


編者按:tryo.labs是一家專注于機器學(xué)習(xí)和自然語言處理的技術(shù)支持公司,在本篇文章中,公司的研究人員介紹了他們在研究過程中所使用的先進目標(biāo)檢測工具Faster R-CNN,包括它的構(gòu)造及實現(xiàn)原理。
之前,我們介紹了目標(biāo)物體檢測(object detection)是什么以及它是如何用于深度學(xué)習(xí)的。去年,我們決定研究Faster R-CNN。通過閱讀原論文以及相關(guān)的參考文獻,我們對其工作原理及如何部署已經(jīng)有了清晰的了解。
最終,我們將Faster R-CNN安裝到Luminoth上,Luminoth是基于TensorFlow的計算機視覺工具包,我們在公開數(shù)據(jù)科學(xué)大會(ODSC)的歐洲和西部會場上分享了這一成果,并收到了很多關(guān)注。
基于我們研發(fā)Luminoth中的收獲以及分享成果,我們認為應(yīng)當(dāng)把研究所得記錄到博客中,以饗讀者。
背景
Faster R-CNN最初是在NIPS 2015上發(fā)表的,后來又經(jīng)過多次修改。Faster R-CNN是Ross Girshick團隊推出的R-CNN的第三次迭代版本。
2014年,在第一篇R-CNN的論文Rich feature hierarchies for accurate object detection and semantic segmentation中,研究人員利用一種名為選擇性搜索(selective search)的算法提出一種可能的感興趣區(qū)域(RoI)和一個標(biāo)準的卷積神經(jīng)網(wǎng)絡(luò)來區(qū)分和調(diào)整它們。2015年初,R-CNN進化成為Fast R-CNN,其中一種名為興趣區(qū)域池化(RoI Pooling)的技術(shù)能夠共享耗能巨大的計算力,并且讓模型變得更快。最后他們提出了Faster R-CNN,是第一個完全可微分的模型。
結(jié)構(gòu)
Faster R-CNN的結(jié)構(gòu)十分復(fù)雜,因為它有好幾個移動部分。我們首先對Faster R-CNN做大致介紹,然后對每個組成部分進行詳細解讀。
問題是圍繞一幅圖像,從中我們想要得到:
邊界框的列表
每個邊界框的標(biāo)簽
每個標(biāo)簽和邊界框的概率
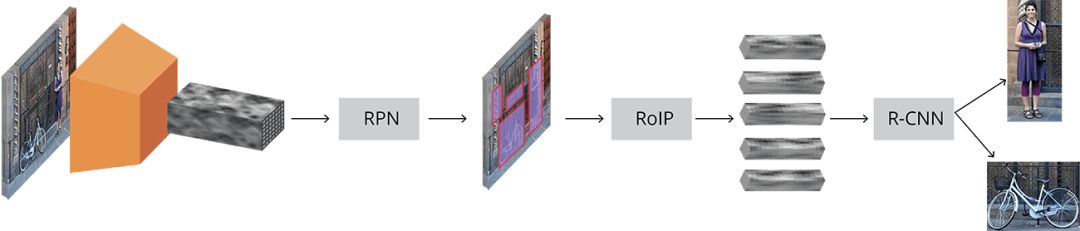
Faster R-CNN完整示意圖
輸入的圖像用高度×寬度×深度的張量(多維數(shù)組)表示,在傳輸?shù)街虚g層之前,先經(jīng)過一個預(yù)訓(xùn)練的CNN,最終生成卷積特征映射。我們將這一映射作為下一部分的特征提取器。
這一技術(shù)在遷移學(xué)習(xí)中還是很常見的,尤其是利用在大規(guī)模數(shù)據(jù)庫上訓(xùn)練的網(wǎng)絡(luò)權(quán)重,來訓(xùn)練小規(guī)模數(shù)據(jù)庫上的分類器。
接著,我們得到了Region Proposal Network(RPN),利用CNN計算出的特征,使用RPN找到既定數(shù)量的區(qū)域(邊框線),其中可能包含目標(biāo)對象。
也許用深度學(xué)習(xí)做目標(biāo)檢測最難的部分就是生成一個長度可變的邊界框列表。對深度神經(jīng)網(wǎng)絡(luò)進行建模時,最后一個block通常是一個固定大小的張量輸出(除使用循環(huán)神經(jīng)網(wǎng)絡(luò)以外)。例如,在圖像分類中,輸出的是一個(N,)的張量,N代表類別的數(shù)量,其中的位置i處的每個標(biāo)量包含該圖像被標(biāo)位labeli的概率。
在RPN中可以使用anchors解決可變長度的問題:在原始圖像中統(tǒng)一放置固定大小的參考邊界框,與直接檢測物體的位置不同,我們將問題分為兩部分。對每個anchor,我們會想:
這個anchor是否含有相關(guān)目標(biāo)對象?
如何調(diào)整這個anchor才能讓它更好地適應(yīng)相關(guān)對象?
聽起來可能有點迷惑,接下來我們將深入探討這個問題。
在原始圖像中得到可能的相關(guān)對象及其位置的列表后,問題就更直接了。利用CNN提取的特征和包含相關(guān)對象的邊界框,應(yīng)用RoI pooling,將與相關(guān)對象對應(yīng)的特征提取出一個新的向量。
最后是R-CNN模塊,它利用這些信息來:
將邊界框里的內(nèi)容分類(或標(biāo)記成“背景”標(biāo)簽丟棄它)
調(diào)整邊界框的坐標(biāo),使其更適合目標(biāo)對象
雖然描述得比較粗略,但這基本上是Faster R-CNN的工作流程。接下來,我們將詳細介紹每一部分的架構(gòu)、損失函數(shù)以及訓(xùn)練過程。
基本網(wǎng)絡(luò)(Base Network)
就像我們之前提到的,第一步是利用一個為分類任務(wù)預(yù)先訓(xùn)練過的CNN(比如ImageNet)和中間層的輸出。對于有機器學(xué)習(xí)背景的人來說,這聽上去挺簡單的。但是關(guān)鍵一點是要理解它是如何工作的,以及為什么會這樣工作。同時還要讓中間層的輸出可視化。
目前沒有公認的最好的網(wǎng)絡(luò)架構(gòu)。最早的R-CNN使用了在ImageNet上預(yù)訓(xùn)練的ZF和VGG,但從那以后,有許多權(quán)重不同的網(wǎng)絡(luò)。例如,MobileNet是一種小型網(wǎng)絡(luò),優(yōu)化后高效的網(wǎng)絡(luò)體系結(jié)構(gòu)能加快運行速度,它有將近3.3M的參數(shù),而152層的ResNet(對,你沒看錯就是152層)有大約60M參數(shù)。最近,像DenseNet這樣的新架構(gòu)既改善了結(jié)果,又減少了參數(shù)數(shù)量。
VGG
在比較孰優(yōu)孰劣之前,讓我們先用標(biāo)準的VGG-16為例來理解他們都是怎樣工作的。
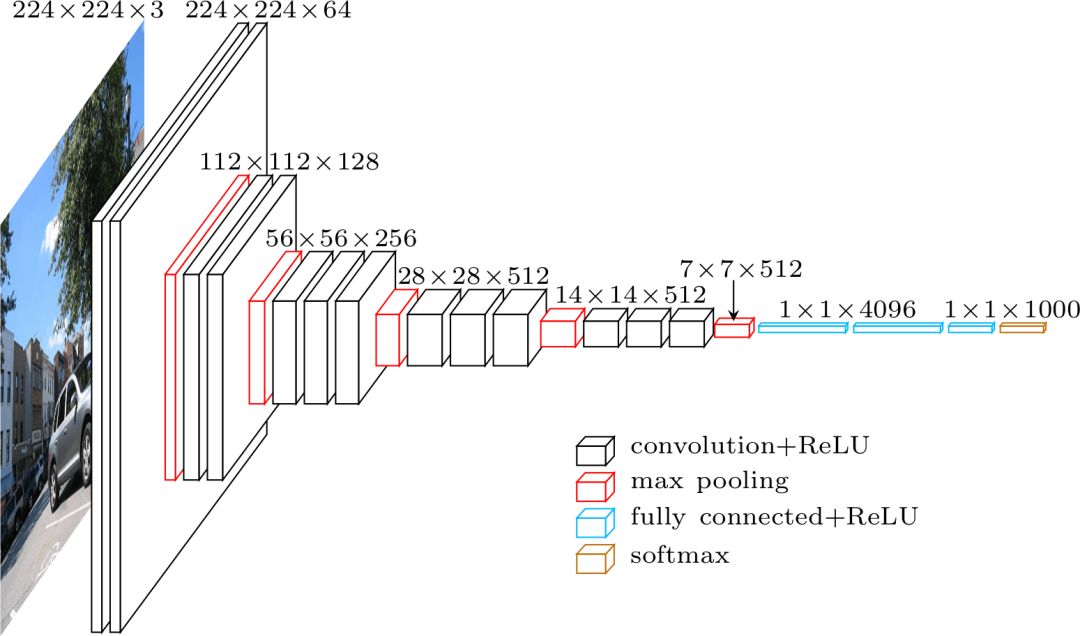
VGG架構(gòu)
VGG這個名字來源于2014年ImageNet ILSVRC比賽中的一組選手,其中的Karen Simonyan和Andrew Zisserman發(fā)表了一篇名為Very Deep Convolutional Networks for Large-Scale Image Recognition的論文。若以現(xiàn)在的標(biāo)準來看,這已經(jīng)不是“very deep”的網(wǎng)絡(luò)了,但在當(dāng)時,它比通常使用的網(wǎng)絡(luò)層數(shù)增加了一倍多,并且開始了“deeper→more capacity→better”的波動(當(dāng)可以訓(xùn)練的時候)。
使用VGG分類時,輸入的是224×224×3的張量(即224×224像素的RGB圖像)。由于網(wǎng)絡(luò)的最后一個模塊使用完全連接層(FC)而不是卷積,這需要一個固定長度的輸入。通常將最后一個卷積層的輸出平坦化,在使用FC層之前得到第一次命中的張量。
由于我們要使用中間卷積層的輸出,所以輸入的大小不用特別考慮。至少,在這個模塊中不用擔(dān)心,因為只使用了卷積層。讓我們繼續(xù)詳細介紹,決定到底要使用哪個卷積層。論文中并未指明要使用的圖層,但在實際安裝過程中,你可以看到它們用了conv5/conv5_1的輸出。
每個卷積層都會從之前的信息中生成抽象的東西。第一層圖層通常學(xué)習(xí)圖像中的邊緣線,第二層找出邊緣內(nèi)的圖形,以學(xué)習(xí)更復(fù)雜的形狀等。最終我們得到了卷積特征向量,它的空間維度比原始圖像小得多,但是更深。特征映射的寬度和高度由于卷積層之間的池化而降低,同時由于卷積層學(xué)習(xí)的過濾器數(shù)量增多導(dǎo)致映射的深度增加。
圖像到卷積特征映射
在深度上,卷積特征映射已經(jīng)對圖像的所有信息進行編碼,同時保持其相對于原始圖像編碼的“物體”的位置。例如,如果圖像的左上角有一個紅色正方形,并且卷積層激活了它,那么該紅色正方形的信息仍然位于卷積特征映射的左上角。
VGG vs ResNet
目前,ResNet架構(gòu)大多已經(jīng)取代了VGG作為特征提取的基礎(chǔ)網(wǎng)絡(luò),F(xiàn)aster R-CNN的三位合作者(Kaiming He,Shaoqing Ren和Jian Sun)也是ResNet原始論文Deep Residual Learning for Image Recognition的共同作者。
相對于VGG,ResNet的明顯優(yōu)勢在與它更大,因此它有更大能力去了解需要什么。這對分類任務(wù)來說是正確的,同時對目標(biāo)物體檢測也是如此。
此外,ResNet讓使用殘差網(wǎng)絡(luò)和批量歸一化來訓(xùn)練深度模型變得簡單,這在VGG發(fā)布之初并未出現(xiàn)。
Anchors
既然我們有了處理過的圖像,則需要找到proposals,即用于分類的興趣區(qū)域(RoI)。上文中提到,anchors是解決可變長度問題的方法,但是沒有詳細講解。
我們的目標(biāo)是在圖像中找到邊界框,它們呈矩形,有不同的尺寸和長寬比。想像一下,我們事先知道圖像中有兩個對象,若要解決的話,第一個立即想到的方案是訓(xùn)練一個返回八個值的網(wǎng)絡(luò):xmin、ymin、xmax、ymax元組各兩個,以確定每個目標(biāo)物體的邊界框位置。這種方法有一些非常基礎(chǔ)的問題。例如,圖像的尺寸和長寬比可能不同,訓(xùn)練預(yù)測原始坐標(biāo)的良好模型可能會變得非常復(fù)雜。另外,模型可能會生成無效的預(yù)測:當(dāng)預(yù)測xmin和xmax的值時,我們需要保證xmin<xmax。
最終,事實證明通過學(xué)習(xí)預(yù)測參考框的偏移量,可以更簡單地預(yù)測邊界框的位置。我們?nèi)center,ycenter,寬度,高度,學(xué)習(xí)預(yù)測Δxcenter、Δycenter、Δwidth、Δheight,這些值可以將參考框調(diào)整得符合我們的需要。
Anchors是固定的邊界框,它們遍布整個圖像,具有不同的大小和比例,這些尺寸在第一次預(yù)測目標(biāo)對象位置的時候用作參考。
由于我們是用的是尺寸為convwidth×convheight×convdepth的卷積特征映射,于是可以在convwidth×convheight中的每個點創(chuàng)造一組anchors。即使anchors是基于卷積特征映射,理解這一點也是非常重要的,最終的anchors可以顯示原始圖像。
由于我們只有卷積層和池化層,特征映射的維度在原始圖像中是成比例的。用數(shù)學(xué)方法表示,即如果圖像是w×h,特征映射就是w/r×h/r,這里的r被稱為subsampling ratio。如果我們把特征映射的每個空間位置定義一個anchor,那么最終的圖像將會是由分散的r像素組成的一群anchors。在VGG中,r=16.
原始圖像的anchor中心
為了更好的選擇anchors,我們通常會定義一組尺寸(例如64px,128px,256px)和一組邊框的寬高比(例如0.5,1,1.5),并且將所有可能的尺寸和比例加以組合。

左:anchors,中:單點的anchor,右:所有anchors
Region Proposal Network
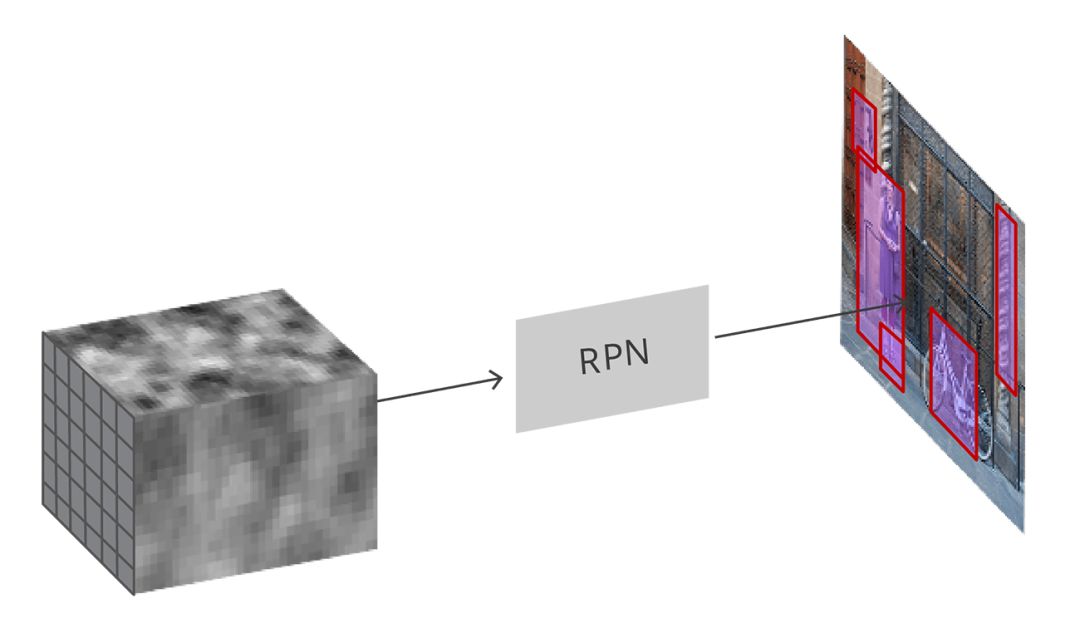
輸入卷積特征映射,RPN在圖像上生成proposals
正如之前所提到的,將所有參考框(anchors)輸入RPN中,輸出一組目標(biāo)的proposals,每個anchors會有兩個不同的輸出。
第一個輸出是anchor中是目標(biāo)對象的概率,可稱為“目標(biāo)性分數(shù)”(objectness score)。注意,RPN不關(guān)心目標(biāo)物體的類別,它只能分辨目標(biāo)與背景。我們將用這個分數(shù)過濾掉不佳的預(yù)測,為第二階段做準備。第二個輸出是邊界框回歸,它的作用是調(diào)整anchors,讓它們更好地圈住目標(biāo)物體。
在完全卷積的環(huán)境中,RPN的安裝十分高效,利用基礎(chǔ)網(wǎng)絡(luò)返回的卷積特征映射作為輸入。首先,我們有一個擁有512個通道和3×3大小的核的卷積層,然后利用1×1的核及一個帶有兩平行通道的卷積層,其中它的通道數(shù)量取決于每個點的anchors數(shù)量。
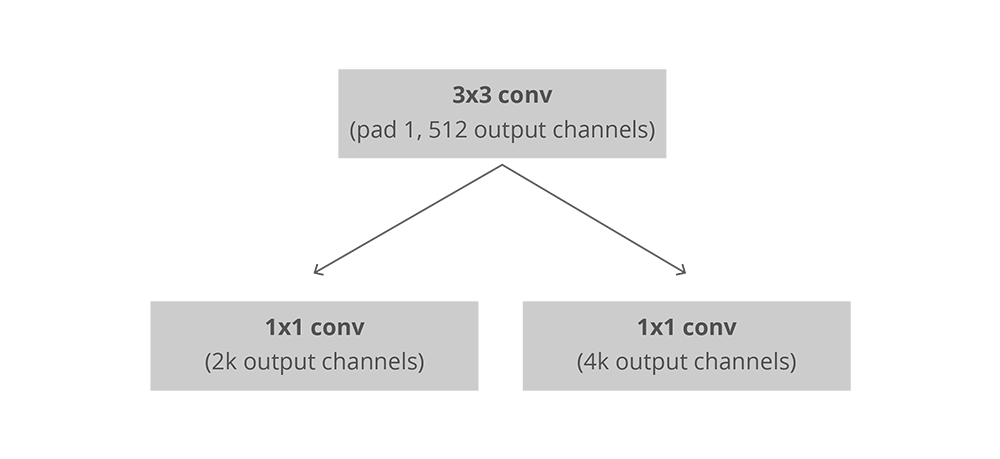
RPN中卷積的安裝,k是anchors的數(shù)量
對于分類層,每個anchor輸出兩個預(yù)測:它為背景的分數(shù)(不是目標(biāo)物)以及它為前景的分數(shù)(實際的目標(biāo)物)。
對于回歸函數(shù),或者邊界框的調(diào)整層,我們輸出四個預(yù)測值:Δxcenter、Δycenter、Δwidth、Δheight,這些會應(yīng)用到anchors上生成最終的proposals。
利用最終的proposals坐標(biāo)和它們的“目標(biāo)性分數(shù)”,就能得到目標(biāo)物體最佳的proposals。
訓(xùn)練,目標(biāo)和損失函數(shù)
RPN能做出兩種預(yù)測:二元分類問題和邊界框回歸調(diào)整。
在訓(xùn)練時,我們將所有的anchors分成兩類。其中交并比(Intersection over Union,IoU)的值大于0.5、與標(biāo)準目標(biāo)物體重合的anchors被認為是“前景”(foreground),那些不與目標(biāo)物體重合、或者IoU的值小于0.1的被認為是“背景”(background)。
然后,我們對anchors隨機采樣256個樣本,同時保證前景和背景anchors的比例不變。
接著,RPN用上述樣本進行計算,利用二元交叉熵計算出分類器的損失函數(shù)。然后用樣本中的前景anchors計算回歸函數(shù)。在計算回歸函數(shù)的目標(biāo)時,我們用前景的anchor和最近的目標(biāo)物體計算能將anchor變?yōu)槟繕?biāo)物體的正確的Δ。
除了用簡單的L1或者L2損失函數(shù)糾正回歸函數(shù)的錯誤,論文中還建議用Smooth L1損失函數(shù)。Smooth L1與L1基本相同,但是當(dāng)L1的錯誤足夠小(用一確定的值σ表示),它就被認為是接近正確的,損失就會以更快的速度消失。
但是用動態(tài)群組(dynamic batches)會有一些困難。即使我們嘗試保持兩種anchors之間比例的平衡,也無法完美地做到這一點。根據(jù)圖像中真實目標(biāo)物體的位置以及anchors的尺寸和比例,有可能最終沒有位于前景的anchors。在這種情況下,我們轉(zhuǎn)而使用IoU值最大的anchors來確定正確邊框的位置。這與理想情況相差較遠。
后處理
非極大抑制
由于anchors經(jīng)常重合,因此proposals最終也會在同意目標(biāo)物體上重疊。為了解決這一問題,我們用簡單的“非極大抑制”(NMS)算法。NMS通過分數(shù)和迭代篩選邊界框并生成一個proposals的列表,放棄IoU大于某個特定閾值的proposals,保留分數(shù)較高的proposals。
雖然看起來簡單,但要謹慎制定IoU的閾值。定的太低,最終可能會找不到正確的proposals;定的太高,最后可能會留下太多proposals。該值常用的數(shù)字是0.6。
Proposal選擇
應(yīng)用了NMS后,我們留下了前N個proposals。在論文中,N=2000,但是即使把數(shù)字換成50也有可能得到相當(dāng)不錯的結(jié)果。
獨立應(yīng)用程序(Standalone application)
RPN可以單獨使用,無需第二個階段的模型。在只有一類對象的問題中,目標(biāo)物體的概率可用作最終的類別概率。這是因為在這種情況下,“前景”=“單一類別”,“背景”=“多種類別”。
在機器學(xué)習(xí)問題中,人臉檢測和文本檢測這種可以從RPN獨立應(yīng)用程序中受益的案例是非常流行的,但目前仍存在很多挑戰(zhàn)。
僅使用RPN的優(yōu)點之一是在訓(xùn)練和預(yù)測中的速度都有所提高。由于RPN是一個非常簡單、并且只是用卷積層的網(wǎng)絡(luò),預(yù)測時間要比其他分類網(wǎng)絡(luò)更快。
興趣區(qū)域池化(RoI Pooling)
RPN階段之后,我們得到一堆沒有分類的proposals。接下來要解決的問題是,如何將這些邊界框分到正確的類別中去。
最簡單的方法是將每個proposals裁剪,然后通過預(yù)訓(xùn)練的基礎(chǔ)網(wǎng)絡(luò)。接著,使用提取出的特征輸入到一般的分類其中。但是想要處理2000個proposals,這樣的效率未免太低了。
這時,F(xiàn)aster R-CNN可以通過重新使用現(xiàn)有的卷及特征映射解決或者緩解這一問題。這是利用RoI池化對每個proposals進行固定大小的特征提取完成的。R-CNN需要固定尺寸的特征映射,以便將它們分成固定數(shù)量的類別。
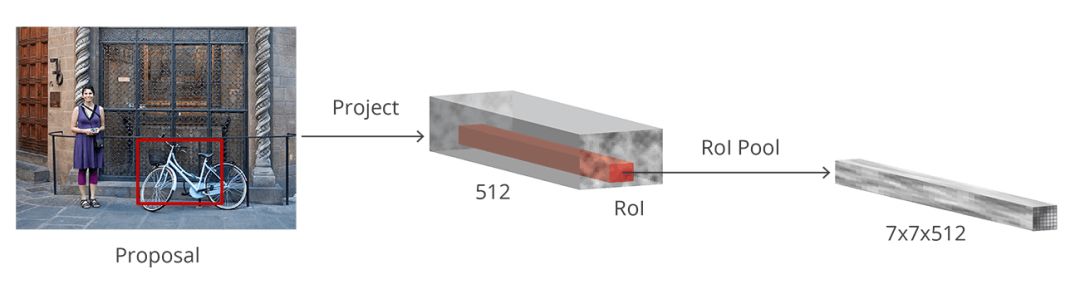
ROI池化
另外一種更簡單的方法,包括Luminoth的Faster R-CNN也在用的,是用每個proposals來裁剪卷積特征映射,然后用雙線性插值將裁剪后的映射調(diào)整為14×14×convdepth的固定大小。裁剪之后,用2×2的最大池得到最終7×7×convdepth的特征映射。
基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(R-CNN)
R-CNN是達到Faster R-CNN的最后一個階段。在從圖像中獲取卷積特征映射后,利用它來獲得目標(biāo)物體的proposals,并最終通過RoI池化為每個proposals提取特征,最后我們需要對這些特征進行分類。R-CNN要模仿CNN分類的最后階段,其中一個完全連接層輸出每個對象可能的類別的分數(shù)。
R-CNN有兩個不同的目的:
將proposals分到其中一類,另外還有一個“背景類”,用于刪除錯誤的proposals
根據(jù)預(yù)測的類別更好地調(diào)整proposals的邊界框
在最初的Faster R-CNN論文中,R-CNN將特征映射應(yīng)用于每個proposal,“壓平”(flatten)后使用ReLU和兩個4096大小的完全連接層將其激活。
然后,它為每個不同的目標(biāo)物體使用兩個不同的完全連接層:
擁有N+1個單位的完全連接層,整理N是類別的總數(shù),多出來的1表示背景
擁有4N個單位的完全連接層。想進行回歸預(yù)測,所以需要對N個可能的類別進行Δxcenter、Δycenter、Δwidth、Δheight四個值的預(yù)測
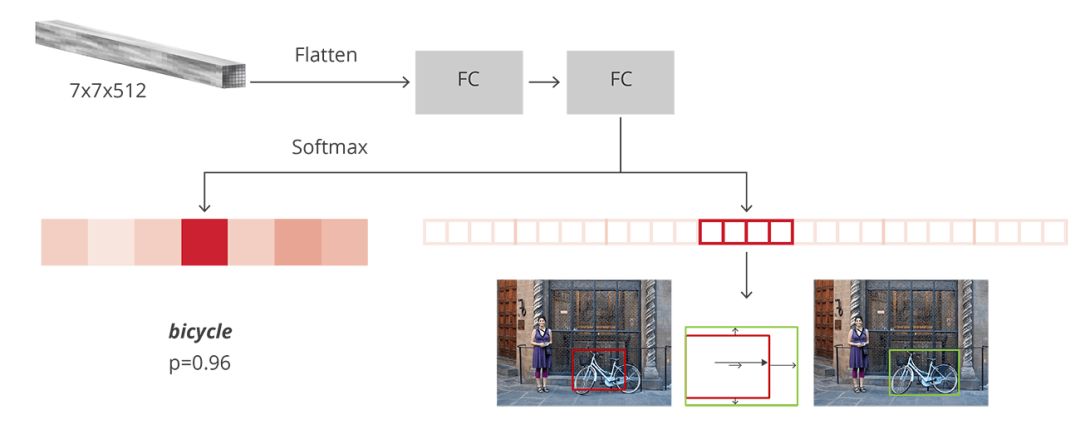
R-CNN的結(jié)構(gòu)
訓(xùn)練和目標(biāo)
R-CNN的目標(biāo)與RPN的目標(biāo)幾乎相同,但考慮到不同類別,我們計算了proposals和標(biāo)準邊界框之間的IoU。
那些大于0.5的proposals被認為是正確的邊框,而分數(shù)在0.1和0.5之間的proposals被標(biāo)記為“背景”。與我們在為RPN組裝目標(biāo)時所做的相反,我們忽略了沒有交集的proposals。這是因為在這個階段,我們假設(shè)這里的proposals很好,而且想要解決更難的案例。當(dāng)然,所有這些可以調(diào)整的超參數(shù)可以更好地適合目標(biāo)物的種類。
邊界框回歸的目標(biāo)試計算proposals與其相應(yīng)的標(biāo)準框架之間的偏移量,而且這里僅針對那些基于IoU閾值分配了類別的proposals。
我們隨機抽樣了一個尺寸為64的迷你群組,其中有高達25%的前景proposals,75%的背景。
按照我們對RPNs損失做的那樣,對于全部所選出的proposals,分類器的損失現(xiàn)在是一個多類交叉熵損失;對于那25%的前景proposals,用Smooth L1損失。由于為了邊框回歸的R-CNN完全連接網(wǎng)絡(luò)的輸出對每種類別只有一個預(yù)測,所以在獲得這種損失時不需小心。在計算損失時,我們只要考慮正確的類別即可。
后處理
與RPN相似,我們最終又得到了一堆已分類的目標(biāo)對象,在返回他們之前需要進行進一步處理。
為了調(diào)整邊框,我們需要考慮哪類是proposals最可能屬于的邊框。同時要忽略那些最有可能是背景的proposals。
在得到最終的目標(biāo)物體之后,我們用基于分類的NMS刪除北京。這是通過將目標(biāo)對象按類別進行分組,然后按概率對其進行排序,然后再將NMS應(yīng)用于每個獨立組。
對于最后的目標(biāo)物體列表,我們也可以為每個類別設(shè)置一個概率閾值和對象數(shù)量的限制。
訓(xùn)練
在原論文中,F(xiàn)aster R-CNN的訓(xùn)練經(jīng)歷了多個步驟,每個步驟都是獨立的,在最終進行全面訓(xùn)練之前合并了所有訓(xùn)練的權(quán)重。從那時起,人們發(fā)現(xiàn)進行端到端的聯(lián)合訓(xùn)練結(jié)果更好。
把模型結(jié)合后,我們可以得到四個不同的損失,兩個用于RPN,兩個用于R-CNN。在RPN和R-CNN上游客訓(xùn)練的圖層,我們也有可以訓(xùn)練(微調(diào))或不能訓(xùn)練的基礎(chǔ)網(wǎng)絡(luò)。
基礎(chǔ)網(wǎng)絡(luò)的訓(xùn)練取決于我們想要學(xué)習(xí)的對象的性質(zhì)和可用的計算能力。如果我們想要檢測與原始數(shù)據(jù)集相似的目標(biāo)對象,那么除了將所有方法都試一遍,也沒什么好方法了。另一方面,訓(xùn)練基礎(chǔ)網(wǎng)絡(luò)是很費時費力的,因為要適應(yīng)全部的梯度。
四種不同的損失用加權(quán)進行組合,這是因為我們可能像給分類器比回歸更多的損失,或者給R-CNN比RPN更多的權(quán)重。
除了正則損失外,我么也有歸一化損失。對一些層使用L2正則化,這取決于正在使用的基礎(chǔ)網(wǎng)絡(luò)以及是否經(jīng)過訓(xùn)練。
我們用隨機梯度下降的動量進行訓(xùn)練,動量設(shè)置為0.9。你可以輕松地訓(xùn)練更快的R-CNN和其他優(yōu)化,不會遇到任何大問題。
學(xué)習(xí)速度開始為0.001,后來經(jīng)過5萬次迭代后降到0.0001。這通常是最重要的超參數(shù)之一。當(dāng)我們用Luminoth進行訓(xùn)練時,通常用默認值開始訓(xùn)練,然后再慢慢調(diào)整。
評估
評估過程使用標(biāo)準的平均精度均值進行判斷(mAP),并將IoU的值設(shè)定在特定范圍。mAP是源于信息檢索的一種標(biāo)準,經(jīng)常用于計算排名和目標(biāo)檢測問題中的錯誤。當(dāng)你漏了某一邊界框、檢測到不存在或者多次檢測到同一物體時,mAP就會進行懲罰。
結(jié)論
現(xiàn)在你應(yīng)該了解R-CNN的工作原理了吧,如果還想深入了解,可以探究一下Luminoth的實現(xiàn)。
Faster R-CNN證明了,在新的深度學(xué)習(xí)革命開始的時候,可以用同樣的原理來解決復(fù)雜的計算機視覺問題。目前正在建立的新模型不僅能用于目標(biāo)物體檢測,還能用于語義分割、3D物體檢測等等。有的借鑒了RPN,有的借鑒了R-CNN,有的二者皆有。這就是為什么我們要搞清楚他們的工作原理,以解決未來將面對的難題。
-
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
229瀏覽量
16059 -
vgg
+關(guān)注
關(guān)注
1文章
11瀏覽量
5357
原文標(biāo)題:目標(biāo)檢測技術(shù)之Faster R-CNN詳解
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于深度學(xué)習(xí)的目標(biāo)檢測算法解析
手把手教你使用LabVIEW實現(xiàn)Mask R-CNN圖像實例分割(含源碼)
基于YOLOX目標(biāo)檢測算法的改進
深度卷積神經(jīng)網(wǎng)絡(luò)在目標(biāo)檢測中的進展
Mask R-CNN:自動從視頻中制作目標(biāo)物體的GIF動圖
什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN
一種新的帶有不確定性的邊界框回歸損失,可用于學(xué)習(xí)更準確的目標(biāo)定位

基于改進Faster R-CNN的目標(biāo)檢測方法
迅速了解目標(biāo)檢測的基本方法并嘗試理解每個模型的技術(shù)細節(jié)
用于實例分割的Mask R-CNN框架
深入了解目標(biāo)檢測深度學(xué)習(xí)算法的技術(shù)細節(jié)
PyTorch教程14.8之基于區(qū)域的CNN(R-CNN)

PyTorch教程-14.8。基于區(qū)域的 CNN (R-CNN)

無Anchor的目標(biāo)檢測算法邊框回歸策略






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論