 端到端InfiniBand網絡解決LLM訓練瓶頸
端到端InfiniBand網絡解決LLM訓練瓶頸
ChatGPT對技術的影響引發了對人工智能未來的預測,尤其是多模態技術的關注。OpenAI推出了具有突破性的多模態模型GPT-4,使各個領域取得了顯著的發展。 這些AI進步是通過大規模模型訓練實現的,這需要大量的計算資源和高速數據傳輸網絡。端到端InfiniBand(IB)網絡作為高性能計算和AI模型訓練的理想選擇,發揮著重要作用。在本文中,我們將深入探討大型語言模型(LLM)訓練的概念,并探索端到端InfiniBand網絡在解決LLM訓練瓶頸方面的必要性。
大型語言模型(LLM)和ChatGPT之間是否存在聯系
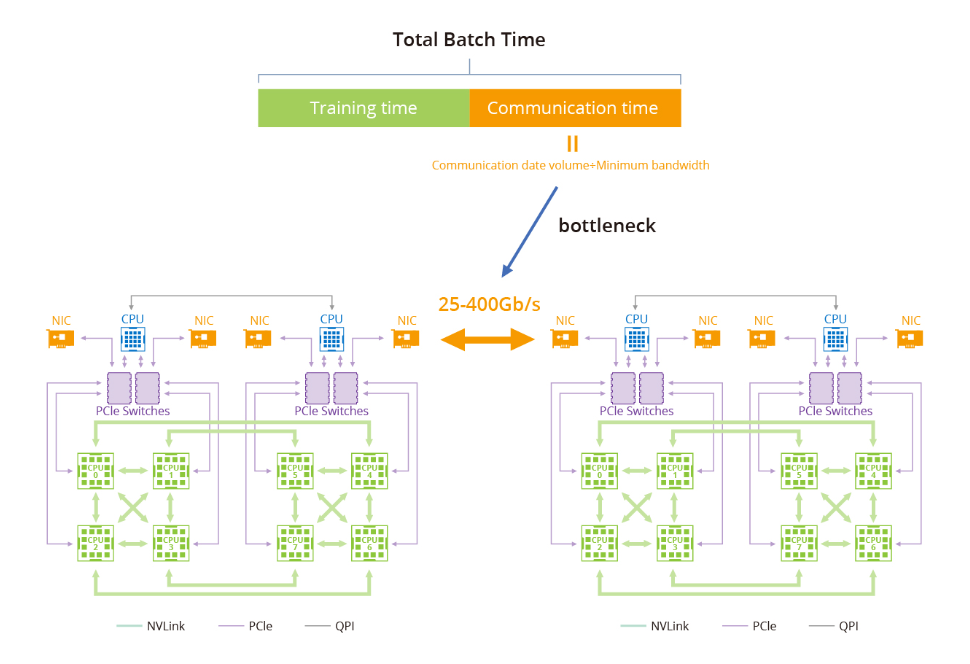
訓練大型語言模型(LLM)面臨的瓶頸主要與GPU計算集群內的數據傳輸和通信有關。隨著大型語言模型的增長,對高速可靠網絡的需求變得至關重要。例如,具有1.75萬億參數的GPT-3的模型無法在單機上訓練,而是嚴重依賴于GPU集群。主要瓶頸在于在訓練集群中高效地在節點之間傳輸數據。
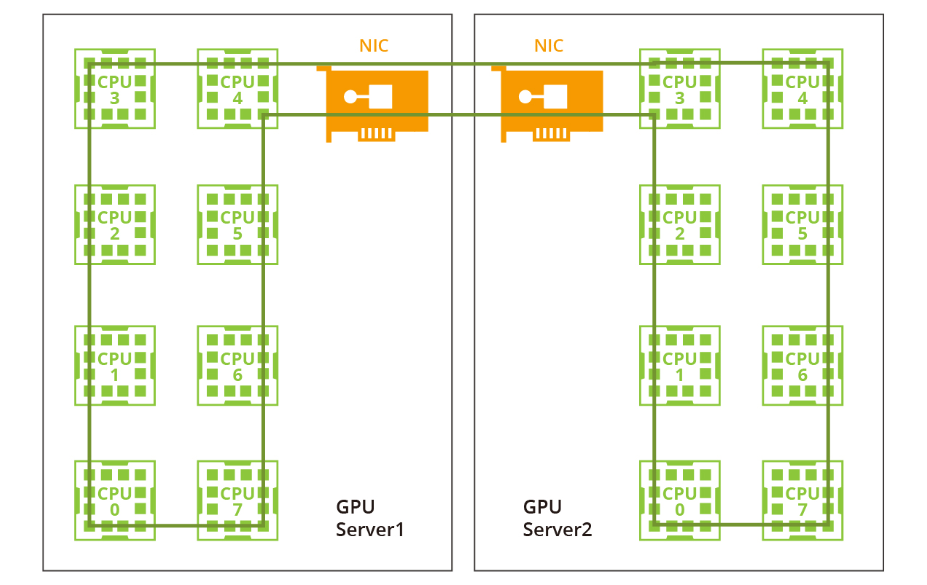
階段1:環形全約減
一種常用的GPU通信算法是環形全約減,其中GPU形成一個環,使數據在環內流動。每個GPU都有一個左鄰和一個右鄰,數據只向右鄰發送,從左鄰接收。該算法包括兩個步驟:散射-約減和全收集。在散射-約減步驟中,GPU交換數據以獲得最終結果的一個塊。在全收集步驟中,GPU交換這些塊,以確保所有GPU都具有完整的最終結果。
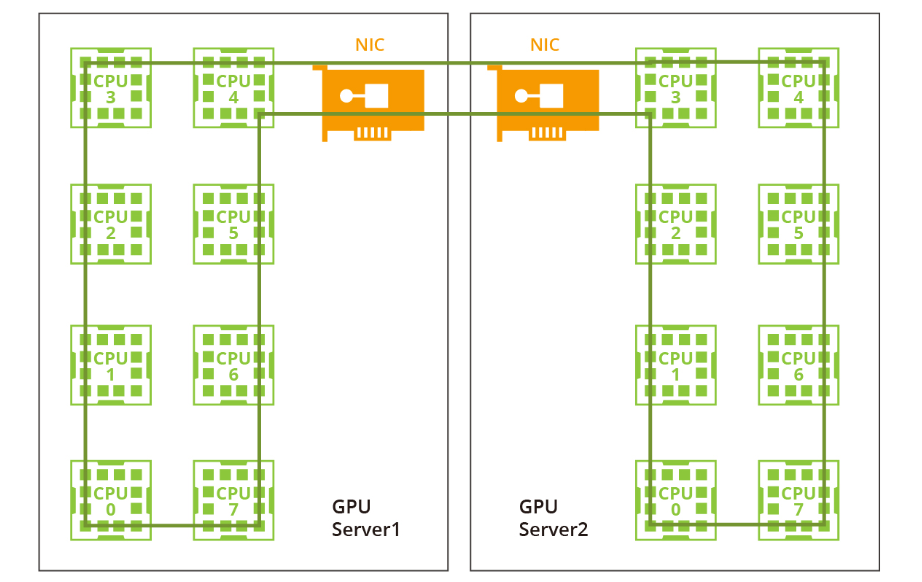
階段2:雙階段環形
過去由于帶寬有限且沒有NVLink或RDMA技術,一個大型環對于單機和多機分布已經足夠。然而,隨著NVLink在單機內的引入,相同的方法不再適用。網絡帶寬遠低于NVLink的帶寬,因此采用一個大環將大幅降低NVLink的效率到網絡的水平。此外,在當前的多網卡環境中,僅利用一個環無法充分利用多個網卡。因此,建議采用雙階段環方法來解決這些問題。 在雙階段環形場景中,數據同步發生在單臺機器內的GPU之間,利用了NVLink的高帶寬優勢。隨后,跨多臺機器的GPU使用多個網卡建立多個環形,以同步來自不同段的數據。最后,單臺機器內的GPU再次進行同步,完成所有GPU之間的數據同步。值得注意的是,NVIDIA集體通信庫(NCCL)在這個過程中發揮了關鍵作用。
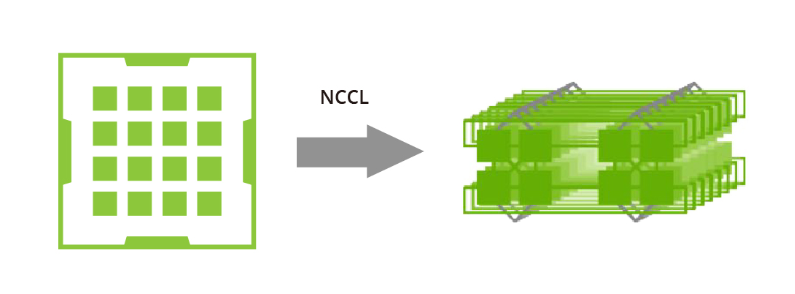
NVIDIA集體通信庫(NCCL)包括針對NVIDIA GPU和網絡進行優化的多GPU和多節點通信例程。NCCL為全收集、全約減、廣播、約減、約減散開和點對點發送和接收操作提供高效的基本操作。這些例程經過優化,以實現高帶寬和低延遲,利用節點內和NVIDIA Mellanox網絡通過PCIe和NVLink高速互連。
通過解決數據傳輸和通信中的瓶頸問題,GPU計算集群的進步以及利用NCCL等工具的使用有助于克服大型語言模型訓練中的挑戰,為AI研究和開發進一步的突破鋪平了道路。
端到端InfiniBand網絡解決方案如何提供幫助
在大型模型訓練中,以太網在傳輸速率和延遲方面存在不足。相比之下,端到端InfiniBand網絡提供了高性能計算解決方案,能夠提供高達400 Gbps的傳輸速率和微秒級的延遲。因此,InfiniBand已成為大規模模型訓練的理想選擇。
數據冗余和錯誤糾正機制
端到端InfiniBand網絡的一個關鍵優勢是其對數據冗余和錯誤糾正機制的支持,確保可靠的數據傳輸。在大規模模型訓練中,由于處理的數據量巨大,傳輸錯誤或數據丟失會對訓練過程產生不利影響,這一點尤為重要。通過利用InfiniBand的強大功能,可以較大程度地減少由于數據傳輸問題引起的中斷或故障。
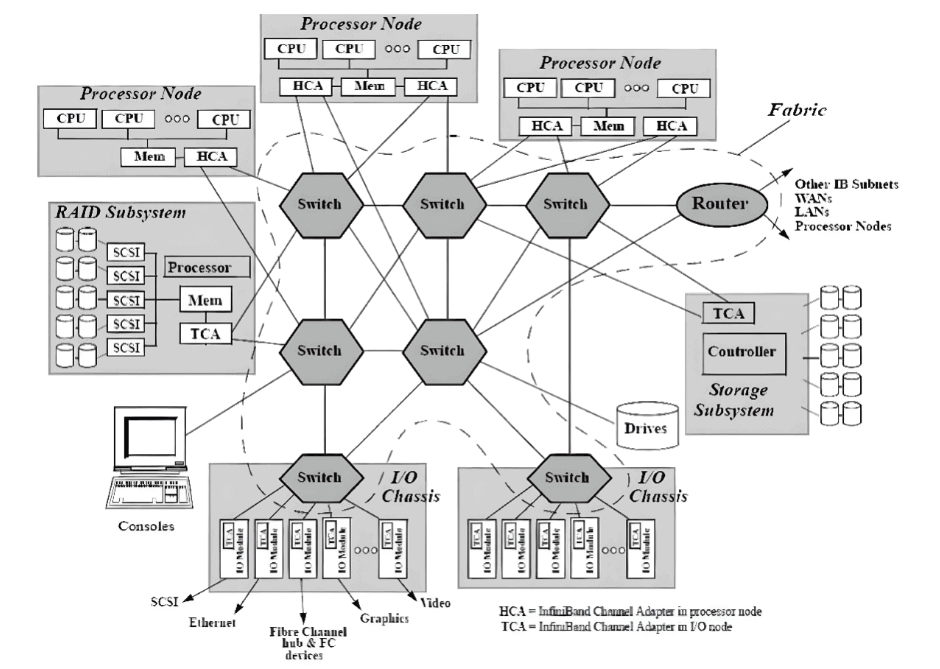
本地子網的配置和維護
在InfiniBand互連協議中,每個節點都配備有一個主機通道適配器(HCA),負責與主機設備建立和維護鏈接。交換機具有多個端口,用于在端口之間進行數據包轉發,從而實現子網內的高效數據傳輸。 子網管理器(SM)在配置和維護本地子網方面發揮著關鍵作用,每個InfiniBand設備上都有子網管理器數據包(SMP)和子網管理器代理(SMA)提供支持。子網管理器(SM)發現和初始化網絡,為所有設備分配唯一標識符,確定最小傳輸單元(MTU),并根據選擇的路由算法生成交換機的路由表。它還定期掃描子網,檢測拓撲變化,并相應調整網絡配置。
基于信用的流量控制
與其他網絡通信協議相比,InfiniBand網絡提供更高的帶寬、更低的延遲和更大的可擴展性。此外,InfiniBand采用基于信用的流量控制,發送節點確保不會傳輸超過接收緩沖區中可用信用數量的數據到連接的另一端。這消除類似TCP窗口算法的數據包丟失機制的需求,使InfiniBand網絡能夠以較低延遲和CPU使用率實現較高數據傳輸速率。
遠程直接內存訪問(RDMA)技術
InfiniBand利用遠程直接內存訪問(RDMA)技術,實現應用程序之間在網絡上直接進行數據傳輸,無需涉及操作系統。這種零拷貝傳輸方法顯著減少了兩端CPU資源的消耗,使應用程序能夠直接從內存中讀取消息。降低的CPU開銷提升了網絡快速傳輸數據的能力,并使應用程序更高效地接收數據。 總體而言,端到端InfiniBand網絡為大型模型訓練提供了顯著優勢,包括高帶寬、低延遲、數據冗余和錯誤糾正機制。通過利用InfiniBand的能力,研究人員可以克服性能限制,增強系統管理,并加速大規模語言模型的訓練。
-
InfiniBand
+關注
關注
1文章
29瀏覽量
9192 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7592 -
大模型
+關注
關注
2文章
2423瀏覽量
2640
原文標題:InfiniBand:突破大模型訓練性能瓶頸
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
InfiniBand 連接現在和未來
語音端到端加密方案
為WiMAX構建端到端的網絡架構
基于WiMAX接入技術的端到端網絡架構
端到端的自動駕駛研發系統介紹
我國正式啟動了5G網絡切片端到端總體架構標準研制工作
三大巨頭實現首個基于APP應用級的5G SA端到端網絡切片
基于深度神經網絡的端到端圖像壓縮方法

英偉達三大AI法寶:CUDA、Nvlink、InfiniBand

理想汽車自動駕駛端到端模型實現

連接視覺語言大模型與端到端自動駕駛

如何訓練自己的LLM模型
準確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni






 工商網監
工商網監
評論