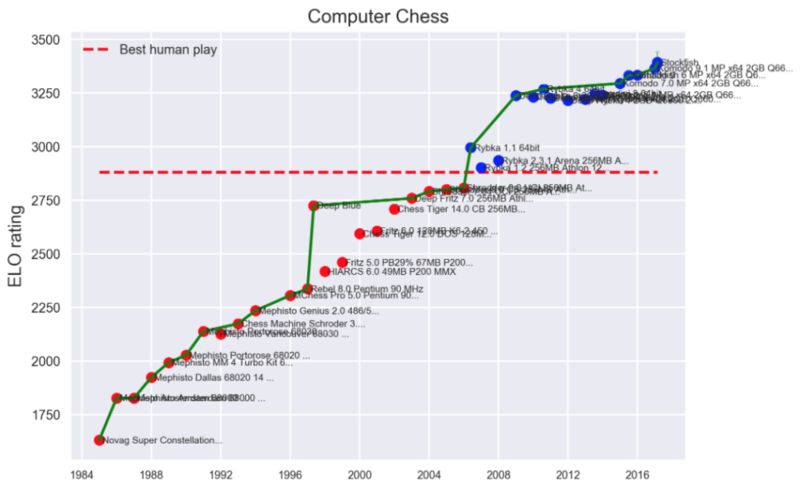
以下一項 AI 實例。圖中所示為上世紀八十年代到現在計算機在國際象棋領域的表現提升趨勢。垂直軸所示為 Elo 等級,好衡量象棋技巧的自然度量,其定義為如果 A 的 Elo 點數比 B 高 100 點,則 A 在與 B 對局時的勝率則為 64%。
盡管計算能力呈指數級增長,且算法性能同樣保持著指數級增長趨勢,但其勝率結果在過去三十年當中仍然保持著顯著的線性關系。這意味著雖然 AI 在國際象棋層面的改進速度擁有指數級特性,但所產出的自然度量卻僅僅能夠實現線性提升。
那么這一切對于奇點理論又意味著什么?請考慮智能爆炸這一論點的核心所在——正如谷歌公司在其經典論文中所言:
……一臺超級智能機器如果能夠設計出更好的機器,那么其無疑將引發一場“智能爆炸”……
如果“設計出更好的機器”被具象為下國際象棋,那么輸入內容(即機器智能)的指數級改進為何只會帶來輸出結果(即機器在設計其它機器時的效能)的線性改進?即使如此,那么智能爆炸的論斷顯然并不準確。事實上,機器智能的增長將僅僅保持線性水平。(我們可以從數學角度進行理解:如果我們假定智能的導數與 log(智能)成正比,那么智能在時間 T 上的增長將遵循 T log(T),幾乎與 T 的線性保持一致。)
那么設計新機器是否能夠與下國際象棋這樣的行為進行類比?對此,我們并不確定。這是復雜性計算理論中的一個難題,其本質在于討論隨著計算資源的增加,究竟能夠達到多少目標。在通過比大多數人更為深入的復雜性理論研究之后,我們發現機器設計也同樣會呈現國際象棋當中所出現的這種收益遞減狀況。無論如何,這種可能性確實令我們有理由對谷歌提出的自我改進“無疑”將帶來智能爆炸這一結論感到懷疑。
因此,奇點理論家們有責任解釋為什么機器設計能夠表現出引起智能爆炸所需要的這種反饋回路——而非像國際象棋那樣遵循收益線性增長。
奇點為何仍未真實發生?
我認為,有時 AI 系統(計算機速度和算法)的輸入改進對 AI 性能改善的作用不大。
有人對此持有各種反對意見。有人說,計算機國際象棋 Elo 評級水平提升應該是指數級的增長;有人說,新 AI 程序 AlphaZero 的到來(我未在我的帖子中討論過它)改變了游戲規則,有力地證明了我的論點無效。下面我來一一反駁這些反對意見。
首先,我們來談談我們是如何衡量人工智能的性能的。對于國際象棋,我使用了 Elo 評級,這個等級評定的規則是,如果玩家 A 比玩家 B 高 100 分,我們預計 A 玩家在和 B 玩家對局時可以得到 64%的分數(贏得游戲得一分,平局每個玩家得 0.5 分,輸的一方得零點。)
有一個可以代替 Elo 的評級系統,我稱其為 ExpElo,它的預測結果與 Elo 相差無幾。Explo 評級是 Elo 評分的乘方。Elo 使用兩位選手的評分來預測勝率,ExpElo 則使用評分的比例來進行預測。從抽象的數學角度來看,Elo 和 ExpElo 的預測能力旗鼓相當,而且預測結果完全相同。但是,如果說 Elo 的提升是呈線性的,則 ExpElo 的改進則是呈指數級的。所以,國際象棋的成績是線性的還是指數性的?
在解決這個問題之前,讓我們停下來思考一下,這種情況并不是國際象棋獨有的。任何線性增長的度量都可以重新調整(通過對度量求冪),以得到一個指數級增長的新度量。而且,任何指數級增長的度量都可以重新調整(通過取對數)來獲得線性增長的新度量。因此,對于任何改進的數量,我們將始終能夠從線性增長和指數增長中做出選擇。
人工智能的關鍵問題是:衡量某個特定任務的“智力”水平最合適的標準是什么?對于國際象棋來說,我認為是 Elo(而不是 ExpElo)。此前,Arpad Elo 推出了被專業象棋人員采用的 Elo 系統。美國國際象棋聯合會按照技能將玩家分大師、專家、A 級、B 級、C 級等級別,而我們選擇用 Elo 為人類國際象棋玩家進行分類。那么,為什么當談到 AI 時,我們應該換一個不同的度量呢?
轉折就發生在這里:隨著電腦的發揮水平接近完美,而實際上人類永遠不可能達到完美的水平,因此,無論是 Elo 還是 ExpElo 在國際象棋中的評級的作用將趨于穩定。
在每一場棋局中,都有一些可能得到最佳游戲結果的最佳棋路(或移動)。對于一個非常強大的玩家,我們可能會問他的錯誤率是多少:即在高水平的比賽中,他會在什么情況下走錯棋路?
假設一個玩家愛麗絲的錯誤率為 1%,并假設一盤棋持續了五十回合。那么從長遠來看,愛麗絲每兩場比賽就會走一次非最優的棋步,在一半的比賽中,她將以最佳狀態進行比賽。這意味著,如果愛麗絲與上帝進行一場國際象棋比賽(總是走最佳棋路),那么愛麗絲將得到至少 25%的分數,因為她會在半場比賽以最佳棋路與上帝對弈,在最糟糕的情況下,她會在犯錯誤的比賽中輸掉。如果愛麗絲能夠得到至少 25%的分數,那么愛麗絲的 Elo 評級將不會比上帝低 200 分。結果是,類似于 “上帝的評級”將無人可以超越,在 Elo 和 ExpElo 系統中都是如此。
Ken Regan 等人的研究表明,今天最好的國際象棋程序的錯誤率相當低,可以說正在接近“上帝的評級”。Regan 的研究表明,RoG 的評分約為 3600,這很值得注意,因為據我所知,最好的程序 Stockfish 的評分約為 3400,Google 的 DeepMind 研發的新 AI 棋手 AlphaZero 可能在 3500 左右。如果 Regan 的估計是正確的,那么 AlphaZero 就會在與上帝比賽中的大部分時間以最佳的棋路與其對弈,得到大約 36%的分數。AI Elo 評級的歷史增長率為每年 50 分,所以看起來增長的趨勢可能會持續幾年,然后才會趨于平穩。目前,不管國際象棋評級分數增長趨勢到底是呈線性還是指數級,似乎在幾年內都會趨于平緩。
-
AI
+關注
關注
87文章
30763瀏覽量
268910 -
奇點
+關注
關注
0文章
4瀏覽量
1893
原文標題:Yann LeCun力挺觀點:算法對AI提升不大,奇點仍然很遙遠
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HiSpark IPC AI攝像頭(Hi3518E)串口能輸入輸出嗎?
生成式AI工具作用
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得

AI芯片的混合精度計算與靈活可擴展
刷新AI PC NPU算力,AMD銳龍AI 9 HX 375領銜55 TOPS





 工商網監
工商網監
評論