
") FPGA和ASIC在大模型推理加速中的應(yīng)用
FPGA和ASIC在大模型推理加速中的應(yīng)用
今天我們?cè)賮砜匆黄撐摹?/p>
隨著現(xiàn)在AI的快速發(fā)展,使用FPGA和ASIC進(jìn)行推理加速的研究也越來越多,從目前的市場(chǎng)來說,有些公司已經(jīng)有了專門做推理的ASIC,像Groq的LPU,專門針對(duì)大語言模型的推理做了優(yōu)化,因此相比GPU這種通過計(jì)算平臺(tái),功耗更低、延遲更小,但應(yīng)用場(chǎng)景比較單一,在圖像/視頻方向就沒有優(yōu)勢(shì)了。
整個(gè)AI的工業(yè)界,使用FPGA的目前還比較少,但學(xué)術(shù)界其實(shí)一直在用FPGA做很多的嘗試,比如通過簡(jiǎn)化矩陣運(yùn)算,使FPGA可以更好的發(fā)揮其優(yōu)勢(shì)。
今天看的這篇論文,是一篇關(guān)于FPGA和ASIC在大模型推理加速和優(yōu)化方向的綜述,我們看下目前的研究進(jìn)展。
Introduction
Transformer模型在自然語言處理(NLP)、計(jì)算機(jī)視覺和語音識(shí)別等多個(gè)領(lǐng)域都取得了顯著的成就。特別是,這些模型在機(jī)器翻譯、文本分類、圖像分類和目標(biāo)檢測(cè)等任務(wù)中表現(xiàn)出色。Transformer模型需要比傳統(tǒng)神經(jīng)網(wǎng)絡(luò)(如循環(huán)神經(jīng)網(wǎng)絡(luò)、長(zhǎng)短期記憶網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò))更多的參數(shù)和計(jì)算操作。例如,Transformer-B模型包含1.1億參數(shù),執(zhí)行21.78億次浮點(diǎn)運(yùn)算,而Vision Transformer (ViT)-B模型包含8600萬參數(shù),執(zhí)行16.85億次浮點(diǎn)運(yùn)算。
GPU的局限性:
盡管GPU在加速大型深度學(xué)習(xí)模型方面發(fā)揮了主要作用,但它們的高功耗限制了在邊緣環(huán)境中的適用性。因此,大多數(shù)大型深度學(xué)習(xí)模型在GPU服務(wù)器環(huán)境中處理,給數(shù)據(jù)中心帶來了沉重的負(fù)擔(dān)。
FPGA和ASIC的優(yōu)勢(shì):
FPGA和ASIC在并行處理、設(shè)計(jì)靈活性和功耗效率方面具有優(yōu)勢(shì),被用作各種深度學(xué)習(xí)模型的專用加速平臺(tái)。通過壓縮和設(shè)計(jì)優(yōu)化技術(shù),可以優(yōu)化FPGA和ASIC上的加速器性能,如吞吐量和功耗效率。
該論文對(duì)FPGA和ASIC基于Transformer的加速器的最新發(fā)展進(jìn)行全面回顧,探索適合于FPGA/ASIC的模型壓縮技術(shù),以及對(duì)最新的FPGA和ASIC加速器的性能進(jìn)行比較。
研究背景
論文中這部分內(nèi)容比較長(zhǎng),對(duì)Transformer模型和Vision Transformer (ViT)模型的進(jìn)行了詳細(xì)介紹,包括它們的基本組件、不同的模型變體以及它們?cè)谟?jì)算上的特點(diǎn),包含了很多理論部分,有興趣的讀者可以看原文,我只總結(jié)一下大概的內(nèi)容。
Transformer模型主要由編碼器(Encoder)和解碼器(Decoder)組成。編碼器處理輸入序列生成上下文向量,而解碼器使用編碼器的上下文向量和前一步的輸出標(biāo)記來生成下一步的標(biāo)記。編碼器和解碼器的核心操作模塊包括多頭自注意力(MHSA)和前饋網(wǎng)絡(luò)(FFN)。通過MHSA,Transformer能夠訓(xùn)練 token 之間的全局上下文信息,從而實(shí)現(xiàn)高精度。基于Transformer架構(gòu)的也有不同的模型,如BERT、GPT等,他們的預(yù)訓(xùn)練和微調(diào)方法也均有不同。這些模型在不同的NLP任務(wù)中表現(xiàn)出色,但大型模型如GPT-3由于參數(shù)眾多,難以在FPGA或ASIC上實(shí)現(xiàn)。
Vision Transformer (ViT)是針對(duì)計(jì)算機(jī)視覺任務(wù)提出的Transformer模型,主要用于圖像分類。與原始Transformer架構(gòu)不同,ViT只使用編碼器,并且在編碼器之前進(jìn)行LayerNorm操作。ViT通過將輸入圖像分割成固定大小的patches,然后通過線性投影生成Transformer輸入tokens。ViT的編碼器操作和圖像分類任務(wù)的執(zhí)行方式也有詳細(xì)說明。基于ViT架構(gòu)也有多種模型變體,如DeiT、Swin Transformer和TNT,這些模型通過不同的方式改進(jìn)了ViT,例如通過知識(shí)蒸餾、層次結(jié)構(gòu)和窗口機(jī)制、以及改進(jìn)的patch嵌入方法來提高性能。
Transformer模型壓縮
要想在FPGA/ASIC上應(yīng)用Transformer,肯定需要對(duì)模型進(jìn)行改進(jìn),要讓算法對(duì)硬件實(shí)現(xiàn)更加的友好。目前有常用的方式:
量化(Quantization):
量化是將模型的參數(shù)和激活值從通常的32位浮點(diǎn)數(shù)轉(zhuǎn)換為低精度數(shù)據(jù)格式(如INT8或INT4)的過程。這樣做可以有效減少內(nèi)存需求,同時(shí)加快計(jì)算速度并降低功耗。比如線性量化的過程,并通過量化感知訓(xùn)練(QAT)或后訓(xùn)練量化(PTQ)來恢復(fù)因量化而可能損失的準(zhǔn)確性。還可以通過優(yōu)化權(quán)重和激活值的量化策略來實(shí)現(xiàn)高壓縮比和最小的準(zhǔn)確性損失。
剪枝(Pruning):
剪枝是通過識(shí)別并移除模型中不重要的參數(shù)來減少模型大小的方法。剪枝可以基于不同的粒度,如細(xì)粒度、標(biāo)記剪枝、頭部剪枝和塊剪枝。結(jié)構(gòu)化剪枝(如標(biāo)記、頭部和塊剪枝)會(huì)改變模型結(jié)構(gòu),而無結(jié)構(gòu)化剪枝(如細(xì)粒度剪枝)則保留了模型結(jié)構(gòu),但可能導(dǎo)致內(nèi)存利用效率低下。合理的Pruning可以在內(nèi)存效率和準(zhǔn)確性之間找到平衡點(diǎn)來實(shí)現(xiàn)SOTA性能。
硬件友好的全整數(shù)算法(Hardware-friendly fully-integer algorithm):
Transformer模型中的非線性操作(如Softmax和GeLU)需要高精度的浮點(diǎn)運(yùn)算,這在FPGA或ASIC硬件上難以高效實(shí)現(xiàn)。為了解決這個(gè)問題,研究者們提出了一些近似算法和量化技術(shù),以便在硬件上以整數(shù)形式處理這些非線性函數(shù),從而減少對(duì)浮點(diǎn)運(yùn)算的需求。
硬件加速器設(shè)計(jì)優(yōu)化
在這一節(jié),論文中詳細(xì)探討了針對(duì)FPGA和ASIC平臺(tái)的Transformer模型加速器的各種優(yōu)化技術(shù)。其實(shí)這一節(jié)的內(nèi)容跟上一節(jié)是一個(gè)道理,都是在講如何讓大模型算法更好的適應(yīng)FPGA/ASIC的平臺(tái)。論文中也是花了很大的篇幅對(duì)每一個(gè)優(yōu)化方法做了詳細(xì)分析,這里我也只是總結(jié)一下論文中使用到的優(yōu)化方法,具體的內(nèi)容還是建議有興趣的讀者看原文。
稀疏性(Sparsity)
計(jì)算優(yōu)化(Computing Optimization)
內(nèi)存優(yōu)化(Memory Optimization)
硬件資源優(yōu)化(Hardware Resource Optimization)
芯片面積優(yōu)化(Chip Area Optimization)
軟硬件協(xié)同設(shè)計(jì)(Hardware-Software Co-design)
這些優(yōu)化技術(shù)都可以幫助提高加速器的性能,降低功耗,并實(shí)現(xiàn)更高效的Transformer模型推理。
性能比較
這一部分主要是對(duì)基于FPGA和ASIC的Transformer加速器的性能進(jìn)行了分析和比較。
FPGA加速器性能比較:
下面這個(gè)表,展示了不同的加速器模型使用在數(shù)據(jù)格式、工作頻率、功耗、吞吐量(GOPS)、推理速度(FPS)以及所使用的FPGA資源(如DSP、LUT、FF和BRAM)的統(tǒng)計(jì)。
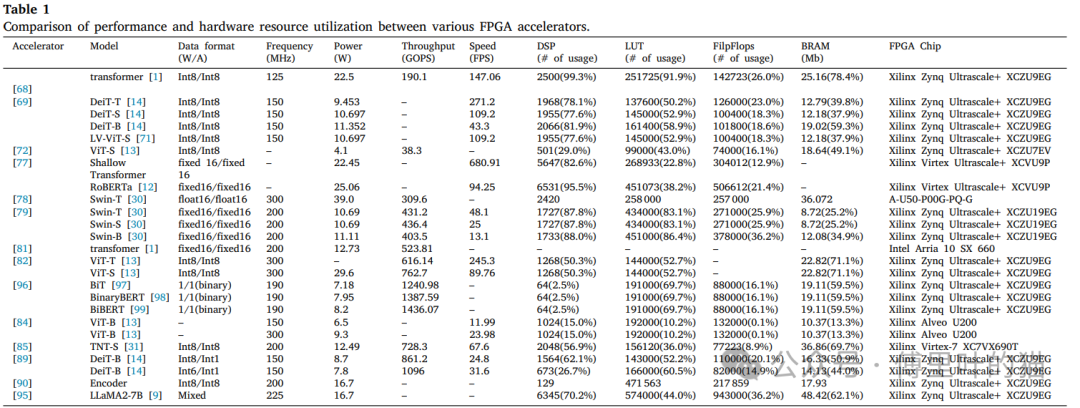
對(duì)于基于FPGA的加速器,分析的這些指標(biāo)都是FPGA芯片的關(guān)鍵資源。
可以看到,這些模型其實(shí)都有各自的優(yōu)勢(shì)和劣勢(shì),某些設(shè)計(jì)可能在吞吐量上有優(yōu)勢(shì),而其他設(shè)計(jì)可能在能效比或推理速度上有優(yōu)勢(shì)。
ASIC加速器性能比較:
下面這個(gè)表是不同模式在數(shù)據(jù)格式、工作頻率、制造工藝、芯片面積、功耗、吞吐量以及片上內(nèi)存大小的統(tǒng)計(jì)。
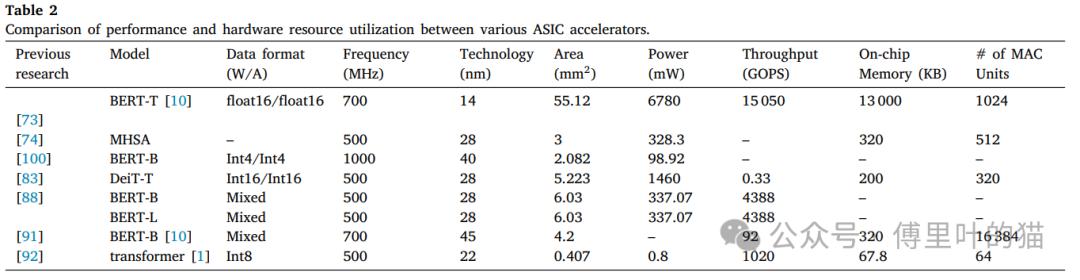
對(duì)于ASIC加速器,性能比較則側(cè)重于諸如芯片面積和技術(shù)節(jié)點(diǎn)等ASIC設(shè)計(jì)的關(guān)鍵指標(biāo)。這些因素影響著ASIC芯片的成本、能耗以及計(jì)算效率。
Further work
在前面的幾節(jié)中,論文中調(diào)研了不同模型在FPGA/ASIC上的性能比較,本節(jié)作者提出了當(dāng)前FPGA和ASIC基Transformer加速器研究的一些潛在方向和未來趨勢(shì)。
復(fù)雜任務(wù)的加速器:
除了傳統(tǒng)的分類任務(wù)外,檢測(cè)和分割等更復(fù)雜的任務(wù)對(duì)計(jì)算能力的要求更高。學(xué)術(shù)界正在探索如何通過剪枝和優(yōu)化來降低這些任務(wù)所需的能量消耗。
異構(gòu)計(jì)算平臺(tái):
異構(gòu)平臺(tái)也是目前非常火的一個(gè)方向,如何將CPU、GPU、FPGA和ASIC集成到一個(gè)平臺(tái)上,以利用每種處理器的優(yōu)勢(shì)。這種異構(gòu)架構(gòu)可以提高吞吐量,降低延遲,并提高能源效率。
混合網(wǎng)絡(luò)性能提升:
結(jié)合卷積神經(jīng)網(wǎng)絡(luò)(CNN)和Transformer的混合網(wǎng)絡(luò)正在受到關(guān)注。
調(diào)度算法和通信協(xié)議:
為了充分利用異構(gòu)計(jì)算平臺(tái)的潛力,需要開發(fā)高效的調(diào)度算法和通信協(xié)議,優(yōu)化處理器之間的數(shù)據(jù)流,減少瓶頸,提高整體性能。
硬件-軟件協(xié)同設(shè)計(jì):
軟硬件協(xié)同設(shè)計(jì)方法可以進(jìn)一步優(yōu)化Transformer模型的加速。通過迭代模擬和優(yōu)化,可以找到最佳的硬件和軟件配置,以實(shí)現(xiàn)最低的延遲和最高的能效。
新應(yīng)用和模型的開發(fā):
隨著新技術(shù)的發(fā)展,如擴(kuò)散模型和LLM,需要開發(fā)新的應(yīng)用和模型來利用這些技術(shù)。這可能涉及到開發(fā)新的硬件加速器,以支持這些模型的特定計(jì)算需求。
其實(shí)論文中講了這么多,我最關(guān)心的還是商業(yè)的部署,GPU的功耗就決定了它的應(yīng)用場(chǎng)景不會(huì)特別廣,像邊緣計(jì)算設(shè)備,基本告別那種大功耗的GPU,F(xiàn)PGA/ASIC在這方面就會(huì)顯得有優(yōu)勢(shì)。但目前來看,除了上面提到的LPU,現(xiàn)在ASIC已經(jīng)在很多場(chǎng)景使用用于做一些“小模型”的推理任務(wù),像現(xiàn)在比較火的AI PC,AI手機(jī),都是在端側(cè)運(yùn)行參數(shù)量較小的大模型,但FPGA在AI 端側(cè)的應(yīng)用還任重而道遠(yuǎn)。
-
FPGA
+關(guān)注
關(guān)注
1638文章
21859瀏覽量
609841 -
asic
+關(guān)注
關(guān)注
34文章
1237瀏覽量
121415 -
AI
+關(guān)注
關(guān)注
87文章
32961瀏覽量
272691 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5530瀏覽量
122066 -
大模型
+關(guān)注
關(guān)注
2文章
2849瀏覽量
3518
原文標(biāo)題:FPGA/ASIC在AI推理加速中的研究
文章出處:【微信號(hào):傅里葉的貓,微信公眾號(hào):傅里葉的貓】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU、FPGA和ASIC鏖戰(zhàn)AI推理
到底什么是ASIC和FPGA?

#硬聲創(chuàng)作季 #ASIC 可編程ASIC設(shè)計(jì)-06.03設(shè)計(jì)模型在FPGA上實(shí)現(xiàn)
好奇~!谷歌的 Edge TPU 專用 ASIC 旨在將機(jī)器學(xué)習(xí)推理能力引入邊緣設(shè)備
FPGA能否繼續(xù)在SoC類應(yīng)用中替代ASIC?
壓縮模型會(huì)加速推理嗎?
對(duì)FPGA與ASIC/GPU NN實(shí)現(xiàn)進(jìn)行定性的比較
AscendCL快速入門——模型推理篇(上)
HarmonyOS:使用MindSpore Lite引擎進(jìn)行模型推理
FPGA_ASIC-MAC在FPGA中的高效實(shí)現(xiàn)

如何對(duì)推理加速器進(jìn)行基準(zhǔn)測(cè)試
如何加速大語言模型推理
LLM大模型推理加速的關(guān)鍵技術(shù)
Neuchips展示大模型推理ASIC芯片
中國電提出大模型推理加速新范式Falcon






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論