


自然語言處理和大部分的機器學習或者人工智能領域的技術一樣,是一個涉及到多個技能、技術和領域的綜合體。
所以自然語言處理工程師會有各種各樣的背景,大部分都是在工作中自學或者是跟著項目一起學習的,這其中也不乏很多有科班背景的專業人才,因為技術的發展實在是日新月異,所以時刻要保持著一種強烈的學習欲望,讓自己跟上時代和技術發展的步伐。本文作者從個人學習經歷出發,介紹相關經驗。
一些研究者將自然語言處理(NLP,Natural Language Processing)和自然語言理解(NLU,Natural Language Understanding)區分開,在文章中我們說的NLP是包含兩者的,并沒有將兩者嚴格分開。
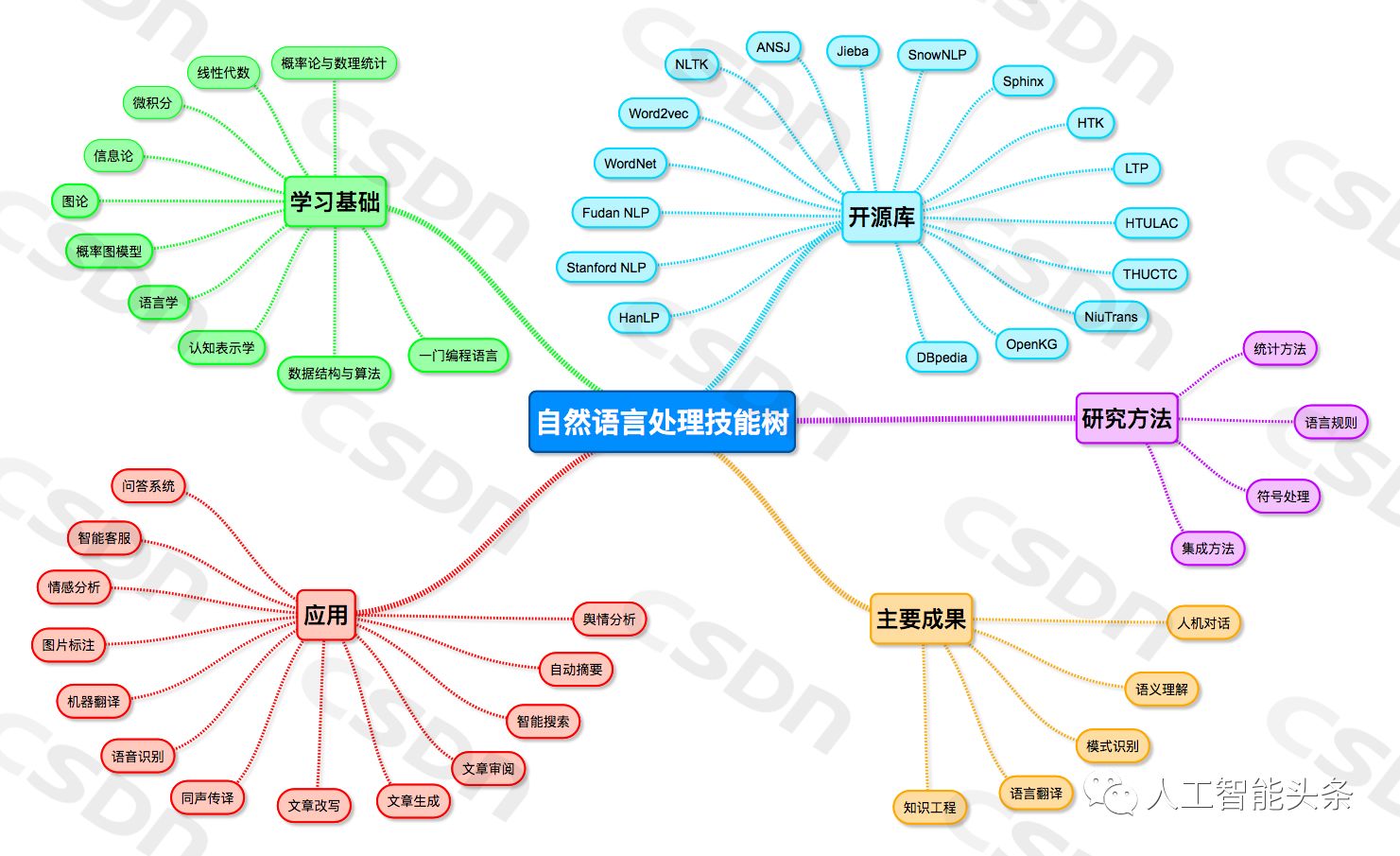
圖1 自然語言處理工程師技能樹
自然語言處理學習路線
數學基礎
數學對于自然語言處理的重要性不言而喻。當然數學的各個分支在自然語言處理的不同階段也會扮演不同的角色,這里介紹幾個重要的分支。
代數
代數作為計算數學里面很重要的一個分支,在自然語言處理中也有舉足輕重的作用。這一部分需要重點關注矩陣處理相關的一些知識,比如矩陣的SVD、QR分解,矩陣逆的求解,正定矩陣、稀疏矩陣等特殊矩陣的一些處理方法和性質等等。
對于這一部分的學習,既可以跟著大學的代數書一起學習,也可以跟著網上的各種公開課一起學習,這里既可以從國內的一些開放學習平臺上學,也可以從國外的一些開放學習平臺上學。這
概率論
在很多的自然語言處理場景中,我們都是算一個事件發生的概率。這其中既有特定場景的原因,比如要推斷一個拼音可能的漢字,因為同音字的存在,我們能計算的只能是這個拼音到各個相同發音的漢字的條件概率。也有對問題的抽象處理,比如詞性標注的問題,這個是因為我們沒有很好的工具或者說能力去精準地判斷各個詞的詞性,所以就構造了一個概率解決的辦法。
對于概率論的學習,既要學習經典的概率統計理論,也要學習貝葉斯概率統計。相對來說,貝葉斯概率統計可能更重要一些,這個和貝葉斯統計的特性是相關的,因其提供了一種描述先驗知識的方法。使得歷史的經驗使用成為了可能,而歷史在現實生活中,也確實是很有用的。比如樸素貝葉斯模型、隱馬爾卡模型、最大熵模型,這些我們在自然語言處理中耳熟能詳的一些算法,都是貝葉斯模型的一種延伸和實例。
信息論作為一種衡量樣本純凈度的有效方法。對于刻畫兩個元素之間的習慣搭配程度非常有效。這個對于我們預測一個語素可能的成分(詞性標注),成分的可能組成(短語搭配)非常有價值,所以這一部分知識在自然語言處理中也有非常重要的作用。
同時這部分知識也是很多機器學習算法的核心,比如決策樹、隨機森林等以信息熵作為決策樁的一些算法。對于這部分知識的學習,更多的是要理解各個熵的計算方法和優缺點,比如信息增益和信息增益率的區別,以及各自在業務場景中的優缺點。
數據結構與算法
這部分內容的重要性就不做贅述了。學習了上面的基礎知識,只是萬里長征開始了第一步,要想用機器實現對自然語言的處理,還是需要實現對應的數據結構和算法。這一部分也算是自然語言處理工程師的一個看家本領。這一部分的內容也是比較多的,這里就做一個簡單的介紹和說明。
首先數據結構部分,需要重點關注鏈表、樹結構和圖結構(鄰接矩陣)。包括各個結構的構建、操作、優化,以及各個結構在不同場景下的優缺點。當然大部分情況下,可能使用到的數據結構都不是單一的,而是有多種數據結構組合。比如在分詞中有非常優秀表現的雙數組有限狀態機就使用樹和鏈表的結構,但是實現上采用的是鏈表形式,提升了數據查詢和匹配的速度。在熟練掌握各種數據結構之后,就是要設計良好的算法了。
伴隨著大數據的不斷擴張,單機的算法越來越難發揮價值,所以多數場景下都要研發并行的算法。這里面又涉及到一些工具的應用,也就是編程技術的使用。例如基于Hadoop的MapReduce開發和Spark開發都是很好的并行化算法開發工具,但是實現機制卻有很大的差別,同時編程的便利程度也不一樣。
當然這里面沒有絕對的孰好孰壞,更多的是個人使用的習慣和業務場景的不同而不同。比如兩個都有比較成熟的機器學習庫,一些常用的機器學習算法都可以調用庫函數實現,編程語言上也都可以采用Java,不過Spark場景下使用Scala會更方便一些。因為這一部分是偏實操的,所以我的經驗會建議實例學習的方法,也就是跟著具體的項目學習各種算法和數據結構。最好能對學習過的算法和數據結構進行總結回顧,這樣可以更好的得到這種方法的精髓。因為基礎的元素,包括數據結構和計算規則都是有限的,所以多樣的算法更多的是在不同的場景下,對于不同元素的一個排列組合,如果能夠融會貫通各個基礎元素的原理和使用,不管是對于新知識的學習還是對于新解決方案的構建都是非常有幫助的。
對于工具的選擇,建議精通一個,對于其他工具也需要知道,比如精通Java和MapReduce,對于Spark和Python也需要熟悉,這樣可以在不同的場景下使用不同的工具,提升開發效率。這一部分實在是太多、太廣,這里不能全面地介紹,大家可以根據自己的需求,選擇合適的學習資料進行學習。
這一部分就更多是語文相關的知識,比如一個句子的組成成分包括:主、謂、賓、定、狀、補等。對于各個成分的組織形式也是多種多樣。比如對于主、謂、賓,常規的順序就是:主語→謂語→賓語。當然也會有:賓語→主語→賓語(飯我吃了)。這些知識的積累有助于我們在模型構建或者解決具體業務的時候,能夠事半功倍,因為這些知識一般情況下,如果要被機器學習,都是非常困難的,或者會需要大量的學習素材,或許在現有的框架下,機器很難學習到。如果把這些知識作為先驗知識融合到模型中,對于提升模型的準確度都是非常有價值的。
在先期的研究中,基于規則的模型,大部分都是基于語言模型的規則進行研究和處理的。所以這一部分的內容對于自然語言處理也是非常重要的。但是這部分知識的學習就比較雜一些,因為大部分的自然語言處理工程師都是語言學專業出身,所以對于這部分知識的學習,大部分情況都是靠碎片化的積累,當然也可以花一些精力,系統性學習。對于這部分知識的學習,個人建議可以根據具體的業務場景進行學習,比如在項目處理中要進行同義詞挖掘,那么就可以跟著“百科”或者“搜索引擎”學習同義詞的定義,同義詞一般會有什么樣的形式,怎么根據句子結構或者語法結構判斷兩個詞是不是同義詞等等。
隨著深度學習在視覺和自然語言處理領域大獲成功,特別是隨著AlphaGo的成功,深度學習在自然語言處理中的應用也越來越廣泛,大家對于它的期望也越來越高。所以對于這部分知識的學習也幾乎成為了一個必備的環節(實際上可能是大部分情況,不用深度學習的模型,也可以解決很多業務)。
對于這部分知識,現在流行的幾種神經網絡都是需要學習和關注的,特別是循環神經網絡,因為其在處理時序數據上的優勢,在自然語言處理領域尤為收到追捧,這里包括單項RNN、雙向RNN、LSTM等形式。同時新的學習框架,比如對抗學習、增強學習、對偶學習,也是需要關注的。其中對抗學習和對偶學習都可以顯著降低對樣本的需求,這個對于自然語言處理的價值是非常大的,因為在自然語言處理中,很重要的一個環節就是樣本的標注,很多模型都是嚴重依賴于樣本的好壞,而隨著人工成本的上升,數據標注的成本越來越高,所以如果能顯著降低標注數據需求,同時提升效果,那將是非常有價值的。
現在還有一個事物正在如火如荼地進行著,就是知識圖譜,知識圖譜的強大這里就不再贅述,對于這部分的學習可能更多的是要關注信息的鏈接、整合和推理的技術。不過這里的每一項技術都是非常大的一個領域,所以還是建議從業務實際需求出發去學習相應的環節和知識,滿足自己的需求。
自然語言處理現狀
隨著知識圖譜在搜索領域的大獲成功,以及知識圖譜的推廣如火如荼地進行中,現在的自然語言處理有明顯和知識圖譜結合的趨勢。特別是在特定領域的客服系統構建中,這種趨勢就更明顯,因為這些系統往往要關聯很多領域的知識,而這種知識的整合和表示,很適合用知識圖譜來解決。隨著知識圖譜基礎工程技術的完善和進步,對于圖譜構建的容易程度也大大提高,所以自然語言處理和知識圖譜的結合就越來越成為趨勢。
語義理解仍然是自然語言處理中一個難過的坎。目前各項自然語言處理技術基本已經比較成熟,但是很多技術的效果還達不到商用的水平。特別是在語義理解方面,和商用還有比較大的差距。比如聊天機器人現在還很難做到正常的聊天水平。不過隨著各個研究機構和企業的不斷努力,進步也是飛速的,比如微軟小冰一直在不斷的進步。
對于新的深度學習框架,目前在自然語言處理中的應用還有待進一步加深和提高。比如對抗學習、對偶學習等雖然在圖像處理領域得到了比較好的效果,但是在自然語言處理領域的效果就稍微差一些,這里面的原因是多樣的,因為沒有深入研究,就不敢妄言。
目前人機對話、問答系統、語言翻譯是自然語言處理中的熱門領域,各大公司都有了自己的語音助手,這一塊也都在投入大量的精力在做。當然這些上層的應用,也都依賴于底層技術和模型的進步,所以對于底層技術的研究應該說一直是熱門,在未來一段時間應該也都還是熱門。之前聽一個教授講過一個故事,他是做parser的,開始的時候很火,后來一段時間因為整個自然語言處理的效果差強人意,所以作為其中一個基礎工作的parser就隨之受到冷落,曾經有段時間相關的期刊會議會員銳減,但是最近整個行業的升溫,這部分工作也隨之而受到重視。不過因為他一直堅持在這個領域,所以建樹頗豐,最近也成為熱門領域和人物。
所以在最后引用一位大牛曾經說過的話:“任何行業或者領域做到頭部都是非常有前途的,即使是打球,玩游戲。”(大意)
個人經驗
筆者是跟著項目學習自然語言處理的,非科班出身,所以的經驗難免會有偏頗,說出來僅供大家參考, 有不足和紕漏的地方敬請指正。
知識結構
要做算法研究,肯定需要一定的知識積累,對于知識積累這部分,我的經驗是先學數學理論基礎,學的順序可以是代數→概率論→隨機過程。當然這里面每一科都是很大的一個方向,學的時候不必面面俱到,所有都深入理解,但是相對基礎的一些概念和這門學科主要講的是什么問題一定要記住。
在學習了一些基礎數學知識之后,就開始實現——編寫算法。這里的算法模型,建議跟著具體的業務來學習和實踐,比如可以先從識別垃圾郵件這樣的demo進行學習實驗,這樣的例子在網上很容易找到,但是找到以后,一定不要看看就過去,要一步一步改寫拿到的demo,同時可以改進里面的參數或者實現方法,看看能不能達到更好的效果。個人覺得學習還是需要下苦功夫一步一步模仿,然后改進,才能深入的掌握相應的內容。對于學習的資料,上學時期的各個教程即可。
工具
工欲善其事必先利其器,所以好的工具往往能事半功倍。在工具的選擇上,個人建議,最高優先級的是Python,畢竟其的宣傳口語是:人生苦短,請用Python。第二優先級的是Java,基于Java可以和現有的很多框架進行直接交互,比如Hadoop、Spark等等。對于工具的學習兩者還是有很大的差別的,Python是一個腳本語言,所以更多的是跟著“命令”學,也就是要掌握你要實現什么目的來找具體的執行語句或者命令,同時因為Python不同版本、不同包對于同一個功能的函數實現差別也比較大,所以在學習的時候,要多試驗,求同存異。
對于Java就要學習一些基礎的數據結構,然后一步一步的去編寫自己的邏輯。對于Python當然也可以按照這個思路,Python本身也是一個高級編程語言,所以掌握了基礎的數據結構之后,也可以一步一步的實現具體的功能,但是那樣好像就失去了slogan的意義。
緊跟時代
自然語言處理領域也算是一個知識密集型的行業,所以知識的更新迭代非常的快,要時刻關注行業、領域的最新進展。這個方面主要就是看一些論文和關注一些重要的會議,對于論文的獲取,Google Scholar、arxiv都是很好的工具和資源(請注意維護知識產權)。會議就更多了KDD、JIST、CCKS等等。
-
算法
+關注
關注
23文章
4719瀏覽量
95901 -
數據結構
+關注
關注
3文章
573瀏覽量
40822 -
深度學習
+關注
關注
73文章
5569瀏覽量
123062 -
自然語言
+關注
關注
1文章
292瀏覽量
13708
原文標題:如何成為一名自然語言處理工程師
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論