 FAIR和INRIA的合作提出人體姿勢估計新模型,適用于人體3D表面構建
FAIR和INRIA的合作提出人體姿勢估計新模型,適用于人體3D表面構建
FAIR和INRIA的合作研究提出一個在Mask-RCNN基礎上改進的密集人體姿態評估模型DensePose-RCNN,適用于人體3D表面構建等,效果很贊。并且提出一個包含50K標注圖像的人體姿態COCO數據集,即將開源。
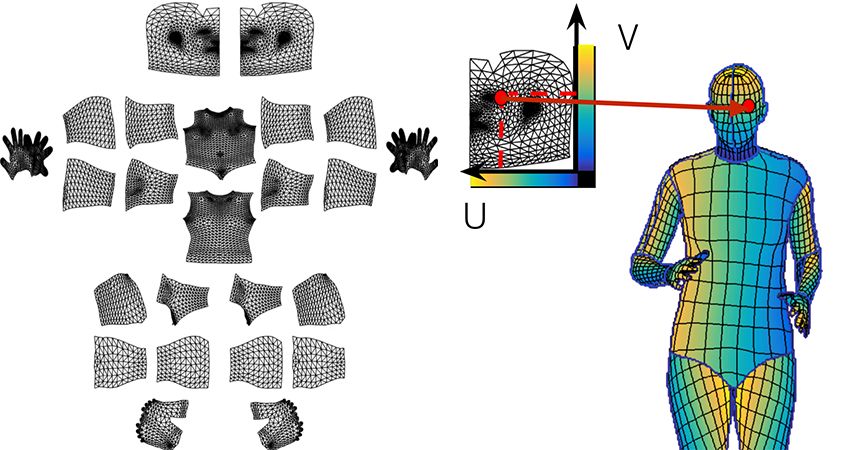
密集人體姿勢估計是指將一個RGB圖像中的所有人體像素點映射到人體的3D表面。
我們介紹了DensePose-COCO數據集,這是一個大型ground-truth數據集,在50000張COCO的圖像上手工標注了圖像-人體表面(image-to-surface)的對應點。
我們提出了DensePose-RCNN架構,這是Mask-RCNN的一個變體,以每秒多幀的速度在每個人體區域內密集地回歸特定部位的UV坐標。
DensePose-COCO數據集
我們利用人工標注建立從二維圖像到人體表面表示的密集對應。如果用常規方法,需要通過旋轉來操縱表明,導致效率低下。相反,我們構建了一個包含兩個階段的標注流程,從而高效地收集到圖像-表面的對應關系的標注。
如下所示,在第一階段,我們要求標注者劃定與可見的、語義上定義的身體部位相對應的區域。我們指導標注者估計被衣服遮擋住的身體部分,因此,比如說穿著一條大裙子也不會使隨后的對應標注復雜化。
在第二階段,我們用一組大致等距的點對每個部位的區域進行采樣,并要求注釋者將這些點與表面相對應。為了簡化這個任務,我們通過提供六個相同身體部分的預渲染視圖來展開身體部位的表面,并允許用戶在其中任何一個視圖上放置標志。這允許注釋者通過從在六個選項中選擇一個,而不用手動旋轉表面來選擇最方便的視點。
我們在數據收集過程中使用了SMPL模型和SURREAL textures。
兩個階段的標注過程使我們能夠非常有效地收集高度準確的對應數據。部位分割(part segmentation)和對應標注( correspondence annotation)這兩個任務基本是是同時進行的,考慮到后一任務更具挑戰性,這很令人驚訝。我們收集了50000人的注釋,收集了超過500萬個人工標注的對應信息。以下是在我們的驗證集中圖像注釋的可視化:圖像(左),U(中)和V(右)是收集的注釋點的值。
DensePose-RCNN系統
與DenseReg類似,我們通過劃分表面來查找密集對應。對于每個像素,需要確定:
它傾向于屬于哪個表面部位;
它對應的部位的2D參數化的位置。
下圖右邊說明了對表面的劃分和“與一個部位上的點的對應”。
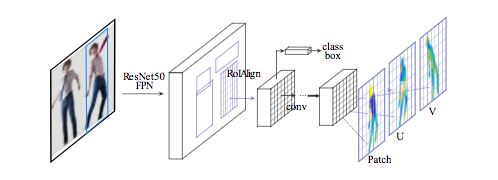
我們采用具有特征金字塔網絡( FPN)的Mask-RCNN結構,以及ROI-Align池化以獲得每個選定區域內的密集部位標簽和坐標。
如下圖所示,我們在ROI-pooling的基礎上引入一個全卷積網絡,目的是以下兩個任務:
生成每像素的分類結果以選擇表面部位
對每個部位回歸局部坐標
在推理過程,我們的系統使用GTX1080 GPU在320x240的圖像上以25fps的速度運行,在800x1100的圖像上以4-5fps的速度運行。
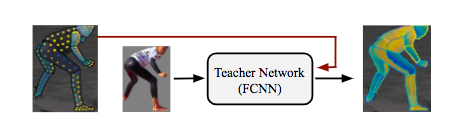
DensePose-RCNN系統可以直接使用注釋點作為監督。但是,我們通過在原本未標注的位置上“修補”監督信號的值進行取得了更好的結果。為了達到這個目的,我們采用一種基于學習的方法,首先訓練一個“教師”網絡:一個完全卷積神經網絡(如下圖),它重新構造了給定圖像的ground-truth值和segmentation mask。
我們使用級聯策略(cascading strategies)進一步提高了系統的性能。通過級聯,我們利用來自相關任務的信息,例如已經被Mask-RCNN架構成功解決的關鍵點估計和實例分割。這使我們能夠利用任務協同和不同監督來源的互補優勢。
-
3D
+關注
關注
9文章
2875瀏覽量
107480 -
RGB
+關注
關注
4文章
798瀏覽量
58461 -
INRIA
+關注
關注
0文章
2瀏覽量
6634
原文標題:效果驚艷!FAIR提出人體姿勢估計新模型,升級版Mask-RCNN
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【愛芯派 Pro 開發板試用體驗】人體姿態估計模型部署前期準備
基于局部姿態先驗的深度圖像3D人體運動捕獲方法
基于遺傳優化的自適應凸松弛人體姿勢估計
特倫托大學與Inria合作:使用GAN生成人體的新姿勢圖像
基于DensePose的姿勢轉換系統,僅根據一張輸入圖像和目標姿勢
3D打印技術未來有望打印出人體器官 以促進醫學研究的發展
先臨三維攜手TechMed 3D推出人體3D掃描一體化解決方案
適用于3D運動分析的模型

CVPR2023:IDEA與清華提出首個一階段3D全身人體網格重建算法
AI深度相機-人體姿態估計應用

3D人體生成模型HumanGaussian實現原理





 工商網監
工商網監
評論