 從五個步驟來講解Redis架構設計
從五個步驟來講解Redis架構設計
摘要:本文章主要分成五個步驟內容講解
Redis、RedisCluster和Codis;
我們更愛一致性;
Codis在生產環境中的使用的經驗和坑們;
對于分布式數據庫和分布式架構的一些看法;
Q & A環節。
Codis是一個分布式Redis解決方案,與官方的純P2P的模式不同,Codis采用的是Proxy-based的方案。今天我們介紹一下Codis及下一個大版本RebornDB的設計,同時會介紹一些Codis在實際應用場景中的tips。最后拋磚引玉,會介紹一下我對分布式存儲的一些觀點和看法,望各位首席們雅正。
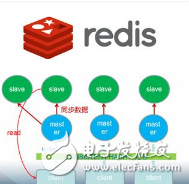
一、 Redis,RedisCluster和Codis
Redis:想必大家的架構中,Redis已經是一個必不可少的部件,豐富的數據結構和超高的性能以及簡單的協議,讓Redis能夠很好的作為數據庫的上游緩存層。但是我們會比較擔心Redis的單點問題,單點Redis容量大小總受限于內存,在業務對性能要求比較高的情況下,理想情況下我們希望所有的數據都能在內存里面,不要打到數據庫上,所以很自然的就會尋求其他方案。 比如,SSD將內存換成了磁盤,以換取更大的容量。更自然的想法是將Redis變成一個可以水平擴展的分布式緩存服務,在Codis之前,業界只有Twemproxy,但是Twemproxy本身是一個靜態的分布式Redis方案,進行擴容/縮容時候對運維要求非常高,而且很難做到平滑的擴縮容。Codis的目標其實就是盡量兼容Twemproxy的基礎上,加上數據遷移的功能以實現擴容和縮容,最終替換Twemproxy。從豌豆莢最后上線的結果來看,最后完全替換了Twem,大概2T左右的內存集群。
Redis Cluster :與Codis同期發布正式版的官方cluster,我認為有優點也有缺點,作為架構師,我并不會在生產環境中使用,原因有兩個:
cluster的數據存儲模塊和分布式的邏輯模塊是耦合在一起的,這個帶來的好處是部署異常簡單,all-in-the-box,沒有像Codis那么多概念,組件和依賴。但是帶來的缺點是,你很難對業務進行無痛的升級。比如哪天Redis cluster的分布式邏輯出現了比較嚴重的bug,你該如何升級?除了滾動重啟整個集群,沒什么好辦法。這個比較傷運維。
對協議進行了較大的修改,對客戶端不太友好,目前很多客戶端已經成為事實標準,而且很多程序已經寫好了,讓業務方去更換Redisclient,是不太現實的,而且目前很難說有哪個Rediscluster客戶端經過了大規模生產環境的驗證,從HunanTV開源的Rediscluster proxy上可以看得出這個影響還是蠻大的,否則就會支持使用cluster的client了。
Codis:和Redis cluster不同的是,Codis采用一層無狀態的proxy層,將分布式邏輯寫在proxy上,底層的存儲引擎還是Redis本身(盡管基于Redis2.8.13上做了一些小patch),數據的分布狀態存儲于zookeeper(etcd)中,底層的數據存儲變成了可插拔的部件。這個事情的好處其實不用多說,就是各個部件是可以動態水平擴展的,尤其無狀態的proxy對于動態的負載均衡,還是意義很大的,而且還可以做一些有意思的事情,比如發現一些slot的數據比較冷,可以專門用一個支持持久化存儲的server group來負責這部分slot,以節省內存,當這部分數據變熱起來時,可以再動態的遷移到內存的server group上,一切對業務透明。比較有意思的是,在Twitter內部棄用Twmeproxy后,t家自己開發了一個新的分布式Redis解決方案,仍然走的是proxy-based路線。不過沒有開源出來。可插拔存儲引擎這個事情也是Codis的下一代產品RebornDB在做的一件事情。btw,RebornDB和它的持久化引擎都是完全開源的,見https://github.com/reborndb/reborn和https://github.com/reborndb/qdb。當然這樣的設計的壞處是,經過了proxy,多了一次網絡交互,看上去性能下降了一些,但是記住,我們的proxy是可以動態擴展的,整個服務的QPS并不由單個proxy的性能決定(所以生產環境中我建議使用LVS/HA Proxy或者Jodis),每個proxy其實都是一樣的。
二、我們更愛一致性
很多朋友問我,為什么不支持讀寫分離,其實這個事情的原因很簡單,因為我們當時的業務場景不能容忍數據不一致,由于Redis本身的replication模型是主從異步復制,在master上寫成功后,在slave上是否能讀到這個數據是沒有保證的,而讓業務方處理一致性的問題還是蠻麻煩的。而且Redis單點的性能還是蠻高的,不像mysql之類的真正的數據庫,沒有必要為了提升一點點讀QPS而讓業務方困惑。這和數據庫的角色不太一樣。所以,你可能看出來了,其實Codis的HA,并不能保證數據完全不丟失,因為是異步復制,所以master掛掉后,如果有沒有同步到slave上的數據,此時將slave提升成master后,剛剛寫入的還沒來得及同步的數據就會丟失。不過在RebornDB中我們會嘗試對持久化存儲引擎(qdb)可能會支持同步復制(syncreplication),讓一些對數據一致性和安全性有更強要求的服務可以使用。
說到一致性,這也是Codis支持的MGET/MSET無法保證原本單點時的原子語義的原因。 因為MSET所參與的key可能分不在不同的機器上,如果需要保證原來的語義,也就是要么一起成功,要么一起失敗,這樣就是一個分布式事務的問題,對于Redis來說,并沒有WAL或者回滾這么一說,所以即使是一個最簡單的二階段提交的策略都很難實現,而且即使實現了,性能也沒有保證。所以在Codis中使用MSET/MGET其實和你本地開個多線程SET/GET效果一樣,只不過是由服務端打包返回罷了,我們加上這個命令的支持只是為了更好的支持以前用Twemproxy的業務。
在實際場景中,很多朋友使用了lua腳本以擴展Redis的功能,其實Codis這邊是支持的,但記住,Codis在涉及這種場景的時候,僅僅是轉發而已,它并不保證你的腳本操作的數據是否在正確的節點上。比如,你的腳本里涉及操作多個key,Codis能做的就是將這個腳本分配到參數列表中的第一個key的機器上執行。所以這種場景下,你需要自己保證你的腳本所用到的key分布在同一個機器上,這里可以采用hashtag的方式。
比如你有一個腳本是操作某個用戶的多個信息,如uid1age,uid1sex,uid1name形如此類的key,如果你不用hashtag的話,這些key可能會分散在不同的機器上,如果使用了hashtag(用花括號擴住計算hash的區域):{uid1}age,{uid1}sex,{uid1}name,這樣就保證這些key分布在同一個機器上。這個是twemproxy引入的一個語法,我們這邊也支持了。
在開源Codis后,我們收到了很多社區的反饋,大多數的意見是集中在Zookeeper的依賴,Redis的修改,還有為啥需要Proxy上面,我們也在思考,這幾個東西是不是必須的。當然這幾個部件帶來的好處毋庸置疑,上面也闡述過了,但是有沒有辦法能做得更漂亮。于是,我們在下一階段會再往前走一步,實現以下幾個設計:
使用proxy內置的Raft來代替外部的Zookeeper,zk對于我們來說,其實只是一個強一致性存儲而已,我們其實可以使用Raft來做到同樣的事情。將raft嵌入proxy,來同步路由信息。達到減少依賴的效果。
抽象存儲引擎層,由proxy或者第三方的agent來負責啟動和管理存儲引擎的生命周期。具體來說,就是現在codis還需要手動的去部署底層的Redis或者qdb,自己配置主從關系什么的,但是未來我們會把這個事情交給一個自動化的agent或者甚至在proxy內部集成存儲引擎。這樣的好處是我們可以最大程度上的減小Proxy轉發的損耗(比如proxy會在本地啟動Redis instance)和人工誤操作,提升了整個系統的自動化程度。
還有replication based migration。眾所周知,現在Codis的數據遷移方式是通過修改底層Redis,加入單key的原子遷移命令實現的。這樣的好處是實現簡單、遷移過程對業務無感知。但是壞處也是很明顯,首先就是速度比較慢,而且對Redis有侵入性,還有維護slot信息給Redis帶來額外的內存開銷。大概對于小key-value為主業務和原生Redis是1:1.5的比例,所以還是比較費內存的。
在RebornDB中我們會嘗試提供基于復制的遷移方式,也就是開始遷移時,記錄某slot的操作,然后在后臺開始同步到slave,當slave同步完后,開始將記錄的操作回放,回放差不多后,將master的寫入停止,追平后修改路由表,將需要遷移的slot切換成新的master,主從(半)同步復制,這個之前提到過。
三、Codis在生產環境中的使用的經驗和坑們
來說一些 tips,作為開發工程師,一線的操作經驗肯定沒有運維的同學多,大家一會可以一起再深度討論。
關于多產品線部署:很多朋友問我們如果有多個項目時,codis如何部署比較好,我們當時在豌豆莢的時候,一個產品線會部署一整套codis,但是zk共用一個,不同的codis集群擁有不同的product name來區分,codis本身的設計沒有命名空間那么一說,一個codis只能對應一個product name。不同product name的codis集群在同一個zk上不會相互干擾。
關于zk:由于Codis是一個強依賴的zk的項目,而且在proxy和zk的連接發生抖動造成sessionexpired的時候,proxy是不能對外提供服務的,所以盡量保證proxy和zk部署在同一個機房。生產環境中zk一定要是>=3臺的奇數臺機器,建議5臺物理機。
關于HA:這里的HA分成兩部分,一個是proxy層的HA,還有底層Redis的HA。先說proxy層的HA。之前提到過proxy本身是無狀態的,所以proxy本身的HA是比較好做的,因為連接到任何一個活著的proxy上都是一樣的,在生產環境中,我們使用的是jodis,這個是我們開發的一個jedis連接池,很簡單,就是**zk上面的存活proxy列表,挨個返回jedis對象,達到負載均衡和HA的效果。也有朋友在生產環境中使用LVS和HA Proxy來做負載均衡,這也是可以的。 Redis本身的HA,這里的Redis指的是codis底層的各個server group的master,在一開始的時候codis本來就沒有將這部分的HA設計進去,因為Redis在掛掉后,如果直接將slave提升上來的話,可能會造成數據不一致的情況,因為有新的修改可能在master中還沒有同步到slave上,這種情況下需要管理員手動的操作修復數據。后來我們發現這個需求確實比較多的朋友反映,于是我們開發了一個簡單的ha工具:codis-ha,用于監控各個server group的master的存活情況,如果某個master掛掉了,會直接提升該group的一個slave成為新的master。 項目的地址是:https://github.com/ngaut/codis-ha。
關于dashboard:dashboard在codis中是一個很重要的角色,所有的集群信息變更操作都是通過dashboard發起的(這個設計有點像docker),dashboard對外暴露了一系列RESTfulAPI接口,不管是web管理工具,還是命令行工具都是通過訪問這些httpapi來進行操作的,所以請保證dashboard和其他各個組件的網絡連通性。比如,經常發現有用戶的dashboard中集群的ops為0,就是因為dashboard無法連接到proxy的機器的緣故。
關于go環境:在生產環境中盡量使用go1.3.x的版本,go的1.4的性能很差,更像是一個中間版本,還沒有達到production ready的狀態就發布了。很多朋友對go的gc頗有微詞,這里我們不討論哲學問題,選擇go是多方面因素權衡后的結果,而且codis是一個中間件類型的產品,并不會有太多小對象常駐內存,所以對于gc來說基本毫無壓力,所以不用考慮gc的問題。
關于隊列的設計:其實簡單來說,就是「不要把雞蛋放在一個籃子」的道理,盡量不要把數據都往一個key里放,因為codis是一個分布式的集群,如果你永遠只操作一個key,就相當于退化成單個Redis實例了。很多朋友將Redis用來做隊列,但是Codis并沒有提供BLPOP/BLPUSH的接口,這沒問題,可以將列表在邏輯上拆成多個LIST的key,在業務端通過定時輪詢來實現(除非你的隊列需要嚴格的時序要求),這樣就可以讓不同的Redis來分擔這個同一個列表的訪問壓力。而且單key過大可能會造成遷移時的阻塞,由于Redis是一個單線程的程序,所以遷移的時候會阻塞正常的訪問。
關于主從和bgsave:codis本身并不負責維護Redis的主從關系,在codis里面的master和slave只是概念上的:proxy會將請求打到「master」上,master掛了codis-ha會將某一個「slave」提升成master。而真正的主從復制,需要在啟動底層的Redis時手動的配置。在生產環境中,我建議master的機器不要開bgsave,也不要輕易的執行save命令,數據的備份盡量放在slave上操作。
關于跨機房/多活:想都別想。。。codis沒有多副本的概念,而且codis多用于緩存的業務場景,業務的壓力是直接打到緩存上的,在這層做跨機房架構的話,性能和一致性是很難得到保證的
關于proxy的部署:其實可以將proxy部署在client很近的地方,比如同一個物理機上,這樣有利于減少延遲,但是需要注意的是,目前jodis并不會根據proxy的位置來選擇位置最佳的實例,需要修改。
四、對于分布式數據庫和分布式架構的一些看法(one more Thing)
Codis相關的內容告一段落。接下來我想聊聊我對于分布式數據庫和分布式架構的一些看法。 架構師們是如此貪心,有單點就一定要變成分布式,同時還希望盡可能的透明:P。就MySQL來看,從最早的單點到主從讀寫分離,再到后來阿里的類似Cobar和TDDL,分布式和可擴展性是達到了,但是犧牲了事務支持,于是有了后來的OceanBase。Redis從單點到Twemproxy,再到Codis,再到Reborn。到最后的存儲早已和最初的面目全非,但協議和接口永存,比如SQL和Redis Protocol。
NoSQL來了一茬又一茬,從HBase到Cassandra到MongoDB,解決的是數據的擴展性問題,通過裁剪業務的存儲和查詢的模型來在CAP上平衡。但是幾乎還是都丟掉了跨行事務(插一句,小米上在HBase上加入了跨行事務,不錯的工作)。
我認為,拋開底層存儲的細節,對于業務來說,KV,SQL查詢(關系型數據庫支持)和事務,可以說是構成業務系統的存儲原語。為什么memcached/Redis+mysql的組合如此的受歡迎,正是因為這個組合,幾個原語都能用上,對于業務來說,可以很方便的實現各種業務的存儲需求,能輕易的寫出「正確」的程序。但是,現在的問題是數據大到一定程度上時,從單機向分布式進化的過程中,最難搞定的就是事務,SQL支持什么的還可以通過各種mysqlproxy搞定,KV就不用說了,天生對分布式友好。
于是這樣,我們就默認進入了一個沒有(跨行)事務支持的世界里,很多業務場景我們只能犧牲業務的正確性來在實現的復雜度上平衡。比如一個很簡單的需求:微博關注數的變化,最直白,最正常的寫法應該是,將被關注者的被關注數的修改和關注者的關注數修改放到同一個事務里,一起提交,要么一起成功,要么一起失敗。但是現在為了考慮性能,為了考慮實現復雜度,一般來說的做法可能是隊列輔助異步的修改,或者通過cache先暫存等等方式繞開事務。
但是在一些需要強事務支持的場景就沒有那么好繞過去了(目前我們只討論開源的架構方案),比如支付/積分變更業務,常見的搞法是關鍵路徑根據用戶特征sharding到單點MySQL,或者MySQLXA,但是性能下降得太厲害。
后來Google在他們的廣告業務中遇到這個問題,既需要高性能,又需要分布式事務,還必須保證一致性:),Google在此之前是通過一個大規模的MySQL集群通過sharding苦苦支撐,這個架構的可運維/擴展性實在太差。這要是在一般公司,估計也就忍了,但是Google可不是一般公司,用原子鐘搞定Spanner,然后再Spanner上構建了SQL查詢層F1。我在第一次看到這個系統的時候,感覺簡直驚艷,應該是第一個可以真正稱為NewSQL的公開設計的系統。所以,BigTable(KV)+F1(SQL)+Spanner(高性能分布式事務支持),同時Spanner還有一個非常重要的特性是跨數據中心的復制和一致性保證(通過Paxos實現),多數據中心,剛好補全了整個Google的基礎設施的數據庫棧,使得Google對于幾乎任何類型的業務系統開發都非常方便。我想,這就是未來的方向吧,一個可擴展的KV數據庫(作為緩存和簡單對象存儲),一個高性能支持分布式事務和SQL查詢接口的分布式關系型數據庫,提供表支持。
五、Q & A
Q1:我沒看過Codis,您說Codis沒有多副本概念,請問是什么意思?
A1:Codis是一個分布式Redis解決方案,是通過presharding把數據在概念上分成1024個slot,然后通過proxy將不同的key的請求轉發到不同的機器上,數據的副本還是通過Redis本身保證
Q2:Codis的信息在一個zk里面存儲著,zk在Codis中還有別的作用嗎?主從切換為何不用sentinel
A2:Codis的特點是動態的擴容縮容,對業務透明;zk除了存儲路由信息,同時還作為一個事件同步的媒介服務,比如變更master或者數據遷移這樣的事情,需要所有的proxy通過**特定zk事件來實現 可以說zk被我們當做了一個可靠的rpc的信道來使用。因為只有集群變更的admin時候會往zk上發事件,proxy**到以后,回復在zk上,admin收到各個proxy的回復后才繼續。本身集群變更的事情不會經常發生,所以數據量不大。Redis的主從切換是通過codis-ha在zk上遍歷各個server group的master判斷存活情況,來決定是否發起提升新master的命令。
Q3:數據分片,是用的一致性hash嗎?請具體介紹下,謝謝。
A3:不是,是通過presharding,hash算法是crc32(key)%1024
Q4:怎么進行權限管理?
A4:Codis中沒有鑒權相關的命令,在reborndb中加入了auth指令。
Q5:怎么禁止普通用戶鏈接Redis破壞數據?
A5:同上,目前Codis沒有auth,接下來的版本會加入。
Q6:Redis跨機房有什么方案?
A6:目前沒有好的辦法,我們的Codis定位是同一個機房內部的緩存服務,跨機房復制對于Redis這樣的服務來說,一是延遲較大,二是一致性難以保證,對于性能要求比較高的緩存服務,我覺得跨機房不是好的選擇。
Q7:集群的主從怎么做(比如集群S是集群M的從,S和M的節點數可能不一樣,S和M可能不在一個機房)?
A7:Codis只是一個proxy-based的中間件,并不負責數據副本相關的工作。也就是數據只有一份,在Redis內部。
Q8:根據你介紹了這么多,我可以下一個結論,你們沒有多租戶的概念,也沒有做到高可用。可以這么說吧?你們更多的是把Redis當做一個cache來設計。
A8:對,其實我們內部多租戶是通過多Codis集群解決的,Codis更多的是為了替換twemproxy的一個項目。高可用是通過第三方工具實現。Redis是cache,Codis主要解決的是Redis單點、水平擴展的問題。把codis的介紹貼一下: Auto rebalance Extremely simple to use Support both Redis or rocksdb transparently. GUI dashboard & admin tools Supports most of Redis commands. Fully compatible with twemproxy(https://github.com/twitter/twemproxy). Native Redis clients are supported Safe and transparent data migration, Easily add or remove nodes on-demand.解決的問題是這些。業務不停的情況下,怎么動態的擴展緩存層,這個是codis關注的。
Q9:對于Redis冷備的數據庫的遷移,您有啥經驗沒有?對于Redis熱數據,可以通過migrate命令實現兩個Redis進程間的數據轉移,當然如果對端有密碼,migrate就玩完了(這個我已經給Redis官方提交了patch)。
A9:冷數據我們現在是實現了完整的Redissync協議,同時實現了一個基于rocksdb的磁盤存儲引擎,備機的冷數據,全部是存在磁盤上的,直接作為一個從掛在master上的。實際使用時,3個group,keys數量一致,但其中一個的ops是另外兩個的兩倍,有可能是什么原因造成的?key的數量一致并不代表實際請求是均勻分布的,不如你可能某幾個key特別熱,它一定是會落在實際存儲這個key的機器上的。剛才說的rocksdb的存儲引擎:https://github.com/reborndb/qdb,其實啟動后就是個Redis-server,支持了PSYNC協議,所以可以直接當成Redis從來用。是一個節省從庫內存的好方法。
Q10:Redis實例內存占比超過50%,此時執行bgsave,開了虛擬內存支持的會阻塞,不開虛擬內存支持的會直接返回err,對嗎?
A10:不一定,這個要看寫數據(開啟bgsave后修改的數據)的頻繁程度,在Redis內部執行bgsave,其實是通過操作系統COW機制來實現復制,如果你這段時間的把幾乎所有的數據都修改了,這樣操作系統只能全部完整的復制出來,這樣就爆了。
Q11:剛讀完,贊一個。可否介紹下codis的autorebalance實現。
A11:算法比較簡單,https://github.com/wandoulabs/codis/blob/master/cmd/cconfig/rebalancer.go#L104。代碼比較清楚,code talks:)。其實就是根據各個實例的內存比例,分配slot好的。
Q12:主要想了解對降低數據遷移對線上服務的影響,有沒有什么經驗介紹?
A12:其實現在codis數據遷移的方式已經很溫和了,是一個個key的原子遷移,如果怕抖動甚至可以加上每個key的延遲時間。這個好處就是對業務基本沒感知,但是缺點就是慢。
原文標題:細說分布式Redis架構設計和踩過的那些坑
文章出處:【微信號:C_Expert,微信公眾號:C語言專家集中營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
軟件架構設計的三個維度
軟件架構設計的三個維度
系統架構設計的詳細講解
SWE.2的軟件架構設計
五個步驟,講解PCBA成本如何估算資料下載

Redis基礎架構設計及核心網絡模型架構演進
架構與微架構設計
如何從0到1構建一個穩定、高性能的Redis集群?

Redis架構演化之路





 工商網監
工商網監
評論