


在當今這個全球化的世界里,語言多樣性是一個不可忽視的現象。隨著互聯網的普及和國際交流的增加,人們對于能夠理解和交流多種語言的需求也在不斷增長。在這樣的背景下,人工智能領域中的自然語言處理(NLP)技術迎來了巨大的挑戰和機遇。ChatGPT,作為一個領先的語言模型,其多語言支持的特點成為了它在眾多應用場景中不可或缺的優勢。
1. 多語言理解能力
ChatGPT 的多語言支持首先體現在其強大的語言理解能力上。通過訓練大量的多語言文本數據,ChatGPT 能夠理解并生成多種語言的文本,包括但不限于英語、中文、西班牙語、法語、德語等。這種能力使得 ChatGPT 能夠在全球范圍內為用戶提供服務,無論是在商業、教育還是娛樂領域。
1.1 語言模型的預訓練
ChatGPT 的多語言理解能力得益于其在預訓練階段對大量多語言文本的學習。這些文本數據覆蓋了不同的領域和話題,使得模型能夠捕捉到各種語言的語法結構、詞匯用法和語境含義。預訓練過程中,模型通過預測下一個詞或句子的方式來逐步提高其語言理解能力。
1.2 遷移學習和微調
除了預訓練,ChatGPT 還采用了遷移學習和微調技術來進一步提升其在特定語言上的表現。這意味著在預訓練的基礎上,模型可以針對特定語言或任務進行進一步的訓練,以適應不同的應用場景。例如,在處理中文對話時,模型可以被微調以更好地理解中文的語境和表達習慣。
2. 跨語言交互能力
ChatGPT 的多語言支持還體現在其跨語言交互的能力上。這意味著用戶可以使用不同的語言與 ChatGPT 進行交流,而模型能夠理解并用相應的語言回應。這種能力極大地擴展了 ChatGPT 的應用范圍,使其能夠服務于全球各地的用戶。
2.1 語言檢測和翻譯
為了實現跨語言交互,ChatGPT 需要具備語言檢測和翻譯的能力。模型首先需要識別用戶輸入的語言,然后將其翻譯成模型能夠理解的語言。這一過程涉及到復雜的算法和大量的訓練數據,以確保翻譯的準確性和流暢性。
2.2 多輪對話和上下文理解
在跨語言交互中,ChatGPT 還需要處理多輪對話和上下文理解的問題。這意味著模型需要記住之前的對話內容,并在此基礎上生成合適的回應。這對于多語言支持尤為重要,因為不同的語言可能有不同的表達方式和文化背景,模型需要能夠靈活地適應這些差異。
3. 文化適應性和本地化
ChatGPT 的多語言支持還體現在其文化適應性和本地化上。這意味著模型不僅能夠理解不同語言的字面意思,還能夠理解其背后的文化含義和社會背景。這對于提供高質量的用戶體驗至關重要,尤其是在涉及敏感話題或文化差異較大的場景中。
3.1 語境和文化敏感性
ChatGPT 在處理多語言文本時,需要考慮到不同語言和文化中的語境和敏感性。例如,某些詞匯或表達在一種語言中可能是中性的,但在另一種語言中可能帶有負面含義。模型需要能夠識別這些差異,并在生成回應時避免可能的誤解或冒犯。
3.2 本地化和個性化
此外,ChatGPT 還需要支持本地化和個性化,以滿足不同地區和用戶群體的需求。這可能涉及到對特定地區的俚語、方言和表達習慣的適應,以及對用戶個人偏好和需求的考慮。通過這種方式,ChatGPT 能夠提供更加貼心和個性化的服務。
4. 多語言支持的挑戰和未來方向
盡管 ChatGPT 在多語言支持方面取得了顯著的進展,但仍然面臨著一些挑戰和未來的發展方向。
4.1 數據不平衡和資源限制
多語言支持的一個主要挑戰是數據不平衡和資源限制。不同語言的數據量和質量可能存在差異,這可能導致模型在某些語言上的表現不如其他語言。為了解決這個問題,需要收集和處理更多的多語言數據,以及開發更加公平和有效的訓練方法。
4.2 語言多樣性和方言處理
另一個挑戰是語言多樣性和方言的處理。世界上有許多語言和方言,它們之間可能存在顯著的差異。ChatGPT 需要能夠識別和處理這些差異,以提供更加準確和自然的交互體驗。
-
人工智能
+關注
關注
1807文章
49036瀏覽量
249795 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14169 -
ChatGPT
+關注
關注
29文章
1590瀏覽量
9130
發布評論請先 登錄
匠芯創發布新版GUI開發工具 新增多國語言設置等功能
中科曙光DeepAI深算智能引擎全面支持Qwen3
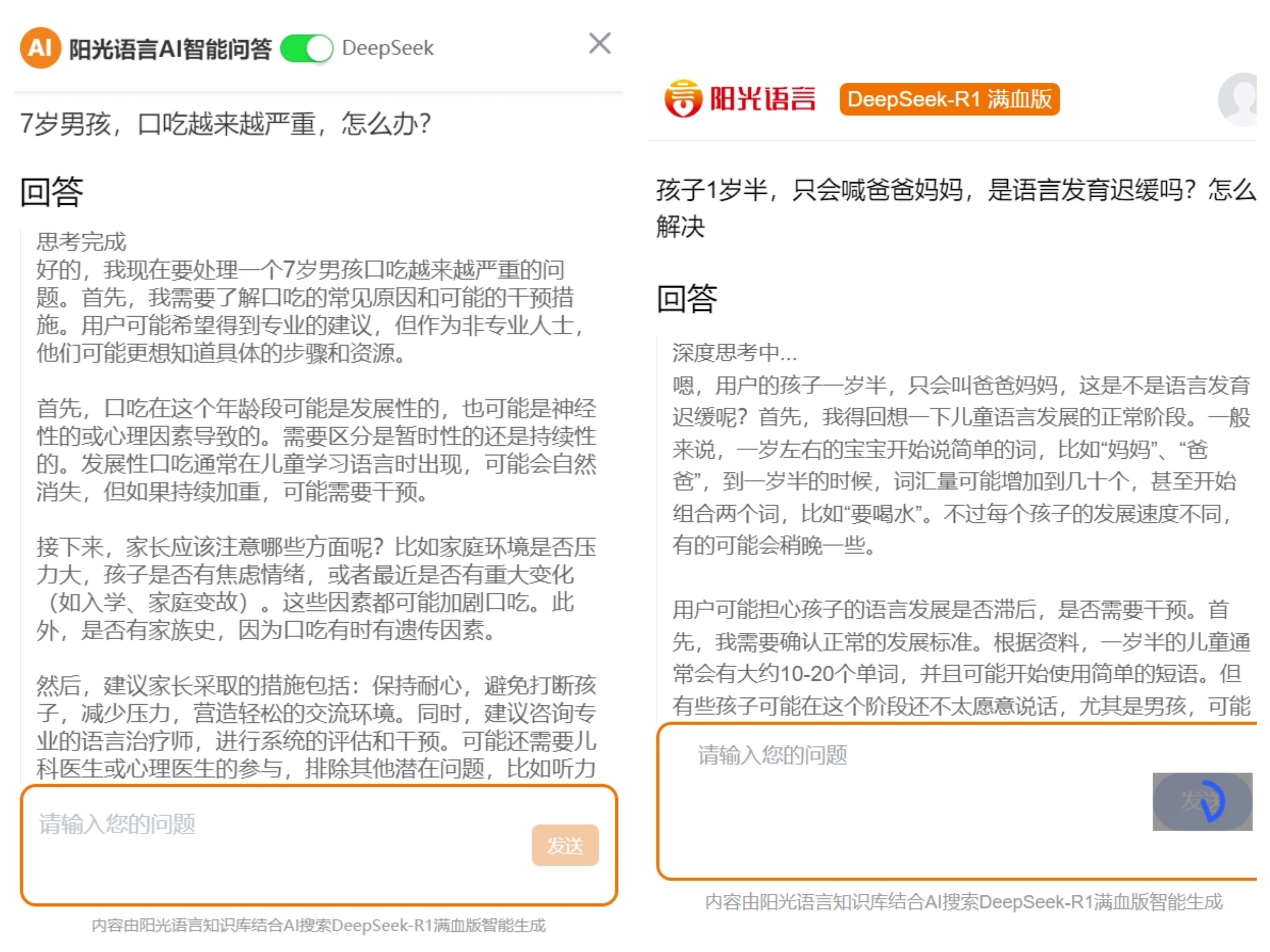
語言康復行業首家!陽光語言正式接入DeepSeek
離線語音識別芯片方案商:茶吧機語音控制模塊NRK3502

Meta與UNESCO合作推動多語言AI發展
微軟Copilot Voice升級,積極拓展多語言支持
Triton編譯器功能介紹 Triton編譯器使用教程
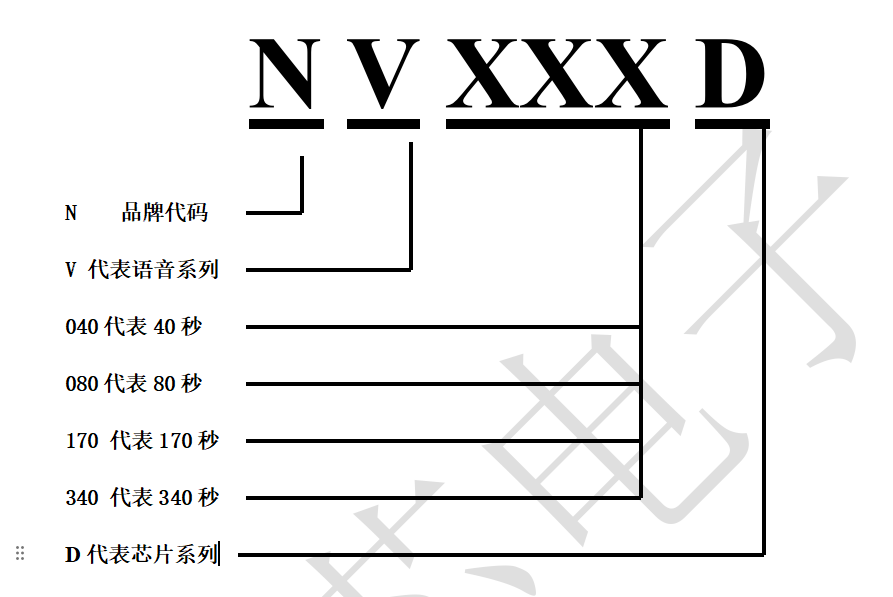
語音IC方案,在交通信號燈語音提示器的應用解析,NV040D
N9300-S16語音芯片:提升電梯播報體驗,實現導航聲音播報提示

Llama 3 語言模型應用
ChatGPT 適合哪些行業
科大訊飛發布訊飛星火4.0 Turbo大模型及星火多語言大模型
谷歌全新推出開放式視覺語言模型PaliGemma
Mistral AI與NVIDIA推出全新語言模型Mistral NeMo 12B
普羅格官網煥新,解鎖供應鏈數智化無限可能






 工商網監
工商網監

評論