 如何使用 Llama 3 進行文本生成
如何使用 Llama 3 進行文本生成
使用LLaMA 3(Large Language Model Family of AI Alignment)進行文本生成,可以通過以下幾種方式實現,取決于你是否愿意在本地運行模型或者使用現成的API服務。以下是主要的幾種方法:
方法一:使用現成的API服務
許多平臺提供了LLaMA 3的API接口,例如Hugging Face的Transformers庫和Inference API。
- 使用Hugging Face Transformers庫 :
- 首先,確保你已經安裝了
transformers庫和torch庫。bash復制代碼pip install transformers torch - 使用Hugging Face的pipeline進行文本生成。
python復制代碼from transformers import pipeline # 加載LLaMA 3模型(注意:實際LLaMA 3模型可能非常大,需要額外下載) generator = pipeline("text-generation", model="meta-research/llama3-7b") # 這里使用7B版本作為示例 # 生成文本 prompt = "Once upon a time, in a faraway kingdom," output = generator(prompt, max_length=50, num_return_sequences=1) for i, text in enumerate(output): print(f"{i+1}: {text['generated_text']}")
- 首先,確保你已經安裝了
- 使用Hugging Face Inference API :
- 注冊并獲取Hugging Face Spaces的API密鑰。
- 使用API進行請求。
python復制代碼import requests import json HEADERS = { "Authorization": f"Bearer YOUR_API_KEY", "Content-Type": "application/json", } DATA = { "inputs": "Once upon a time, in a faraway kingdom,", "parameters": { "max_length": 50, "num_return_sequences": 1, }, } response = requests.post( "https://api-inference.huggingface.co/models/meta-research/llama3-7b", headers=HEADERS, data=json.dumps(DATA), ) print(response.json())
方法二:在本地運行LLaMA 3
由于LLaMA 3模型非常大(從7B參數到65B參數不等),在本地運行需要強大的計算資源(如多個GPU或TPU)。
- 準備環境 :
- 確保你有一個強大的計算集群,并安裝了CUDA支持的PyTorch。
- 下載LLaMA 3的模型權重文件(通常從Hugging Face的模型庫中獲取)。
- 加載模型并生成文本 :
- 使用PyTorch加載模型并進行推理。
python復制代碼import torch from transformers import AutoTokenizer, AutoModelForCausalLM # 加載模型和分詞器 tokenizer = AutoTokenizer.from_pretrained("meta-research/llama3-7b") model = AutoModelForCausalLM.from_pretrained("meta-research/llama3-7b") # 準備輸入文本 prompt = "Once upon a time, in a faraway kingdom," inputs = tokenizer(prompt, return_tensors="pt") # 生成文本 outputs = model.generate(inputs.input_ids, max_length=50, num_return_sequences=1) # 打印生成的文本 print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 使用PyTorch加載模型并進行推理。
注意事項
- 計算資源 :LLaMA 3模型非常大,尤其是更高參數版本的模型,需要強大的計算資源。
- 模型加載時間 :加載模型可能需要幾分鐘到幾小時,具體取決于你的硬件。
- API限制 :如果使用API服務,請注意API的調用限制和費用。
通過上述方法,你可以使用LLaMA 3進行文本生成。選擇哪種方法取決于你的具體需求和計算資源。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
API接口
+關注
關注
1文章
85瀏覽量
10697
發布評論請先 登錄
相關推薦
如何構建文本生成器?如何實現馬爾可夫鏈以實現更快的預測模型
準確的,內存少(只存儲1個以前的狀態)并且執行速度快。文本生成的實現這里將通過6個步驟完成文本生成器:1、生成查找表:創建表來記錄詞頻2、將頻率轉換為概率:將我們的發現轉換為可用的形式3
發表于 11-22 15:06
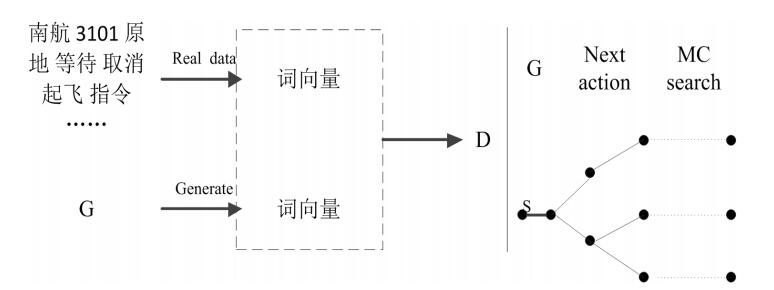
基于生成對抗網絡GAN模型的陸空通話文本生成系統設計
可以及時發現飛行員錯誤的復誦內容。考慮到訓練一個有效的差錯校驗網絡模型需要大量的文本數據,本文提出一種基于生成對抗網絡GAN的陸空通話文本生成方法。首先對現有真實的陸空通話文本
發表于 03-26 09:22
?34次下載
基于生成器的圖像分類對抗樣本生成模型
,并保證攻擊成功率。模型將對抗樣本生成的過程視為對原圖進行圖像増強的操作引入生成對抗網絡,并改進感知損失函數以增加對抗樣本與原圖在內容與特征空間上的相似性,采用多分類器損失函數優化訓練從而提高攻擊效率。實
發表于 04-07 14:56
?2次下載

基于生成式對抗網絡的深度文本生成模型
評論,對音樂作品自動生成評論可以在一定程度上解決此問題。在在線唱歌平臺上的評論文本與音樂作品的表現評級存在一定的關系。因此,研究考慮音樂作品評級信息的評論文本自動生成的方為此提出了一種
發表于 04-12 13:47
?15次下載

文本生成任務中引入編輯方法的文本生成
4. FELIX FELIX是Google Research在“FELIX: Flexible Text Editing Through Tagging and Insertion”一文中提出的文本生成

受控文本生成模型的一般架構及故事生成任務等方面的具體應用
來自:哈工大訊飛聯合實驗室 本期導讀:本文是對受控文本生成任務的一個簡單的介紹。首先,本文介紹了受控文本生成模型的一般架構,點明了受控文本生成模型的特點。然后,本文介紹了受控文本生成技
基于GPT-2進行文本生成
文本生成是自然語言處理中一個重要的研究領域,具有廣闊的應用前景。國內外已經有諸如Automated Insights、Narrative Science以及“小南”機器人和“小明”機器人等文本生成
深度學習——如何用LSTM進行文本分類
簡介 主要內容包括 如何將文本處理為Tensorflow LSTM的輸入 如何定義LSTM 用訓練好的LSTM進行文本分類 代碼 導入相關庫 #coding=utf-8 import
基于VQVAE的長文本生成 利用離散code來建模文本篇章結構的方法
寫在前面 近年來,多個大規模預訓練語言模型 GPT、BART、T5 等被提出,這些預訓練模型在自動文摘等多個文本生成任務上顯著優于非預訓練語言模型。但對于開放式生成任務,如故事生成、新聞生成
通俗理解文本生成的常用解碼策略
“Autoregressive”語言模型的含義是:當生成文本時,它不是一下子同時生成一段文字(模型吐出來好幾個字),而是一個字一個字的去生成。"Autoregressive"
Meta提出Make-A-Video3D:一行文本,生成3D動態場景!
具體而言,該方法運用 4D 動態神經輻射場(NeRF),通過查詢基于文本到視頻(T2V)擴散的模型,優化場景外觀、密度和運動的一致性。任意機位或角度都可以觀看到提供的文本生成的動態視頻輸出,并可以
ETH提出RecurrentGPT實現交互式超長文本生成
RecurrentGPT 則另辟蹊徑,是利用大語言模型進行交互式長文本生成的首個成功實踐。它利用 ChatGPT 等大語言模型理解自然語言指令的能力,通過自然語言模擬了循環神經網絡(RNNs)的循環計算機制。

面向結構化數據的文本生成技術研究
今天我們要講的文本生成是現在最流行的研究領域之一。文本生成的目標是讓計算機像人類一樣學會表達,目前看基本上接近實現。這些突然的技術涌現,使得計算機能夠撰寫出高質量的自然文本,滿足特定的需求。

Meta發布一款可以使用文本提示生成代碼的大型語言模型Code Llama
今天,Meta發布了Code Llama,一款可以使用文本提示生成代碼的大型語言模型(LLM)。

Meta Llama 3基礎模型現已在亞馬遜云科技正式可用
亞馬遜云科技近日宣布,Meta公司最新發布的兩款Llama 3基礎模型——Llama 3 8B和Llama





 工商網監
工商網監

評論