

編者按:半年前,上海交大陳天奇團隊開源了端到端IR堆棧工具TVM,可以幫用戶優化深度學習過程中的硬件配置,緩解了當前大多數計算機GPU在面對深度學習時表現出來的性能不足。近日,團隊的一名學生鄭憐憫帶來了項目的新進展,他將TVM用于移動端常見的ARM GPU,提高了移動設備對深度學習的支持能力。
以下是論智對原文的翻譯:
隨著深度學習不斷取得進展,開發者們對在移動設備上的部署神經網絡的需求也與日俱增。和我們之前在桌面級GPU上做過的嘗試類似,把深度學習框架移植到移動端需要做到這兩點:夠快的inference速度和合理的能耗。但是,現在的大多數DL框架并不能很好地支持移動端GPU,因為它們和桌面級GPU在架構上存在巨大差異。為了在移動端做深度學習,開發者們往往要對GPU做一些特殊優化,而這類額外工作也加大了對GPU的壓力。
TVM是一個端到端的IR堆棧,它可以解決學習過程中的資源分配問題,從而輕松實現硬件優化。在這篇文章中,我們將展示如何用TVM/NNVM為ARM Mali GPU生成高效kernel,并進行端到端編譯。在對Mali-T860 MP4的測試中,我們的方法在VGG-16上比Arm Compute Library快了1.4倍,在MobileNet上快了2.2倍。這些提升在圖像處理和運算上均有體現。
Mali Midgard GPU
目前,移動領域最常見的3大圖形處理器為高通的Adreno、英國PowerVR和ARM的嵌入式圖形處理器Mali。我們的測試環境是配有Mali-T860 MP4 GPU的開發板Firefly-RK3399,所以下面我們主要關注Mali T8xx的表現。
架構
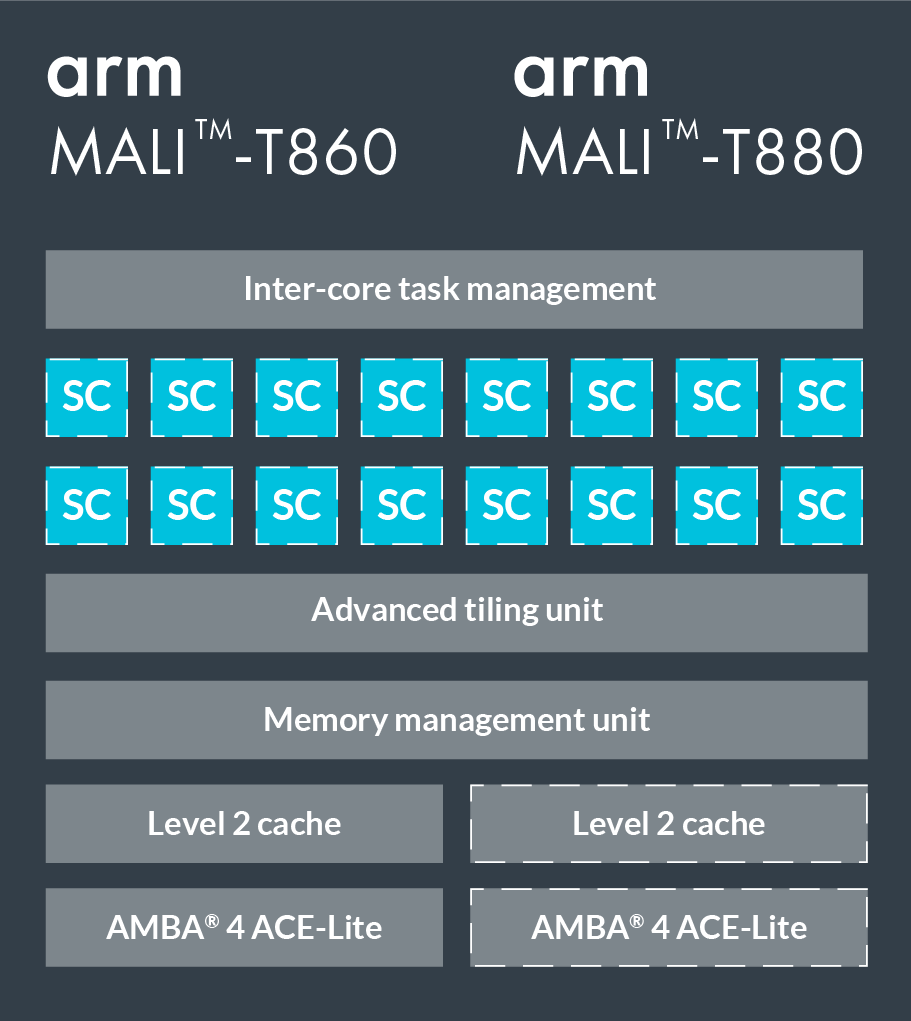
T860和T880是Mali系列的兩款高端GPU,下圖是具體配置。它們有16個著色器核心(Shader Core),每個核心內包含2—3條運算管道、1條加載/存儲管道和1條紋理管道(即Triple Pipeline架構)。其中運算管道中的ALU(算數邏輯單元)又包含4個128-bit的矢量單元和一個標量單元。
我們用OpenCL編寫程序。當映射到OpenCL模型時,每個著色器核心會執行一個或多個工作組,它們的上限是并行執行384個線程,通常一個工作組對應一個線程。Mali系列GPU使用的是VLIW架構(超長指令集架構),因此每個指令包含多個操作;同時,它也用了SIMD(單指令流多數據流),所以大多數運算運算指令可以同時執行多個數據流。
和NVIDIA GPU的區別
在用TVM優化GPU前,我們先看一看Mali GPU和NVIDIA GPU的區別:
NVIDIA GPU的存儲系統架構一般分為全局內存、共享內存、寄存器三層,在實踐中我們通常會把數據復制到共享內存;而Mali GPU只有一個統一的全局內存,它不需要制作副本提升性能,因為這個內存是和CPU共享的,所以CPU和GPU之間也不需要復制;
Mali Midgard GPU基于SIMD設計,所以需要用到矢量;而在NVIDIA CUDA中,GPU的并行處理是通過SIMT實現的,所以它對矢量沒有那么高的要求。需要注意的是,Mali Bifrost架構的圖形處理器新添加了Quad based vectorization技術,即允許四個線程一起被執行,它也不太需要矢量;
Mali GPU中的每一個線程都有獨立的程序計數器,即warp size=1,所以Branch Divergence不是問題。
優化:以卷積層為例
卷積層是許多深度神經網絡的核心,也占用了大部分計算資源。所以我們以卷積層為例,談談TVM在pack、tile、unroll、向量化中的優化應用。
im2col+GEMM
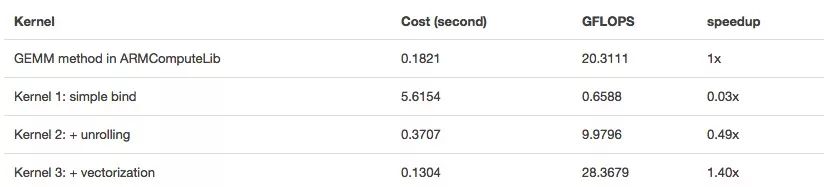
im2col是卷積計算的一種常用方法,它會把問題轉換成一個矩陣,然后調用GEMM完成矩陣乘法運算。這種方法的優點是便于和高度優化的BLAS庫結合,缺點是會耗費大量內存。
Spatial Packing
所以我們換了一種方法,先計算卷積,再逐步應用優化技術。以VGG-16中的卷積層為例(如下圖所示),inference的batch size=1。

為了提供一個對照組,我們列出了Arm Compute Library的數據。

pack和tile是兩個調整內存的常見指令。其中tile是把數據劃分成片,使每一片適合共享內存的使用;而pack則是對輸入矩陣重新布局(內存對齊),方便我們按順序讀取數據。
我們在輸入圖像的寬度和filter矩陣的CO維上使用了tile(tvm.compute):
# set tiling factor
VH = 1
VW = VC = 4
# get input shape
_, CI, IH, IW = data.shape
CO, CI, KH, KW = kernel.shape
TH = IH + 2 * H_PAD
TW = IW + 2 * W_PAD
# calc output shape
OH = (IH + 2*H_PAD - KH) // H_STR + 1
OW = (IW + 2*W_PAD - KW) // W_STR + 1
# data shape after packing
dvshape = (N, TH // (VH*H_STRIDE), TW // (VW*W_STRIDE), CI, VH*H_STRIDE+HCAT, VW*W_STRIDE+WCAT)
# kernel shape after packing
kvshape = (CO // VC, CI, KH, KW, VC)
ovshape = (N, CO // VC, OH // VH, OW // VW, VH, VW, VC)
oshape = (N, CO, OH, OW)
# define packing
data_vec = tvm.compute(dvshape, lambda n, h, w, ci, vh, vw:
data_pad[n][ci][h*VH*H_STRIDE+vh][w*VW*W_STRIDE+vw], name='data_vec')
kernel_vec = tvm.compute(kvshape, lambda co, ci, kh, kw, vc:
kernel[co*VC+vc][ci][kh][kw], name='kernel_vec')
# define convolution
ci = tvm.reduce_axis((0, CI), name='ci')
kh = tvm.reduce_axis((0, KH), name='kh')
kw = tvm.reduce_axis((0, KW), name='kw')
conv = tvm.compute(ovshape, lambda n, co, h, w, vh, vw, vc:
tvm.sum(data_vec[n, h, w, ci, vh*H_STRIDE+kh, vw*W_STRIDE+kw].astype(out_dtype) *
kernel_vec[co, ci, kh, kw, vc].astype(out_dtype),
axis=[ci, kh, kw]), name='conv')
# unpack to correct layout
output = tvm.compute(oshape, lambda n, co, h, w:
conv[n][co//VC][h/VH][w//VW][h%VH][w%VW][co%VC],
name='output_unpack', tag='direct_conv_output')
用以下命令檢查定義的IR:
print(tvm.lower(s, [data, kernel, output], simple_mode=True))
選擇卷積的部分:
produce conv {
for (co, 0, 64) {
for (h, 0, 56) {
for (w, 0, 14) {
for (vw.init, 0, 4) {
for (vc.init, 0, 4) {
conv[((((((((co*56) + h)*14) + w)*4) + vw.init)*4) + vc.init)] = 0.000000f
}
}
for (ci, 0, 256) {
for (kh, 0, 3) {
for (kw, 0, 3) {
for (vw, 0, 4) {
for (vc, 0, 4) {
conv[((((((((co*56) + h)*14) + w)*4) + vw)*4) + vc)] = (conv[((((((((co*56) + h)*14) + w)*4) + vw)*4) + vc)] + (data_vec[(((((((((h*14) + w)*256) + ci)*3) + kh)*6) + kw) + vw)]*kernel_vec[((((((((co*256) + ci)*3) + kh)*3) + kw)*4) + vc)]))
}
}
}
}
}
}
}
}
}
Kernel 1:綁定線程
在TVM中,我們先計算,再計劃(schedule),這便于分離算法和實現細節。
如代碼所示,我們簡單把axes坐標軸對應到GPU線程,之后就能在Mali GPU上跑代碼了。
# helper function for binding thread
def tile_and_bind3d(s, tensor, z, y, x, z_factor=2, y_factor=None, x_factor=None):
""" tile and bind 3d """
y_factor = y_factor or z_factor
x_factor = x_factor or y_factor
zo, zi = s[tensor].split(z, z_factor)
yo, yi = s[tensor].split(y, y_factor)
xo, xi = s[tensor].split(x, x_factor)
s[tensor].bind(zo, tvm.thread_axis("blockIdx.z"))
s[tensor].bind(zi, tvm.thread_axis("threadIdx.z"))
s[tensor].bind(yo, tvm.thread_axis("blockIdx.y"))
s[tensor].bind(yi, tvm.thread_axis("threadIdx.y"))
s[tensor].bind(xo, tvm.thread_axis("blockIdx.x"))
s[tensor].bind(xi, tvm.thread_axis("threadIdx.x"))
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)
雖然有了這個schedule,我們現在可以運行代碼了,但它的性能要求還是相當可怕。

Kernel 2:unroll
循環展開(loop unrolling)是一個常用的優化方法,它能通過減少循環控制指令降低循環本身的開銷,同時因為能消除分支以及一些管理歸納變量的代碼,它也可以攤銷一些分支開銷,此外,它還能掩蓋讀取內存的延遲。在TVM中,你可以調用s.unroll(axis)實現循環展開。
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
"""!! ADD UNROLL HERE !!"""
s[data_vec].unroll(vw)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
"""!! ADD UNROLL HERE !!"""
s[kernel_vec].unroll(kh)
s[kernel_vec].unroll(kw)
s[kernel_vec].unroll(vc)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
"""!! ADD UNROLL HERE !!"""
s[conv].unroll(kh)
s[conv].unroll(kw)
s[conv].unroll(vw)
s[conv].unroll(vc)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)

Kernel 3:向量化(vectorization)
如前所述,為了在Mali GPU上實現最佳性能,我們還要把數字轉成矢量。
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
# unroll
s[data_vec].unroll(vw)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
# unroll
s[kernel_vec].unroll(kh)
s[kernel_vec].unroll(kw)
"""!! VECTORIZE HERE !!"""
s[kernel_vec].vectorize(vc)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
# unroll
s[conv].unroll(kh)
s[conv].unroll(kw)
s[conv].unroll(vw)
"""!! VECTORIZE HERE !!"""
s[conv].vectorize(vc)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)
如何設置可調參數
上文中涉及的一些可調參數是可以被計算出來的,如向量vc,如果是float32,|vc|=128/32=4;如果是float16,則是128/16=8。
但由于運行時間過長,很多時候我們會無法確定最佳值。TVM使用的是網格搜索,所以如果用的是python,而不是OpenCL的話,我們也能快速找到最佳值。
端到端的Benchmark
在這一節中,我們比較了一些流行深度神經網絡在不同后端上的綜合性能,測試環境是:
Firefly-RK3399 4G
CPU: dual-core Cortex-A72 + quad-core Cortex-A53
GPU: Mali-T860MP4
ArmComputeLibrary : v17.12
MXNet: v1.0.1
Openblas: v0.2.18
我們使用NNVM和TVM進行端到端編譯。
性能
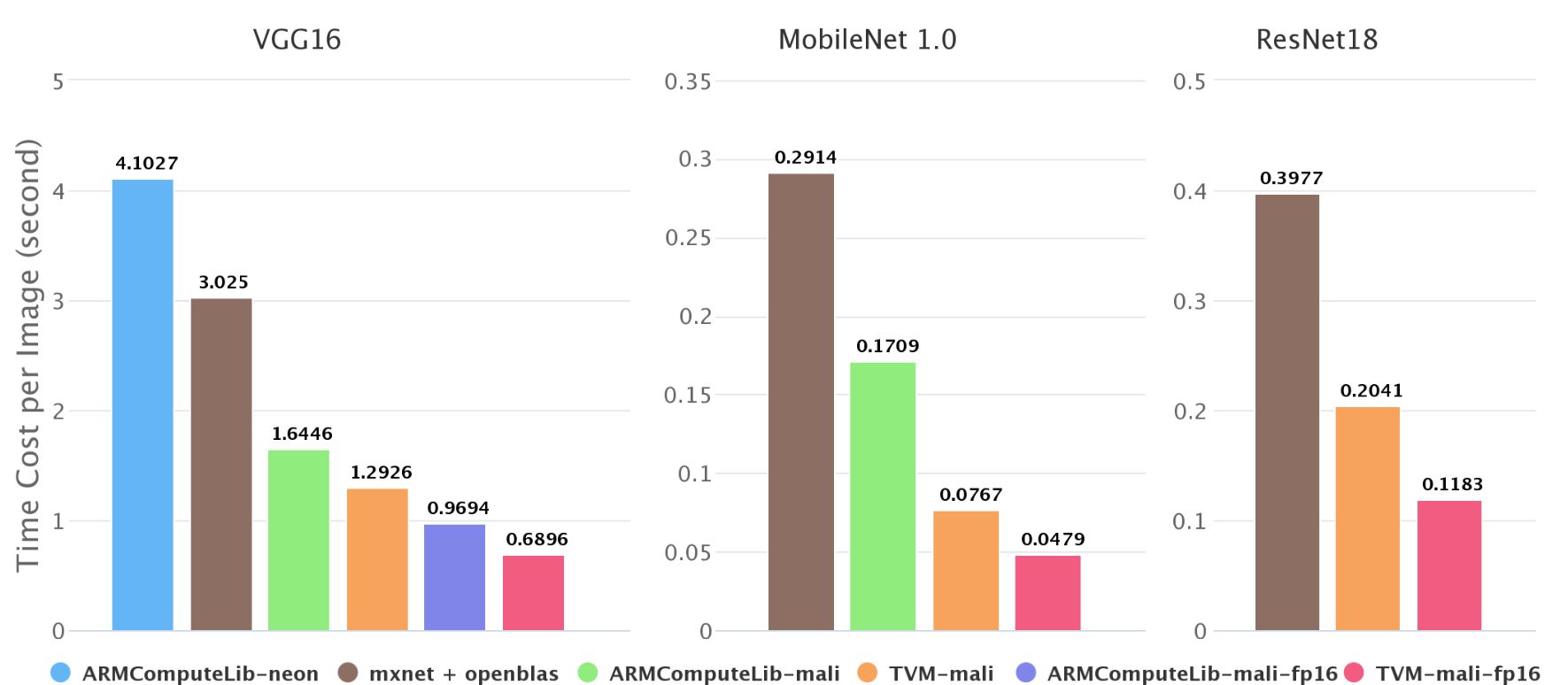
ImageNet上不同后端的inference速度
如上圖所示,我們在ImageNet測試了移動端神經網絡的inference速度,發現在Firefly-RK3399上,Mali GPU可以比6核big.LITTLE CPU快2—4倍,我們的端到端編譯速度比Arm Compute Library快了1.4—2.2倍。在Arm Compute Library中,我們比較了用GEMM計算卷積和直接計算卷積,發現前者速度始終更快,所以在圖中只展示了GEMM方法的成果。
上圖中也有一些數據缺失,如第二幅圖不包含Arm Compute Library上的resnet18。這是因為Arm Compute Library的graph runtime目前不支持跳轉連接,并且Neon在上面的實現性能不太好。這也從側面反映了NNVM軟件棧的優勢。
半精度性能
深度神經網絡對精度要求不高,尤其是對于計算資源捉襟見肘的移動設備,降低精度可以加快神經網絡的inference速度。我們還計算了Mali GPU上的半精度浮點數。
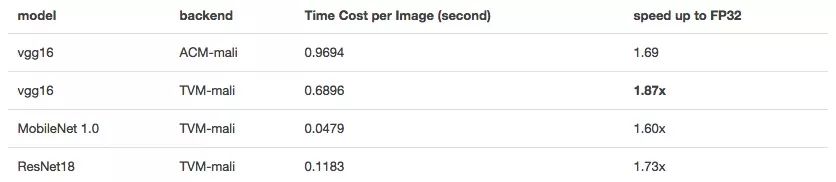
mageNet上FP16的inference速度
從理論上講,FP16既可以實現雙峰計算,又可以將內存消耗減半,從而使速度提高一倍。但是如果涉及較長的向量化和某些參數的微調,它也需要良好的輸入形態。
-
ARM
+關注
關注
134文章
9327瀏覽量
375637 -
gpu
+關注
關注
28文章
4921瀏覽量
130801 -
深度學習
+關注
關注
73文章
5557瀏覽量
122576 -
TVM
+關注
關注
0文章
19瀏覽量
3789
原文標題:上海交大團隊:如何用TVM優化ARM架構GPU,在移動端實現快速深度學習
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
移動互聯網的發展需要移動電源的支持
移動互聯網的發展需要移動電源的支持
三地聯動 Qualcomm邀您探索移動應用圖像進階之路
動態分配多任務資源的移動端深度學習框架
TVM整體結構,TVM代碼的基本構成
如何實現嵌入式平臺與深度學習的智能氣象監測儀器的設計
Mali GPU支持tensorflow或者caffe等深度學習模型嗎
小米自研開源移動端深度學習框架MACE
小米AI移動端深度學習框架MACE開源了!
TVM學習(三)編譯流程






 工商網監
工商網監

評論