


我們知道,任何編程語言編寫的程序歸根到底都是由底層機器的機器代碼(01序列)執行的,無論是編譯型語言還是解釋型語言。而任何高級編程語言程序的源代碼都是一個字符序列,這個字符序列到底層的01序列是通過編譯器或解析器經過多次轉換完成的。

圖1 編程語言的層次結構
這個層次結構中,從高到低越來越接近于機器硬件。機器代碼就是01序列,匯編語言就是描述本地機器的指令集體系結構,而高級語言就包含相應的數據結構和語法結構,更接近人類的語言習慣。因此,層次越高就越面向于人類。在計算機科學中,CPU被抽象為指令集體系結構,這個指令集描述了CPU所有完成的所有功能。所有的程序都經過編譯或解釋轉化為這個指令集表示的機器程序。在指令集中指令可以按功能劃分為:
1. 數據傳輸指令,用于讀寫內存、寄存器。
2. 算術與邏輯運算指令,比如:addl執行雙字(32bit)的加法,andl雙字的按位與。
3. 控制流指令,用于實現高級編程語言中的分支、循環等控制結構。
4. 過程調用指令,用于實現函數調用,分配、恢復棧幀等操作。
任何程序都需要被轉換為某個指令集的指令序列,比如下列簡單的求階乘的C程序:
[cpp] view plaincopyprint?int fact_while(int n)
{
int result = 1;
while (n > 1) {
result *= n;
n = n-1;
}
return result;
}
在32bit機器上,經過gcc編譯之后的x86指令序列為:
[plain] view plaincopyprint? movl 8(%ebp), %edx
movl $1, %eax
cmpl $1, %edx
jle .L7
.L10:
imull %edx, %eax
subl $1, %edx
cmpl $1, %edx
jg .L10
.L7:
通過觀察C程序的機器代碼可以發現由C程序轉化為機器代碼,主要有數據類型和控制結構的轉換。下面以x86指令集說明:
1. 數據類型的轉換:在底層,x86指令對于數據是不區分邏輯類型的,也就是不分int,float,double。所有的數據按照其所占的字節數被歸類為字(16個字節,Word)、雙字(32個字節,Double Words)、四字(64個字節,Quad Words)。一個指令操作的數據類型是由這個指令的后綴表示的,比如mov指令,movw操作字,movl操作雙字。也就是說高級語言的程序中的不同數據類型反映到底層指令集上主要體現是指令的不同。比如,將上述C程序中的result類型改為short,在相應的匯編代碼中的mov指令會由movl轉換為movw。當然,還有一個問題就是C語言中的具體數據類型,在機器代碼中是如何存儲表示的。這應該是gcc編譯器的職責,比如對于int,首先gcc需要知道底層指令集如何編碼int,采用什么編碼方式,字節順序是Big-endian還是Little-endian等。在知道底層的實現方式后gcc才能將表示整型數字的字符串編碼為相應的二進制形式。而對于數組、struct和union這些數據結構會轉化為相應的內存地址加偏移量的形式。
2. 控制結構的轉換:控制結構就是執行指令的流程。在x86中,所有的指令集都是順序執行。要實現分支、循環等結構,必須具備go形式的跳轉指令,以及相應的條件判斷指令。CPU中有一組條件碼寄存器,指示算術或邏輯運算的狀態(計算結果是否溢出、為0或者是負數等)。執行條件運算指令可以測試一個條件,比如"cmpl $1, %edx"比較直接數1與寄存器%edx中存放的數的大小,并將結果存入條件碼寄存器中。接下來執行條件跳轉指令,根據條件碼寄存器中的狀態進行判斷是否進行跳轉。比如“jg .L10”是在前一條的cmpl指令結果返回大于的情況跳轉到L10,否則執行下一條指令。
當然,在進行函數調用時,還要在底層用機器碼對其進行描述。我們知道,計算機科學中用棧來實現函數的調用(叫做調用棧),棧中存放棧幀。每一次函數調用對應一個棧幀,棧幀中包含該方法的局部變量、保存的寄存器值等數據。這樣函數的調用和返回就對應著棧幀的入棧和出棧。CPU的寄存器組中,有兩個專門用于實現方法調用,分別是%esp和%ebp。%esp是棧指針寄存器,存放當前函數棧棧頂的內存地址。%ebp是幀指針寄存器,在%esp和%ebp之間的內存地址序列就對應于當前函數的棧幀。由于函數調用、返回與棧幀的關系很密切,所以可以將以此函數調用過程描述為:
1. 初始化被調用函數的棧幀,并將其入棧。也就是調用函數過程,通過call指令實現。
2. 執行被調用函數。
3. 恢復調用函數的棧幀,將被調用函數的棧幀出棧。也就是函數返回的過程,通過ret指令實現。
對于初始化、恢復棧幀實際上都是%esp和%ebp的調整,還要包括傳參和返回值的問題,這些都是由編譯器實現的。
上面介紹了C語言和機器語言的關系,下面看一下其他類型語言的實現機制。首先,我們可以把編程語言分為編譯型語言、解釋型語言和虛擬機語言。編譯型語言直接被編譯成本地機器代碼,比如C、C++。解釋型語言是通過解釋器執行,比如javascript、shell、python等。虛擬機語言運行在虛擬機上,需要被編譯成虛擬機代碼,由虛擬機執行,比如java。雖然python也有自己的虛擬機,但是不需要編譯,所以把它歸類為解釋型語言。
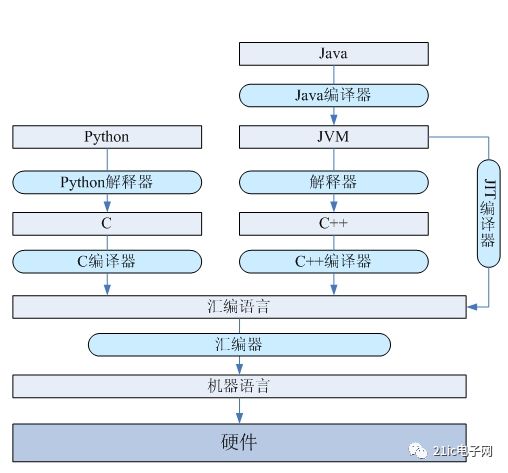
圖2 編程語言實現結構
通過上文的分析、我們知道對于一門語言最重要的是數據類型、控制結構和語法結構以及系統調用。從上圖可以看出,C和C++更接近于底層硬件,但是不能像匯編語言一樣可以直接訪問寄存器等硬件。而python和java相對于C和C++的抽象層次又高了一層,它們不能通過指針直接訪問內存。從機器語言->匯編語言->系統語言(C和C++)->解釋型語言(python)和虛擬機語言(java),抽象層次越來越高,越貼近于人的思維,不需要考慮那么多細節;同時,程序員的自由度和程序的運行速度越來越低。下面從低向高j討論一下。
在底層,匯編語言會經過匯編器轉換為機器代碼。比如,通過gcc編譯C程序時,會調用匯編器進行匯編。通過匯編器和匯編語言這一層次,可以很好的隔離底層機器硬件的實現細節。不同的處理器具有與之對應的匯編器,將匯編語言匯編成該處理器支持的指令集。這樣就是實現了匯編語言這一層的移植性。
在C和C++系統編程語言這一層,會通過編譯器完成語言元素到匯編語言的映射。比如前文描述的,數據類型、控制結構、函數調用等結構的轉換。
python是解釋型語言,它通過python解釋器實現向底層語言的映射。我們知道python虛擬機是由C語言編寫的,所以python程序會轉化為C程序而執行。比如,python中的所有對象都會在C中有對應的PyObject結構體。python的list、dict等數據類型也要在C中有對應的表示。而像生成器、迭代器等語法結構需要相應的支持。
而虛擬機是模擬一個指令集的程序,所以它自身有一套獨立于具體硬件、操作系統的指令集。需要通過底層語言實現這套指令集。虛擬機本身也有自己的數據類型系統、語言結構等。比如,java虛擬機上支持的數據類型有基本數據類型和引用類型,也支持tableswitch和lookupswitch等實現switch語法結構的字節碼指令。對于這些語言元素映射到底層語言的實現方式可以不同的方式。首先是解釋器模式轉化為C++,還有就是JIT直接編譯成本地機器代碼。
像java這樣的虛擬機語言會被編譯器編譯成虛擬機本地的機器代碼,然后再虛擬機上執行,這里就需要向javac編譯器實現java語言的數據類型、語言結構和java虛擬機上的數據類型、語法結構的映射。
通過談論,可以看出編譯器和解釋器以及虛擬機在編程語言中的重要性,它們都是編程語言可以在計算機上運行的基石。一門編程語言的編譯器、解釋器或者虛擬機可以很大程度上影響這門語言的執行效率。因為它們在進行語言轉換時會進行很多的優化以提高執行效率。這也是為什么JVM上有那么多優秀的語言,因為JVM很強大。所以,要深入語言的底層,要學會編譯器、解釋器和虛擬機的實現,這方面還需要下功夫啊。
-
C語言
+關注
關注
180文章
7633瀏覽量
141973 -
python
+關注
關注
56文章
4828瀏覽量
87002 -
機器語言
+關注
關注
0文章
36瀏覽量
10913
原文標題:關于編程語言的思考—編譯型和解釋型
文章出處:【微信號:weixin21ic,微信公眾號:21ic電子網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論