 谷歌探討了如果分類器不再僅限于微小的改變,最終輸出會是什么結果
谷歌探討了如果分類器不再僅限于微小的改變,最終輸出會是什么結果
深度學習系統很容易受到生成樣本的攻擊,對輸入的參數進行細微的改變會導致網絡輸出變化,但人類肉眼卻看不出什么差別。通常,這些對抗樣本只對每個像素做少量調整,或者修改圖像中少量像素。也就是說,大部分對抗樣本都將重點放在對輸入數據極小或不易察覺的改變上。
在這篇論文中,谷歌的研究人員探討了如果分類器不再僅限于微小的改變,最終輸出會是什么結果。他們構建了一個獨立于圖像的補丁,能讓神經網絡做出非常明顯的反應。這個補丁可以放置在分類器視野內的任何地方,并讓分類器輸出一個目標類。因為這個補丁是獨立于場景的,所以攻擊樣本無需提前了解光照條件、相機角度、分類器類型以及其他信息。
在VGG16上,用打印出的補丁對分類器進行攻擊。分類器先將圖片以97%的概率識別為“香蕉”;在下圖添加補丁后,分類器以99%的概率將其識別為“烤面包機”
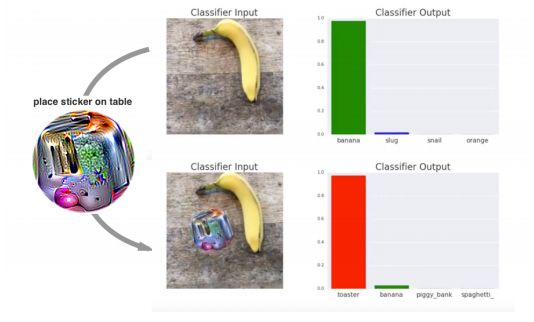
生成對抗補丁之后,補丁可以發布到網上供其他人打印或使用。此外,由于攻擊會使用較大的擾動,目前的防御技術主要是針對較小擾動的,面對大擾動也許會不穩定。最近的研究表明,在MNIST上最先進的對抗訓練模型仍然容易受到較大擾動的影響。
與以往不同,研究人員將補丁作為圖像的一部分作為攻擊,它可以變成任意形狀,然后訓練各種類型的圖像,在每個圖像上隨機變換、縮放并旋轉補丁,使用梯度下降進行優化。
假設圖片x∈Rw×h×c,補丁為p,補丁位置l,補丁變換為t,將補丁應用操作器(patch application operator)定義為A(p,x,l,t)。

操作器輸入一個補丁、一個圖片、一個位置以及任何補丁的變換,然后進行訓練,優化識別出正確類別的概率。
為了得到訓練后的補丁P^,我們在目標函數上訓練:
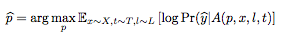
X表示正在訓練的一套圖像,T是經過變換的補丁分布,L是圖像位置的分布。
研究人員認為這種攻擊利用了圖像分類任務的構建方式。雖然圖像可能包含多個對象,但只有一個目標標簽是正確的。所以網絡必須學會檢測每一幀最“明顯”的項目。對抗補丁通過生成比現實世界中的物體更顯著的輸入來利用這一特征。因此,在目標檢測或圖像分割模型受到攻擊時,我們希望烤面包機補丁能被分類為烤面包機,而不影響圖像的其他部分。

不同方法創造出對抗補丁的比較。成功率是將補丁放在圖片頂部計算的。每張圖片都經歷了400張位置不同的補丁測試;同時又經歷了400張不同大小補丁照片的測試
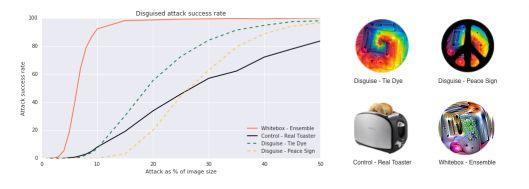
偽裝成不同類別的補丁比較。研究人員發現他們可以改變補丁的樣式,但仍然能騙過分類器
結果表明,這個通用、穩定、有針對性的補丁無論放在圖片的哪個位置,都能成功騙過分類器,而且不需要提前了解場景信息。這些補丁還可以打印出來,在許多地方通用。
-
谷歌
+關注
關注
27文章
6161瀏覽量
105300 -
分類器
+關注
關注
0文章
152瀏覽量
13179 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:谷歌推出對抗補丁,可導致分類器輸出任意目標類
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADS805E數字輸入信號最小要3.5V,這個僅限于時鐘信號CLK還是同時包括了輸出使能信號OE?
言必信電源濾波器的適用性:不僅僅局限于用電穩定且消耗小的器材

XTR108電路輸出電流永遠是2mA左右,改變配置參數會有微小變動,為什么?
豐田與比亞迪合作僅限BEV領域,廣汽豐田無DMI插混項目?
簡單電源恢復報警電路說明
流量傳感器(1)差壓式流量傳感器說明
Windows 11預覽版禁用"已連接設備"選項
小鵬P7價格下探至14.09萬元,優惠僅限于新車
為什么稱重傳感器接大地,且系統使用開關電源供電時,AD 值會亂跳?
機器學習多分類任務深度解析
cyusb3014枚舉的工作原理是什么?如果下載固件后不枚舉,可能會是什么原因,原理是什么?
谷歌用AI創作新聞引發爭議,與部分出版商達成合作協議
電源設計如果只看電壓跌落,不看電流密度會怎么樣?

千兆位多媒體串行鏈路SerDes IC推動汽車安全和信息娛樂系統發展





 工商網監
工商網監
評論