 深度解析LSTM的全貌
深度解析LSTM的全貌
第一次接觸長短期記憶神經網絡(LSTM)時,我驚呆了。
原來,LSTM是神經網絡的擴展,非常簡單。深度學習在過去的幾年里取得了許多驚人的成果,均與LSTM息息相關。因此,在本篇文章中我會用盡可能直觀的方式為大家介紹LSTM——方便大家日后自己進行相關的探索。
首先,請看下圖:
LSTM是不是很漂亮?
注意:如果你對神經網絡和LSTM很熟悉,請直接跳到本文的中間部分——前半部分相當于入門教程。
神經網絡
假設我們從某部電影中截取出了一系列的圖像,并且我們想對每張圖像進行標記,使其成為某個事件(是打斗嗎?演員們在說話嗎?演員們在吃東西嗎?)
我們該怎么做?
其中一種方法就是,在忽視圖像連續屬性的情況下構建一個單獨處理各個圖像的單圖像分類器。例如,提供足夠多的圖像和標簽:
在數據變多的情況下,算法可能會學習將這些圖形與更為復雜的形式結合在一起,如人臉(一個橢圓形的東西的上方是一個三角形,三角形上有兩個圓形)或貓。
如果數據量進一步增多的話,算法可能會學習將這些高級圖樣映射至活動本身(包含嘴、肉排和餐叉的場景可能就是在用餐)
這就是一個深度神經網絡:輸入一張圖像而后輸出相應的事件——這與我們在對犬類一無所知的情況下仍可能會通過幼犬行為學習檢測其各種特征是一樣的(在觀察了足夠多的柯基犬后,我們發現它們有一些共同特征,如蓬松的臀部和短小的四肢等;接下來,我們繼續學習更加高級的特性,如排泄行為等)——在這兩個步驟之間,算法通過隱含圖層的向量表示來學習描述圖像。
數學表達
雖然大家可能對基本的神經網絡已經非常熟悉,但是此處我們仍快速地回顧一下:
單隱含層的神經網絡將向量x作為輸入,我們可以將其視作為一組神經元。
算法通過一組學習后的權重將每個輸入神經元連接至神經元的一個隱含層。
第j個隱層神經元輸出為 ,其中??是激活函數。
,其中??是激活函數。
隱含層與輸出層完全連接在一起,第j個輸出神經元輸出為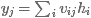 ,如果需要知道其概率的話,我們可以借助softmax函數對輸出層進行轉換。
,如果需要知道其概率的話,我們可以借助softmax函數對輸出層進行轉換。
用矩陣符號表示為:
h=?(Wx)h=?(Wx)
y=Vhy=Vh
其中
matchx 是輸入向量
W是連接輸入層和隱含層的權重矩陣
V是連接隱含層和輸出層的權重矩陣
? 的激活函數通常為雙彎曲函數(sigmoid function) σ(x) ,它將數字縮小到 (0, 1)區間內;雙曲線函數(hyperbolic tangent)tanh(x),它將數字縮小至(-1, 1)區間內,修正線性單位 ReLU(x)=max(0,x)。
下圖為圖形視圖:
注意:為了使符號更加簡潔些,我假設x和h各包含一個額外的偏差神經元,偏差設置為1固定不變,方便學習偏差權重。
利用RNN記憶信息
忽視電影圖像的連續屬性像是ML 101的做法。如果我們看到一個沙灘的場景,我們應該在接下來的幀數中增強沙灘活動:如果圖像中的人在海水中,那么這個圖像可能會被標記為“游泳”;如果圖像中的人閉著眼睛躺在沙灘上,那么這個圖像可能會被標記為“日光浴”。如果如果我們能夠記得Bob剛剛抵達一家超市的話,那么即使沒有任何特別的超市特征,Bob手拿一塊培根的圖像都可能會被標記為“購物”而不是“烹飪”。
因此,我們希望讓我們的模型能夠跟蹤世界上的各種狀態:
在檢測完每個圖像后,模型會輸出一個標簽,同時模型對世界的認識也會有所更新。例如,模型可能會學習自主地去發現并跟蹤相關的信息,如位置信息(場景發生的地點是在家中還是在沙灘上?)、時間(如果場景中包含月亮的圖像,模型應該記住該場景發生在晚上)和電影進度(這個圖像是第一幀還是第100幀?)。重要的是,正如神經元在未收到隱含圖像(如棱邊、圖形和臉等)的情況下可以自動地去發現這些圖像,我們的模型本身可以自動發現有用的信息。
在向模型輸入新的圖像時,模型應該結合它收集到的信息,更加出色地完成任務。
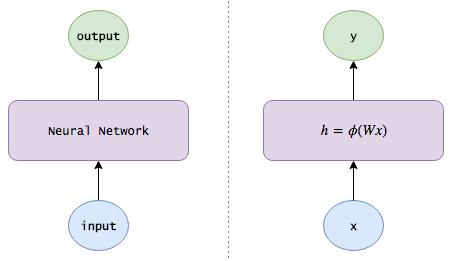
這就是遞歸神經網絡(RNN),它不僅能夠完成簡單地圖像輸入和事件輸出行為,還能保持對世界的記憶(給不同信息分配的權重),以幫助改進自己的分類功能。
數學表達
接下來,讓我們把內部知識的概念添加到方程式中,我們可以將其視為神經網絡長久以來保存下的記憶或者信息。
非常簡單:我們知道神經網絡的隱含層已經對關于輸入的有用信息進行了編碼,因此,為什么不把這些隱含層作為記憶來使用呢?這一想法使我們得到了下面的RNN方程式:
ht=?(Wxt+Uht?1)
yt=Vht
注意:在時間t處計算得出的隱狀態(ht為我們的內部知識)在下個時間步長內會被反饋給神經網絡。(另外,我會在本文中交替使用隱狀態、知識、記憶和認識等概念來描述ht)
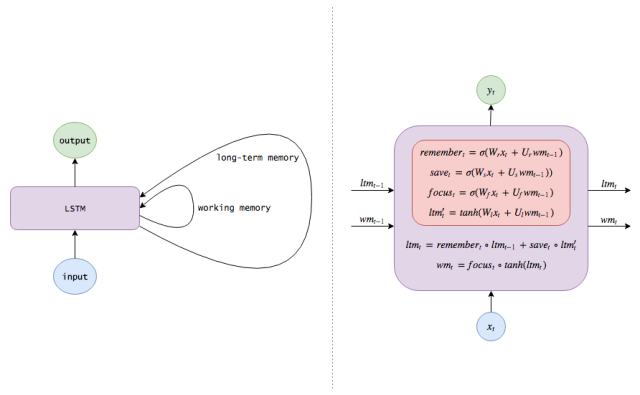
利用LSTM實現更長久的記憶
讓我們思考一下我們的模型是如何更新它對世界的認識的。到目前為止,我們并未對其更新過程施加任何限制措施,因此該認識更新過程可能十分混亂:在某一幀,模型可能會認為其中的人物是在美國;到了下一幀,當它觀察到人物在吃壽司時,便會認為這些人在日本;而在下一幀,當它觀察到北極熊時,便認為他們是在伊德拉島 ( Hydra island )。也有可能,模型收集到的大量信息表明Alice是一名投資分析師,但是在看到她進行烹飪時又斷定她是一名職業殺手。
這種混亂意味著信息會快速地改變并消失,模型很難保存長期記憶。因此,我們希望神經網絡能學會如何更新自己的認識(也就是說,沒有Bob的場景不應該改變所有與Bob相關的信息,有Alice的場景就應該專注于收集關于她的信息),這樣神經網絡就可以相對緩慢地更新它對世界的認識。
以下是我們的實現方法。
添加遺忘機制。例如,如果某個場景結束了,模型就應該忘記當前場景的位置和時間,并且重置任何與該場景有關的信息;但是,如果某個人物在該場景中死亡了,那么模型應該繼續記住該人物死亡的事實。因此,我們想要模型學習獨立的的遺忘/記憶機制:當收到新的輸入時,模型需要知道哪些認識應該保留以及哪些認識應該遺棄。
添加保存機制。當模型看到新的圖像時,它需要學習關于該圖像的所有信息是否值得使用以及是否值得保存。也許你媽曾給你發過一篇關于卡戴珊一家的文章,但是誰在乎呢?
因此當收到新的輸入信息時,模型首先忘記所有它認為自己不再需要的長期信息。然后,再學習新輸入信息的哪部分具有使用價值,并且將它們保存到長期記憶中。
將長期記憶聚焦為工作記憶。最后,模型需要學習哪一部分的長期記憶能立刻發揮作用。例如,Bob的年齡可能是一條有用的信息,需要保存在長期記憶中(兒童更可能會爬行,而成人則更可能會工作),但是如果Bob并未出現在當前場景中,那么這條信息就可能是不相干的信息。因此,模型并不是始終都在使用全部的長期記憶的,它只需要學習應該集中注意力于哪部分記憶。
這就是長短期記憶網絡。RNN在各個時間步中改寫記憶的方式可以說是相當無序的,而LSTM改寫自己記憶的方式是更加精確的:通過使用特定的學習機制來判斷哪些信息需要記憶、哪些信息需要更新以及哪些信息需要特別注意。這有助于LSTM對信息進行長期跟蹤。
數學表達
讓我們用數學表達式來描述LSTM的添加機制。
在時間t時,我們收到一個新的輸入xt。我們還將長期記憶和工作記憶從前兩個時間步ltmt?1和wmt?1(兩者都為n-長度向量)傳遞到當前時間步,進行更新。
我們先處理長期記憶。首先,我們需要知道哪些長期記憶需要繼續記憶,并且需要知道哪些長期記憶需要舍棄。因此,我們使用新的輸入和工作記憶來學習0和1之間n個數字的記憶門,各個記憶門決定某長期記憶元素需要保留的程度。(1表示保存,0表示完全遺忘)。
我們可以使用一個小型神經網絡來學習這個時間門:
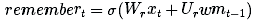
(請注意它與先前網絡方程式相似的地方;這只是一個淺層神經網絡。另外,我們之所以使用S形激活函數是因為我們所需要的數字介于0至1之間。)
接下來,我們需要計算可以從xt中學習的信息,也就是長期記憶的候選添加記憶:
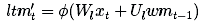
?是一個激活函數,通常被選作為tanh。在將候選記憶添加到長期記憶中之前,我們想要學習候選記憶的哪部分值得使用和保存:

(想象一下你在閱讀網頁時發生的事情。當新的新聞可能包含關于希拉里的信息時,如果該信息來自布萊巴特(Breitbart)網站,那么你就應該忽視它。)
現在讓我們把所有這些步驟結合起來。在忘記我們認為不再需要的記憶并保存輸入信息的有用部分后,我們就會得到更新后的長期記憶:
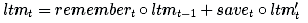
其中°表示以元素為單元 (Element-wise)的乘法。
接下來,讓我們更新一下工作記憶。我們想要學習如何將我們的長期記憶聚焦到能立刻發揮作用的信息上。(換句話說,我們想要學習需要將哪些數據從外接硬盤中轉移到用于工作的筆記本上)。因此,此處我們來學習一下關注/注意向量(focus/attention vector):

我們的工作記憶為:
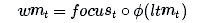
換言之,我們注意關注向量為1的元素,忽視關注向量為0的元素。
我們完成了!希望你也將這些步驟記到了你的的長期記憶中。
總結來說,普通的RNN只利用一個方程式來更新它的隱狀態/記憶:
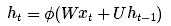
而 LSTM 則會利用數個方程式:
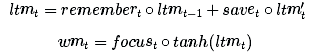
其中的每個記憶/注意子機制只是它自己的一個迷你大腦:
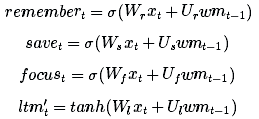
(注意:我使用的術語和變量名稱與常規文章中的用法不同。以下是標準名稱,我從此處起將會交替使用這些名稱:
長期記憶ltmt通常被稱為cell狀態,表示為ct。
工作記憶wmt通常被稱為隱狀態,表示為ht。它與普通RNN中的隱狀態類似
記憶向量remembert通常被稱為記憶門(盡管記憶門中的1仍表示保留記憶,0仍表示忘記),表示為ft。
保存向量savet通常被稱為輸入門(因為它決定輸入信息中需要保存到cell狀態中的程度),表示為it。
關注向量focust通常被稱為輸出門,表示為ot。)
Snorlax
寫這篇文章的時間我本來可以捉到一百只Pidgey的!下面Pidgey的卡通圖像。
神經網絡

遞歸神經網絡
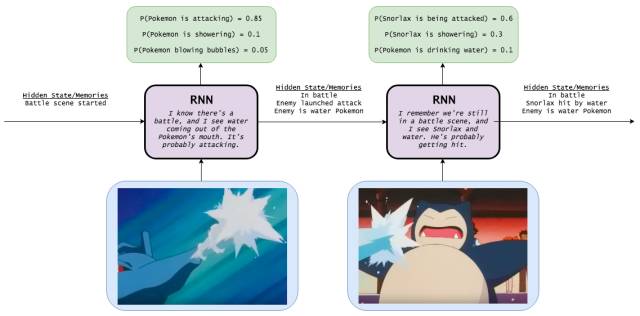
長短期記憶網絡
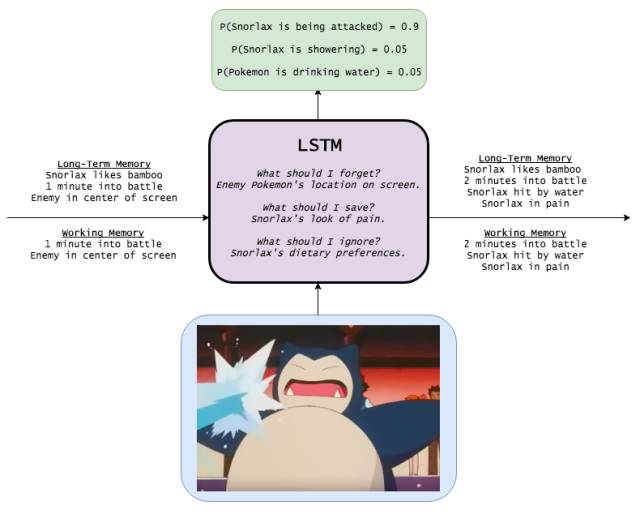
學習如何編碼
讓我們看幾個LSTM發揮作用的例子。效仿Andrej Karpathy的文章,我將使用字符級別的LSTM模型,我給模型輸入字符序列并對其進行訓練,使它能夠預測序列中的下個字符。
盡管這種方法似乎有點幼稚,但是字符級別的模型其實真的十分有用,甚至超越文字模型。例如:
想象一個可以使你在手機上進行編碼的自動填充編碼插件(code autocompleter)。LSTM(理論上)可以跟蹤你當前使用的方法的返回類型,并能對應當返回的變量做出更好的建議;它還能在不進行編譯的情況下通過返回錯誤類型得知你是否犯有錯誤。
自然語言處理應用(如機器翻譯)在處理罕見術語時通常會有困難。該如何翻譯一個你以前從未見過的單詞?或者如何將形容詞轉換為副詞呢?即使你知道某篇推文的意思,你該如何生成一個新的話題標簽以方便其他人捕捉相關的信息呢?字符模型可以憑空想象出新的術語,這是另一個可以實現有趣應用的領域。
首先我啟動了一個EC2 p2.xlarge競價實例(spot instance),在Apache Commons Lang codebase上訓練了一個3層LSTM。這是該LSTM在數小時后生成的一個程序。
盡管該編碼肯定不算完美,但是也比許多我認識的數據科學家編得好。我們可以看出,LSTM學到了很多有趣(并且正確!)的編碼行為:
它知道如何構造類別:先是證書,然后是程序包和輸入,再是評論和類別定義,最后是變量和方法。同樣,它懂得如何創造方法:正確指令后跟裝飾符(先是描述,然后是@param,再是@return等),正確放置裝飾符,返回值非空的方法以合適的返回語句結尾。至關重要的是,這種行為貫穿長串長串的代碼!
它還能跟蹤子程序和嵌套層數:語句的縮進始終正確,并且Loop循環結構始終關閉。
它甚至知道如何生成測試。
模型是如何做到的呢?讓我們觀察幾個隱狀態。
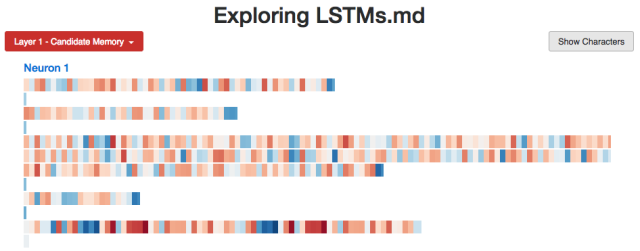
這是一個似乎是用來跟蹤代碼縮進外層的神經元(當模型讀取字符作為輸入時,代碼的狀態會決定字符的顏色,也就是當模型試圖生成下個字符時;紅色cell為否定,藍色cell為肯定):
這是一個倒數tab間空格數的神經元:
這是一個與眾不同的3層LSTM,在TensorFlow的代碼庫中訓練得出,供您試玩:
鏈接:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
如果想查看更多的實例,你可以在網絡上找到許多其他有趣的實例。
探究LSTM內部結構
讓我們研究得更深一些。我們在上一節中探討了幾個隱狀態的實例,但是我還想使用LSTM的cell狀態以及其他記憶機制。它們會如我們預期的那樣被激活嗎?或者說,是否存在令人意想不到的模式呢?
計數
為了進行研究,讓我們先教LSTM進行計數。(記住Java和Python語言下的LSTM是如何生成正確的縮進的!)因此,我生成了這種形式的序列

(N個"a"后跟著一個分隔符X,X后跟著N個"b"字符,其中1 <= N <= 10),并且訓練了一個帶有10個隱層神經元的單層LSTM。
不出所料,LSTM在它的訓練范圍內學習得非常好——它甚至在超出范圍后還能類推幾步。(但是當我們試著使它數到19時,它便開始出現錯誤。)

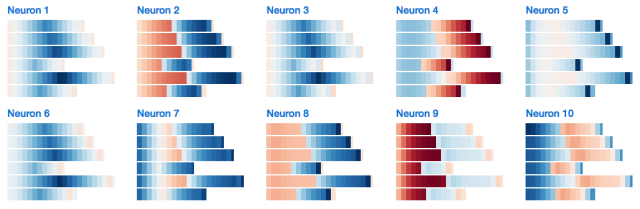
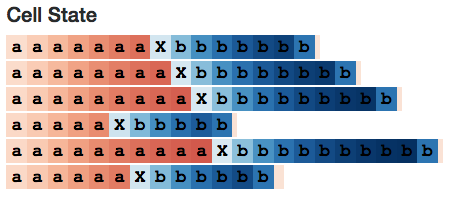
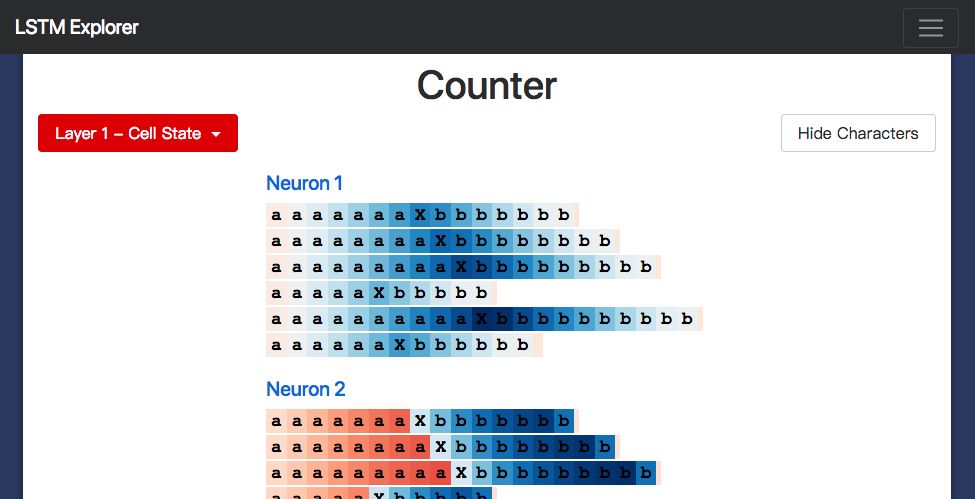
研究模型的內部,我們期望找到一個能夠計算a's數量的隱層神經元。我們也確實找到了一個:

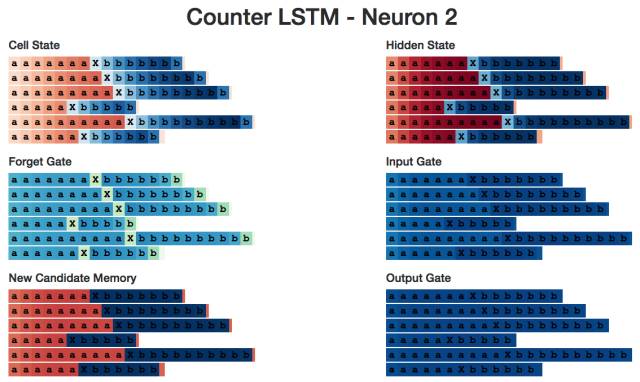
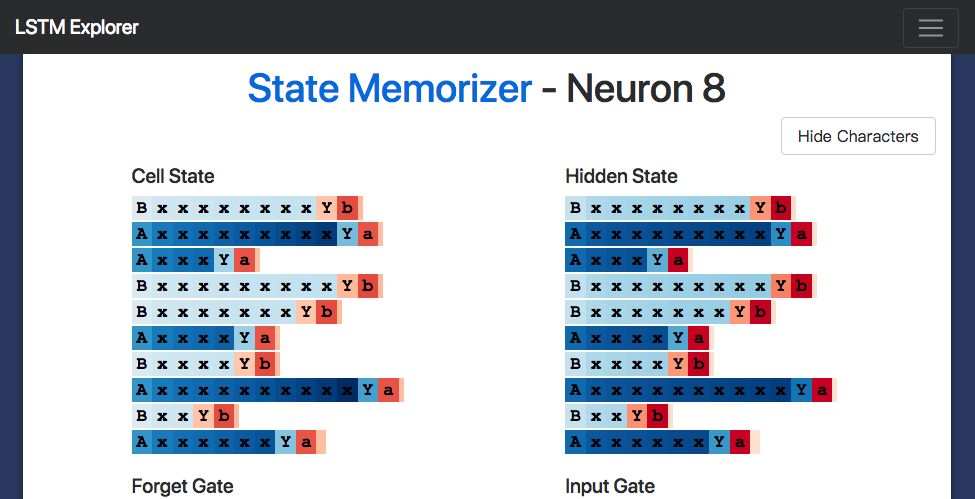
Neuron #2隱藏狀態
我用LSTM開發了一個小的網頁應用(http://blog.echen.me/lstm-explorer),Neuron #2計數的似乎是它所能看到的a's和b's的總數。(記住根據神經元的激活狀態對Cell進行上色,顏色在暗紅色 [-1] 到暗藍色 [+1]之間變化。)
Cell狀態呢?它的表現類似:
Neuron #2Cell狀態
有趣的是,工作記憶看起來像是“更加清晰”的長期記憶。是不是整體都存在這種現象呢?
確實存在。(這和我們的預期完全相同,因為tanh激活函數壓縮了長期記憶,同時輸出門會對記憶做出限制。)例如,以下是對所有10個cell狀態節點的快速概覽。我們看到許多淺色的cell,它們代表的是接近于0的數值。
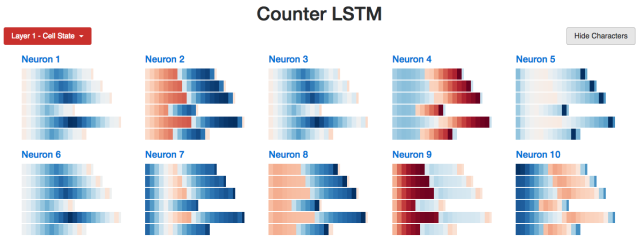
LSTM Cell狀態的統計
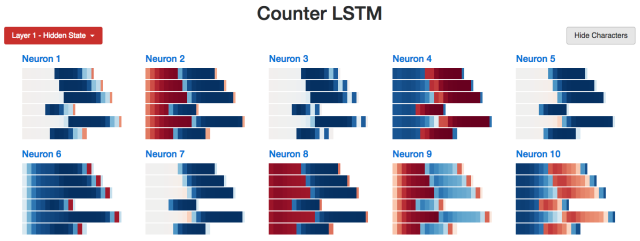
相比之下,10個工作記憶神經元的表現非常集中。神經元1、3、5、7在序列的前半部分甚至完全處于0的狀態。
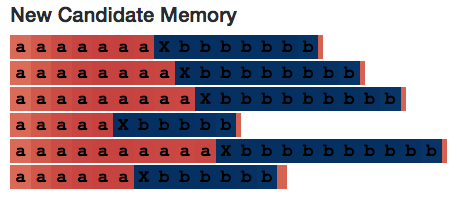
讓我們再看看神經元#2。圖片中是候選記憶和輸出門,它們在各半個序列中都相對較為穩定——似乎神經元每一步計算的都是a += 1或者b += 1。

輸入門
最后,這是對所有神經元2的內部的概覽。
如果你想要研究不同的計數神經元,你可以使用這里提供的觀察器(visualizer)。
鏈接:http://blog.echen.me/lstm-explorer/#/network?file=counter
注意:這絕不是LSTM學習計數的唯一方法,我在本文中使用了相當多的擬人手法。在我看來,觀察神經網絡的行為非常有趣,也有助于構建出更好的模型——畢竟神經網絡中的許多想法都是對人類大腦的模擬,如果能觀察到我們未預料到的行為,也許可以設計出更加有效的學習機制。
Count von Count
讓我們看一個稍微復雜些的計數器。這次我生成了這種形式的序列:

(N個a's 中隨機夾雜幾個X's,然后加一個分隔符Y,Y后再跟N個b's)。LSTM仍需計算a's的數量,但是這次它需要忽視X's。
這是完整的LSTM(http://blog.echen.me/lstm-explorer/#/network?file=selective_counter)。我們預期看到一個計數神經元,但是當神經元觀測到X時,輸入門為零。的確是這樣!

上圖為Neuron 20的cell狀態。該狀態在讀到分隔符Y之前一直在增加,之后便一直減少至序列結尾——就如計算num_bs_left_to_print變量一樣,該變量在讀到a's時增加,讀到b's時減小)。
如果觀察它的輸入門,它的確在忽視X's :

有趣的是,候選記憶在讀到不相關的X's時完全激活——這表明了設置輸入門的必要性。(但是,如果該輸入門不是模型結構的一部分,那么該神經網絡則很可能會通過其他方法學會如何忽視X's,至少在當下簡單的實例中是這樣的。)
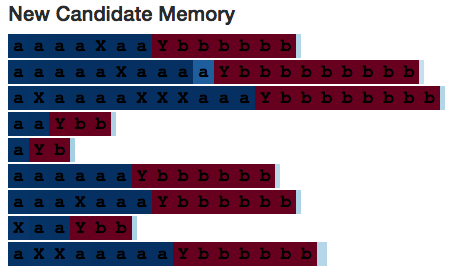
讓我們再看看Neuron 10。

這個神經元很有趣,因為它只有在讀取到分隔符"Y"時才會激活——但它仍能成功編碼出序列中a's的數量。(也許從圖片中很難看出來,但是當讀取到序列中的Y's和a's數量相同時,所有cell狀態的值要么完全相同,要么彼此間的誤差不超過0.1%。你可以看到,a's較少的Y's比其他a's較多的Y's顏色更淺。)也許某些其他神經元看到神經元10偷懶便幫了它一下。

記住狀態
接下來,我想看看LSTM是如何記住狀態的。我生成了這種形式的序列:
(即一個"A" or "B",緊跟1-10個x's,再跟一個分隔符"Y",結尾是開頭字符的小寫形式)。在這種情況下,神經網絡需要記住它是處于"A" 狀態還是 "B"狀態中。我們期望找到一個在記憶以"A"開頭的序列時激活的神經元,以及一個在記憶以"B"開頭的序列時激活的神經元。我們的確找到了。
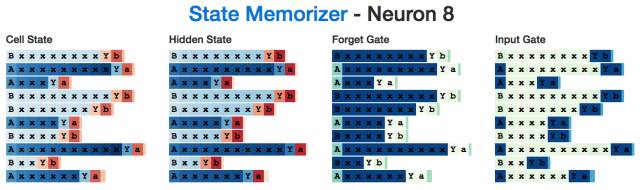
例如,下面是一個在讀到"A"時會激活的"A"神經元,它在生成最后的字符之前會一直進行記憶。注意:輸入門會忽視所有的"x"字符。
這是一個"B"神經元:
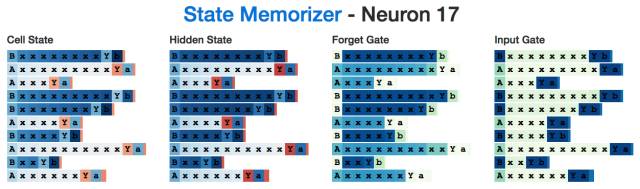
有趣的是,盡管在神經網絡讀到分隔符"Y" 之前,我們并不需要了解A狀態與B狀態的情況,但是隱狀態在讀取所有中間輸入的整個過程中都處于激活狀態。這似乎有些“效率低下”,或許是因為神經元在計算x's的數量時還在完成一些其他的任務。
復制任務
最后,讓我們探究一下LSTM是如何學習復制信息的。(Java LSTM能夠記憶和復制Apache許可證。)
注意:思考一下LSTM的工作方式你就會知道,LSTM并不十分擅長記憶大量單獨且詳細的信息。例如,你可能注意到由LSTM生成的代碼有個大缺陷,那就是它常常會使用未定義的變量——LSTM無法記住哪些變量已經被定義過并不令人感到驚訝,因為很難使用單一的cell來有效地編碼多值信息,如特征等。同時,LSTM并沒有可以用來串連相鄰記憶形成相關話語的自然機制。記憶網絡和神經圖靈機(neural Turing machines)是神經網絡的兩個擴展,它們可以借助外部記憶控件來增強記憶能力,從而幫助修復這個問題。因此,雖然LSTM并不能十分高效地進行復制,但是觀察它們進行各種嘗試也非常有趣。
為了完成復制任務,我在如下形式的序列上訓練了一個小的2層LSTM。

(即先是一個由a's、b's和 c's組成的3字符序列,中間插一個分隔符"X",后半部分則組前半部分的序列相同)。
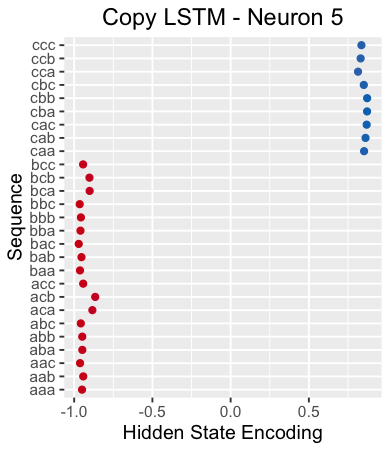
我不確定“復制神經元”長什么樣,因此為了找到記憶初始序列部分元素的神經元,我在神經網絡讀取分隔符X時觀察了它們的隱狀態。由于神經網絡需要對初始序列進行編碼,它的狀態應當根據學習的內容呈現出不同的模式。
例如,下圖繪制了神經網絡讀取分隔符"X"時神經元5的隱狀態。該神經元顯然能夠從不同序列中區分出以"c"開頭的序列。
再舉一個例子,下圖是神經網絡讀取分隔符"X"時神經元20的隱狀態。該神經元似乎能挑選出以"b"開頭的序列。
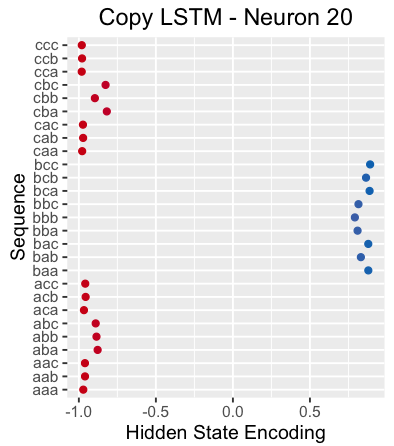
有趣的是,如果我們觀察神經元20的cell狀態,可以看出它幾乎獨自捕捉了整個3字符序列(由于神經元是一維的,這并不簡單!):

這是神經元20在整個序列中的cell狀態和隱狀態。注意:它的隱狀態在整個初始序列中都是關閉的(這也許是預料之中的事,因為只需要在某一點上被動地保留該神經元的記憶即可)。

但是,如果我們觀察得更仔細一些就會發現:下一字符只要是"b",該神經元就會激活。因此該神經元并不是以"b"開頭的"b"神經元,而是下一個字符是"b"的神經元。
在我看來,這個模式適用于整個神經網絡——所有神經元似乎都在預測下一字符,而不是在記憶特定位置上的字符。例如,神經元5似乎就是“預測下一字符是‘c’”的神經元。
我不確定這是不是LSTM在復制信息時學習的默認行為,也不確定是否存在其他復制機制。
狀態和門
為了真正深入探討和理解LSTM中不同狀態和門的用途,讓我們重復之前
狀態和隱藏狀態(記憶)cell.
我們原本將cell狀態描述為長期記憶,將隱藏狀態描述為在需要時取出并聚焦這些記憶的方法。
因此,當某段記憶當前不相干時,我們猜想隱藏狀態會關閉——這正是這個序列復制神經元采取的行為。
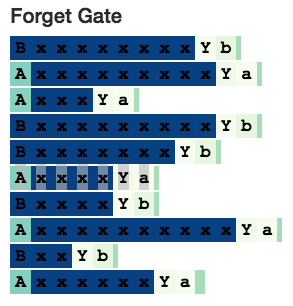
遺忘門
遺忘門舍棄cell狀態的信息(0代表完全遺忘,1代表完全記住),因此我們猜想:遺忘門在需要準確記憶什么時會完全激活,而當不再需要已記住的信息時則會關閉。
我們認為這個"A"記憶神經元用的是同樣的原理:當該神經元在讀取x's時,記憶門完全激活,以記住這是一個"A"狀態,當它準備生成最后一個"a"時,記憶門關閉。
輸入門(保存門)
我們將輸入門(我原理稱其為“保存門“)的作用描述為決定是否保存來自某一新輸入的信息。因此,在識別到無用的信息時,它會自動關閉。
這就是這個選擇計數神經元的作用:它計算a's和b's的數量,但是忽略不相關的x's。
令人驚奇的是我們并未在LSTM方程式中明確規定輸入(保存)、遺忘(記憶)和輸出(注意)門的工作方式。神經網絡自己學會了最好的工作方式。
擴展閱讀
讓我們重新概括一下如何獨自認識LSTM。
首先,我們要解決的許多問題在某種程度上都是連續的或暫時的,因此我們應該將過去學到的知識整合到我們的模型中。但是我們知道,神經網絡的隱層能編碼有用的信息。因此,為什么不將這些隱層用作為記憶,從某一時間步傳遞到下一時間步呢?于是我們便得到RNN。
從自己的行為中我們可以知道,我們不能隨心所欲地跟蹤信息;但當我們閱讀關于政策的新文章時,我們并不會立即相信它寫內容并將其納入我們對世界的認識中。我們會有選擇地決定哪些信息需要進行保存、哪些信息需要舍棄以及下次閱讀該新聞時需要使用哪些信息來作出決策。因此,我們想要學習如何收集、更新和使用信息——為什么不借助它們自己的迷你神經網絡來學習這些東西呢?這樣我們就得到了LSTM。
現在,我們已經瀏覽了整個的過程,可以自己進行模型的調整了。
例如,你可能認為用LSTM區分長期記憶和短期記憶很沒意義——為什么不直接構建一個LSTM?或者,你也有可能發現,分離的記憶門和保存門有點冗余——任何被遺忘的信息都應該由新的信息替換,反之亦然。這樣一來便可提出另一個很受歡迎的LSTM變量——GRU。
又或者,也許你認為在決定需要記憶、保存和注意哪些信息時我們不應該只依賴于工作記憶——為什么不使用長期記憶呢?這樣一來,你就會發現Peephole LSTMs。
復興神經網絡
最后讓我們再看一個實例,這個實例是用特朗普總統的推文訓練出的2層LSTM。盡管這個數據集很小,但是足以學習很多模式。例如,下面是一個在話題標簽、URL和@mentions中跟蹤推文位置的神經元:
以下是一個正確的名詞檢測器(注意:它不只是在遇到大寫單詞時激活):
這是一個“輔助動詞+ ‘to be’”的檢測器(包括“will be”、“I've always been”、“has never been”等關鍵詞)。
這是一個引用判定器:
甚至還有一個MSGA和大寫神經元:
這是LSTM生成的相關聲明(好吧,其中只有一篇是真的推文;猜猜看哪篇是真的推文吧!):
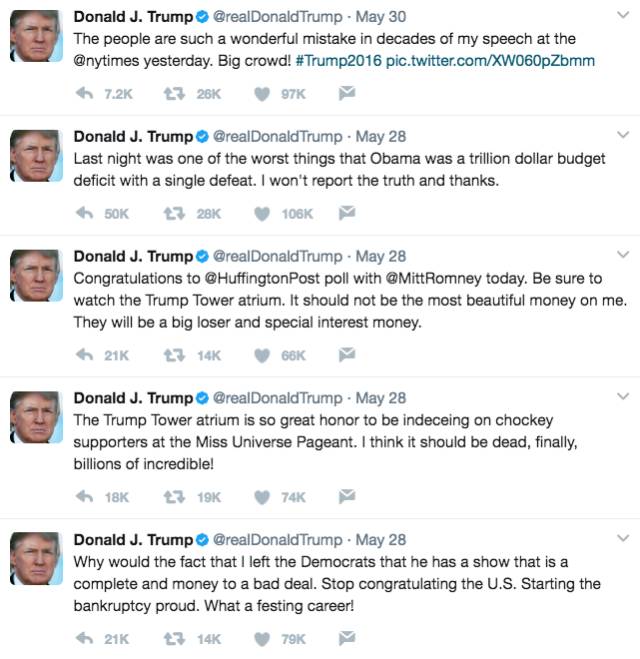

不幸的是,LSTM只學會了如何像瘋子一樣瘋言瘋語。
總結
總結一下,這就是你學到的內容:
這是你應該儲存在記憶中的內容:
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:詳解LSTM:神經網絡的記憶機制是這樣煉成的
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Zstack中串口操作的深度解析(一)
java經典面試題深度解析
功能安全---AUTOSAR架構深度解析 精選資料分享
AUTOSAR架構深度解析 精選資料分享
基于LSTM和CNN融合的深度神經網絡個人信用評分方法

基于深度LSTM和注意力機制的金融數據預測方法






 工商網監
工商網監
評論