") cpu工程師該何去何從
cpu工程師該何去何從
對(duì)可憐的處理器設(shè)計(jì)師表示同情。他們的工作以前非常簡(jiǎn)單。在每一半導(dǎo)體新工藝代中,每平方毫米的晶體管數(shù)量都會(huì)加倍,速度會(huì)有很大的提高,同時(shí)總功耗也會(huì)降低。設(shè)計(jì)師的黃金規(guī)則是“保持體系結(jié)構(gòu)不變,在實(shí)現(xiàn)上稍作調(diào)整。”
但現(xiàn)在完全不同了。速度提高的越來越小,功耗降低的也越來越少。您再也不能簡(jiǎn)單的提高時(shí)鐘了:設(shè)計(jì)師不得不使用所有新晶體管來研究實(shí)現(xiàn)并行功能。但是怎樣找到并行功能呢? 首先,我們找到了現(xiàn)成的好方法:通過超標(biāo)量體系結(jié)構(gòu)自動(dòng)實(shí)現(xiàn)指令級(jí)并行功能。然后,有了更多的晶體管,使用了大部分指令并行功能,矢量處理器進(jìn)行數(shù)據(jù)并行處理,宏單元級(jí)指令并行——線程,采用多線程,然后是多核CPU。
但是,我們突然發(fā)現(xiàn)自己身處無盡的“暗硅片”中。所有這些晶體管的功率密度增加非常快,如果它們都同時(shí)全速運(yùn)行,根本沒法對(duì)其進(jìn)行散熱。我們使用時(shí)鐘選通,然后是電源選通,最后降低晶體管封裝密度,以避免互聯(lián)走線被熔化。但是,這限制了我們采用越來越多的晶體管實(shí)現(xiàn)數(shù)據(jù)和算法的并行處理。看起來這一過程要慢慢停下來了。
年初的熱點(diǎn)芯片大會(huì)上就提出了這類問題。雖然在克服困難方面已經(jīng)取得了很大的成就,但是芯片設(shè)計(jì)師仍然展示了還有繼續(xù)創(chuàng)新的空間:找到能夠進(jìn)行并行處理的地方,使用所有晶體管的方法,以及使其保持較低溫度的技術(shù)。
找到好方法
很顯然,如果我們繼續(xù)使用所有這些晶體管,那么,我們必須降低能耗。這意味著,減少信息的傳送:數(shù)據(jù)移動(dòng)和復(fù)制少了,指令讀取的少了。不僅DRAM周期能耗比較高,而且在高級(jí)進(jìn)程中,數(shù)據(jù)通過阻抗越來越大的片內(nèi)互聯(lián)也是問題。在傳統(tǒng)的體系結(jié)構(gòu)中,我們能夠傳送大量的數(shù)據(jù):最近的估算表明,SoC中80%的活動(dòng)硅片用于連接或者緩沖互聯(lián),而不是用于邏輯功能。
信息傳送的少了,意味著需要圍繞數(shù)據(jù)內(nèi)部結(jié)構(gòu)來組織處理單元——這是熱點(diǎn)芯片大會(huì)論文最明顯的觀點(diǎn)。我們特別關(guān)注一下四種情形。第一,搜索引擎加速,處理大量的非結(jié)構(gòu)和獨(dú)立數(shù)據(jù)元素。第二種情形,矢量處理,處理高度結(jié)構(gòu)化的數(shù)據(jù),其元素之間會(huì)有相關(guān)性。第三種,有很多線程的問題,但不一定是并行數(shù)據(jù)處理。最后一種情形,單線程加速。
搜索引擎加速
對(duì)于并行執(zhí)行而言,網(wǎng)絡(luò)搜索既帶來了很多難題,也創(chuàng)造了機(jī)會(huì)。數(shù)據(jù)中心設(shè)計(jì)師不僅僅需要多核x86 CPU,他們考慮更多的是數(shù)據(jù)的非結(jié)構(gòu)、獨(dú)立特性——基本上,網(wǎng)頁上到處都是。在熱點(diǎn)芯片大會(huì)上,微軟資深研究硬件設(shè)計(jì)工程師Andrew Putnam介紹了他的團(tuán)隊(duì)在加速必應(yīng)搜索引擎方面的工作。
Putnam簡(jiǎn)要介紹了搜索問題的關(guān)鍵階段流程,頁面評(píng)定(圖1)。在第一階段,服務(wù)器群——大量的服務(wù)器,選擇候選頁面:含有某些搜索字符串元素的頁面。這些頁面被送入評(píng)定引擎,本身包括三級(jí):特性提取、自由形式表達(dá)評(píng)估,以及機(jī)器學(xué)習(xí)評(píng)分。
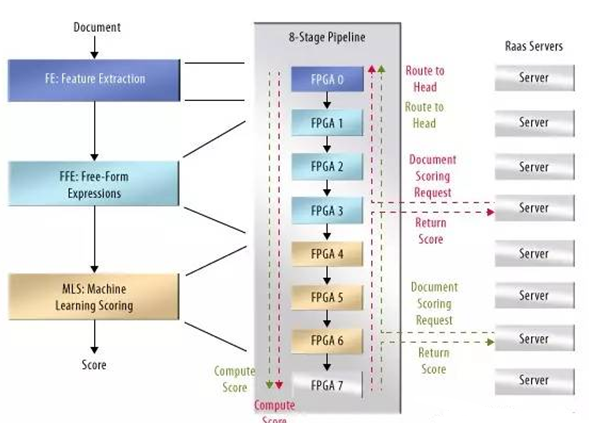
圖1.在專用處理單元群中實(shí)現(xiàn)頁面評(píng)定流水線,加速必應(yīng)搜索。
Putnam說,特性提取是由54個(gè)硬件狀態(tài)機(jī)陣列完成的,即,規(guī)則表達(dá)匹配和結(jié)果列表。使用狀態(tài)機(jī)避免了指令獲取和解碼操作帶來的能耗問題。為進(jìn)一步降低能耗,頁面內(nèi)容不會(huì)通過特性提取器:只有記錄特性出現(xiàn)、位置和頻率的表格數(shù)據(jù)被傳送至下一級(jí)。
表達(dá)式評(píng)估器是另一陣列,但這次是特殊的多線程處理器陣列。這些處理器,以240個(gè)單元為一群,讀取來自提取器的表格數(shù)據(jù),從中計(jì)算出非常復(fù)雜的數(shù)字表達(dá)值,這可能會(huì)包括超越函數(shù)。必應(yīng)開發(fā)人員調(diào)整了算法,因此,這些表達(dá)式會(huì)有所變化,無法對(duì)其進(jìn)行硬線連接。這一級(jí)的輸出是頁面評(píng)定,為從搜索字符串中提取出的元特性分配一個(gè)數(shù)字。
這一數(shù)據(jù)隨后被送入機(jī)器學(xué)習(xí)級(jí),Putnam對(duì)此并沒有介紹,這可能需要大量的并行神經(jīng)網(wǎng)絡(luò)仿真。正是這一可訓(xùn)練級(jí)為頁面產(chǎn)生最終的評(píng)定分。
Putnam說,微軟選擇在大規(guī)模FPGA的2D平面內(nèi)實(shí)現(xiàn)三級(jí)評(píng)定引擎。每一FPGA位于中間電路板上,插入到微軟標(biāo)準(zhǔn)服務(wù)器機(jī)柜的服務(wù)器刀片中。Putnam觀察到,可以采用ASIC來很好的均衡速度和功耗。但是由于必應(yīng)評(píng)定算法的多變性,需要具備重新配置能力。他提醒說,否則,特殊的硬件很快就會(huì)成為程序員面臨的瓶頸問題,最終不得不依賴數(shù)據(jù)中心來解決問題。
微軟的設(shè)計(jì)人員建立了硬件引擎的很多例化,允許異步運(yùn)行,研究頁面評(píng)定的固有并行特性。盡可能減少指令獲取和解碼操作。定義了任務(wù),因此,只有很少量的數(shù)據(jù)在流水線級(jí)之間傳送。在不同的環(huán)境中應(yīng)用相同的原理,會(huì)導(dǎo)致完全不同的體系結(jié)構(gòu)。
矢量處理器
搜索引擎使用的數(shù)據(jù)集有兩個(gè)重要的特性(除了巨大的規(guī)模之外)。首先,數(shù)據(jù)元素是獨(dú)立的。即,一個(gè)頁面的評(píng)定分值對(duì)任何其他頁面的分值沒有影響,因此,打分任務(wù)互不影響。其次,數(shù)據(jù)元素是非結(jié)構(gòu)化的:兩個(gè)頁面不必有相同的格式。
但是仍然有其他大量的數(shù)據(jù)集具有嚴(yán)格的結(jié)構(gòu)。例如,在大氣模型中,每一點(diǎn)都會(huì)是矢量,包括了坐標(biāo)、溫度、入射射線、各種氣體的壓力分量,以及懸浮顆粒的濃度等。計(jì)算模型的下一狀態(tài)需要對(duì)同一矢量算法進(jìn)行大量的重復(fù)。
這些問題非常適合采用矢量處理器來解決:很多同樣的算法流水線工作在鎖定步驟,同時(shí)完成相同的運(yùn)算,但是針對(duì)不同的數(shù)據(jù)——即,經(jīng)常使用的術(shù)語,單指令多數(shù)據(jù)(SIMD)機(jī)制。很顯然,這些機(jī)制并行完成很多運(yùn)算,從而提高了性能。通過減少指令獲取數(shù)據(jù)流,也降低了能耗。
在熱點(diǎn)芯片大會(huì)上,NEC開發(fā)經(jīng)理Shintaro Momose介紹了他所在單位的下一代芯片設(shè)計(jì),包括NEC長(zhǎng)遠(yuǎn)的SX系列矢量超級(jí)計(jì)算機(jī):SX-ACE。Momose重點(diǎn)介紹了兩個(gè)特殊問題:存儲(chǔ)器帶寬和粒度。
Momose解釋了很多大規(guī)模應(yīng)用——包括天氣預(yù)報(bào)、例子物理、流體動(dòng)力學(xué),以及結(jié)構(gòu)分析等,為提高計(jì)算性能,這需要很高的存儲(chǔ)器帶寬,計(jì)算機(jī)每完成一次浮點(diǎn)運(yùn)算都需要與存儲(chǔ)器交換一個(gè)字節(jié)。而矢量處理器芯片達(dá)到了數(shù)十GFLOPS,對(duì)DRAM的要求越來越高——足以填滿芯片的任何總線。相應(yīng)的,NEC把DRAM控制器——16個(gè)獨(dú)立的DDR3 SDRAM控制器,直接放到矢量處理器管芯中,大量的管芯交叉開關(guān)連接所有DRAM通道和任何矢量處理單元。這一決定使得單芯片總帶寬達(dá)到256 GBps。
粒度是更有趣的一個(gè)問題。并行體系結(jié)構(gòu)最近的發(fā)展趨勢(shì)是——可能受到圖形處理單元(GPU)進(jìn)行高性能計(jì)算的影響,由非常簡(jiǎn)單的處理器構(gòu)成大規(guī)模陣列。而Momose看到,這類體系結(jié)構(gòu)雖然概念上很簡(jiǎn)單,但是在實(shí)際中,要求程序員發(fā)現(xiàn)足夠的并行功能,使這些小CPU工作起來,讓每一個(gè)任務(wù)保持同步或者互相鎖定。他認(rèn)為,更好的是采用一些功能更強(qiáng)大的矢量?jī)?nèi)核而不是很多小內(nèi)核。
這就是SX-ACE所采用的方法。每一芯片中的每個(gè)內(nèi)核都包括標(biāo)量處理單元、矢量處理單元和1 MB的共享快速RAM。矢量單元有16個(gè)處理模塊,每個(gè)模塊包括了兩個(gè)加法流水線,兩個(gè)乘法流水線,以及一個(gè)除法/平方根流水線,一個(gè)邏輯流水線,以及一個(gè)屏蔽流水線。每一芯片有四個(gè)內(nèi)核,因此,每一芯片總峰值達(dá)到256 GFLOPS,與存儲(chǔ)器總帶寬相匹配。在大規(guī)模本地存儲(chǔ)器周圍布置快速控制處理器和16個(gè)算術(shù)模塊,NEC找到了大規(guī)模并行和實(shí)際代碼編程的最佳平衡點(diǎn),這些代碼與實(shí)際的數(shù)據(jù)有很大的相關(guān)性。
需要大量流水線的應(yīng)用
與數(shù)據(jù)并行的很多問題相比,數(shù)據(jù)中的一些問題看起來很難解決,但是可以編程,產(chǎn)生很多線程。在這種情況下,您仍然可以實(shí)現(xiàn)很多并行執(zhí)行,但是每一線程可以完成不同的工作,因此,矢量處理體系結(jié)構(gòu)的價(jià)值不大。對(duì)于這些情形,ARM? CTO Mike Muller在他的主題演講中建議了一種不同的策略:他稱之為異構(gòu)計(jì)算/同構(gòu)體系結(jié)構(gòu)。
這種想法來自于ARM的big.LITTLE概念。如果一項(xiàng)任務(wù)有很多線程,一個(gè)或者兩個(gè)線程真正需要大量的計(jì)算,而很多線程并不需要。big.LITTLE概念就是把一些小規(guī)模的低功耗處理器,以及使用相同的指令集而功能強(qiáng)大的大規(guī)模處理器組織起來。然后,硬核線程可以在高速大功率CPU上運(yùn)行,線程完成后,可以選通電源供電。在較慢的低功耗CPU上運(yùn)行簡(jiǎn)單線程。
在熱點(diǎn)芯片大會(huì)上,Muller進(jìn)一步延伸了這一概念,他建議,除了big和LITTLE ARM內(nèi)核,集群還可以含有ARM的MALI GPU內(nèi)核,以及單指令多線程處理器,一些實(shí)例目前已經(jīng)在ARM的研究實(shí)驗(yàn)室中開始規(guī)劃了(圖2)。所有處理器會(huì)共享公共編程語言,甚至是某些對(duì)象代碼,共享主存儲(chǔ)器,透明、動(dòng)態(tài)的進(jìn)行線程分配,降低了對(duì)顯式數(shù)據(jù)傳送的需求。通過把每一線程分配給低功耗處理器,滿足了線程目前的性能需求,這類系統(tǒng)降低了總?cè)蝿?wù)的能耗。
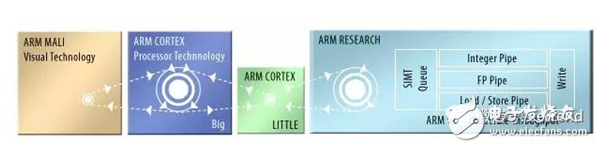
圖2.ARM的異構(gòu)計(jì)算同構(gòu)體系結(jié)構(gòu)結(jié)合了完全不同的微體系結(jié)構(gòu)內(nèi)核,可以共享相同的源代碼。
單線程性能
聰明的程序員發(fā)現(xiàn)并應(yīng)用了數(shù)據(jù)并行執(zhí)行功能,梳理好代碼中的所有線程后,仍然存在單線程執(zhí)行的問題。但是,我們已經(jīng)把時(shí)鐘頻率、超標(biāo)量體系結(jié)構(gòu)、分支預(yù)測(cè)以及很多其他方法發(fā)揮到了極限。還有什么其他好辦法嗎?在一篇介紹新Denver CPU內(nèi)核的文章中,Nvidia CPU設(shè)計(jì)師Darrell Boggs說,有。
丹佛很可能是ARM V8所要采用的(圖3)。這是一種七路超標(biāo)量體系結(jié)構(gòu),含有整數(shù)、整數(shù)/負(fù)載存儲(chǔ)和NEON浮點(diǎn)執(zhí)行流水線。它使用了硬件預(yù)獲取單元,每一周期解碼8條指令。這實(shí)際源自很早的CPU體系結(jié)構(gòu)的一種特性:丹佛完成動(dòng)態(tài)隨時(shí)微代碼優(yōu)化功能。
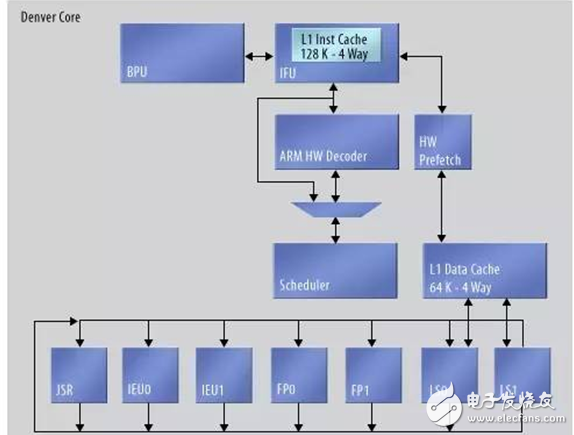
圖3.在您深入了解指令獲取單元之前,Nvidia的丹佛CPU看起來像是傳統(tǒng)的超標(biāo)量CPU。
Boggs解釋說;“執(zhí)行和分支單元在執(zhí)行期間對(duì)代碼進(jìn)行分析。把分析信息傳送給硬件優(yōu)化器,解開循環(huán),重新命名寄存器,重新組織指令。然后,優(yōu)化后的代碼以微代碼的形式存儲(chǔ)器在特殊高速緩存中。”
Boggs解釋說,第一次通過循環(huán),丹佛構(gòu)建了代碼的微代碼版本,優(yōu)化了數(shù)千條指令。在后續(xù)的步驟中,讀取單元裝入來自優(yōu)化高速緩存而不是指令高速緩存的微代碼,旁路指令解碼器,把微代碼直接送入執(zhí)行單元。結(jié)果,對(duì)于迭代代碼,丹佛在遇到新代碼之前會(huì)盡可能只使用最初的指令流。會(huì)很快開始處理大部分微代碼。
Boggs宣稱,這一方法提高了執(zhí)行速度。他展示了結(jié)果,在標(biāo)準(zhǔn)測(cè)試中,2.5 GHz丹佛接近甚至超越了Intel的Haswell。
Boggs說,丹佛還解決了功耗問題。除了時(shí)鐘選通和電源軌選通之外,CPU還支持低電壓“保持”模式,保持CPU和高速緩存狀態(tài),有效的降低了泄漏電流。通過避免CPU檢查點(diǎn)和高速緩存泛洪問題,保持模式提供了空閑間隙降低功耗的方法,這些間隙非常短,無法完全進(jìn)行電源選通,通過這些方法處理泛洪和狀態(tài)恢復(fù)問題。
對(duì)高性能和低功耗的需求會(huì)持續(xù)不斷,半導(dǎo)體技術(shù)再也不能以簡(jiǎn)單的方式來滿足這些需求。而解決方案越來越專門針對(duì)應(yīng)用的特殊性,算法編程,以及數(shù)據(jù)的本質(zhì)結(jié)構(gòu)等。最終,所有體系結(jié)構(gòu)都會(huì)更加專用化,通用CPU這一術(shù)語的含義也會(huì)逐漸變化。
-
處理器
+關(guān)注
關(guān)注
68文章
19345瀏覽量
230233 -
cpu
+關(guān)注
關(guān)注
68文章
10878瀏覽量
212170 -
工程師
+關(guān)注
關(guān)注
59文章
1571瀏覽量
68556
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

不同時(shí)期的硬件工程師,最怕發(fā)生的事 #電子工程師 #硬件工程師 #內(nèi)容過于真實(shí) #YXC晶振 #揚(yáng)興科技

當(dāng)硬件工程師穿越到霸總劇: 以他性格肯定忍不到第二集? #硬件工程師 #電路設(shè)計(jì) #晶振 #揚(yáng)興科技

當(dāng)你的工程師朋友失聯(lián)時(shí),別氣,ta真的是在忙工作 #搞笑 #電子愛好者 #硬件工程師 #晶振 #揚(yáng)興科技

硬件工程師VS軟件工程師|硬件工程師看到這都淚目了!#硬件設(shè)計(jì) #硬件工程師 #電子工程師 #軟件工程師



干硬件這一行,各種辛酸只有同行才懂吧 ? #電路設(shè)計(jì) #電子愛好者 #硬件工程師 #電子工程師
嵌入式軟件工程師和硬件工程師的區(qū)別?


“班長(zhǎng)!說好畢業(yè)后當(dāng)硬件工程師,你怎么..." #搞笑 #電子行業(yè) #電子工程師 #晶振 #揚(yáng)興科技


一位硬件工程師的歷練之路:從入門學(xué)習(xí)理論到... #搞笑 #硬件工程師 #電子工程師 #揚(yáng)興科技







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論