") 【每天學(xué)點(diǎn)AI】人工智能大模型評估標(biāo)準(zhǔn)有哪些?
【每天學(xué)點(diǎn)AI】人工智能大模型評估標(biāo)準(zhǔn)有哪些?
OpenAI新模型o1號稱編程能力8倍殺GPT-4o,MMLU媲美人類專家,MMLU是什么?評估大模型的標(biāo)準(zhǔn)是什么?
相信大家在閱讀大模型相關(guān)文檔的時候經(jīng)常會看到MMLU,BBH,GSM8K,MATH,HumanEval,MBPP,C-Eval,CMMLU等等這些都是什么?大模型訓(xùn)練完成后,如何客觀地評估其效果呢?
當(dāng)然我們不能依靠主觀判斷,于是研究者們制定了一系列標(biāo)準(zhǔn),用于測評大模型在不同數(shù)據(jù)集上的表現(xiàn)。而這些數(shù)據(jù)集( MMLU、C-Eval、GSM8K、MATH、HumanEval、MBPP、BBH 和 CMMLU),正是用于評估大模型性能的重要依據(jù)。
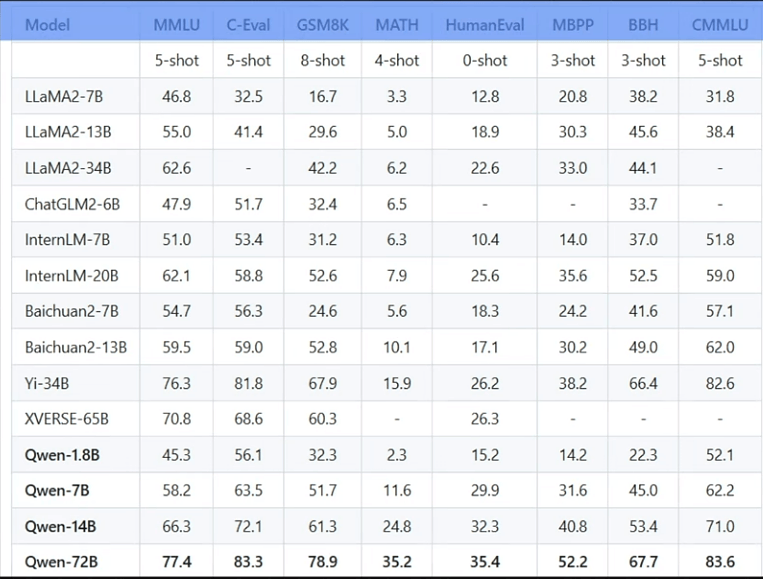
當(dāng)然,它們也也可用于模型訓(xùn)練。
MMLU這個基準(zhǔn)包含STEM(科學(xué)、技術(shù)、工程、數(shù)學(xué))、人文學(xué)科、社會學(xué)科等57個學(xué)科領(lǐng)域,難度從初級到高級不等。

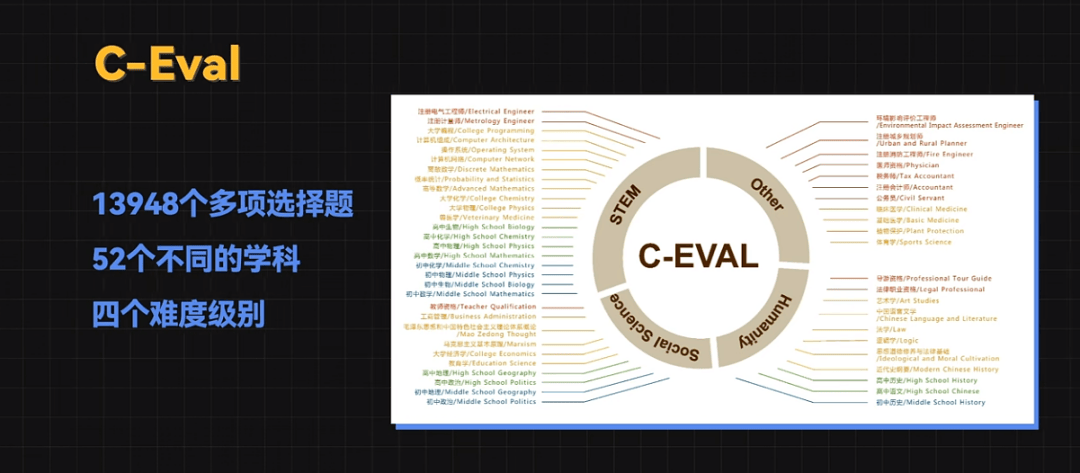
C-Eval 是一個全面的中文基礎(chǔ)模型評估套件,它包含了13948個多項(xiàng)選擇題,涵蓋了52個不同的學(xué)科和四個難度級別。
GSM8K(Grade School Math)是一個由OpenAI發(fā)布的數(shù)據(jù)集,有8.5K個高質(zhì)量語言多樣的小學(xué)數(shù)學(xué)問題組成。這些問題需要 2 到 8 個步驟來解決,解決方法主要是使用基本的算術(shù)運(yùn)算(+ - / *)進(jìn)行一連串的基本計算,以得出最終答案。

雖然看起來很簡單,但很多大模型的表現(xiàn)都不太好。
MATH是一個包含 12500 個數(shù)學(xué)競賽問題的數(shù)據(jù)集,其中的每個問題都有一個完整的推導(dǎo)過程。

HumanEval是由 164 個簡單編程問題組成,主要用來評估語言理解、算法和簡單的數(shù)學(xué)。

MBPP(Mostly Basic Python Programming)由大約 1000 個Python 編程問題組成,每個問題由任務(wù)描述、代碼解決方案和 3 個自動化測試用例組成。

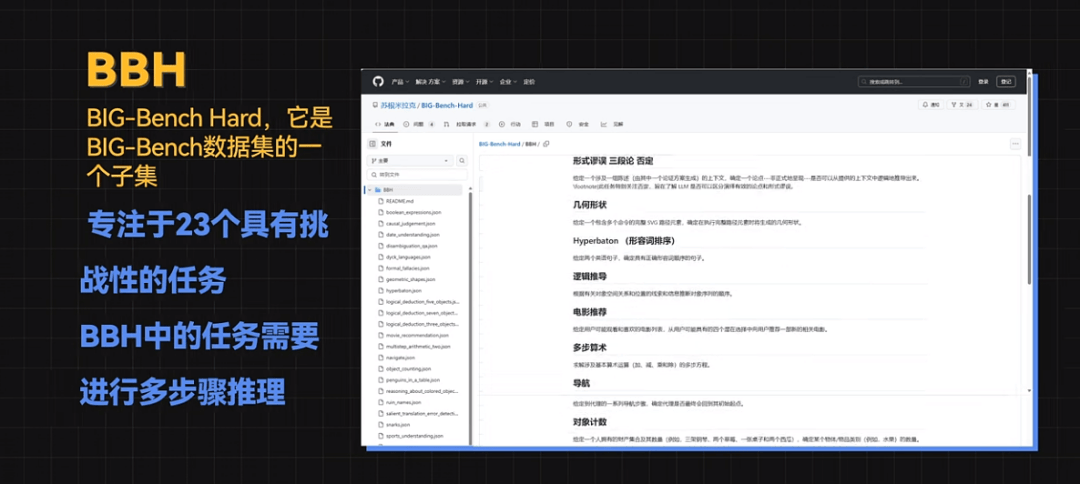
BBH的全稱是BIG-Bench Hard,它是BIG-Bench數(shù)據(jù)集的一個子集,它專注于23個具有挑戰(zhàn)性的任務(wù),這些任務(wù)超出了當(dāng)前語言模型的能力范圍,BBH中的任務(wù)需要進(jìn)行多步驟推理。
CMMLU,一個全面的中文大模型評估數(shù)據(jù)集。它涵蓋了67個主題,涉及自然科學(xué)、社會科學(xué)、工程、人文、以及常識等,就是中文版的MMLU。

通過這些評測數(shù)據(jù)集和評估標(biāo)準(zhǔn),我們可以從不同角度系統(tǒng)地評估大模型的性能、泛化能力和魯棒性,為大模型的進(jìn)一步研究和應(yīng)用提供科學(xué)依據(jù)。
AI體系化學(xué)習(xí)路線
學(xué)習(xí)資料免費(fèi)領(lǐng)
? AI全體系學(xué)習(xí)路線超詳版
? AI體驗(yàn)卡(AI實(shí)驗(yàn)平臺體驗(yàn)權(quán)限)
? 100余講AI視頻課程
? 項(xiàng)目源碼《從零開始訓(xùn)練與部署YOLOV8》
? 170余篇AI經(jīng)典論文
全體系課程詳情介紹

-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268886 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238247 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
發(fā)布評論請先 登錄
相關(guān)推薦
【每天學(xué)點(diǎn)AI】實(shí)戰(zhàn)圖像增強(qiáng)技術(shù)在人工智能圖像處理中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論